Oplossingsideeën
In dit artikel wordt een oplossingsidee beschreven. Uw cloudarchitect kan deze richtlijnen gebruiken om de belangrijkste onderdelen te visualiseren voor een typische implementatie van deze architectuur. Gebruik dit artikel als uitgangspunt om een goed ontworpen oplossing te ontwerpen die overeenkomt met de specifieke vereisten van uw workload.
Implementeer een aangepaste NLP-oplossing (Natural Language Processing) in Azure. Gebruik Spark NLP voor taken zoals onderwerp- en sentimentdetectie en -analyse.
Apache, Apache® Spark en het vlamlogo zijn gedeponeerde handelsmerken of handelsmerken van de Apache Software Foundation in de Verenigde Staten en/of andere landen. Er wordt geen goedkeuring door De Apache Software Foundation geïmpliceerd door het gebruik van deze markeringen.
Architectuur

Een Visio-bestand van deze architectuur downloaden.
Workflow
- Azure Event Hubs, Azure Data Factory of beide services ontvangen documenten of ongestructureerde tekstgegevens.
- Event Hubs en Data Factory slaan de gegevens op in bestandsindeling in Azure Data Lake Storage. U wordt aangeraden een adreslijststructuur in te stellen die voldoet aan de bedrijfsvereisten.
- De Azure Computer Vision-API maakt gebruik van de OCR-mogelijkheid (Optical Character Recognition) om de gegevens te gebruiken. De API schrijft vervolgens de gegevens naar de bronslaag. Dit verbruiksplatform maakt gebruik van een lakehouse-architectuur.
- In de bronslaag worden de tekst door verschillende Spark NLP-functies vooraf verwerkt. Voorbeelden hiervan zijn het splitsen, corrigeren van de spelling, het opschonen en begrijpen van grammatica. We raden u aan om documentclassificatie uit te voeren op de bronslaag en vervolgens de resultaten naar de zilveren laag te schrijven.
- In de zilveren laag voeren geavanceerde Spark NLP-functies documentanalysetaken uit, zoals herkenning van benoemde entiteiten, samenvattingen en het ophalen van gegevens. In sommige architecturen wordt het resultaat naar de gouden laag geschreven.
- In de gouden laag voert Spark NLP verschillende taalkundige visuele analyses uit op de tekstgegevens. Deze analyses bieden inzicht in taalafhankelijkheden en helpen bij de visualisatie van NER-labels.
- Gebruikers voeren een query uit op de tekstgegevens van de gouden laag als een gegevensframe en bekijken de resultaten in Power BI- of web-apps.
Tijdens de verwerkingsstappen worden Azure Databricks, Azure Synapse Analytics en Azure HDInsight gebruikt met Spark NLP om NLP-functionaliteit te bieden.
Onderdelen
- Data Lake Storage is een hadoop-compatibel bestandssysteem met een geïntegreerde hiërarchische naamruimte en de enorme schaal en economie van Azure Blob Storage.
- Azure Synapse Analytics is een analyseservice voor datawarehouses en big data-systemen.
- Azure Databricks is een analyseservice voor big data die eenvoudig te gebruiken is, samenwerking faciliteert en is gebaseerd op Apache Spark. Azure Databricks is ontworpen voor data science en data engineering.
- Event Hubs neemt gegevensstromen op die clienttoepassingen genereren. Event Hubs slaat de streaminggegevens op en behoudt de volgorde van ontvangen gebeurtenissen. Consumenten kunnen verbinding maken met hub-eindpunten om berichten op te halen voor verwerking. Event Hubs kan worden geïntegreerd met Data Lake Storage, zoals in deze oplossing wordt weergegeven.
- Azure HDInsight is een beheerde opensource-analyseservice in de cloud voor ondernemingen. U kunt opensource-frameworks gebruiken met Azure HDInsight, zoals Hadoop, Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Storm en R.
- Data Factory verplaatst automatisch gegevens tussen opslagaccounts met verschillende beveiligingsniveaus om scheiding van taken te garanderen.
- Computer Vision maakt gebruik van API's voor tekstherkenning om tekst in afbeeldingen te herkennen en die informatie te extraheren. De Read-API maakt gebruik van de nieuwste herkenningsmodellen en is geoptimaliseerd voor grote, tekstintensieve documenten en lawaaierige afbeeldingen. De OCR-API is niet geoptimaliseerd voor grote documenten, maar ondersteunt meer talen dan de Read-API. Deze oplossing maakt gebruik van OCR om gegevens te produceren in de hOCR-indeling .
Scenariodetails
Natuurlijke taalverwerking (NLP) heeft veel toepassingen: sentimentanalyse, onderwerpdetectie, taaldetectie, sleuteltermextractie en documentcategorisatie.
Apache Spark is een framework voor parallelle verwerking dat ondersteuning biedt voor in-memory verwerking om de prestaties van analysetoepassingen voor big data, zoals NLP, te verbeteren. Azure Synapse Analytics, Azure HDInsight en Azure Databricks bieden toegang tot Spark en profiteren van de verwerkingskracht.
Voor aangepaste NLP-workloads fungeert de opensource-bibliotheek Spark NLP als een efficiënt framework voor het verwerken van een grote hoeveelheid tekst. In dit artikel vindt u een oplossing voor grootschalige aangepaste NLP in Azure. De oplossing maakt gebruik van Spark NLP-functies voor het verwerken en analyseren van tekst. Zie De functionaliteit en pijplijnen van Spark NLP verderop in dit artikel voor meer informatie over Spark NLP.
Potentiële gebruikscases
Documentclassificatie: Spark NLP biedt verschillende opties voor tekstclassificatie:
- Tekstvoorverwerking in Spark NLP- en machine learning-algoritmen die zijn gebaseerd op Spark ML
- Tekstvoorverwerking en woord-insluiting in Spark NLP en machine learning-algoritmen zoals GloVe, BERT en ELMo
- Tekstvoorverwerking en insluiten van zinnen in Spark NLP- en machine learning-algoritmen en -modellen zoals de Universal Sentence Encoder
- Tekstvoorverwerking en -classificatie in Spark NLP die gebruikmaakt van de ClassificatieDL-annotator en is gebaseerd op TensorFlow
Naamentiteitextractie (NER): In Spark NLP, met een paar regels code, kunt u een NER-model trainen dat GEBRUIKMAAKT van BERT en u kunt de nauwkeurigheid van de nieuwste prestaties bereiken. NER is een subtaak van gegevensextractie. NER zoekt benoemde entiteiten in ongestructureerde tekst en classificeert deze in vooraf gedefinieerde categorieën, zoals namen van personen, organisaties, locaties, medische codes, tijdexpressies, hoeveelheden, monetaire waarden en percentages. Spark NLP maakt gebruik van een state-of-the-art NER-model met BERT. Het model is geïnspireerd op een voormalig NER-model, bidirectionele LSTM-CNN. Dat voormalige model maakt gebruik van een nieuwe neurale netwerkarchitectuur die automatisch functies op woord- en tekenniveau detecteert. Hiervoor maakt het model gebruik van een hybride bidirectionele LSTM- en CNN-architectuur, waardoor de meeste functie-engineering niet meer nodig is.
Gevoels- en emotiedetectie: Spark NLP kan automatisch positieve, negatieve en neutrale aspecten van taal detecteren.
Onderdeel van spraak (POS): Met deze functionaliteit wordt een grammaticale label toegewezen aan elk token in invoertekst.
Zindetectie (SD): SD is gebaseerd op een algemeen neuraal netwerkmodel voor zingrensdetectie waarmee zinnen in tekst worden geïdentificeerd. Veel NLP-taken nemen een zin als invoereenheid. Voorbeelden van deze taken zijn POS-taggen, afhankelijkheid parseren, herkenning van benoemde entiteiten en machinevertaling.
Spark NLP-functionaliteit en -pijplijnen
Spark NLP biedt Python-, Java- en Scala-bibliotheken die de volledige functionaliteit van traditionele NLP-bibliotheken bieden, zoals spaCy, NLTK,Core CoreNLP en Open NLP. Spark NLP biedt ook functionaliteit zoals spellingcontrole, sentimentanalyse en documentclassificatie. Spark NLP verbetert de eerdere inspanningen door geavanceerde nauwkeurigheid, snelheid en schaalbaarheid te bieden.
Spark NLP is verreweg de snelste opensource NLP-bibliotheek. Recente openbare benchmarks tonen Spark NLP 38 en 80 keer sneller dan spaCy, met vergelijkbare nauwkeurigheid voor het trainen van aangepaste modellen. Spark NLP is de enige opensource-bibliotheek die een gedistribueerd Spark-cluster kan gebruiken. Spark NLP is een systeemeigen uitbreiding van Spark ML die rechtstreeks op gegevensframes werkt. Als gevolg hiervan resulteren versnellingen in een cluster in een andere volgorde van grootte van prestatiewinst. Omdat elke Spark NLP-pijplijn een Spark ML-pijplijn is, is Spark NLP geschikt voor het bouwen van geïntegreerde NLP- en machine learning-pijplijnen, zoals documentclassificatie, risicovoorspelling en aanbevolen pijplijnen.
Naast uitstekende prestaties levert Spark NLP ook state-of-the-art nauwkeurigheid voor een groeiend aantal NLP-taken. Het Spark NLP-team leest regelmatig de meest recente relevante academische documenten en produceert de meest nauwkeurige modellen.
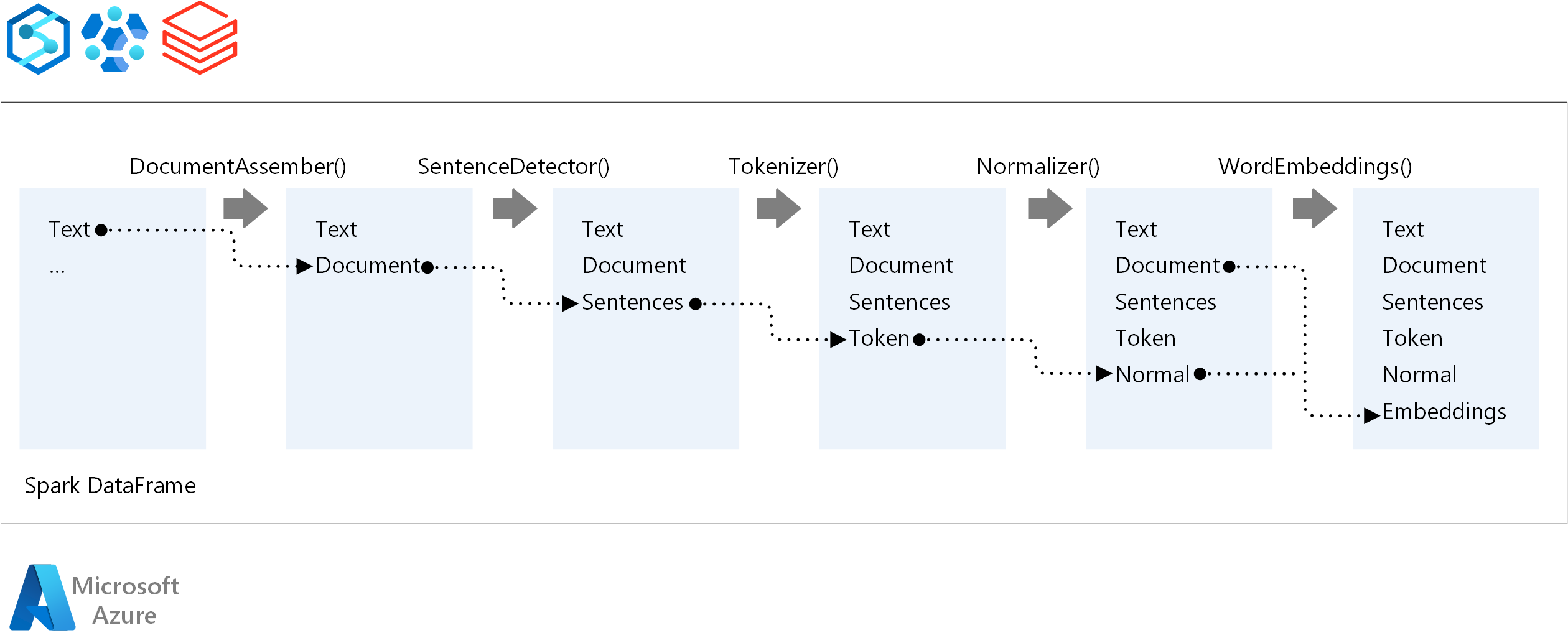
Voor de uitvoeringsvolgorde van een NLP-pijplijn volgt Spark NLP hetzelfde ontwikkelingsconcept als traditionele Spark Machine Learning-modellen. Maar Spark NLP past NLP-technieken toe. In het volgende diagram ziet u de kernonderdelen van een Spark NLP-pijplijn.
Medewerkers
Dit artikel wordt onderhouden door Microsoft. De tekst is oorspronkelijk geschreven door de volgende Inzenders.
Hoofdauteur:
- De Steller van Microsoft | Senior Cloud Solution Architect
Volgende stappen
Documentatie voor Spark NLP:
Azure-onderdelen: