Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Azure HDInsight is een beheerde, zeer uitgebreide opensource-analyseservice in de cloud voor bedrijven. Met HDInsight kunt u opensource-frameworks gebruiken, zoals Apache Spark, Apache Hive, LLAP, Apache Kafka, Hadoop en meer in uw Azure-omgeving.
Wat is HDInsight en de Hadoop-technologiestack?
Azure HDInsight is een beheerd clusterplatform waarmee u eenvoudig big data-frameworks kunt uitvoeren, zoals Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Hadoop en andere in uw Azure-omgeving. Het is ontworpen om grote hoeveelheden gegevens met hoge snelheid en efficiëntie te verwerken.
Waarom moet ik Azure HDInsight gebruiken?
| Mogelijkheid | Beschrijving |
|---|---|
| Cloud-native | Met Azure HDInsight kunt u geoptimaliseerde clusters maken voor Spark, Interactive Query (LLAP), Kafka, HBase en Hadoop in Azure. HDInsight Biedt tevens een end-to-end SLA voor al uw productieworkloads. |
| Voordelig en schaalbaar | Met HDInsight kunt u workloads omhoog of omlaag schalen. U kunt kosten verlagen door clusters op aanvraag te maken en alleen te betalen voor wat u gebruikt. U kunt ook gegevenspijplijnen maken om uw taken operationeel maken. Rekenwerk en opslag zijn niet langer gekoppeld, voor betere prestaties en flexibiliteit. |
| Beveiligd en compatibel | Met HDInsight kunt u uw zakelijke gegevensassets beveiligen met Azure Virtual Network, versleuteling en integratie met Microsoft Entra ID. HDInsight voldoet aan de meeste populaire nalevingsstandaarden van de industrie en de overheid. |
| Controleren | Azure HDInsight kan worden geïntegreerd met Azure Monitor-logboeken en biedt zo één enkele interface waarmee u al uw clusters kunt bewaken. |
| Wereldwijde beschikbaarheid | HDInsight is beschikbaar in meer regio's dan elke andere aanbieding voor big data-analyses . Azure HDInsight is ook beschikbaar in Azure Government, China en Duitsland, waarmee u kunt voldoen aan de behoeften van uw bedrijf in belangrijke soevereine gebieden. |
| Productiviteit | Met Azure HDInsight kunt u geavanceerde hulpprogramma's voor Hadoop en Spark gebruiken in de ontwikkelomgeving van uw keuze. Deze ontwikkelomgevingen omvatten Visual Studio, VS Code, Eclipse en IntelliJ voor ondersteuning voor Scala, Python, Java en .NET. |
| Uitbreidbaarheid | U kunt de HDInsight-clusters uitbreiden met geïnstalleerde onderdelen (Hue, Presto, enzovoort) met behulp van scriptacties, door edge-knooppunten toe te voegen of door te integreren met andere toepassingen die zijn gecertificeerd voor big data . Met HDInsight kunt u naadloos integreren met de meest populaire big data-oplossingen met éénkliksimplementatie. |
Wat is big data?
Big data wordt verzameld in steeds sneller groeiende volumes, met een steeds hogere snelheid en in een groter aantal indelingen dan ooit tevoren. Dit kan historisch zijn (dat wil zeggen opgeslagen) of realtime (wat betekent dat gegevens worden gestreamd vanuit de bron). Zie Scenario's voor het gebruik van HDInsight voor meer informatie over de meest voorkomende gebruiksvoorbeelden voor big data.
Clustertypen in HDInsight
HDInsight omvat specifieke clustertypen en opties voor clusteraanpassing, zoals de mogelijkheid om onderdelen, hulpprogramma's en talen toe te voegen. HDInsight biedt de volgende clustertypen:
| Clustertype | Beschrijving | Aan de slag |
|---|---|---|
| Apache Hadoop | Een kader dat gebruikmaakt van HDFS, YARN voor resourcebeheer en een eenvoudig MapReduce-programmeermodel om batchgegevens parallel te verwerken en te analyseren. | Een Apache Hadoop-cluster maken |
| Apache Spark | Een opensourcekader voor parallelle verwerking dat ondersteuning biedt voor in-memory verwerking om de prestaties van toepassingen voor de analyse van big data te verbeteren. Zie Wat is Apache Spark in HDInsight?. | Een Apache Spark-cluster maken |
| Apache HBase | Een NoSQL-database gebouwd op Hadoop. Deze biedt willekeurige toegang en sterke consistentie voor grote hoeveelheden (mogelijk miljarden rijen bij miljoenen kolommen) ongestructureerde en semi-gestructureerde gegevens. Zie Wat is HBase in HDInsight? | Een Apache HBase-cluster maken |
| Apache Interactive Query | Caching in geheugen voor interactieve en snellere Hive-query's. Zie Interactive Query gebruiken in HDInsight. | Een Interactive Query-cluster maken |
| Apache Kafka | Een opensource-platform wordt gebruikt voor het bouwen van pijplijnen en toepassingen voor streaminggegevens. Kafka biedt ook berichtenwachtrijfunctionaliteit waarmee u gegevensstromen kunt publiceren en zich kunt abonneren op gegevensstromen. Zie Inleiding tot Apache Kafka in HDInsight. | Een Apache Kafka-cluster maken |
Scenario's voor het gebruik van HDInsight
Azure HDInsight kan worden gebruikt voor verschillende scenario's in de verwerking van big data . Dit kunnen historische gegevens zijn (gegevens die al zijn verzameld en opgeslagen) of realtime gegevens (gegevens die rechtstreeks vanuit de bron worden gestreamd). De scenario's voor het verwerken van deze gegevens kunnen worden ingedeeld in de volgende categorieën:
Batchverwerking (ETL)
Extraheren, transformeren en laden (ETL) is een proces waarbij ongestructureerde of gestructureerde gegevens worden geëxtraheerd uit heterogene gegevensbronnen. Deze gegevens worden vervolgens omgezet in een gestructureerde indeling en in een gegevensarchief geladen. U kunt de getransformeerde gegevens gebruiken voor data science of datawarehousing.
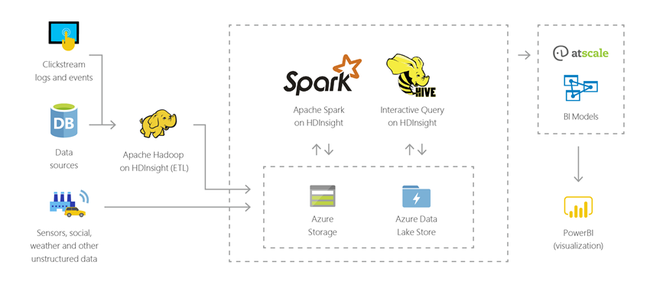
Datawarehousing
Met HDInsight kunt u interactieve query's op petabyte-schaal uitvoeren voor gestructureerde of ongestructureerde gegevens in elke indeling. U kunt ook modellen bouwen die hen verbinden met BI-hulpprogramma’s.
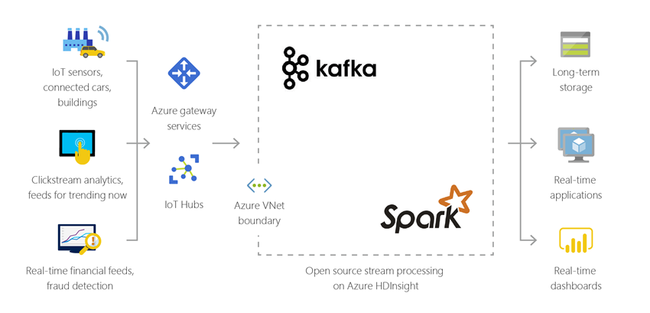
Internet der dingen (IoT)
U kunt HDInsight gebruiken om streaminggegevens te verwerken die in realtime worden ontvangen van verschillende soorten apparaten. Voor meer informatie leest u deze Azure-blogpost waarin de openbare preview van Apache Kafka in HDInsight met Azure Managed Disks wordt aangekondigd.
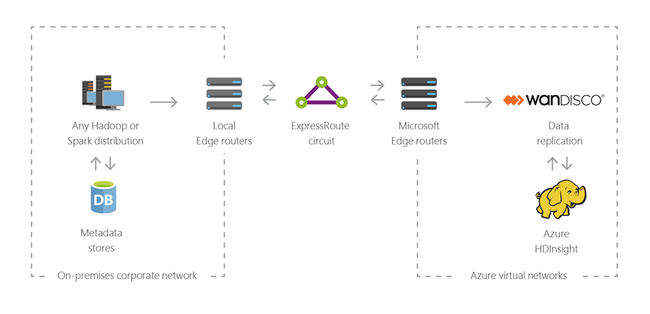
Hybride
U kunt HDInsight gebruiken om uw bestaande on-premises big data-infrastructuur uit te breiden naar Azure om de geavanceerde analysemogelijkheden van de cloud toe te passen.
Opensource-onderdelen in HDInsight
Met Azure HDInsight kunt u clusters maken met opensource-frameworks zoals Spark, Hive, LLAP, Kafka, Hadoop en HBase. Deze clusters bevatten standaard verschillende opensource-onderdelen, zoals Apache Ambari, Avro, Apache Hive 3, HCatalog, Apache Hadoop MapReduce, Apache Hadoop YARN, Apache Phoenix, Apache Pig, Apache Sqoop, Apache Tez, Apache Oozie en Apache ZooKeeper.
Programmeertalen in HDInsight
HDInsight-clusters, waaronder Spark, HBase, Kafka, Hadoop en andere, bieden ondersteuning voor een groot aantal programmeertalen. Sommige programmeertalen worden niet standaard geïnstalleerd. Gebruik voor bibliotheken, modules en pakketten die niet standaard zijn geïnstalleerd, een scriptactie om het betreffende onderdeel te installeren.
| Programmeertaal | Gegevens |
|---|---|
| Standaardondersteuning voor programmeertalen | Standaard bieden HDInsight-clusters ondersteuning voor:
|
| Talen voor de JVM, Java Virtual Machine | Op een virtuele Java-machine (JVM) kunnen naast Java ook vele andere talen worden uitgevoerd. Als u echter een aantal van deze talen uitvoert, moet u mogelijk meer onderdelen op het cluster installeren. De volgende op JVM gebaseerde talen worden ondersteund in HDInsight-clusters:
|
| Hadoop-specifieke talen | HDInsight-clusters ondersteunen de volgende talen die specifiek zijn voor de Hadoop-technologiestack:
|
Ontwikkelingsprogramma's voor HDInsight
U kunt HDInsight-ontwikkelingsprogramma's zoals IntelliJ, Eclipse, Visual Studio Code en Visual Studio gebruiken om HDInsight-gegevensquery's en taken te schrijven en te verzenden met naadloze integratie in Azure.
- Azure-toolkit voor IntelliJ 10
- Azure-toolkit voor Eclipse 6
- Azure HDInsight-hulpprogramma's voor VS Code 13
- Azure Data Lake-hulpprogramma's voor Visual Studio 9
Business Intelligence in HDInsight
Voor het ophalen, analyseren en rapporteren van met HDInsight geïntegreerde gegevens kunt u gebruikmaken van gangbare hulpprogramma's voor Business Intelligence (BI). Hiervoor is de invoegtoepassing Power Query of het ODBC-stuurprogramma Microsoft Hive vereist.
Apache Spark BI met gebruik van hulpmiddelen voor gegevensvisualisatie met Azure HDInsight
Apache Hive-gegevens visualiseren met Microsoft Power BI in Azure HDInsight
Interactive Query Hive-gegevens visualiseren met Power BI in Azure HDInsight
Excel koppelen aan Apache Hadoop met behulp van Power Query (vereist Windows)
Excel koppelen aan Apache Hadoop met behulp van het Hive ODBC-stuurprogramma van Microsoft (vereist Windows)
Gegevensverblijf binnen de regio
Spark, Hadoop en LLAP slaan geen klantgegevens op, zodat deze services automatisch voldoen aan de vereisten voor gegevenslocatie in de regio die zijn opgegeven in de globale infrastructuursite van Azure.
Kafka en HBase slaan wel klantgegevens op. Deze gegevens worden automatisch opgeslagen door Kafka en HBase in één regio, zodat deze service voldoet aan de vereisten voor gegevenslocatie in de regio die zijn opgegeven in de globale infrastructuursite van Azure.
Voor het ophalen, analyseren en rapporteren van met HDInsight geïntegreerde gegevens kunt u gebruikmaken van gangbare hulpprogramma's voor Business Intelligence (BI). Hiervoor is de invoegtoepassing Power Query of het ODBC-stuurprogramma Microsoft Hive vereist.