Patroon Pijpen en filters
Splits een taak waarmee een complexe verwerking wordt uitgevoerd, op in een reeks afzonderlijke elementen die kunnen worden hergebruikt. Hierdoor kunnen de prestaties, schaalbaarheid en herbruikbaarheid van de eerste stappen worden verbeterd door taakelementen die de verwerking uitvoeren, onafhankelijk van elkaar te implementeren en te schalen. Het patroon Pijpen en Filters ondersteunt een hoog niveau van modulariteit.
Context en probleem
U hebt een pijplijn met opeenvolgende taken die u moet verwerken. Een eenvoudige maar inflexibele benadering voor het implementeren van deze toepassing is door deze verwerking uit te voeren in een monolithische module. Deze aanpak vermindert echter waarschijnlijk de mogelijkheden voor het herstructureren van de code, het optimaliseren ervan of het hergebruik ervan als delen van dezelfde verwerking elders in de toepassing vereist zijn.
Het volgende diagram illustreert een van de problemen met het verwerken van gegevens met behulp van een monolithische benadering, het onvermogen om code opnieuw te gebruiken in meerdere pijplijnen. In dit voorbeeld ontvangt en verwerkt een toepassing gegevens van twee bronnen. Een afzonderlijke module verwerkt de gegevens van elke bron door een reeks taken uit te voeren om de gegevens te transformeren voordat het resultaat wordt doorgegeven aan de bedrijfslogica van de toepassing.
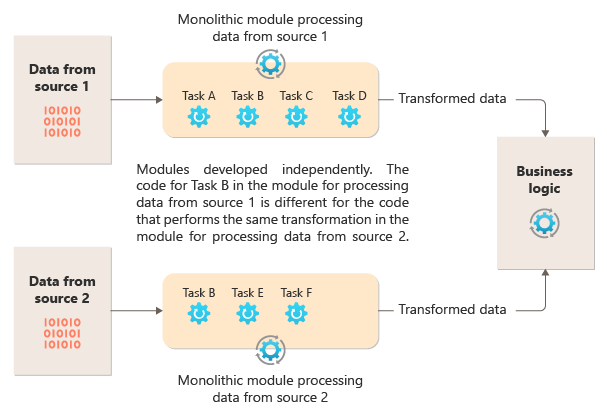
Sommige van de taken die door de monolithische modules worden uitgevoerd, zijn functioneel vergelijkbaar, maar de code moet in beide modules worden herhaald en is waarschijnlijk nauw gekoppeld in de module. Naast het onvermogen om logica opnieuw te gebruiken, introduceert deze benadering een risico wanneer de vereisten veranderen. U moet de code op beide locaties bijwerken.
Er zijn andere uitdagingen met een monolithische implementatie die niet is gerelateerd aan meerdere pijplijnen of hergebruik. Met een monolith hebt u niet de mogelijkheid om specifieke taken in verschillende omgevingen uit te voeren of ze onafhankelijk te schalen. Sommige taken kunnen rekenintensief zijn en kunnen profiteren van uitvoering op krachtige hardware of het parallel uitvoeren van meerdere exemplaren. Andere taken hebben mogelijk niet dezelfde vereisten. Verder is het met monolithen lastig om taken opnieuw te ordenen of nieuwe taken in de pijplijn te injecteren. Voor deze wijzigingen moet de hele pijplijn opnieuw worden getest.
Oplossing
Splits de vereiste verwerking voor elke stroom in een set afzonderlijke onderdelen (of filters), die elk één enkele taak uitvoeren. Samengestelde taken moeten meerdere filters gebruiken in plaats van één. De filters zijn samengesteld in pijplijnen door de filters te verbinden met pijplijnen. Filters zijn onafhankelijk, zelfstandig en meestal staatloos. Filters ontvangen berichten van een binnenkomende pijp en publiceren berichten naar een andere uitgaande pijp. Filters kunnen het bericht transformeren of testen op basis van een of meer criteria om voorwaardelijke logica op te nemen. Pijpen voeren geen routering of andere logica uit. Ze verbinden alleen filters en geven het uitvoerbericht van het ene filter door als invoer aan het volgende.
Filters handelen onafhankelijk en zijn niet op de hoogte van andere filters. Ze zijn alleen op de hoogte van hun invoer- en uitvoerschema's. Als zodanig kunnen de filters in elke volgorde worden gerangschikt zolang het invoerschema voor elk filter overeenkomt met het uitvoerschema voor het vorige filter. Het gebruik van een gestandaardiseerd schema voor alle filters verbetert de mogelijkheid om filters opnieuw te ordenen. Pijpen en filters architectuur stimuleert compositie hergebruik.
Door de losse koppeling van filters kunt u het volgende eenvoudig doen:
- Nieuwe pijplijnen maken die bestaan uit bestaande filters
- Logica in afzonderlijke filters bijwerken of vervangen
- Filters opnieuw ordenen, indien nodig
- Voer waar nodig filters uit op verschillende hardware
- Filters parallel uitvoeren
In dit diagram ziet u een oplossing die is geïmplementeerd met pijpen en filters:
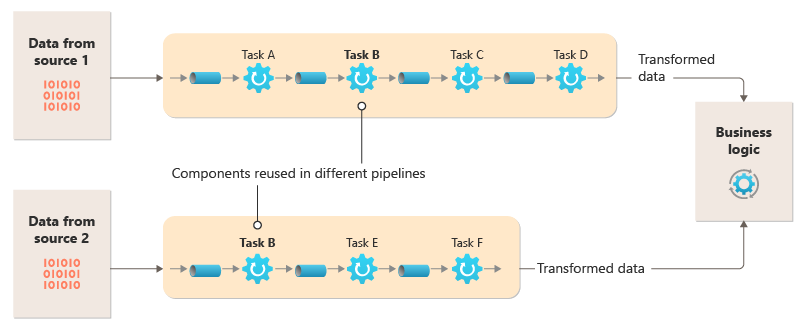
De tijd die nodig is om één aanvraag te verwerken, is afhankelijk van de snelheid van de langzaamste filters in de pijplijn. Een of meer filters kunnen knelpunten zijn, met name als een groot aantal aanvragen in een stroom van een bepaalde gegevensbron wordt weergegeven. Dankzij de mogelijkheid om parallelle exemplaren van trage filters uit te voeren, kan het systeem de belasting verspreiden en de doorvoer verbeteren.
Dankzij de mogelijkheid om filters uit te voeren op verschillende rekeninstanties, kunnen ze onafhankelijk worden geschaald en profiteren van de elasticiteit die veel cloudomgevingen bieden. Een filter dat rekenintensief is, kan worden uitgevoerd op krachtige hardware, terwijl andere minder veeleisende filters kunnen worden gehost op goedkopere basishardware. De filters hoeven zich niet eens in hetzelfde datacenter of dezelfde geografische locatie te bevinden, zodat elk element in een pijplijn kan worden uitgevoerd in een omgeving die dicht bij de resources ligt die nodig zijn. Deze inspanningen vereisen specifieke ontwerptechnieken, zoals berichten, multithreading, enzovoort om de elasticiteit van elke pijp of filter te maximaliseren. In dit diagram ziet u een voorbeeld dat is toegepast op de pijplijn voor de gegevens uit bron 1:
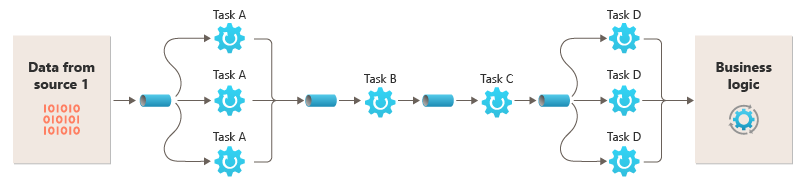
Als de invoer en uitvoer van een filter zijn gestructureerd als een stroom, kunt u de verwerking voor elk filter parallel uitvoeren. Het eerste filter in de pijplijn kan het werk starten en de resultaten uitvoeren, die rechtstreeks worden doorgegeven aan het volgende filter in de reeks voordat het eerste filter het werk voltooit.
Het gebruik van het patroon Pipes en Filters in combinatie met het patroon Compenserende transactie is een alternatieve benadering voor het implementeren van gedistribueerde transacties. U kunt een gedistribueerde transactie opsplitsen in afzonderlijke, compenserende taken, die elk kunnen worden geïmplementeerd via een filter waarmee ook het patroon Compenserende transactie wordt geïmplementeerd. U kunt de filters in een pijplijn implementeren als afzonderlijke gehoste taken die dicht bij de gegevens worden uitgevoerd die ze onderhouden.
Problemen en overwegingen
Houd rekening met de volgende punten wanneer u besluit hoe u dit patroon implementeert:
Monolithische aard. Dit patroon wordt meestal geïmplementeerd als een monolithische pijplijn, dus voor elke wijziging moet de volledige filterketen end-to-end worden getest. Bovendien moet rekening worden gehouden met fouttolerantie voor het hele proces; Als een filter of pijp mislukt, mislukt de hele pijplijn waarschijnlijk.
Complexiteit. De grotere flexibiliteit die dit patroon biedt, kan ook leiden tot extra complexiteit, met name als de filters in een pijplijn zijn verspreid over verschillende servers.
Betrouwbaarheid. Gebruik een infrastructuur die ervoor zorgt dat gegevens die tussen filters in een pijp stromen, niet verloren gaan.
Idempotentie. Als een filter in een pijplijn mislukt nadat een bericht is ontvangen en het werk opnieuw is gepland voor een ander exemplaar van het filter, is een deel van het werk mogelijk al voltooid. Als het werk een bepaald aspect van de globale status bijwerkt (zoals informatie die is opgeslagen in een database), kan één update worden herhaald. Er kan een vergelijkbaar probleem optreden als een filter mislukt nadat het de resultaten naar het volgende filter heeft geplaatst, maar voordat wordt aangegeven dat het werk is voltooid. In deze gevallen kan een ander exemplaar van het filter dit werk herhalen, waardoor dezelfde resultaten tweemaal worden gepost. Dit scenario kan ertoe leiden dat volgende filters in de pijplijn dezelfde gegevens tweemaal verwerken. Daarom moeten filters in een pijplijn worden ontworpen om idempotent te zijn. Zie Idempotentiepatronen op de blog van Jonathan Oliver voor meer informatie.
Herhaalde berichten. Als een filter in een pijplijn mislukt nadat er een bericht in de volgende fase van de pijplijn is geplaatst, kan een ander exemplaar van het filter worden uitgevoerd en wordt er een kopie van hetzelfde bericht naar de pijplijn geplaatst. Dit scenario kan ertoe leiden dat twee exemplaren van hetzelfde bericht worden doorgegeven aan het volgende filter. Om dit probleem te voorkomen, moet de pijplijn dubbele berichten detecteren en elimineren.
Notitie
Als u de pijplijn implementeert met behulp van berichtenwachtrijen (zoals Azure Service Bus-wachtrijen), kan de infrastructuur voor berichtenwachtrijen automatische detectie en verwijdering van dubbele berichten bieden.
Context en status. In een pijplijn wordt elk filter in feite geïsoleerd uitgevoerd en mag dit geen aannames doen over hoe het is aangeroepen. Daarom moet elk filter voldoende context krijgen om het werk uit te voeren. Deze context kan een aanzienlijke hoeveelheid statusinformatie bevatten. Als filters externe status gebruiken, zoals gegevens in een database of externe opslag, moet u rekening houden met de invloed op de prestaties. Elk filter moet die status laden, gebruiken en behouden, waardoor overhead wordt toegevoegd aan oplossingen die de externe status één keer laden.
Berichttolerantie. Filters moeten tolerant zijn voor gegevens in het binnenkomende bericht waarop ze niet werken. Ze werken op de gegevens die relevant zijn voor deze gegevens en negeren andere gegevens en geven deze ongewijzigd door in het uitvoerbericht.
Foutafhandeling : elk filter moet bepalen wat u moet doen in het geval van een fout die fouten veroorzaakt. Het filter moet bepalen of de pijplijn mislukt of de uitzondering doorgeeft.
Wanneer dit patroon gebruiken
Gebruik dit patroon wanneer:
De verwerking die een toepassing vereist, kan eenvoudig worden opgesplitst in een reeks onafhankelijke stappen.
De verwerkingsstappen die worden uitgevoerd door een toepassing, hebben verschillende schaalbaarheidsvereisten.
Notitie
U kunt filters groeperen die samen moeten worden geschaald in hetzelfde proces. Zie Patroon Consolidatie van rekenresources voor meer informatie.
U hebt de flexibiliteit nodig om de volgorde van de verwerkingsstappen die de toepassing uitvoert, opnieuw te ordenen of om de mogelijkheid toe te staan stappen toe te voegen en te verwijderen.
Het systeem kan ervan profiteren als de verwerking van stappen over verschillende servers wordt verdeeld.
U hebt een betrouwbare oplossing nodig waarmee de gevolgen van fouten in een stap worden geminimaliseerd terwijl gegevens worden verwerkt.
In de volgende gevallen is dit patroon mogelijk niet geschikt:
De toepassing volgt een aanvraag-antwoordpatroon.
De taakverwerking moet worden voltooid als onderdeel van een eerste aanvraag, zoals een aanvraag/antwoordscenario.
De verwerkingsstappen die door een toepassing worden uitgevoerd, zijn niet onafhankelijk of moeten samen worden uitgevoerd als onderdeel van één transactie.
De hoeveelheid context- of statusgegevens die een stap vereist, maakt deze benadering inefficiënt. Mogelijk kunt u statusinformatie naar een database behouden, maar gebruik deze strategie niet als de extra belasting van de database overmatige conflicten veroorzaakt.
Workloadontwerp
Een architect moet evalueren hoe het patroon Pijpen en filters kan worden gebruikt in het ontwerp van hun workload om de doelstellingen en principes te verhelpen die worden behandeld in de pijlers van het Azure Well-Architected Framework. Voorbeeld:
| Pijler | Hoe dit patroon ondersteuning biedt voor pijlerdoelen |
|---|---|
| Beslissingen over betrouwbaarheidsontwerp helpen uw workload bestand te worden tegen storingen en ervoor te zorgen dat deze herstelt naar een volledig functionerende status nadat er een fout is opgetreden. | De enige verantwoordelijkheid van elke fase maakt gerichte aandacht mogelijk en vermijdt afleiding van commingled gegevensverwerking. - RE:01 Eenvoud - RE:07 Achtergrondtaken |
Net als bij elke ontwerpbeslissing moet u rekening houden met eventuele compromissen ten opzichte van de doelstellingen van de andere pijlers die met dit patroon kunnen worden geïntroduceerd.
Opmerking
U kunt een reeks berichtenwachtrijen gebruiken om de infrastructuur te bieden die vereist is om een pijplijn te implementeren. Een eerste berichtenwachtrij ontvangt niet-verwerkte berichten die het begin worden van de implementatie van het pijp- en filterpatroon. Een onderdeel dat is geïmplementeerd als een filtertaak luistert naar een bericht in deze wachtrij, voert het werk uit en plaatst vervolgens een nieuw of getransformeerd bericht in de volgende wachtrij in de reeks. Een andere filtertaak kan luisteren naar berichten in deze wachtrij, verwerken, de resultaten posten in een andere wachtrij, enzovoort, totdat de laatste stap die het pijpen- en filtersproces beëindigt. Dit diagram illustreert een pijplijn die gebruikmaakt van berichtenwachtrijen:

Een pijplijn voor afbeeldingsverwerking kan worden geïmplementeerd met behulp van dit patroon. Als uw workload een afbeelding neemt, kan de afbeelding een reeks grotendeels onafhankelijke en herschikbare filters passeren om acties uit te voeren, zoals:
- con tentmodus ration
- formaat aanpassen
- Watermerken
- Heroriëntatie
- Verwijdering van exif-metagegevens
- CDN-publicatie (Content Delivery Network)
In dit voorbeeld kunnen de filters worden geïmplementeerd als afzonderlijk geïmplementeerde Azure Functions of zelfs één Azure Function-app die elk filter als een geïsoleerde implementatie bevat. Het gebruik van Azure-functietriggers, invoerbindingen en uitvoerbindingen kan de filtercode vereenvoudigen en automatisch werken met een pijp op basis van een wachtrij met behulp van een claimcontrole voor de afbeelding die moet worden verwerkt.

Hier volgt een voorbeeld van hoe één filter, geïmplementeerd als een Azure-functie, wordt geactiveerd vanuit een Queue Storage-pijp met een claim controleren op de afbeelding en hoe het schrijven van een nieuwe claimcontrole naar een andere Queue Storage-pijp eruit kan zien. We hebben de implementatie vervangen door pseudocode in opmerkingen voor beknoptheid. Meer code als deze vindt u in de demonstratie van het patroon Pipes en Filters dat beschikbaar is op GitHub.
// This is the "Resize" filter. It handles claim checks from input pipe, performs the
// resize work, and places a claim check in the next pipe for anther filter to handle.
[Function(nameof(ResizeFilter))]
[QueueOutput("pipe-fjur", Connection = "pipe")] // Destination pipe claim check
public async Task<string> RunAsync(
[QueueTrigger("pipe-xfty", Connection = "pipe")] string imageFilePath, // Source pipe claim check
[BlobInput("{QueueTrigger}", Connection = "pipe")] BlockBlobClient imageBlob) // Image to process
{
_logger.LogInformation("Processing image {uri} for resizing.", imageBlob.Uri);
// Idempotency checks
// ...
// Download image based on claim check in queue message body
// ...
// Resize the image
// ...
// Write resized image back to storage
// ...
// Create claim check for image and place in the next pipe
// ...
_logger.LogInformation("Image resizing done or not needed. Adding image {filePath} into the next pipe.", imageFilePath);
return imageFilePath;
}
Notitie
Het Spring Integration Framework heeft een implementatie van het pijp- en filterpatroon.
Volgende stappen
Mogelijk vindt u de volgende resources nuttig wanneer u dit patroon implementeert:
- Een demonstratie van het pipes- en filterspatroon met behulp van het scenario voor afbeeldingsverwerking is beschikbaar op GitHub.
- Idempotentiepatronen, op de blog van Jonathan Oliver.
Verwante resources
De volgende patronen zijn mogelijk ook relevant wanneer u dit patroon implementeert:
- Claimcontrolepatroon. Een pijplijn die is geïmplementeerd met behulp van een wachtrij, bevat mogelijk niet het werkelijke item dat via de filters wordt verzonden, maar in plaats daarvan een aanwijzer naar de gegevens die moeten worden verwerkt. In het voorbeeld wordt een claimcontrole in Azure Queue Storage gebruikt voor installatiekopieën die zijn opgeslagen in Azure Blob Storage.
- Patroon Concurrerende consumenten. Een pijplijn kan meerdere exemplaren van een of meer filters bevatten. Deze methode is handig voor het uitvoeren van parallelle exemplaren van trage filters. Hierdoor kan het systeem de belasting verspreiden en de doorvoer verbeteren. Elk exemplaar van een filter concurreert voor invoer met de andere exemplaren, maar twee exemplaren van een filter mogen niet dezelfde gegevens verwerken. In dit artikel wordt de aanpak uitgelegd.
- Patroon Consolidatie van rekenresources. Het is mogelijk om filters te groeperen die samen moeten worden geschaald in één proces. Dit artikel bevat meer informatie over de voordelen en afwegingen van deze strategie.
- Patroon Compenserende transactie. U kunt een filter implementeren als een bewerking die kan worden omgekeerd of die een compenserende bewerking heeft waarmee de status wordt hersteld naar een eerdere versie als er een fout optreedt. In dit artikel wordt uitgelegd hoe u dit patroon kunt implementeren om uiteindelijke consistentie te behouden of te bereiken.
- Pijpen en filters - Patronen voor bedrijfsintegratie.