Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Azure Service Bus
Azure Queue Storage
Azure Event Hubs
Veel services maken gebruik van een beperkingspatroon om de resources te beheren die ze verbruiken, waarbij limieten worden opgelegd voor de snelheid waarmee andere toepassingen of services toegang hebben. U kunt een frequentiebeperkingspatroon gebruiken om beperkingsfouten met betrekking tot deze beperkingslimieten te voorkomen of te minimaliseren en om u te helpen de doorvoer nauwkeuriger te voorspellen.
Een frequentiebeperkingspatroon is geschikt in veel scenario's, maar het is met name handig voor grootschalige terugkerende geautomatiseerde taken, zoals batchverwerking.
Context en probleem
Het uitvoeren van grote aantallen bewerkingen met behulp van een vertraagde service kan leiden tot meer verkeer en doorvoer, omdat u zowel geweigerde aanvragen moet bijhouden als deze bewerkingen opnieuw moet uitvoeren. Naarmate het aantal bewerkingen toeneemt, kan een beperkingslimiet meerdere doorvoeringen van het opnieuw verzenden van gegevens vereisen, wat resulteert in een grotere impact op de prestaties.
Bekijk bijvoorbeeld het volgende naïef opnieuw proberen bij het foutproces voor het opnemen van gegevens in Azure Cosmos DB:
- Uw toepassing moet 10.000 records opnemen in Azure Cosmos DB. Elke record kost 10 aanvraageenheden (RU's) om op te nemen, waarvoor in totaal 100.000 RU's nodig zijn om de taak te voltooien.
- Uw Azure Cosmos DB-exemplaar heeft 20.000 RU's ingerichte capaciteit.
- U verzendt alle 10.000 records naar Azure Cosmos DB. 2000 records worden geschreven en 8.000 records worden geweigerd.
- U verzendt de resterende 8000 records naar Azure Cosmos DB. 2000 records worden geschreven en 6.000 records worden geweigerd.
- U verzendt de resterende 6000 records naar Azure Cosmos DB. 2000 records worden met succes geschreven en 4.000 records worden geweigerd.
- U verzendt de resterende 4000 records naar Azure Cosmos DB. 2000 records worden met succes geschreven en 2000 records worden geweigerd.
- U verzendt de resterende 2000 records naar Azure Cosmos DB. Alles is geschreven.
De opnametaak is voltooid, maar pas na het verzenden van 30.000 records naar Azure Cosmos DB, ook al bestond de hele gegevensset alleen uit 10.000 records.
In het bovenstaande voorbeeld zijn er aanvullende factoren die u moet overwegen:
- Grote aantallen fouten kunnen ook leiden tot extra werk om deze fouten te registreren en de resulterende logboekgegevens te verwerken. Deze naïeve benadering heeft 20.000 fouten verwerkt en het loggen van deze fouten kan verwerkings-, geheugen- of opslagkosten met zich meebrengen.
- Het is niet mogelijk om de beperkingslimieten van de opnameservice te kennen, maar de naïeve benadering kan geen verwachtingen instellen voor hoe lang gegevensverwerking duurt. Met snelheidsbeperking kunt u de benodigde tijd voor opname berekenen.
Solution
Snelheidsbeperking kan het verkeer verminderen en de doorvoer mogelijk verbeteren door het aantal records dat gedurende een bepaalde periode naar een service wordt verzonden, te verminderen.
Een service kan worden beperkt op basis van verschillende metrische gegevens in de loop van de tijd, zoals:
- Het aantal bewerkingen (bijvoorbeeld 20 aanvragen per seconde).
- De hoeveelheid gegevens (bijvoorbeeld 2 GiB per minuut).
- De relatieve kosten van bewerkingen (bijvoorbeeld 20.000 RU's per seconde).
Ongeacht de metrische gegevens die worden gebruikt voor beperking, omvat uw implementatie voor snelheidsbeperking het beheren van het aantal en/of de grootte van bewerkingen die gedurende een bepaalde periode naar de service worden verzonden, waarbij het gebruik van de service wordt geoptimaliseerd terwijl de beperkingscapaciteit niet wordt overschreden.
In scenario's waarin uw API's aanvragen sneller kunnen verwerken dan de beperkte opnameservices toestaan, moet u beheren hoe snel u de service gebruikt. Het behandelen van throttling alleen als een mismatch van gegevenssnelheid en het bufferen van opnameverzoeken totdat de service herstelt, creëert risico's. Als uw toepassing vastloopt in dit scenario, gaan eventuele gebufferde gegevens mogelijk verloren.
U kunt dit risico voorkomen door uw records te verzenden naar een duurzaam berichtensysteem dat uw volledige opnamesnelheid kan verwerken. (Services zoals Azure Event Hubs kunnen miljoenen bewerkingen per seconde verwerken). Vervolgens kunt u een of meer taakprocessors gebruiken om de records van het berichtensysteem te lezen met een gecontroleerde snelheid die binnen de limieten van de beperkte service valt. Als u records naar het berichtensysteem verzendt, kunt u intern geheugen besparen door alleen de records uit de wachtrij te verwijderen die gedurende een bepaald tijdsinterval kunnen worden verwerkt.
Azure biedt verschillende duurzame berichtenservices die u met dit patroon kunt gebruiken, waaronder:
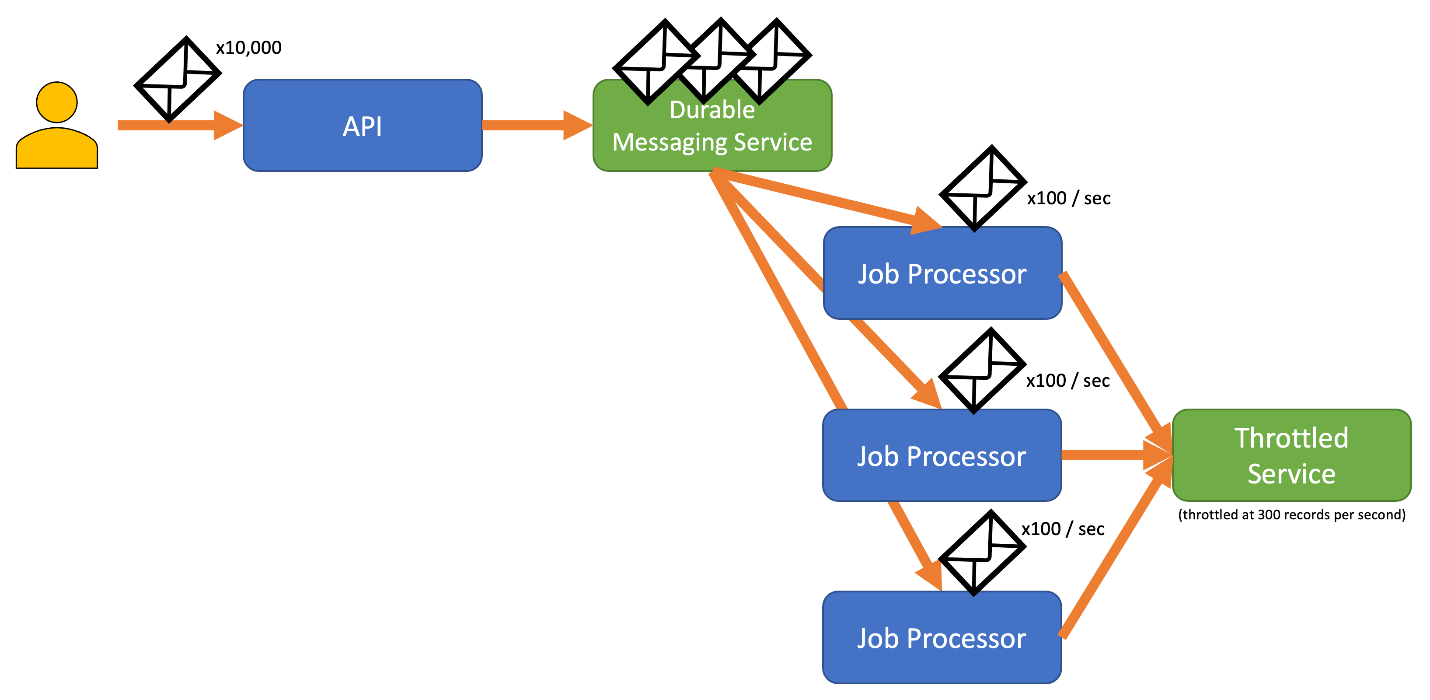
Wanneer u records verzendt, is de periode die u gebruikt voor het vrijgeven van records mogelijk verfijnder dan de periode waarop de service beperkingen toepast. Systemen stellen vaak beperkingen in op basis van tijdspanne die u gemakkelijk kunt begrijpen en ermee kunt werken. Voor de computer waarop een service wordt uitgevoerd, kunnen deze tijdsbestekken echter erg lang zijn in vergelijking met hoe snel informatie kan worden verwerkt. Een systeem kan bijvoorbeeld per seconde of per minuut worden beperkt, maar meestal wordt de code verwerkt in de volgorde van nanoseconden of milliseconden.
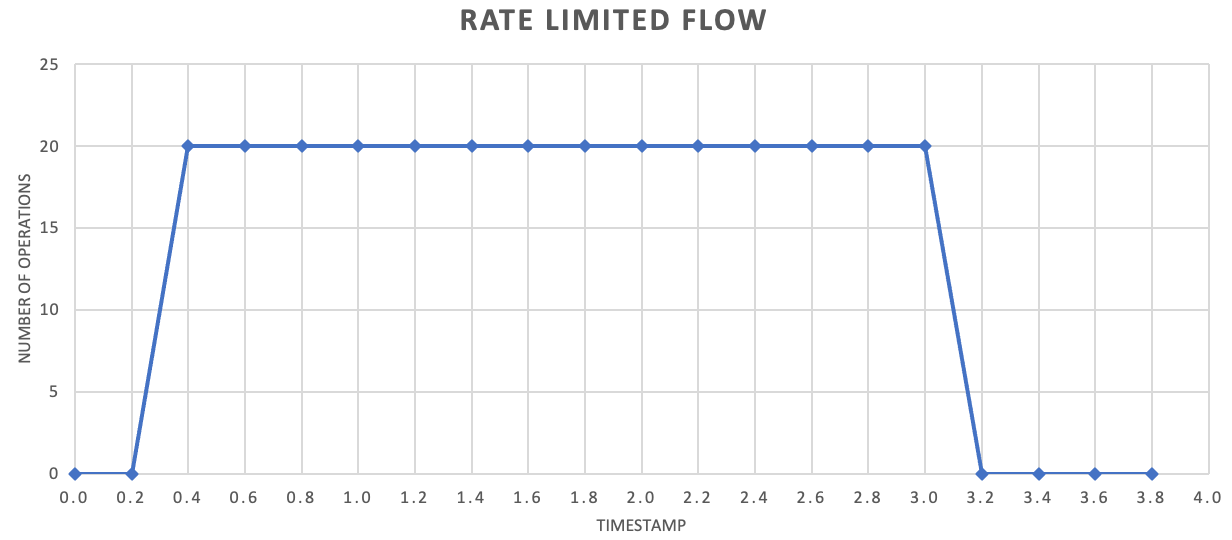
Hoewel dit niet vereist is, wordt het vaak aanbevolen om kleinere hoeveelheden records vaker te verzenden om de doorvoer te verbeteren. Dus in plaats van te proberen om items één keer per seconde of eenmaal per minuut te batcheren, kunt u gedetailleerder zijn dan dat om uw resourceverbruik (geheugen, CPU en netwerk) met een meer gelijkmatige snelheid te laten stromen, waardoor potentiële knelpunten worden voorkomen vanwege plotselinge pieken in aanvragen. Als een service bijvoorbeeld 100 bewerkingen per seconde toestaat, kan de implementatie van een frequentielimieter aanvragen gelijkmatig uitzetten door elke 200 milliseconden 20 bewerkingen uit te brengen, zoals wordt weergegeven in de volgende grafiek.
Daarnaast is het soms noodzakelijk dat meerdere niet-gecoördineerde processen een beperkte service delen. Als u snelheidsbeperking in dit scenario wilt implementeren, kunt u de capaciteit van de service logisch partitioneren en vervolgens een gedistribueerd wederzijds uitsluitingssysteem gebruiken om exclusieve vergrendelingen op deze partities te beheren. De niet-gecoördineerde processen kunnen vervolgens concurreren voor vergrendelingen op deze partities wanneer ze capaciteit nodig hebben. Voor elke partitie waarvoor een proces een vergrendeling bevat, krijgt het een bepaalde hoeveelheid capaciteit.
Als het vertraagde systeem bijvoorbeeld 500 aanvragen per seconde toestaat, kunt u 20 partities maken die elk 25 aanvragen per seconde waard zijn. Als een proces nodig is om 100 aanvragen uit te geven, kan het het gedistribueerde wederzijdse uitsluitingssysteem voor vier partities vragen. Het systeem kan twee partities gedurende 10 seconden verlenen. Het proces zou vervolgens een frequentielimiet hebben van 50 aanvragen per seconde, de taak in twee seconden voltooien en vervolgens de vergrendeling vrijgeven.
Een manier om dit patroon te implementeren, is het gebruik van Azure Storage. In dit scenario maakt u één 0-byte-blob per logische partitie in een container. Uw toepassingen kunnen dan gedurende korte tijd exclusieve leases verkrijgen op basis van deze blobs (bijvoorbeeld 15 seconden). Voor elke lease wordt een toepassing verleend, kan deze de capaciteit van die partitie gebruiken. De toepassing moet vervolgens de leasetijd bijhouden, zodat deze, wanneer deze verloopt, kan stoppen met het gebruik van de capaciteit die is verleend. Bij het implementeren van dit patroon wilt u vaak dat elk proces probeert een willekeurige partitie te leasen wanneer deze capaciteit nodig heeft.
Als u de latentie verder wilt verminderen, kunt u voor elk proces een kleine hoeveelheid exclusieve capaciteit toewijzen. Een proces zou vervolgens alleen een lease op gedeelde capaciteit willen verkrijgen als deze de gereserveerde capaciteit moet overschrijden.
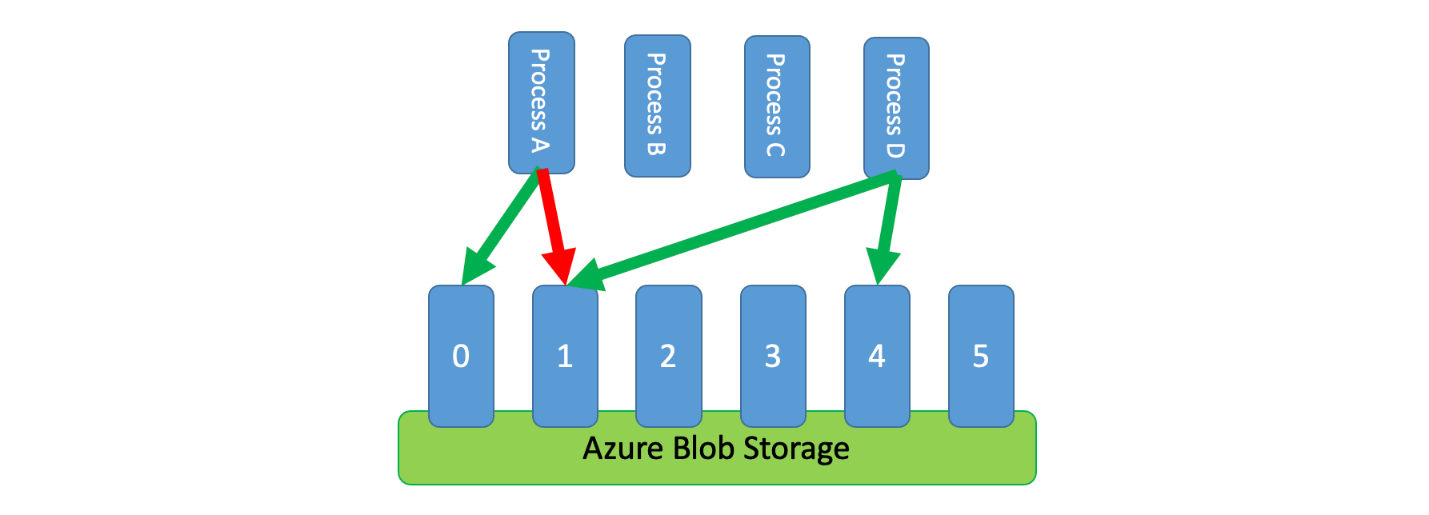
Als alternatief voor Azure Storage kunt u dit type leasebeheersysteem ook implementeren met behulp van technologieën zoals Zookeeper, Consul, enzovoort, Redis/Redsync en andere.
Problemen en overwegingen
Houd rekening met het volgende bij het bepalen hoe u dit patroon implementeert:
- Hoewel het frequentiebeperkingspatroon het aantal beperkingsfouten kan verminderen, moet uw toepassing nog steeds alle beperkingsfouten die zich kunnen voordoen, correct verwerken.
- Als uw toepassing meerdere werkstromen heeft die toegang hebben tot dezelfde beperkte service, moet u deze allemaal integreren in uw strategie voor snelheidsbeperking. U kunt bijvoorbeeld ondersteuning bieden voor het bulksgewijs laden van records in een database, maar ook voor records in diezelfde database. U kunt capaciteit beheren door ervoor te zorgen dat alle werkstromen worden beperkt door hetzelfde frequentiebeperkingsmechanisme. U kunt ook afzonderlijke pools met capaciteit reserveren voor elke workstream.
- De beperkte service kan in meerdere toepassingen worden gebruikt. In sommige, maar niet alle gevallen is het mogelijk om dat gebruik te coördineren (zoals hierboven wordt weergegeven). Als u een groter dan verwacht aantal beperkingsfouten ziet, kan dit een teken zijn van conflicten tussen toepassingen die toegang hebben tot een service. Als dit het geval is, moet u overwegen om de doorvoer die wordt opgelegd door uw snelheidsbeperkingsmechanisme tijdelijk te verminderen totdat het gebruik van andere toepassingen lager wordt.
Wanneer dit patroon gebruiken
U gebruikt dit patroon voor het volgende:
- Verminder beperkingsfouten die worden gegenereerd door een beperkte service.
- Verminder het verkeer in vergelijking met een naïef opnieuw proberen bij foutbenadering.
- Verminder het geheugenverbruik door records alleen te verwijderen wanneer er capaciteit is om ze te verwerken.
Werklastontwerp
Een architect moet evalueren hoe het patroon snelheidsbeperking kan worden gebruikt in het ontwerp van hun workload om de doelstellingen en principes te verhelpen die worden behandeld in de pijlers van het Azure Well-Architected Framework. Voorbeeld:
| Pillar | Hoe dit patroon ondersteuning biedt voor pijlerdoelen |
|---|---|
| Beslissingen over betrouwbaarheidsontwerp helpen uw workload bestand te worden tegen storingen en ervoor te zorgen dat deze herstelt naar een volledig functionerende status nadat er een fout is opgetreden. | Deze tactiek beschermt de klant door de beperkingen en kosten van de communicatie met een service te erkennen en te respecteren wanneer de service wenst te voorkomen dat overmatig gebruik wordt gebruikt. - RE:07 Zelfbehoud |
Net als bij elke ontwerpbeslissing moet u rekening houden met eventuele compromissen ten opzichte van de doelstellingen van de andere pijlers die met dit patroon kunnen worden geïntroduceerd.
Example
Met de volgende voorbeeldtoepassing kunnen gebruikers records van verschillende typen verzenden naar een API. Er is een unieke taakprocessor voor elk recordtype dat de volgende stappen uitvoert:
- Validation
- Enrichment
- Invoeging van de record in de database
Alle onderdelen van de toepassing (API, taakprocessor A en taakprocessor B) zijn afzonderlijke processen die onafhankelijk kunnen worden geschaald. De processen communiceren niet rechtstreeks met elkaar.
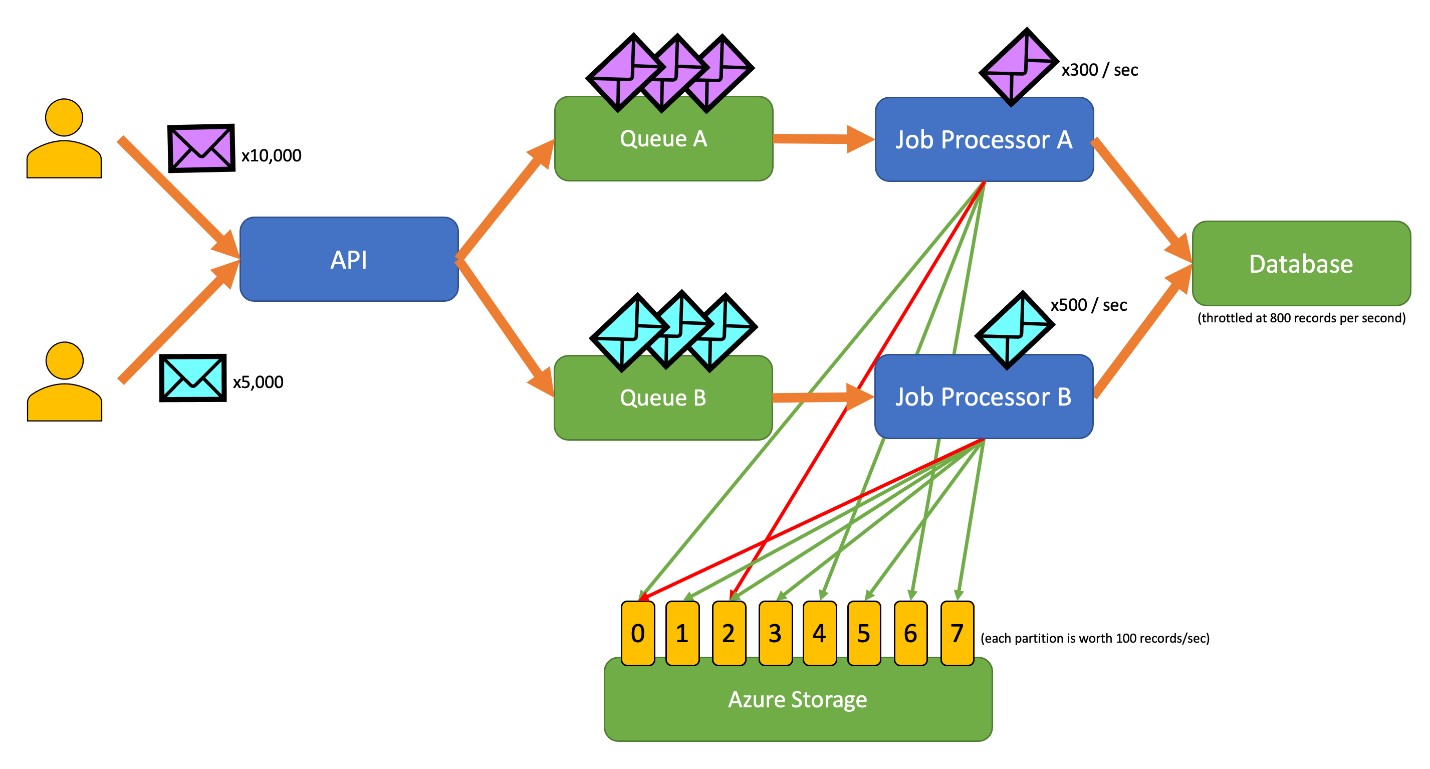
Dit diagram bevat de volgende werkstroom:
- Een gebruiker verzendt 10.000 records van het type A naar de API.
- De API enqueueert die 10.000 records in Wachtrij A.
- Een gebruiker verzendt 5000 records van het type B naar de API.
- De API gebruikt deze 5000 records in wachtrij B.
- Jobprocessor A ziet dat Queue A records heeft en probeert een exclusieve lease op blob 2 te verkrijgen.
- Jobprocessor B ziet dat Queue B records heeft en probeert een exclusieve lease op blob 2 te verkrijgen.
- Taakverwerker A kan de lease niet verkrijgen.
- Jobprocessor B verkrijgt de lease op blob 2 gedurende 15 seconden. Aanvragen voor de database kunnen nu met een snelheid van 100 per seconde worden beperkt.
- Taakprocessor B verwijdert 100 records uit wachtrij B en schrijft ze.
- Een seconde passeert.
- JobProcessor A ziet dat Queue A meer records heeft en probeert een exclusieve lease op blob 6 te verkrijgen.
- Taakprocessor B ziet dat Wachtrij B meer records heeft en probeert een exclusieve lease op blob 3 te verkrijgen.
- JobProcessor A verkrijgt de lease op blob 6 gedurende 15 seconden. Aanvragen voor de database kunnen nu met een snelheid van 100 per seconde worden beperkt.
- Jobprocessor B verkrijgt de lease op blob 3 gedurende 15 seconden. Aanvragen voor de database kunnen nu worden beperkt met een snelheid van 200 per seconde. (Het bevat ook de lease voor blob 2.)
- Taakprocessor A verwijdert 100 records uit wachtrij A en schrijft ze.
- Taakprocessor B verwijdert 200 records uit wachtrij B en schrijft ze.
- Een seconde passeert.
- Jobprocessor A ziet dat Queue A meer records heeft en probeert een exclusieve lease op blob 0 te verkrijgen.
- JobProcessor B ziet dat Queue B meer records heeft en probeert een exclusieve lease op blob 1 te verkrijgen.
- JobProcessor A verkrijgt de lease op blob 0 gedurende 15 seconden. Aanvragen voor de database kunnen nu worden beperkt met een snelheid van 200 per seconde. (Het bevat ook de lease voor blob 6.)
- JobProcessor B verkrijgt de lease op blob 1 gedurende 15 seconden. Aanvragen voor de database kunnen nu worden beperkt met een snelheid van 300 per seconde. (Het bevat ook de lease voor blobs 2 en 3.)
- Taakprocessor A verwijdert 200 records uit wachtrij A en schrijft ze.
- Taakprocessor B verwijdert 300 records uit wachtrij B en schrijft ze.
- Enzovoort...
Na 15 seconden worden een of beide taken nog steeds niet voltooid. Wanneer de leases verlopen, moet een processor ook het aantal aanvragen verminderen dat het uit de wachtrij en schrijfbewerkingen verwijdert.
 Implementaties van dit patroon zijn beschikbaar in verschillende programmeertalen:
Implementaties van dit patroon zijn beschikbaar in verschillende programmeertalen:
Verwante middelen
De volgende patronen en richtlijnen zijn mogelijk ook relevant bij de implementatie van dit patroon:
- Throttling. Het hier besproken frequentiebeperkingspatroon wordt doorgaans geïmplementeerd als reactie op een service die wordt beperkt.
- Retry. Wanneer aanvragen voor een beperkte service leiden tot beperkingsfouten, is het over het algemeen geschikt om deze na een geschikt interval opnieuw te proberen.
Load Leveling op basis van wachtrij is vergelijkbaar, maar verschilt op verschillende manieren van het frequentiebeperkingspatroon:
- Snelheidsbeperking hoeft niet noodzakelijkerwijs wachtrijen te gebruiken om de belasting te beheren, maar moet wel gebruikmaken van een duurzame berichtenservice. Een frequentiebeperkingspatroon kan bijvoorbeeld gebruikmaken van services zoals Apache Kafka of Azure Event Hubs.
- Het frequentiebeperkingspatroon introduceert het concept van een gedistribueerd wederzijds uitsluitingssysteem op partities, waarmee u capaciteit kunt beheren voor meerdere niet-gecoördineerde processen die communiceren met dezelfde beperkte service.
- Een patroon voor load leveling op basis van wachtrijen is van toepassing wanneer er sprake is van een niet-overeenkomende prestaties tussen services of om de tolerantie te verbeteren. Dit maakt het een breder patroon dan snelheidsbeperking, wat meer specifiek betrekking heeft op het efficiënt openen van een beperkte service.