Functies en terminologie in Azure Event Hubs
Azure Event Hubs is een schaalbare service voor gebeurtenisverwerking die grote hoeveelheden gebeurtenissen en gegevens opneemt en verwerkt, met lage latentie en hoge betrouwbaarheid. Zie Wat is Event Hubs?voor een algemeen overzicht van de service.
Dit artikel bouwt voort op de informatie in het overzichtsartikel en biedt technische en implementatiedetails over Event Hubs-onderdelen en -functies.
Naamruimte
Een Event Hubs-naamruimte is een beheercontainer voor Event Hubs (of onderwerpen, in Kafka-parlance). Het biedt dns-geïntegreerde netwerkeindpunten en een reeks functies voor toegangsbeheer en netwerkintegratiebeheer, zoals IP-filtering, service-eindpunt voor virtuele netwerken en Private Link.

Partities
Event Hubs organiseert reeksen gebeurtenissen die naar een Event Hub worden verzonden naar een of meer partities. Als er nieuwere gebeurtenissen plaatsvinden, worden deze toegevoegd aan het einde van deze reeks.

Een partitie kan worden beschouwd als een doorvoerlogboek. Partities bevatten gebeurtenisgegevens die de volgende informatie bevatten:
- Hoofdtekst van de gebeurtenis
- Door de gebruiker gedefinieerde eigenschapsverzameling die de gebeurtenis beschrijft
- Metagegevens zoals de offset in de partitie, het nummer in de stroomreeks
- Tijdstempel aan de servicezijde waarop deze is geaccepteerd

Voordelen van het gebruik van partities
Event Hubs is ontworpen om te helpen bij het verwerken van grote hoeveelheden gebeurtenissen. Partitioneren draagt hier op twee manieren aan bij:
- Hoewel Event Hubs een PaaS-service is, is er daaronder een fysieke realiteit. Als u een logboek onderhoudt waarin de volgorde van gebeurtenissen behouden blijft, moeten deze gebeurtenissen samen worden bewaard in de onderliggende opslag en de bijbehorende replica's. Dit resulteert in een doorvoermaximum voor een dergelijk logboek. Partitionering maakt het mogelijk om meerdere parallelle logboeken te gebruiken voor dezelfde Event Hub en daarom de beschikbare capaciteit voor onbewerkte invoer-uitvoer (IO) te vermenigvuldigen.
- Uw eigen toepassingen moeten in staat zijn om het aantal gebeurtenissen dat naar een Event Hub wordt verzonden, bij te houden. Het kan complex zijn en vereist aanzienlijke, uitgeschaalde, parallelle verwerkingscapaciteit. De capaciteit van één proces voor het afhandelen van gebeurtenissen is beperkt, dus u hebt verschillende processen nodig. Partities zijn hoe uw oplossing deze processen voedt en toch zorgt ervoor dat elke gebeurtenis een duidelijke verwerkingseigenaar heeft.
Aantal partities
Het aantal partities wordt opgegeven op het moment van het maken van een Event Hub. Het moet tussen één en het maximumaantal partities zijn dat is toegestaan voor elke prijscategorie. Zie dit artikel voor de limiet voor het aantal partities voor elke laag.
U wordt aangeraden ten minste zoveel partities te kiezen als u verwacht dat deze vereist zijn tijdens de piekbelasting van uw toepassing voor die specifieke Event Hub. Voor andere lagen dan de premium- en toegewezen lagen kunt u het aantal partities voor een Event Hub niet wijzigen nadat deze is gemaakt. Voor een Event Hub in een premium- of toegewezen laag kunt u het aantal partities verhogen nadat deze zijn gemaakt, maar u kunt ze niet verlagen. De distributie van streams tussen partities wordt gewijzigd wanneer deze wordt uitgevoerd als de toewijzing van partitiesleutels aan partities verandert. Probeer deze wijzigingen dus moeilijk te voorkomen als de relatieve volgorde van gebeurtenissen in uw toepassing van belang is.
Het instellen van het aantal partities op de maximaal toegestane waarde is verleidelijk, maar u moet er altijd rekening mee houden dat uw gebeurtenissenstromen zo moeten worden gestructureerd dat u wel kunt profiteren van meerdere partities. Als u absolute volgordebehoud nodig hebt voor alle gebeurtenissen of slechts een handvol substreams, kunt u mogelijk niet profiteren van veel partities. Daarnaast maken veel partities de verwerkingszijde complexer.
Het maakt niet uit hoeveel partities zich in een Event Hub bevinden als het gaat om prijzen. Dit is afhankelijk van het aantal prijseenheden (doorvoereenheden (RU's) voor de standard-laag, verwerkingseenheden (PU's) voor de Premium-laag en capaciteitseenheden (CA's) voor de toegewezen laag) voor de naamruimte of het toegewezen cluster. Een Event Hub van de standard-laag met 32 partities of met één partitie kost bijvoorbeeld exact dezelfde kosten wanneer de naamruimte is ingesteld op één TU-capaciteit. U kunt ook TU's of RU's schalen op uw naamruimte of CA's van uw toegewezen cluster, onafhankelijk van het aantal partities.
Als partitie is een mechanisme voor gegevensorganisatie waarmee u gegevens parallel kunt publiceren en gebruiken. We raden u aan om schaaleenheden (doorvoereenheden voor de standard-laag, verwerkingseenheden voor de Premium-laag of capaciteitseenheden voor de toegewezen laag) en partities te verdelen om optimale schaal te bereiken. Over het algemeen raden we een maximale doorvoer van 1 MB/s per partitie aan. Daarom is een vuistregel voor het berekenen van het aantal partities het delen van de maximale verwachte doorvoer met 1 MB/s. Als uw use-case bijvoorbeeld 20 MB/s vereist, raden we u aan ten minste 20 partities te kiezen om de optimale doorvoer te bereiken.
Als u echter een model hebt waarin uw toepassing een affiniteit met een bepaalde partitie heeft, is het verhogen van het aantal partities niet nuttig. Zie beschikbaarheid en consistentie voor meer informatie.
Toewijzing van gebeurtenissen aan partities
U kunt een partitiesleutel gebruiken om inkomende gebeurtenisgegevens toe te wijzen aan specifieke partities, zodat de gegevens kunnen worden geordend. De partitiesleutel is een door de afzender opgegeven waarde die aan een Event Hub wordt doorgegeven. Het wordt verwerkt via een statische hashfunctie, waarmee de partitietoewijzing wordt gemaakt. Als u bij het publiceren van een gebeurtenis geen partitiesleutel opgeeft, wordt er gebruikgemaakt van round robin-toewijzing.
De gebeurtenisuitgever is alleen op de hoogte van de partitiesleutel en niet van de partitie waarop de gebeurtenissen worden gepubliceerd. Deze ontkoppeling van sleutel en partitie schermt de afzender af, zodat deze niet te veel te weten hoeft te komen over de downstreamverwerking. Goede partitiesleutels zijn bijvoorbeeld een apparaatspecifieke of een gebruikersspecifieke identiteit, maar voor het groeperen van gerelateerde gebeurtenissen in dezelfde partitie kunnen ook andere kenmerken, zoals geografie, worden gebruikt.
Als u een partitiesleutel opgeeft, kunt u gerelateerde gebeurtenissen bijeenhouden in dezelfde partitie en in de exacte volgorde waarin ze zijn aangekomen. De partitiesleutel is een tekenreeks die is afgeleid van uw toepassingscontext en identificeert de relatie tussen de gebeurtenissen. Een reeks gebeurtenissen die wordt geïdentificeerd door een partitiesleutel is een stroom. Een partitie is een multiplex-logboekopslag voor veel van zulke stromen.
Notitie
Hoewel u gebeurtenissen rechtstreeks naar partities kunt verzenden, raden we dit niet aan, met name wanneer hoge beschikbaarheid belangrijk voor u is. Het downgradet de beschikbaarheid van een Event Hub naar partitieniveau. Zie Beschikbaarheid en consistentie voor meer informatie.
Gebeurtenisuitgevers
Elke entiteit die gegevens naar een Event Hub verzendt, is een gebeurtenisuitgever (die synoniem wordt gebruikt met gebeurtenisproducent). Gebeurtenisuitgevers kunnen gebeurtenissen publiceren met HTTPS of AMQP 1.0 of het Kafka-protocol. Gebeurtenisuitgevers gebruiken op Microsoft Entra ID gebaseerde autorisatie met door OAuth2 uitgegeven JWT-tokens of een Sas-token (Shared Access Signature) dat specifiek is voor Event Hub om publicatietoegang te krijgen.
U kunt een gebeurtenis publiceren via AMQP 1.0, het Kafka-protocol of HTTPS. De Event Hubs-service biedt REST API- en .NET-, Java-, Python-, JavaScript- en Go-clientbibliotheken voor het publiceren van gebeurtenissen naar een Event Hub. Voor andere runtimes en platforms kunt u een AMQP 1.0-client gebruiken, zoals Apache Qpid.
De keuze om AMQP of HTTPS te gebruiken, geldt specifiek voor het gebruiksscenario. AMQP vereist de inrichting van een permanente bidirectionele socket naast Transport Layer Security (TLS) of SSL/TLS. AMQP heeft hogere netwerkkosten bij het initialiseren van de sessie, maar HTTPS vereist extra TLS-overhead voor elke aanvraag. AMQP heeft hogere prestaties voor frequente uitgevers en kan veel lagere latenties bereiken wanneer deze worden gebruikt met asynchrone publicatiecode.
U kunt gebeurtenissen afzonderlijk of batchgewijs publiceren. Eén publicatie heeft een limiet van 1 MB, ongeacht of het één gebeurtenis of een batch is. Publicatie-gebeurtenissen die groter zijn dan deze drempelwaarde, worden geweigerd.
Event Hubs-doorvoer wordt geschaald met behulp van partities en toewijzingen van doorvoereenheden. Het is een best practice voor uitgevers om niet op de hoogte te blijven van het specifieke partitioneringsmodel dat is gekozen voor een Event Hub en om alleen een partitiesleutel op te geven die wordt gebruikt om gerelateerde gebeurtenissen consistent toe te wijzen aan dezelfde partitie.
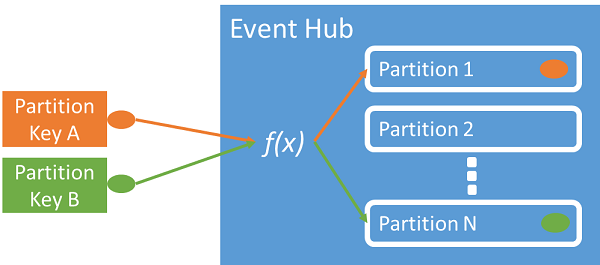
Event Hubs zorgt ervoor dat alle gebeurtenissen die een partitiesleutelwaarde delen, samen worden opgeslagen en geleverd op volgorde van aankomst. De identiteit van de uitgever en de waarde van de partitiesleutel moeten overeenkomen als er partitiesleutels met uitgeversbeleid worden gebruikt. Als deze niet overeenkomen, treedt er een fout op.
Retentie van gebeurtenissen
Gepubliceerde gebeurtenissen worden verwijderd uit een Event Hub op basis van een configureerbaar, op tijd gebaseerd bewaarbeleid. Hier volgen enkele belangrijke punten:
- De standaardwaarde en kortst mogelijke bewaarperiode is 1 uur. Op dit moment kunt u de bewaarperiode alleen instellen in uren in Azure Portal. Met de Resource Manager-sjabloon, PowerShell en CLI kan deze eigenschap slechts in dagen worden ingesteld.
- Voor Event Hubs Standard is de maximale bewaarperiode 7 dagen.
- Voor Event Hubs Premium en Dedicated is de maximale bewaarperiode 90 dagen.
- Als u de bewaarperiode wijzigt, is deze van toepassing op alle gebeurtenissen, inclusief gebeurtenissen die zich al in de Event Hub bevinden.
Event Hubs bewaart gebeurtenissen voor een geconfigureerde bewaartijd die wordt toegepast op het niveau van alle partities. Gebeurtenissen worden automatisch verwijderd wanneer de retentieperiode is bereikt. Als u een bewaarperiode van één dag (24 uur) hebt opgegeven, is de gebeurtenis exact 24 uur nadat deze is geaccepteerd niet meer beschikbaar. U kunt gebeurtenissen niet expliciet verwijderen.
Als u gebeurtenissen wilt archiveren buiten de toegestane bewaarperiode, kunt u ze automatisch laten opslaan in Azure Storage of Azure Data Lake door de functie Event Hubs Capture in te schakelen. Als u dergelijke diepe archieven wilt doorzoeken of analyseren, kunt u ze eenvoudig importeren in Azure Synapse of andere vergelijkbare winkels en analyseplatforms.
De limiet op de retentieperiode voor Event Hubs is om te voorkomen dat grote hoeveelheden historische klantgegevens worden vastgelegd in een archief dat alleen wordt geïndexeerd per timestamp en alleen sequentiële toegang toestaat. De architectuur filosofie hier is dat historische gegevens uitgebreidere indexering en meer directe toegang nodig hebben dan de realtime eventing interface die Event Hubs of Kafka bieden. Gebeurtenisstroomengines zijn niet geschikt voor het spelen van de rol van data lakes of langetermijnarchieven voor gebeurtenisbronnen.
Notitie
Event Hubs is een gebeurtenisstroomengine in realtime en is niet ontworpen om te worden gebruikt in plaats van een database en/of als een permanent archief voor oneindig gehouden gebeurtenisstromen.
Hoe dieper de geschiedenis van een gebeurtenisstroom wordt, hoe meer u hulpindexen nodig hebt om een bepaald historisch segment van een bepaalde stroom te vinden. Inspectie van nettoladingen en indexering van gebeurtenissen valt niet binnen het functiebereik van Event Hubs (of Apache Kafka). Databases en gespecialiseerde analysearchieven en engines zoals Azure Data Lake Store, Azure Data Lake Analytics en Azure Synapse zijn daarom veel beter geschikt voor het opslaan van historische gebeurtenissen.
Event Hubs Capture kan rechtstreeks worden geïntegreerd met Azure Blob Storage en Azure Data Lake Storage. Via die integratie kunnen ook gebeurtenissen rechtstreeks naar Azure Synapse stromen.
Uitgeversbeleid
In Event Hubs kunt u gebeurtenisuitgevers nauwkeurig beheren met behulp van uitgeversbeleid. Uitgeversbeleid bestaat uit runtimefuncties die zijn ontworpen om grote aantallen onafhankelijke gebeurtenisuitgevers mogelijk te maken. Als u uitgeversbeleid implementeert, gebruikt elke uitgever zijn eigen unieke id bij het publiceren van gebeurtenissen naar een Event Hub. Hierbij wordt het volgende mechanisme gebruikt:
//<my namespace>.servicebus.windows.net/<event hub name>/publishers/<my publisher name>
Het is niet nodig om van tevoren uitgeversnamen te maken. De namen moeten echter wel overeenkomen met het SAS-token dat wordt gebruikt wanneer een gebeurtenis wordt gepubliceerd. Hiermee wordt voor onafhankelijke uitgeversidentiteiten gezorgd. Wanneer u uitgeversbeleid gebruikt, moet de PartitionKey-waarde worden ingesteld op de naam van de uitgever. Voor een goede werking moeten deze waarden overeenkomen.
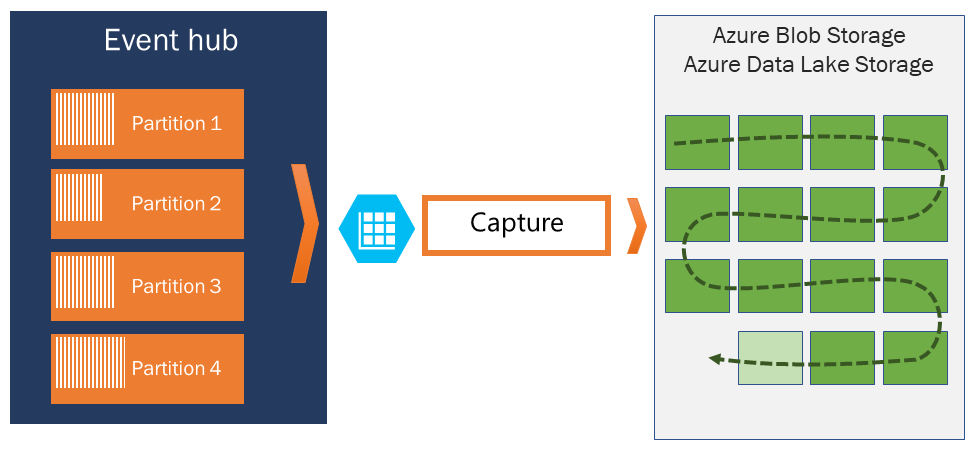
Capture
Met Event Hubs Capture kunt u de streaminggegevens automatisch vastleggen in Event Hubs en opslaan in uw keuze uit een Blob Storage-account of een Azure Data Lake Storage-account. U kunt vastleggen vanuit Azure Portal inschakelen en een minimale grootte en tijdvenster opgeven om de opname uit te voeren. Met Event Hubs Capture geeft u uw eigen Azure Blob Storage-account en -container op, of een Azure Data Lake Storage-account dat wordt gebruikt om de vastgelegde gegevens op te slaan. Vastgelegde gegevens worden geschreven in de Apache Avro-indeling.
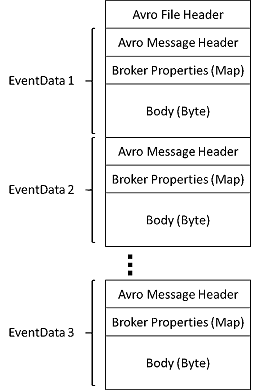
De bestanden die door Event Hubs Capture worden geproduceerd, hebben het volgende Avro-schema:
Notitie
Wanneer u geen code-editor in Azure Portal gebruikt, kunt u streaminggegevens vastleggen in Event Hubs in een Azure Data Lake Storage Gen2-account in de Parquet-indeling . Zie Procedure voor meer informatie: gegevens van Event Hubs vastleggen in Parquet-indeling en zelfstudie: Event Hubs-gegevens vastleggen in Parquet-indeling en analyseren met Azure Synapse Analytics.
SAS-tokens
Event Hubs gebruikt Shared Access Signatures die beschikbaar zijn op het niveau van de naamruimte en Event Hub. Een SAS-token wordt gegenereerd uit een SAS-sleutel en is een SHA-hash of URL. gecodeerd in een specifieke indeling. Event Hubs kan de hash opnieuw genereren met behulp van de naam van de sleutel (beleid) en het token en de afzender dus verifiëren. Normaal gesproken worden SAS-tokens voor gebeurtenisuitgevers alleen gemaakt met bevoegdheden voor verzenden voor een specifieke Event Hub. Dit URL-mechanisme met SAS-token vormt de basis voor de uitgeversidentificatie die in het uitgeversbeleid wordt geïntroduceerd. Zie Shared Access Signature-verificatie met Service Bus voor meer informatie over werken met SAS.
Gebeurtenisconsumers
Elke entiteit die gebeurtenisgegevens van een Event Hub leest, is een gebeurtenisconsumer. Alle Event Hubs-consumers maken verbinding via de AMQP 1.0-sessie, waarin gebeurtenissen worden geleverd zodra deze beschikbaar komen. De client hoeft niet te peilen naar beschikbaarheid van gegevens.
Consumentengroepen
Het Event Hubs-mechanisme voor publiceren/abonneren wordt geactiveerd via consumergroepen. Een consumentengroep is een logische groepering van consumenten die gegevens lezen uit een Event Hub of Kafka-onderwerp. Hiermee kunnen meerdere toepassingen dezelfde streaminggegevens in een Event Hub onafhankelijk in hun eigen tempo lezen met hun offsets. Hiermee kunt u het verbruik van berichten parallelliseren en de werkbelasting verdelen over meerdere consumenten, terwijl de volgorde van berichten binnen elke partitie behouden blijft.
U wordt aangeraden slechts één actieve ontvanger op een partitie binnen een consumentengroep te gebruiken. In bepaalde scenario's kunt u echter maximaal vijf consumenten of ontvangers per partitie gebruiken, waarbij alle ontvangers alle gebeurtenissen van de partitie ontvangen. Als u meerdere lezers op dezelfde partitie hebt, verwerkt u dubbele gebeurtenissen. U moet deze afhandelen in uw code, wat niet triviaal is. In sommige scenario's is het echter een geldige benadering.
In een architectuur waarin de stroom wordt verwerkt, is elke downstream-toepassing gelijk aan een consumergroep. Als u gebeurtenisgegevens naar de langetermijnopslag wilt schrijven, is de schrijftoepassing die hiervoor wordt gebruikt, een consumergroep. De complexe verwerking van gebeurtenissen kan vervolgens worden uitgevoerd door een andere, afzonderlijke consumergroep. U hebt alleen toegang tot partities via een consumergroep. Er is altijd een standaardconsumentgroep in een Event Hub en u kunt maximaal het maximum aantal consumentengroepen voor de bijbehorende prijscategorie maken.
Sommige clients die door de Azure SDK's worden aangeboden, zijn intelligente consumentenagents die automatisch de details beheren om ervoor te zorgen dat elke partitie één lezer heeft en dat alle partities voor een Event Hub worden gelezen. Hiermee kan uw code zich richten op het verwerken van de gebeurtenissen die worden gelezen vanuit de Event Hub, zodat veel van de details van de partities kunnen worden genegeerd. Zie Verbinding maken naar een partitie voor meer informatie.
In de volgende voorbeelden ziet u de URI-conventie voor consumentengroepen:
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #1>
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #2>
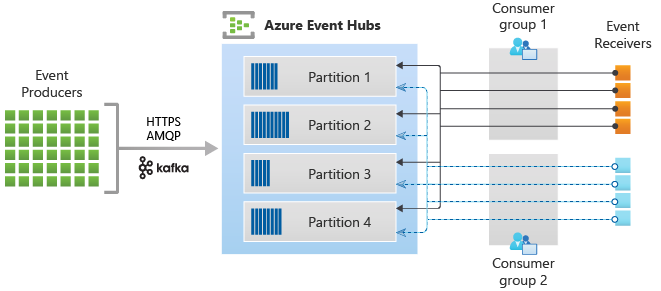
In de volgende afbeelding ziet u de architectuur voor de verwerking van stromen van Event Hubs:
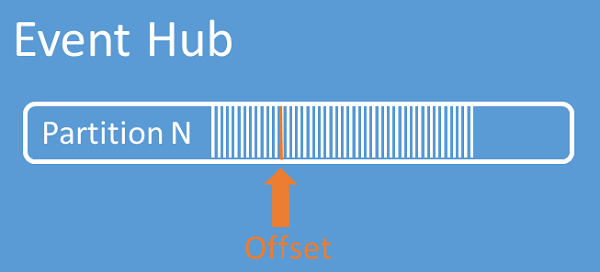
Stroom-offsets
Een offset is de positie van een gebeurtenis binnen een partitie. U kunt een offset beschouwen als een clientcursor. De offset is een bytenummering van de gebeurtenis. Met deze offset kan een gebeurtenisconsumer (lezer) een punt in de gebeurtenisstroom opgeven vanwaaruit begonnen moet worden met het lezen van gebeurtenissen. U kunt de offset opgeven als een tijdstempel of als een offsetwaarde. Consumers zijn zelf verantwoordelijk voor het opslaan van hun eigen offsetwaarden buiten de Event Hubs-service. Binnen een partitie bevat elke gebeurtenis een offset.
Controlepunten maken
Het plaatsen van controlepunten is een proces waarbij lezers hun positie binnen de gebeurtenisvolgorde van een partitie markeren of vastleggen. Het plaatsen van controlepunten is de verantwoordelijkheid van de consumer en vindt plaats per partitie binnen een consumergroep. Deze verantwoordelijkheid houdt in dat elke partitielezer voor elke consumergroep de huidige positie in de gebeurtenisstroom moet bijhouden en de service kan informeren wanneer de gegevensstroom is voltooid.
Als een lezer van een partitie is losgekoppeld en er vervolgens weer verbinding wordt gemaakt, begint het lezen bij het controlepunt dat eerder is verzonden door de laatste lezer van de betreffende partitie in de consumergroep. Wanneer de lezer verbinding maakt, wordt de offset doorgegeven aan de Event Hub om de locatie op te geven waarop moet worden gelezen. Op deze manier kunt u het plaatsen van controlepunten gebruiken om gebeurtenissen te markeren als 'voltooid' door downstream-toepassingen. Bovendien beschikt u met controlepunten over tolerantie bij een failover tussen lezers die op verschillende apparaten worden uitgevoerd. Het is mogelijk om terug te keren naar oudere gegevens door een lagere offset op te geven van dit controlepuntproces. Via dit mechanisme zorgt het plaatsen van controlepunten voor failover-tolerantie en voor herhaling van gebeurtenisstromen.
Belangrijk
Offsets worden geleverd door de Event Hubs-service. Het is de verantwoordelijkheid van de consument om controlepunten te controleren wanneer gebeurtenissen worden verwerkt.
Volg deze aanbevelingen wanneer u Azure Blob Storage gebruikt als controlepuntarchief:
- Gebruik een afzonderlijke container voor elke consumentengroep. U kunt hetzelfde opslagaccount gebruiken, maar één container per groep gebruiken.
- Gebruik de container niet voor iets anders en gebruik het opslagaccount niet voor iets anders.
- Het opslagaccount moet zich in dezelfde regio bevinden als waarin de geïmplementeerde toepassing zich bevindt. Als de toepassing on-premises is, probeert u de dichtstbijzijnde regio te kiezen.
Controleer op de pagina Opslagaccount in Azure Portal in de sectie Blob-service of de volgende instellingen zijn uitgeschakeld.
- Hiërarchische naamruimte
- Blob voorlopig verwijderen
- Versiebeheer
Logboekcompressie
Azure Event Hubs biedt ondersteuning voor het comprimeren van gebeurtenislogboeken om de meest recente gebeurtenissen van een bepaalde gebeurtenissleutel te behouden. Met gecomprimeerde Event Hubs/Kafka-onderwerp kunt u retentie op basis van sleutels gebruiken in plaats van de grof korrelige retentie op basis van tijd.
Zie Logboekcompressie voor meer informatie over logboekcompressie.
Algemene taken voor consumers
Alle Event Hubs-consumenten maken verbinding via een AMQP 1.0-sessie, een statusbewust bidirectioneel communicatiekanaal. Elke partitie heeft een AMQP 1.0-sessie die het mogelijk maakt partitiespecifieke gebeurtenissen te transporteren.
Verbinding maken met een partitie
Wanneer u verbinding maakt met partities, is het gebruikelijk om een leasemechanisme te gebruiken om lezerverbindingen met specifieke partities te coördineren. Op deze manier is het mogelijk dat elke partitie in een consumentengroep slechts één actieve lezer heeft. Controlepunten, leasen en beheren van lezers worden vereenvoudigd door de clients binnen de Event Hubs SDK's te gebruiken, die fungeren als intelligente consumentenagenten. Dit zijn:
- De EventProcessorClient voor .NET
- De EventProcessorClient voor Java
- De EventHubConsumerClient voor Python
- De EventHubConsumerClient voor JavaScript/TypeScript
Gebeurtenissen lezen
Nadat er voor een specifieke partitie een AMQP 1.0-sessie en -koppeling zijn geopend, worden de gebeurtenissen door de Event Hubs-service aan de AMQP 1.0-client geleverd. Dit leveringsmechanisme maakt hogere doorvoer en lagere latentie mogelijk dan pull-mechanismen zoals HTTP GET. Tijdens het verzenden van gebeurtenissen naar de client wordt elk gebeurtenisgegeven voorzien van belangrijke metagegevens, zoals de offset en het volgnummer. Deze worden gebruikt om het plaatsen van controlepunten in de gebeurtenisvolgorde mogelijk te maken.
Gebeurtenisgegevens:
- Verschuiving
- Volgnummer
- Hoofdtekst
- Gebruikerseigenschappen
- Systeemeigenschappen
Het is uw verantwoordelijkheid om de offset te beheren.
Toepassingsgroepen
Een toepassingsgroep is een verzameling clienttoepassingen die verbinding maken met een Event Hubs-naamruimte die een unieke identificatievoorwaarde deelt, zoals de beveiligingscontext- beleid voor gedeelde toegang of de id van de Microsoft Entra-toepassing.
Met Azure Event Hubs kunt u toegangsbeleid voor resources definiëren, zoals beperkingsbeleid voor een bepaalde toepassingsgroep en het beheren van gebeurtenisstreaming (publiceren of gebruiken) tussen clienttoepassingen en Event Hubs.
Zie Resourcebeheer voor clienttoepassingen met toepassingsgroepen voor meer informatie.
Ondersteuning voor Apache Kafka
De protocolondersteuning voor Apache Kafka-clients (versies >=1.0) biedt eindpunten waarmee bestaande Kafka-toepassingen Event Hubs kunnen gebruiken. De meeste bestaande Kafka-toepassingen kunnen eenvoudigweg opnieuw worden geconfigureerd om te verwijzen naar een naamruimte in plaats van een Kafka-clusterboottrapserver.
Vanuit het perspectief van kosten, operationele inspanningen en betrouwbaarheid is Azure Event Hubs een uitstekend alternatief voor het implementeren en gebruiken van uw eigen Kafka- en Zookeeper-clusters en voor Kafka-as-a-Service-aanbiedingen die niet systeemeigen zijn voor Azure.
Naast het verkrijgen van dezelfde kernfunctionaliteit als de Apache Kafka-broker, krijgt u ook toegang tot Azure Event Hubs-functies zoals automatische batchverwerking en archivering via Event Hubs Capture, automatisch schalen en verdelen, herstel na noodgevallen, kostenneutrale beschikbaarheidszoneondersteuning, flexibele en veilige netwerkintegratie en ondersteuning voor meerdere protocollen, waaronder het firewallvriendelijke AMQP-over-WebSockets-protocol.
Volgende stappen
Voor meer informatie over Event Hubs gaat u naar de volgende koppelingen:
- Aan de slag met Event Hubs