Communicatie tussen microservices moet efficiënt en robuust zijn. Met veel kleine services die communiceren om één bedrijfsactiviteit te voltooien, kan dit een uitdaging zijn. In dit artikel kijken we naar de afwegingen tussen asynchrone berichten versus synchrone API's. Vervolgens kijken we naar enkele van de uitdagingen bij het ontwerpen van tolerante interservicecommunicatie.
Uitdagingen
Hier volgen enkele van de belangrijkste uitdagingen die voortvloeien uit service-naar-service-communicatie. Service-meshes, die verderop in dit artikel worden beschreven, zijn ontworpen om veel van deze uitdagingen aan te pakken.
Flexibiliteit. Er kunnen tientallen of zelfs honderden exemplaren van een bepaalde microservice zijn. Een exemplaar kan om een aantal redenen mislukken. Er kan een fout op knooppuntniveau optreden, zoals een hardwarefout of het opnieuw opstarten van een VIRTUELE machine. Een exemplaar kan vastlopen of worden overweldigd met aanvragen en kan geen nieuwe aanvragen verwerken. Elk van deze gebeurtenissen kan ertoe leiden dat een netwerkoproep mislukt. Er zijn twee ontwerppatronen waarmee service-naar-service-netwerkoproepen toleranter kunnen worden:
Opnieuw proberen. Een netwerkoproep kan mislukken vanwege een tijdelijke fout die zelf verdwijnt. In plaats van een fout uit te voeren, moet de beller de bewerking meestal een bepaald aantal keren opnieuw proberen of totdat een geconfigureerde time-outperiode is verstreken. Als een bewerking echter niet idempotent is, kunnen nieuwe pogingen onbedoelde bijwerkingen veroorzaken. De oorspronkelijke aanroep kan slagen, maar de beller krijgt nooit een antwoord. Als de beller opnieuw probeert te proberen, kan de bewerking twee keer worden aangeroepen. Over het algemeen is het niet veilig om POST- of PATCH-methoden opnieuw uit te voeren, omdat deze niet gegarandeerd idempotent zijn.
Circuitonderbreker. Te veel mislukte aanvragen kunnen een knelpunt veroorzaken, omdat wachtende aanvragen zich in de wachtrij verzamelen. Deze geblokkeerde aanvragen kunnen kritische bedrijfsresources bevatten, zoals geheugen, threads, databaseverbindingen enzovoort, die tot een opeenstapeling van storingen kan leiden. Het circuitonderbrekerpatroon kan voorkomen dat een service herhaaldelijk een bewerking probeert uit te voeren die waarschijnlijk mislukt.
Taakverdeling. Wanneer service A service B aanroept, moet de aanvraag een actief exemplaar van de service B bereiken. In Kubernetes biedt het Service resourcetype een stabiel IP-adres voor een groep pods. Netwerkverkeer naar het IP-adres van de service wordt doorgestuurd naar een pod via iptable-regels. Standaard wordt een willekeurige pod gekozen. Een service-mesh (zie hieronder) kan meer intelligente algoritmen voor taakverdeling bieden op basis van waargenomen latentie of andere metrische gegevens.
Gedistribueerde tracering. Eén transactie kan meerdere services omvatten. Hierdoor kan het lastig zijn om de algehele prestaties en status van het systeem te bewaken. Zelfs als elke service logboeken en metrische gegevens genereert, zonder dat ze op een of andere manier aan elkaar kunnen worden gekoppeld, zijn ze van beperkt gebruik. In het artikel Logboekregistratie en bewaking wordt meer gesproken over gedistribueerde tracering, maar we noemen het hier als een uitdaging.
Serviceversiebeheer. Wanneer een team een nieuwe versie van een service implementeert, moeten ze voorkomen dat andere services of externe clients die hiervan afhankelijk zijn, worden onderbroken. Daarnaast kunt u meerdere versies van een service naast elkaar uitvoeren en aanvragen naar een bepaalde versie routeren. Zie API-versiebeheer voor meer informatie over dit probleem.
TLS-versleuteling en wederzijdse TLS-verificatie. Om veiligheidsredenen wilt u mogelijk verkeer tussen services versleutelen met TLS en wederzijdse TLS-verificatie gebruiken om bellers te verifiëren.
Synchroon versus asynchrone berichten
Er zijn twee basispatronen voor berichten die microservices kunnen gebruiken om te communiceren met andere microservices.
Synchrone communicatie. In dit patroon roept een service een API aan die een andere service beschikbaar maakt, met behulp van een protocol zoals HTTP of gRPC. Deze optie is een synchrone berichtenpatroon omdat de beller wacht op een reactie van de ontvanger.
Asynchroon bericht doorgeven. In dit patroon verzendt een service een bericht zonder te wachten op een antwoord en verwerken een of meer services het bericht asynchroon.
Het is belangrijk om onderscheid te maken tussen asynchrone I/O en een asynchroon protocol. Asynchrone I/O betekent dat de aanroepende thread niet wordt geblokkeerd terwijl de I/O is voltooid. Dat is belangrijk voor prestaties, maar is een implementatiedetail in termen van de architectuur. Een asynchroon protocol betekent dat de afzender niet op een antwoord wacht. HTTP is een synchroon protocol, ook al kan een HTTP-client asynchrone I/O gebruiken wanneer een aanvraag wordt verzonden.
Er zijn compromissen voor elk patroon. Aanvraag/antwoord is een goed begrepen paradigma, dus het ontwerpen van een API voelt zich natuurlijker dan het ontwerpen van een berichtensysteem. Asynchrone berichten hebben echter enkele voordelen die nuttig kunnen zijn in een microservicesarchitectuur:
Gereduceerde koppeling. De afzender van het bericht hoeft niet op de hoogte te zijn van de consument.
Meerdere abonnees. Met behulp van een pub/submodel kunnen meerdere consumenten zich abonneren op het ontvangen van gebeurtenissen. Zie de stijl gebeurtenisgestuurde architectuur.
Isolatie van fouten. Als de consument uitvalt, kan de afzender nog steeds berichten verzenden. De berichten worden opgehaald wanneer de consument herstelt. Deze mogelijkheid is vooral handig in een microservicesarchitectuur, omdat elke service een eigen levenscyclus heeft. Een service kan op elk gewenst moment niet meer beschikbaar zijn of worden vervangen door een nieuwere versie. Asynchrone berichten kunnen onregelmatige downtime verwerken. Synchrone API's vereisen daarentegen dat de downstreamservice beschikbaar is of dat de bewerking mislukt.
Reactiesnelheid. Een upstream-service kan sneller reageren als deze niet wacht op downstreamservices. Dit is vooral handig in een microservicearchitectuur. Als er een keten van serviceafhankelijkheden is (service A roept B aan, die C aanroept, enzovoort), kan het wachten op synchrone aanroepen onacceptabele hoeveelheden latentie toevoegen.
Herverdeling van taken. Een wachtrij kan fungeren als buffer om de werkbelasting te evelleren, zodat ontvangers berichten op hun eigen snelheid kunnen verwerken.
Werkstromen. Wachtrijen kunnen worden gebruikt om een werkstroom te beheren door het bericht na elke stap in de werkstroom te controleren.
Er zijn echter ook enkele uitdagingen voor het effectief gebruik van asynchrone berichten.
Koppeling met de berichteninfrastructuur. Het gebruik van een bepaalde berichteninfrastructuur kan een nauwe koppeling met die infrastructuur veroorzaken. Het is later lastig om over te schakelen naar een andere berichteninfrastructuur.
Latentie. End-to-endlatentie voor een bewerking kan hoog worden als de berichtenwachtrijen vol raken.
Kosten. Bij hoge doorvoer kunnen de financiële kosten van de berichteninfrastructuur aanzienlijk zijn.
Complexiteit. Het verwerken van asynchrone berichten is geen triviale taak. U moet bijvoorbeeld dubbele berichten afhandelen door dupliceren of door bewerkingen idempotent te maken. Het is ook moeilijk om semantiek voor aanvragen en antwoorden te implementeren met behulp van asynchrone berichten. Als u een antwoord wilt verzenden, hebt u een andere wachtrij nodig, plus een manier om aanvraag- en antwoordberichten te correleren.
Doorvoer. Als berichten semantiek van wachtrijen vereisen, kan de wachtrij een knelpunt in het systeem worden. Voor elk bericht is ten minste één wachtrijbewerking en één wachtrijbewerking vereist. Bovendien vereisen wachtrijsemantiek over het algemeen een soort vergrendeling binnen de berichteninfrastructuur. Als de wachtrij een beheerde service is, is er mogelijk extra latentie, omdat de wachtrij zich buiten het virtuele netwerk van het cluster bevindt. U kunt deze problemen beperken door berichten in batches te plaatsen, maar dat maakt de code ingewikkeld. Als voor de berichten geen semantiek van de wachtrij is vereist, kunt u mogelijk een gebeurtenisstroom gebruiken in plaats van een wachtrij. Zie Gebeurtenisgestuurde architectuurstijl voor meer informatie.
Drone Delivery: De berichtenpatronen kiezen
Deze oplossing maakt gebruik van het droneleveringsvoorbeeld. Het is ideaal voor de luchtvaart- en vliegtuigindustrie.
Met deze overwegingen in het achterhoofd heeft het ontwikkelteam de volgende ontwerpkeuzes gemaakt voor de Drone Delivery-toepassing:
De opnameservice maakt een openbare REST API beschikbaar die clienttoepassingen gebruiken om leveringen te plannen, bij te werken of te annuleren.
De opnameservice maakt gebruik van Event Hubs om asynchrone berichten naar de Scheduler-service te verzenden. Asynchrone berichten zijn nodig om de load-leveling te implementeren die vereist is voor opname.
Het account, de levering, het pakket, de drone en de transportservices van derden maken allemaal interne REST API's beschikbaar. De Scheduler-service roept deze API's aan om een gebruikersaanvraag uit te voeren. Een van de redenen om synchrone API's te gebruiken, is dat de Scheduler een antwoord moet krijgen van elk van de downstreamservices. Een fout in een van de downstreamservices betekent dat de hele bewerking is mislukt. Een potentieel probleem is echter de hoeveelheid latentie die wordt geïntroduceerd door de back-endservices aan te roepen.
Als een downstreamservice een niet-tijdelijke fout heeft, moet de hele transactie worden gemarkeerd als mislukt. Om dit geval af te handelen, verzendt de Scheduler-service een asynchroon bericht naar de Supervisor, zodat de Supervisor compenserende transacties kan plannen.
De Delivery-service maakt een openbare API beschikbaar die clients kunnen gebruiken om de status van een levering op te halen. In het artikel API-gateway bespreken we hoe een API-gateway de onderliggende services van de client kan verbergen, zodat de client niet hoeft te weten welke services beschikbaar zijn voor welke API's.
Terwijl een drone onderweg is, verzendt de Drone-service gebeurtenissen die de huidige locatie en status van de drone bevatten. De Leveringsservice luistert naar deze gebeurtenissen om de status van een levering bij te houden.
Wanneer de status van een levering verandert, verzendt de Leveringsservice een gebeurtenis van de leveringsstatus, zoals
DeliveryCreatedofDeliveryCompleted. Elke service kan zich abonneren op deze gebeurtenissen. In het huidige ontwerp is de Delivery History-service de enige abonnee, maar er kunnen later andere abonnees zijn. De gebeurtenissen kunnen bijvoorbeeld naar een realtime analyseservice gaan. En omdat de Scheduler niet hoeft te wachten op een antwoord, heeft het toevoegen van meer abonnees geen invloed op het hoofdwerkstroompad.
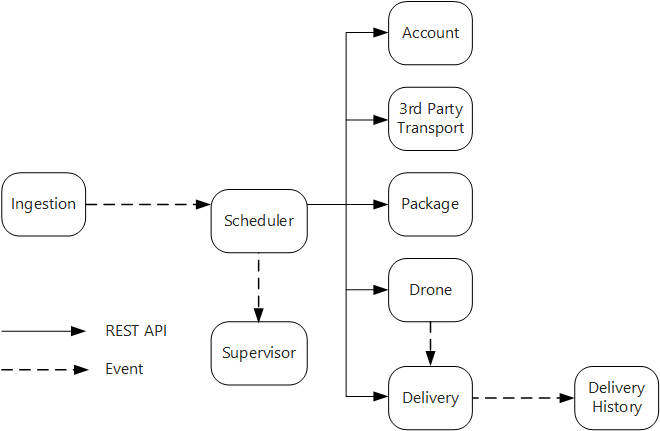
U ziet dat gebeurtenissen van de leveringsstatus worden afgeleid van locatie-gebeurtenissen van drones. Wanneer een drone bijvoorbeeld een leveringslocatie bereikt en een pakket afgeeft, vertaalt de Leveringsservice dit in een DeliveryCompleted-gebeurtenis. Dit is een voorbeeld van denken in termen van domeinmodellen. Zoals eerder beschreven, behoort Drone Management tot een afzonderlijke context. De drone-gebeurtenissen brengen de fysieke locatie van een drone over. De leveringsevenementen vertegenwoordigen daarentegen wijzigingen in de status van een levering, een andere bedrijfsentiteit.
Een service-mesh gebruiken
Een service-mesh is een softwarelaag die service-naar-service-communicatie afhandelt. Service-meshes zijn ontworpen om veel van de problemen in de vorige sectie aan te pakken en om de verantwoordelijkheid voor deze problemen weg te verplaatsen van de microservices zelf en in een gedeelde laag. De service-mesh fungeert als een proxy die netwerkcommunicatie tussen microservices in het cluster onderschept. Het service-mesh-concept is momenteel voornamelijk van toepassing op containerorchestrators, in plaats van serverloze architecturen.
Notitie
Service mesh is een voorbeeld van het Ambassador-patroon : een helperservice waarmee netwerkaanvragen namens de toepassing worden verzonden.
Op dit moment zijn linkerd en Istio de belangrijkste opties voor een service-mesh in Kubernetes. Beide technologieën ontwikkelen zich snel. Sommige functies die zowel Linkerd als Istio gemeen hebben, zijn echter:
Taakverdeling op sessieniveau, op basis van waargenomen latenties of het aantal openstaande aanvragen. Dit kan de prestaties verbeteren ten opzichte van de laag-4-taakverdeling die wordt geleverd door Kubernetes.
Laag-7-routering op basis van URL-pad, hostheader, API-versie of andere regels op toepassingsniveau.
Mislukte aanvragen opnieuw proberen. Een service-mesh begrijpt HTTP-foutcodes en kan mislukte aanvragen automatisch opnieuw proberen. U kunt dit maximum aantal nieuwe pogingen configureren, samen met een time-outperiode om de maximale latentie te beperken.
Circuitonderbreking. Als een exemplaar consistent mislukte aanvragen, markeert de service-mesh deze tijdelijk als niet beschikbaar. Na een uitstelperiode wordt het exemplaar opnieuw geprobeerd. U kunt de circuitonderbreker configureren op basis van verschillende criteria, zoals het aantal opeenvolgende fouten,
Service mesh legt metrische gegevens vast over interservice-aanroepen, zoals het aanvraagvolume, de latentie, fout- en slagingspercentages en antwoordgrootten. De service-mesh maakt gedistribueerde tracering ook mogelijk door correlatie-informatie toe te voegen voor elke hop in een aanvraag.
Wederzijdse TLS-verificatie voor service-naar-service-aanroepen.
Hebt u een service mesh nodig? Dat hangt ervan af. Zonder service-mesh moet u rekening houden met elk van de uitdagingen die aan het begin van dit artikel worden genoemd. U kunt problemen oplossen zoals opnieuw proberen, circuitonderbreker en gedistribueerde tracering zonder een service-mesh, maar een service-mesh verplaatst deze problemen uit de afzonderlijke services en in een toegewezen laag. Aan de andere kant voegt een service-mesh complexiteit toe aan de installatie en configuratie van het cluster. Er kunnen gevolgen zijn voor de prestaties, omdat aanvragen nu worden gerouteerd via de service-mesh-proxy en omdat er nu extra services worden uitgevoerd op elk knooppunt in het cluster. U moet grondige prestaties en belastingstests uitvoeren voordat u een service-mesh in productie implementeert.
Gedistribueerde transacties
Een veelvoorkomende uitdaging in microservices is het correct verwerken van transacties die meerdere services omvatten. In dit scenario is het succes van een transactie vaak alles of niets. Als een van de deelnemende services mislukt, moet de hele transactie mislukken.
Er zijn twee gevallen waar u rekening mee moet houden:
Een service kan een tijdelijke fout ondervinden, zoals een time-out voor het netwerk. Deze fouten kunnen vaak worden opgelost door de aanroep opnieuw uit te voeren. Als de bewerking na een bepaald aantal pogingen nog steeds mislukt, wordt deze beschouwd als een niet-tijdelijke fout.
Een niet-tijdelijke fout is een fout die waarschijnlijk niet zelf weggaat. Niet-tijdelijke fouten omvatten normale foutvoorwaarden, zoals ongeldige invoer. Ze omvatten ook niet-verwerkte uitzonderingen in toepassingscode of een proces dat vastloopt. Als dit type fout optreedt, moet de hele zakelijke transactie worden gemarkeerd als een fout. Het kan nodig zijn om andere stappen in dezelfde transactie ongedaan te maken die al zijn geslaagd.
Na een niet-tijdelijke fout kan de huidige transactie een gedeeltelijk mislukte status hebben, waarbij een of meer stappen al zijn voltooid. Als de Drone-service bijvoorbeeld al een drone heeft gepland, moet de drone worden geannuleerd. In dat geval moet de toepassing de stappen die zijn geslaagd ongedaan maken met behulp van een compenserende transactie. In sommige gevallen moet deze actie worden uitgevoerd door een extern systeem of zelfs door een handmatig proces. In uw ontwerp moet u er rekening mee houden dat compenserende maatregelen ook fouten ondervinden.
Als de logica voor compenserende transacties complex is, kunt u overwegen een afzonderlijke service te maken die verantwoordelijk is voor dit proces. In de Drone Delivery-toepassing plaatst de Scheduler-service mislukte bewerkingen in een toegewezen wachtrij. Een afzonderlijke microservice, de Supervisor genoemd, leest uit deze wachtrij en roept een annulerings-API aan voor de services die moeten worden gecompenseerd. Dit is een variant van het Scheduler Agent Supervisor-patroon. De Supervisor-service kan ook andere acties ondernemen, zoals de gebruiker per sms of e-mail op de hoogte stellen of een waarschuwing verzenden naar een bewerkingsdashboard.
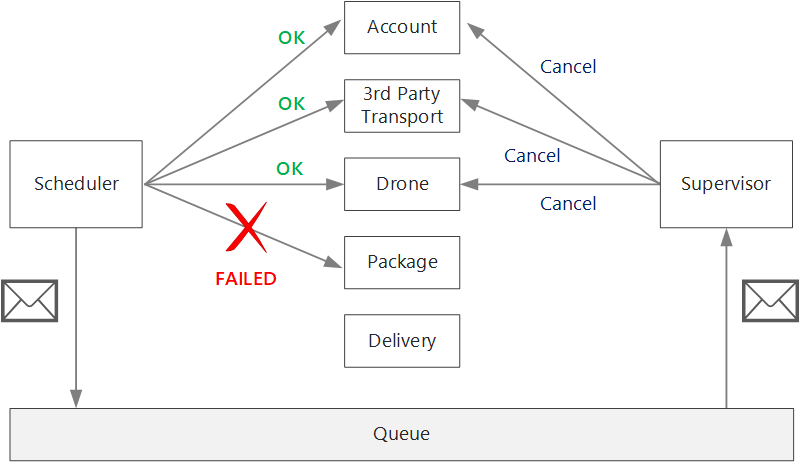
De Scheduler-service zelf kan mislukken (bijvoorbeeld omdat een knooppunt vastloopt). In dat geval kan een nieuwe instantie worden uitgevoerd en overnemen. Alle transacties die al worden uitgevoerd, moeten echter worden hervat.
Een benadering is het opslaan van een controlepunt in een duurzame opslag nadat elke stap in de werkstroom is voltooid. Als een exemplaar van de Scheduler-service vastloopt in het midden van een transactie, kan een nieuw exemplaar het controlepunt gebruiken om te hervatten waar het vorige exemplaar was gebleven. Het schrijven van controlepunten kan echter een prestatieoverhead tot gevolg hebben.
Een andere optie is om alle bewerkingen te ontwerpen die idempotent zijn. Een bewerking is idempotent als deze meerdere keren kan worden aangeroepen zonder extra bijwerkingen na de eerste aanroep te produceren. In wezen moet de downstreamservice dubbele aanroepen negeren, wat betekent dat de service dubbele aanroepen moet kunnen detecteren. Het is niet altijd eenvoudig om idempotente methoden te implementeren. Zie Idempotent operations voor meer informatie.
Volgende stappen
Voor microservices die rechtstreeks met elkaar communiceren, is het belangrijk om goed ontworpen API's te maken.