Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Azure Cosmos DB
Azure Event Hubs
Azure Monitor
Azure Stream Analytics
Deze referentiearchitectuur toont een end-to-end stroomverwerkingspijplijn. De pijplijn neemt gegevens op uit twee bronnen, correleert records in de twee streams en berekent een doorlopend gemiddelde gedurende een tijdvenster. De resultaten worden opgeslagen voor verdere analyse.
Architectuur

Een Visio-bestand van deze architectuur downloaden.
Werkproces
De architectuur bestaat uit de volgende onderdelen:
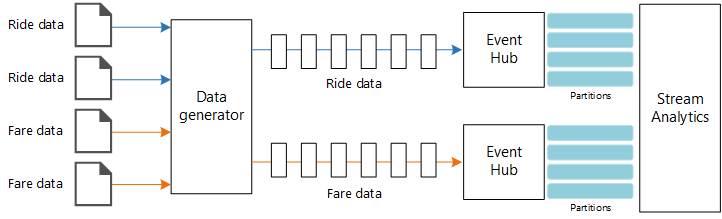
Gegevensbronnen. In deze architectuur zijn er twee gegevensbronnen die in realtime gegevensstromen genereren. De eerste stream bevat ritgegevens en de tweede bevat tariefinformatie. De referentiearchitectuur bevat een gesimuleerde gegevensgenerator die uit een set statische bestanden leest en de gegevens naar Event Hubs pusht. In een echte toepassing zijn de gegevensbronnen apparaten die in de taxi's zijn geïnstalleerd.
Azure Event Hubs. Event Hubs is een gebeurtenisopnameservice. Deze architectuur maakt gebruik van twee Event Hub-exemplaren, één voor elke gegevensbron. Elke gegevensbron verzendt een gegevensstroom naar de bijbehorende Event Hub.
Azure Stream Analytics. Stream Analytics is een engine voor gebeurtenisverwerking. Een Stream Analytics-taak leest de gegevensstromen van de twee Event Hubs en voert stroomverwerking uit.
Azure Cosmos DB-. De uitvoer van de Stream Analytics-taak is een reeks records, die zijn geschreven als JSON-documenten naar een Azure Cosmos DB-documentdatabase.
Microsoft Power BI. Power BI is een suite met hulpprogramma's voor bedrijfsanalyse voor het analyseren van gegevens voor zakelijke inzichten. In deze architectuur worden de gegevens uit Azure Cosmos DB geladen. Hierdoor kunnen gebruikers de volledige set historische gegevens analyseren die zijn verzameld. U kunt de resultaten ook rechtstreeks vanuit Stream Analytics naar Power BI streamen voor een realtime weergave van de gegevens. Zie Realtime streaming in Power BI voor meer informatie.
Azure Monitor. Azure Monitor verzamelt metrische prestatiegegevens over de Azure-services die in de oplossing zijn geïmplementeerd. Door deze in een dashboard te visualiseren, krijgt u inzicht in de status van de oplossing.
Details van het scenario
Scenario: Een taxibedrijf verzamelt gegevens over elke taxirit. Voor dit scenario wordt ervan uitgegaan dat er twee afzonderlijke apparaten zijn die gegevens verzenden. De taxi heeft een meter die informatie over elke rit verzendt: de duur, afstand en ophaal- en afleverlocaties. Een afzonderlijk apparaat accepteert betalingen van klanten en verzendt gegevens over tarieven. Het taxibedrijf wil de gemiddelde tip per mijl berekenen, in realtime, om trends te herkennen.
Potentiële gebruikscases
Deze oplossing is geoptimaliseerd voor het retailscenario.
Gegevensopname
Voor het simuleren van een gegevensbron maakt deze referentiearchitectuur gebruik van de gegevensset New York City Taxi Data[1]. Deze gegevensset bevat gegevens over taxiritten in New York City gedurende een periode van vier jaar (2010-2013). Het bevat twee typen records: ritgegevens en tariefgegevens. Ritgegevens omvatten reisduur, reisafstand en ophaal- en afleverlocatie. Tariefgegevens omvatten tarief-, belasting- en fooibedragen. Algemene velden in beide recordtypen zijn het medaillenummer, de hacklicentie en de leverancier-ID. Samen identificeren deze drie velden een taxi plus een chauffeur. De gegevens worden opgeslagen in CSV-indeling.
[1] Donovan, Brian; Work, Dan (2016): Gegevens van taxiritten in New York City (2010-2013). Universiteit van Illinois bij Urbana-Champaign. https://doi.org/10.13012/J8PN93H8
De gegevensgenerator is een .NET toepassing waarmee de records worden gelezen en naar Azure Event Hubs worden verzonden. De generator verzendt ritgegevens in JSON-indeling en tariefgegevens in CSV-indeling.
Event Hubs maakt gebruik van partities om de gegevens te segmenteren. Met partities kan een consument elke partitie parallel lezen. Wanneer u gegevens naar Event Hubs verzendt, kunt u de partitiesleutel expliciet opgeven. Anders worden records volgens het round-robin-principe toegewezen aan partities.
In dit specifieke scenario moeten ritgegevens en tariefgegevens uiteindelijk in dezelfde partitie-id terechtkomen voor een bepaalde taxi. Hierdoor kan Stream Analytics een mate van parallelle uitvoering toepassen wanneer deze de twee streams correleert. Een record in partitie n van de ritgegevens komt overeen met een record in partitie n van de tariefgegevens.
In de gegevensgenerator heeft het algemene gegevensmodel voor beide recordtypen een PartitionKey eigenschap die de samenvoeging is van Medallion, HackLicenseen VendorId.
public abstract class TaxiData
{
public TaxiData()
{
}
[JsonProperty]
public long Medallion { get; set; }
[JsonProperty]
public long HackLicense { get; set; }
[JsonProperty]
public string VendorId { get; set; }
[JsonProperty]
public DateTimeOffset PickupTime { get; set; }
[JsonIgnore]
public string PartitionKey
{
get => $"{Medallion}_{HackLicense}_{VendorId}";
}
Deze eigenschap wordt gebruikt om een expliciete partitiesleutel op te geven bij het verzenden naar Event Hubs:
using (var client = pool.GetObject())
{
return client.Value.SendAsync(new EventData(Encoding.UTF8.GetBytes(
t.GetData(dataFormat))), t.PartitionKey);
}
Stroomverwerking
De stroomverwerkingstaak wordt gedefinieerd met behulp van een SQL-query met verschillende afzonderlijke stappen. De eerste twee stappen selecteren records uit de twee invoerstromen.
WITH
Step1 AS (
SELECT PartitionId,
TRY_CAST(Medallion AS nvarchar(max)) AS Medallion,
TRY_CAST(HackLicense AS nvarchar(max)) AS HackLicense,
VendorId,
TRY_CAST(PickupTime AS datetime) AS PickupTime,
TripDistanceInMiles
FROM [TaxiRide] PARTITION BY PartitionId
),
Step2 AS (
SELECT PartitionId,
medallion AS Medallion,
hack_license AS HackLicense,
vendor_id AS VendorId,
TRY_CAST(pickup_datetime AS datetime) AS PickupTime,
tip_amount AS TipAmount
FROM [TaxiFare] PARTITION BY PartitionId
),
In de volgende stap worden de twee invoerstromen samengevoegd om overeenkomende records uit elke stream te selecteren.
Step3 AS (
SELECT tr.TripDistanceInMiles,
tf.TipAmount
FROM [Step1] tr
PARTITION BY PartitionId
JOIN [Step2] tf PARTITION BY PartitionId
ON tr.PartitionId = tf.PartitionId
AND tr.PickupTime = tf.PickupTime
AND DATEDIFF(minute, tr, tf) BETWEEN 0 AND 15
)
Met deze query worden records samengevoegd in een set velden waarmee overeenkomende records (PartitionId en PickupTime) uniek worden geïdentificeerd.
Notitie
We willen dat de TaxiRide en TaxiFare streams worden samengevoegd door de unieke combinatie van Medallion, HackLicenseVendorId en PickupTime. In dit geval dekt de PartitionId de Medallion, HackLicense en VendorId velden, maar dit mag in het algemeen niet als het geval worden beschouwd.
In Stream Analytics zijn joins tijdelijk, wat betekent dat records binnen een bepaald tijdsbestek worden samengevoegd. Anders moet de taak mogelijk voor onbepaalde tijd wachten op een overeenkomst. De DATEDIFF-functie geeft aan hoe ver twee overeenkomende records in tijd van elkaar gescheiden kunnen zijn om te voldoen aan een overeenkomst.
De laatste stap in de taak berekent de gemiddelde fooi per mijl, gegroepeerd binnen een schuivend venster van vijf minuten.
SELECT System.Timestamp AS WindowTime,
SUM(tr.TipAmount) / SUM(tr.TripDistanceInMiles) AS AverageTipPerMile
INTO [TaxiDrain]
FROM [Step3] tr
GROUP BY HoppingWindow(Duration(minute, 5), Hop(minute, 1))
Stream Analytics biedt verschillende vensterfuncties. Een verspringend venster wordt in de tijd met een vaste tijdsperiode verplaatst, in dit geval één minuut per hop. Het resultaat is het berekenen van een zwevend gemiddelde in de afgelopen vijf minuten.
In de architectuur die hier wordt weergegeven, worden alleen de resultaten van de Stream Analytics-taak opgeslagen in Azure Cosmos DB. Voor een scenario met big data kunt u ook Event Hubs Capture gebruiken om de onbewerkte gebeurtenisgegevens op te slaan in Azure Blob Storage. Door de onbewerkte gegevens te bewaren, kunt u op een later tijdstip batchquery's uitvoeren op uw historische gegevens om nieuwe inzichten uit de gegevens af te leiden.
Overwegingen
Met deze overwegingen worden de pijlers van het Azure Well-Architected Framework geïmplementeerd. Dit is een set richtlijnen die kunnen worden gebruikt om de kwaliteit van een workload te verbeteren. Zie Microsoft Azure Well-Architected Framework voor meer informatie.
Kostenoptimalisatie
Kostenoptimalisatie gaat over manieren om onnodige uitgaven te verminderen en operationele efficiëntie te verbeteren. Zie controlelijst ontwerpbeoordeling voor kostenoptimalisatievoor meer informatie.
Gebruik de Azure-prijscalculator om een schatting van de kosten te maken. Hier volgen enkele overwegingen voor services die in deze referentiearchitectuur worden gebruikt.
Azure Stream Analytics
Azure Stream Analytics heeft een prijs voor het aantal streaming-eenheden ($ 0,11/uur) dat nodig is om de gegevens in de service te verwerken.
Stream Analytics kan duur zijn als u de gegevens niet in realtime of kleine hoeveelheden gegevens verwerkt. Voor deze gebruiksscenario's kunt u overwegen om Azure Functions of Logic Apps te gebruiken om gegevens van Azure Event Hubs naar een gegevensarchief te verplaatsen.
Azure Event Hubs en Azure Cosmos DB
Zie de streamverwerking met azure Databricks-referentiearchitectuur voor azure Event Hubs en Azure Cosmos DB- kostenoverwegingen.
Operationele uitmuntendheid
Operational Excellence behandelt de operationele processen die een toepassing implementeren en deze in productie houden. Zie controlelijst ontwerpbeoordeling voor Operational Excellencevoor meer informatie.
Controleren
Bij elke oplossing voor stroomverwerking is het belangrijk om de prestaties en status van het systeem te bewaken. Azure Monitor verzamelt metrische gegevens en diagnostische logboeken voor de Azure-services die in de architectuur worden gebruikt. Azure Monitor is ingebouwd in het Azure-platform en vereist geen extra code in uw toepassing.
Een van de volgende waarschuwingssignalen geeft aan dat u de relevante Azure-resource moet uitschalen:
- Event Hubs beperkt aanvragen of ligt dicht bij het dagelijkse berichtquotum.
- De Stream Analytics-taak maakt consistent gebruik van meer dan 80% van de toegewezen streaming-eenheden (SU).
- Azure Cosmos DB begint aanvragen te beperken.
De referentiearchitectuur bevat een aangepast dashboard dat is geïmplementeerd in Azure Portal. Nadat u de architectuur hebt geïmplementeerd, kunt u het dashboard bekijken door Azure Portal te openen en te TaxiRidesDashboard selecteren in de lijst met dashboards. Zie Programmatisch Azure-dashboards maken en implementeren voor meer informatie over het maken en implementeren van aangepaste dashboards in Azure Portal.
In de volgende afbeelding ziet u het dashboard nadat de Stream Analytics-taak ongeveer een uur is uitgevoerd.
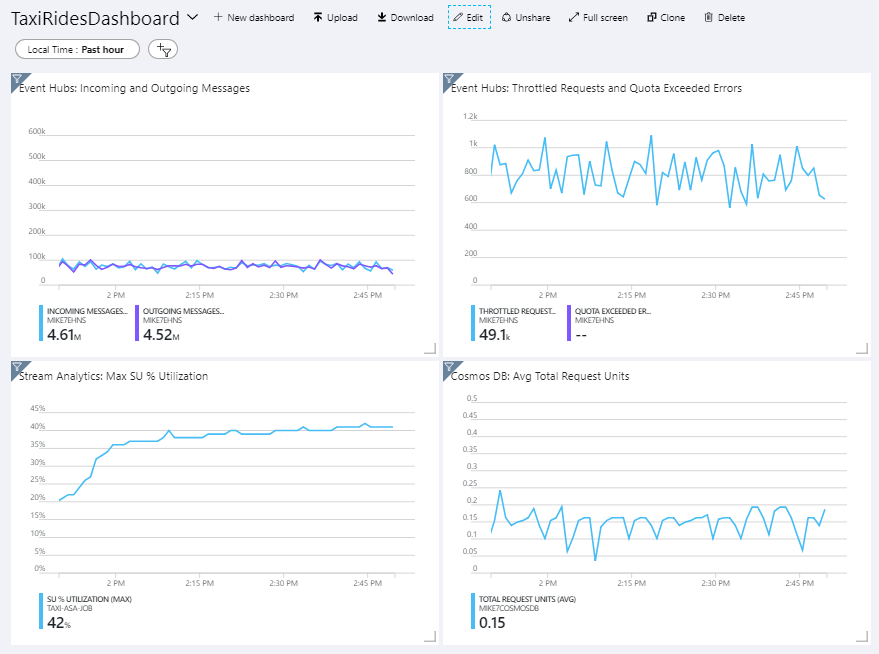
In het deelvenster linksonder ziet u dat het SU-verbruik voor de Stream Analytics-taak in de eerste 15 minuten stijgt en vervolgens stabiel wordt. Dit is een typisch patroon omdat de taak een stabiele status bereikt.
Merk op dat Event Hubs aanvragen beperkt, zoals weergegeven in het deelvenster rechtsboven. Een af en toe vertraagde aanvraag is geen probleem, omdat de Event Hubs-client-SDK automatisch opnieuw probeert wanneer er een beperkingsfout optreedt. Als u echter consistente snelheidsbeperkingsfouten ziet, betekent dit dat de Event Hub extra doorvoereenheden nodig heeft. In de volgende grafiek ziet u een testuitvoering met de auto-schaalfunctie van Event Hubs, waarmee de doorvoereenheden automatisch indien nodig worden uitgeschaald.
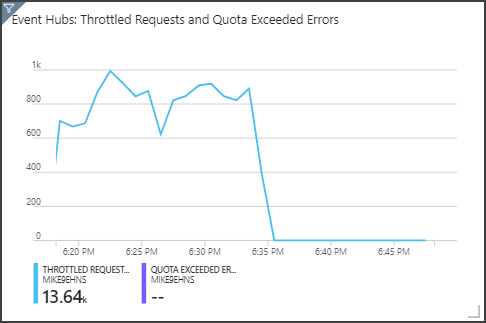
De automatische opblaasfunctie werd rond 06:35 geactiveerd. U kunt de 'p-drop' in begrensde aanvragen zien, omdat Event Hubs automatisch wordt opgeschaald naar 3 doorvoereenheden.
Interessant is dat dit het neveneffect had van het verhogen van het SU-gebruik in de Stream Analytics-taak. Door throttling heeft Event Hubs kunstmatig de opnamesnelheid voor de Stream Analytics-taak verlaagd. Het is eigenlijk gebruikelijk dat het oplossen van een knelpunt in prestaties een ander knelpunt weergeeft. In dit geval heeft het toewijzen van extra SU voor de Stream Analytics-taak het probleem opgelost.
DevOps
Maak afzonderlijke resourcegroepen voor productie-, ontwikkelings- en testomgevingen. Met afzonderlijke resourcegroepen kunt u eenvoudiger implementaties beheren, testimplementaties verwijderen en toegangsrechten verlenen.
Gebruik een Azure Resource Manager-sjabloon om de Azure-resources te implementeren die volgen op het proces infrastructuur als code (IaC). Met sjablonen is het automatiseren van implementaties met Behulp van Azure DevOps Services of andere CI/CD-oplossingen eenvoudiger.
Plaats elke workload in een afzonderlijke implementatiesjabloon en sla de resources op in broncodebeheersystemen. U kunt de sjablonen samen of afzonderlijk implementeren als onderdeel van een CI/CD-proces, waardoor het automatiseringsproces eenvoudiger wordt.
In deze architectuur worden Azure Event Hubs, Log Analytics en Azure Cosmos DB geïdentificeerd als één workload. Deze resources zijn opgenomen in één ARM-sjabloon.
Overweeg om uw workloads in fasen te plannen. Implementeer in verschillende fasen en voer validatiecontroles uit in elke fase voordat u doorgaat naar de volgende fase. Op die manier kunt u op een zeer gecontroleerde manier updates naar uw productieomgevingen pushen en onverwachte implementatieproblemen minimaliseren.
Overweeg om Azure Monitor te gebruiken om de prestaties van uw stroomverwerkingspijplijn te analyseren.
Zie de pijler operationele uitmuntendheid in Microsoft Azure Well-Architected Framework voor meer informatie.
Prestatie-efficiëntie
Prestatie-efficiëntie is de mogelijkheid van uw workload om te schalen om te voldoen aan de eisen die gebruikers op een efficiënte manier stellen. Zie controlelijst ontwerpbeoordeling voor prestatie-efficiëntievoor meer informatie.
Event Hubs
De doorvoercapaciteit van Event Hubs wordt gemeten in doorvoereenheden. U kunt een Event Hub automatisch schalen door automatische vergroting in te schakelen, waardoor de doorvoereenheden automatisch worden geschaald op basis van het verkeer, tot een geconfigureerd maximum.
Streamanalyse
Voor Stream Analytics worden de rekenresources die aan een taak zijn toegewezen, gemeten in streaming-eenheden. Stream Analytics-taken worden het beste geschaald als de taak kan worden geparallelliseerd. Op die manier kan Stream Analytics de taak verdelen over meerdere rekenknooppunten.
Gebruik voor Event Hubs-invoer het PARTITION BY trefwoord om de Stream Analytics-taak te partitioneren. De gegevens worden onderverdeeld in subsets op basis van de Event Hubs-partities.
Vensterfuncties en tijdelijke koppelingen vereisen extra SU. Gebruik, indien mogelijk, PARTITION BY zodat elke partitie afzonderlijk wordt verwerkt. Zie Streaming-eenheden begrijpen en aanpassen.
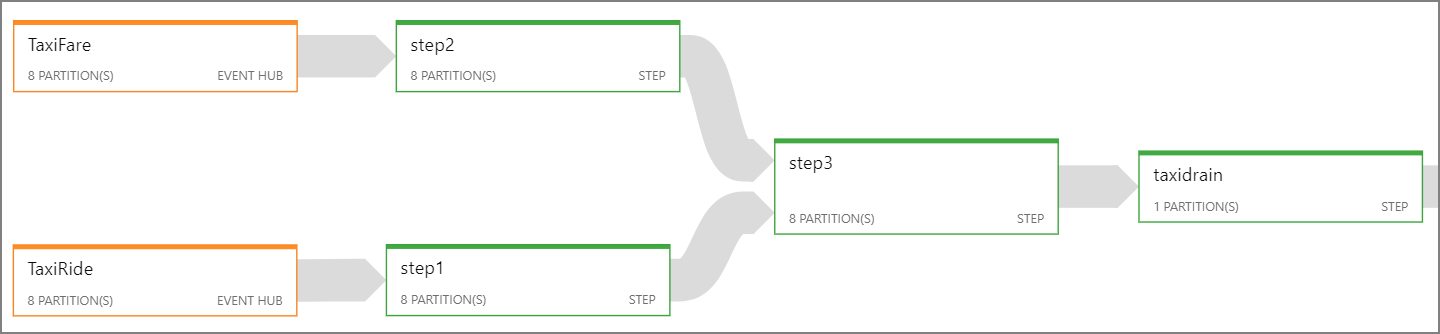
Als het niet mogelijk is om de hele Stream Analytics-taak te parallelliseren, probeert u de taak in meerdere stappen op te splitsen, te beginnen met een of meer parallelle stappen. Op die manier kunnen de eerste stappen parallel worden uitgevoerd. Bijvoorbeeld in deze referentiearchitectuur:
- Stap 1 en 2 zijn
SELECTinstructies die records binnen één partitie selecteren. - Stap 3 voert een gepartitioneerde join uit in twee invoerstromen. Deze stap maakt gebruik van het feit dat overeenkomende records dezelfde partitiesleutel delen en dus gegarandeerd dezelfde partitie-id hebben in elke invoerstroom.
- Stap 4 voegt alle partities samen. Deze stap kan niet worden geparallelliseerd.
Gebruik het Stream Analytics-taakdiagram om te zien hoeveel partities aan elke stap in de taak zijn toegewezen. In het volgende diagram ziet u het taakdiagram voor deze referentiearchitectuur:
Azure Cosmos DB
Doorvoercapaciteit voor Azure Cosmos DB wordt gemeten in aanvraageenheden (RU's). Elke Azure Cosmos DB-container vereist een partitionsleutel en elk document moet die sleutel bevatten. Eén fysieke partitie kan maximaal 10.000 RU/s verwerken, dus Azure Cosmos DB verdeelt gegevens op basis van de partitiesleutel over meerdere fysieke partities om verder te schalen dan die limiet. Kies een partitiesleutel die zowel opslag als aanvraagvolume gelijkmatig verspreidt om dynamische partities te voorkomen.
In deze referentiearchitectuur worden nieuwe documenten slechts één keer per minuut gemaakt (het interval van het hoppingvenster), zodat de doorvoervereisten laag zijn. Selecteer zelfs een partitiesleutel die ondersteuning biedt voor uw verwachte querypatronen en groei.