Wereldwijd beschikbare services ontwerpen met behulp van Azure SQL Database
Van toepassing op:![]() Azure SQL Database
Azure SQL Database
Bij het bouwen en implementeren van cloudservices met Azure SQL Database gebruikt u actieve geo-replicatie of failovergroepen om tolerantie te bieden voor regionale storingen en catastrofale fouten. Met dezelfde functie kunt u wereldwijd gedistribueerde toepassingen maken die zijn geoptimaliseerd voor lokale toegang tot de gegevens. In dit artikel worden veelvoorkomende toepassingspatronen besproken, met inbegrip van de voordelen en afwegingen van elke optie.
Notitie
Als u Premium of Bedrijfskritiek databases en elastische pools gebruikt, kunt u ze tolerant maken voor regionale storingen door ze te converteren naar zone-redundante implementatieconfiguratie. Zie zone-redundante databases.
Scenario 1: Twee Azure-regio's gebruiken voor bedrijfscontinuïteit met minimale downtime
In dit scenario hebben de toepassingen de volgende kenmerken:
- Toepassing is actief in één Azure-regio
- Alle databasesessies vereisen lees- en schrijftoegang (RW) tot gegevens
- De weblaag en gegevenslaag moeten worden gebruikt om de latentie en de verkeerskosten te verminderen
- In principe is downtime een hoger bedrijfsrisico voor deze toepassingen dan gegevensverlies
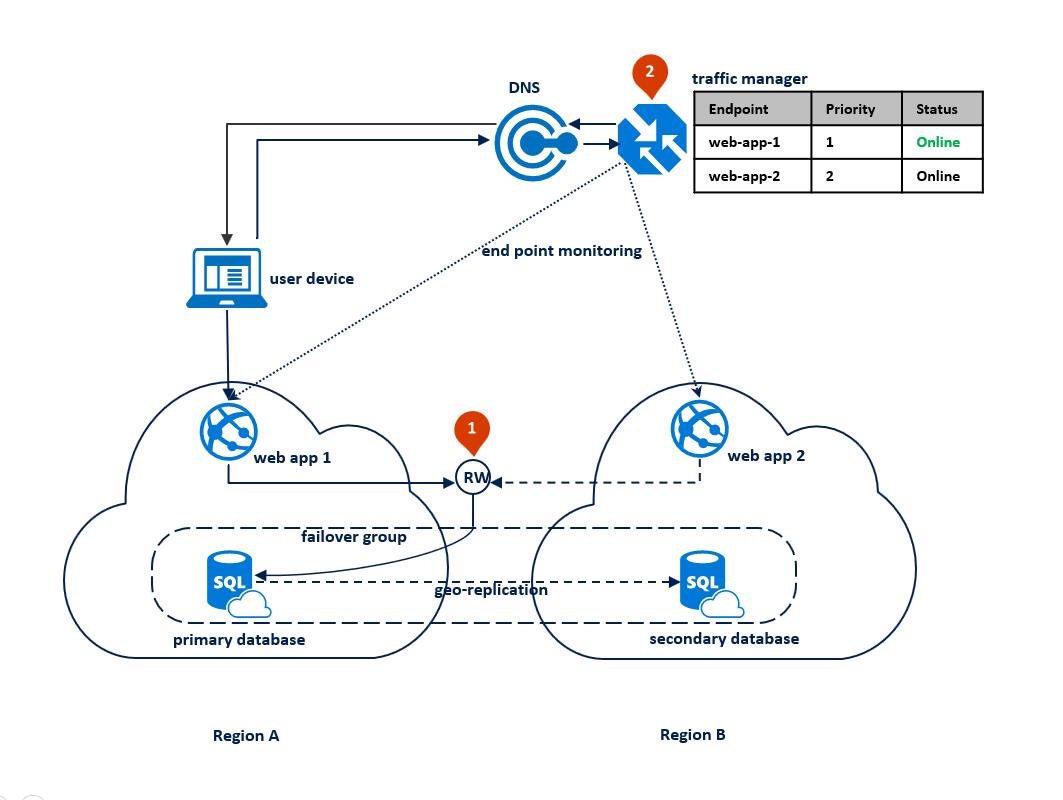
In dit geval is de topologie voor de implementatie van toepassingen geoptimaliseerd voor het afhandelen van regionale rampen wanneer alle toepassingsonderdelen een failover moeten uitvoeren. In het onderstaande diagram ziet u deze topologie. Voor geografische redundantie worden de resources van de toepassing geïmplementeerd in regio A en B. De resources in regio B worden echter pas gebruikt als regio A mislukt. Er wordt een failovergroep geconfigureerd tussen de twee regio's voor het beheren van databaseconnectiviteit, replicatie en failover. De webservice in beide regio's is geconfigureerd voor toegang tot de database via de failover-naam> van de read-write-listener.database.windows.net<(1). Azure Traffic Manager is ingesteld voor het gebruik van prioriteitsrouteringsmethode (2).
Notitie
Azure Traffic Manager wordt alleen in dit artikel gebruikt voor illustratiedoeleinden. U kunt elke oplossing voor taakverdeling gebruiken die ondersteuning biedt voor routeringsmethode met prioriteit.
In het volgende diagram ziet u deze configuratie vóór een storing:
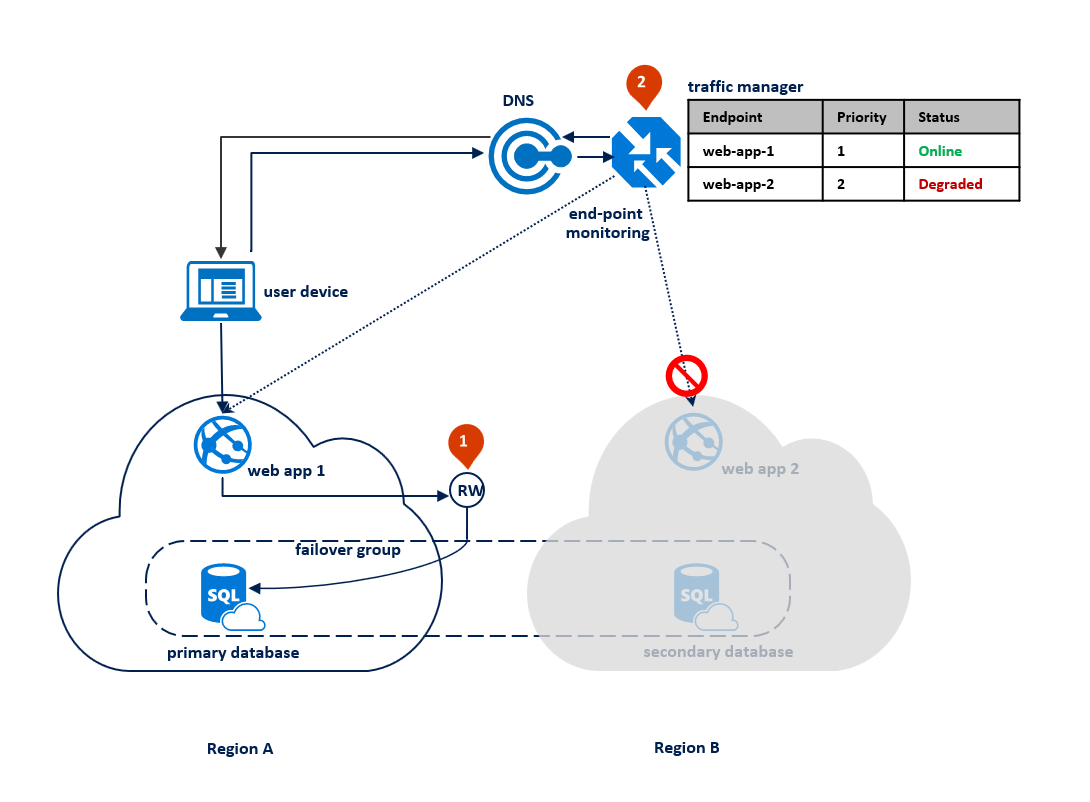
Na een storing in de primaire regio detecteert SQL Database dat de primaire database niet toegankelijk is en wordt failover naar de secundaire regio geactiveerd op basis van de parameters van het beleid voor automatische failover (1). Afhankelijk van de SLA van uw toepassing kunt u een respijtperiode configureren waarmee de tijd tussen de detectie van de storing en de failover zelf wordt bepaald. Het is mogelijk dat Azure Traffic Manager de failover van het eindpunt start voordat de failovergroep de failover van de database activeert. In dat geval kan de webtoepassing niet onmiddellijk opnieuw verbinding maken met de database. De nieuwe verbindingen worden echter automatisch uitgevoerd zodra de databasefailover is voltooid. Wanneer de mislukte regio is hersteld en weer online is, wordt de oude primaire automatisch opnieuw verbonden als een nieuwe secundaire. In het onderstaande diagram ziet u de configuratie na een failover.
Notitie
Alle transacties die na de failover zijn doorgevoerd, gaan verloren tijdens het opnieuw verbinden. Nadat de failover is voltooid, kan de toepassing in regio B opnieuw verbinding maken en de aanvragen van de gebruiker opnieuw starten. Zowel de webtoepassing als de primaire database bevinden zich nu in regio B en blijven co-locatie.
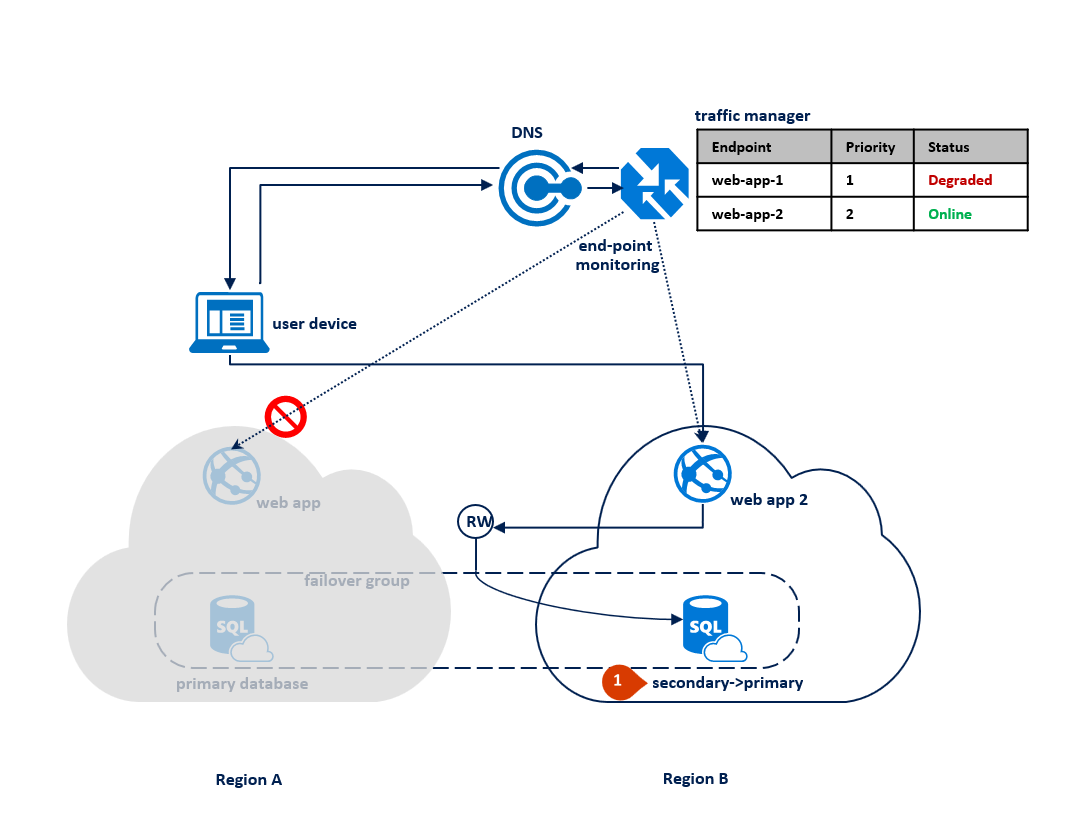
Als er een storing optreedt in regio B, wordt het replicatieproces tussen de primaire en de secundaire database onderbroken, maar blijft de koppeling tussen de twee intact (1). Traffic Manager detecteert dat de verbinding met regio B is verbroken en markeert de eindpuntweb-app 2 als gedegradeerd (2). De prestaties van de toepassing worden in dit geval niet beïnvloed, maar de database wordt blootgesteld en loopt daarom een hoger risico op gegevensverlies in het geval regio A achter elkaar mislukt.
Notitie
Voor herstel na noodgevallen raden we de configuratie aan met toepassingsimplementatie beperkt tot twee regio's. Dit komt doordat de meeste Azure-geografische gebieden slechts twee regio's hebben. Deze configuratie beveiligt uw toepassing niet tegen een gelijktijdige catastrofale fout van beide regio's. In een onwaarschijnlijk geval van een dergelijke fout kunt u uw databases in een derde regio herstellen met behulp van geo-herstelbewerking. Zie de richtlijnen voor herstel na noodgevallen van Azure SQL Database voor meer informatie.
Zodra de storing is verzacht, wordt de secundaire database automatisch opnieuw gesynchroniseerd met de primaire database. Tijdens de synchronisatie kunnen de prestaties van de primaire machine worden beïnvloed. De specifieke impact is afhankelijk van de hoeveelheid gegevens die de nieuwe primaire sinds de failover heeft verkregen.
Notitie
Nadat de storing is verzacht, start Traffic Manager met het routeren van de verbindingen naar de toepassing in Regio A als eindpunt met een hogere prioriteit. Als u de primaire regio B een tijdje wilt behouden, moet u de prioriteitstabel in het Traffic Manager-profiel dienovereenkomstig wijzigen.
In het volgende diagram ziet u een storing in de secundaire regio:
De belangrijkste voordelen van dit ontwerppatroon zijn:
- Dezelfde webtoepassing wordt geïmplementeerd in beide regio's zonder regiospecifieke configuratie en vereist geen aanvullende logica voor het beheren van failover.
- De prestaties van toepassingen worden niet beïnvloed door failover omdat de webtoepassing en de database zich altijd op dezelfde locatie bevinden.
Het belangrijkste nadeel is dat de toepassingsbronnen in regio B meestal te weinig worden gebruikt.
Scenario 2: Azure-regio's voor bedrijfscontinuïteit met maximale gegevensbehoud
Deze optie is het meest geschikt voor toepassingen met de volgende kenmerken:
- Gegevensverlies is een hoog bedrijfsrisico. De databasefailover kan alleen worden gebruikt als laatste redmiddel als de storing wordt veroorzaakt door een catastrofale fout.
- De toepassing biedt ondersteuning voor bewerkingen met het kenmerk Alleen-lezen en lezen/schrijven en kan gedurende een bepaalde periode in de modus Alleen-lezen werken.
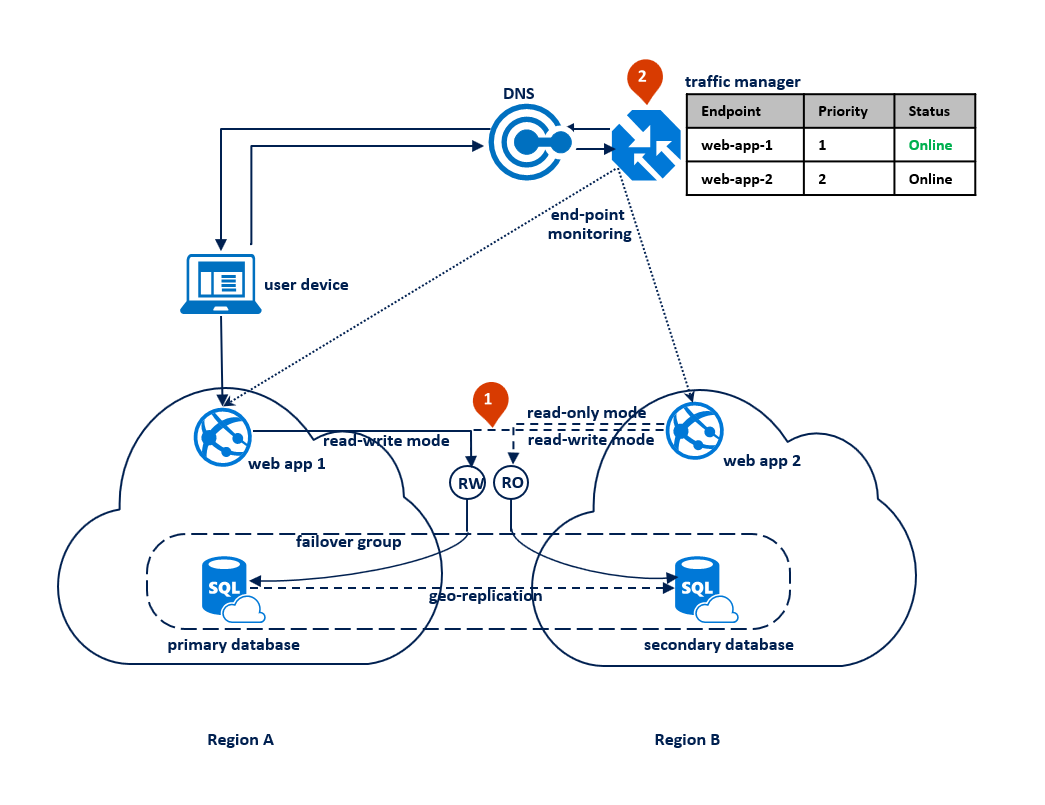
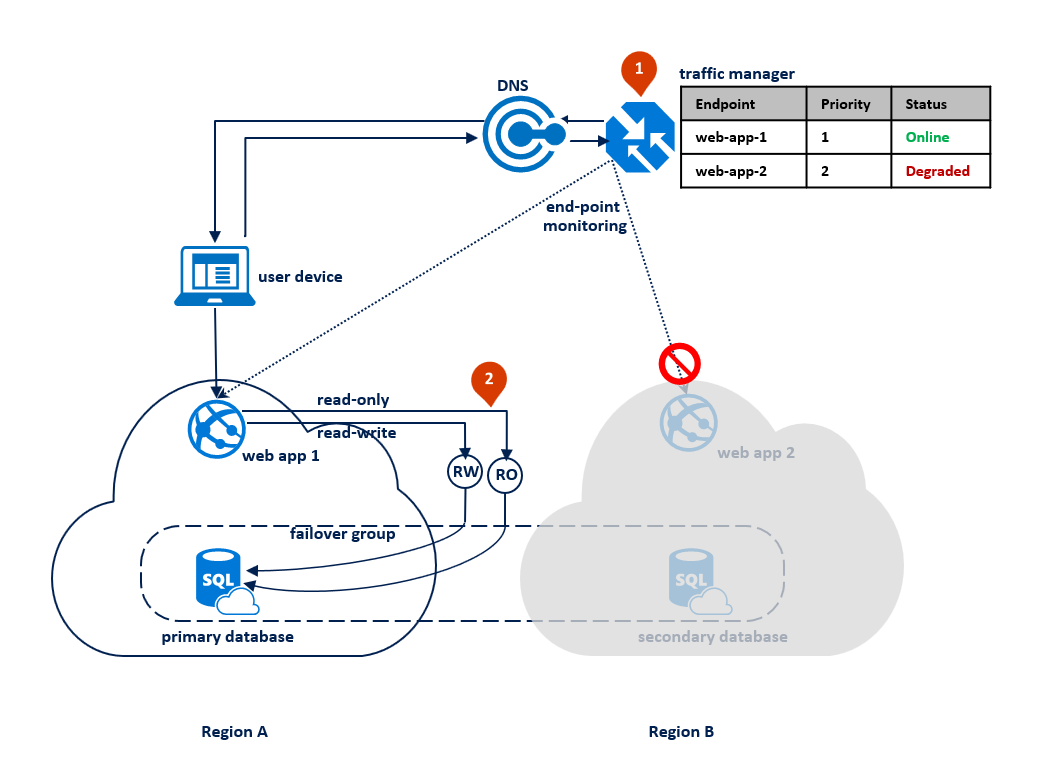
In dit patroon schakelt de toepassing over naar de modus Alleen-lezen wanneer de lees-/schrijfverbindingen time-outfouten krijgen. De webtoepassing wordt geïmplementeerd in beide regio's en bevat een verbinding met het eindpunt van de listener voor lezen/schrijven en een andere verbinding met het alleen-lezen-listenereindpunt (1). Het Traffic Manager-profiel moet prioriteitsroutering gebruiken. Eindpuntbewaking moet zijn ingeschakeld voor het toepassingseindpunt in elke regio (2).
In het volgende diagram ziet u deze configuratie vóór een storing:
Wanneer Traffic Manager een verbindingsfout in regio A detecteert, wordt gebruikersverkeer automatisch overgeschakeld naar het toepassingsexemplaren in regio B. Met dit patroon is het belangrijk dat u de respijtperiode met gegevensverlies instelt op een voldoende hoge waarde, bijvoorbeeld 24 uur. Het zorgt ervoor dat gegevensverlies wordt voorkomen als de storing binnen die tijd wordt beperkt. Wanneer de webtoepassing in regio B is geactiveerd, mislukken de lees-/schrijfbewerkingen. Op dat moment moet deze overschakelen naar de modus Alleen-lezen (1). In deze modus worden de aanvragen automatisch doorgestuurd naar de secundaire database. Als de storing wordt veroorzaakt door een onherstelbare fout, kan deze waarschijnlijk niet worden verzacht binnen de respijtperiode. Wanneer de failovergroep verloopt, wordt de failover geactiveerd. Daarna is de listener voor lezen/schrijven beschikbaar en mislukken de verbindingen met de listener (2). In het volgende diagram ziet u de twee fasen van het herstelproces.
Notitie
Als de storing in de primaire regio binnen de respijtperiode wordt beperkt, detecteert Traffic Manager het herstel van de connectiviteit in de primaire regio en schakelt het gebruikersverkeer terug naar het toepassingsexemplaren in regio A. Dat toepassingsexemplaren worden hervat en in de lees-/schrijfmodus worden uitgevoerd met behulp van de primaire database in regio A, zoals geïllustreerd in het vorige diagram.
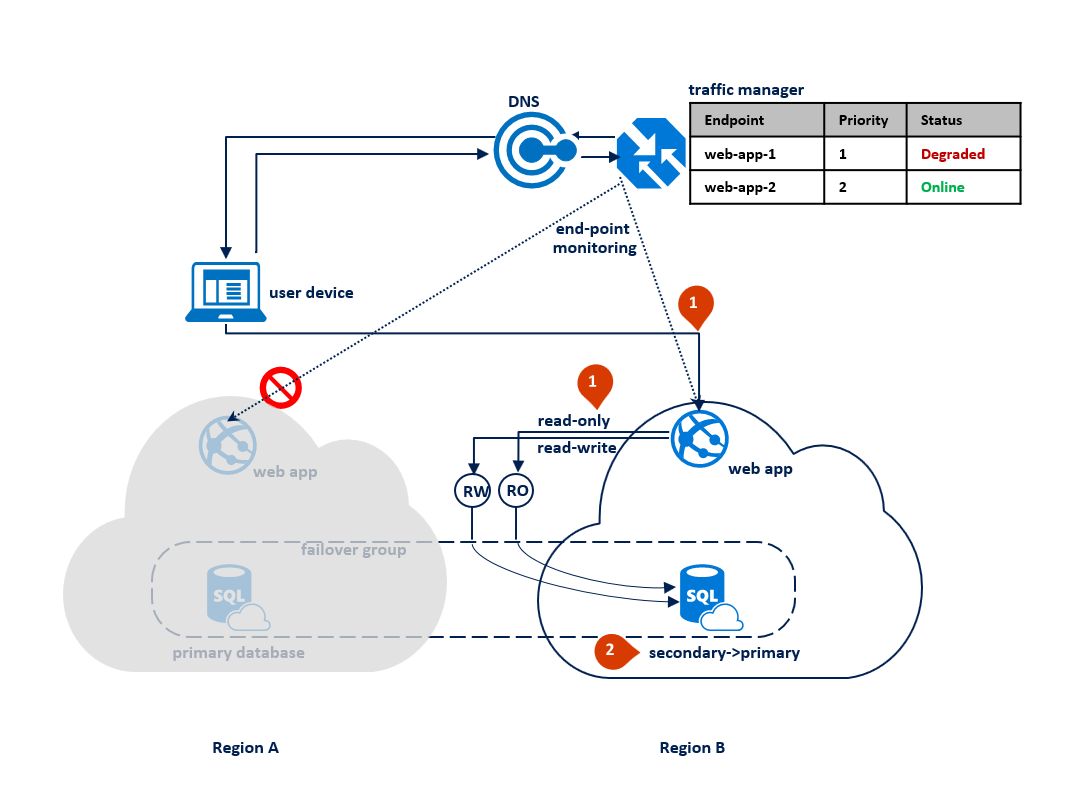
Als er een storing optreedt in regio B, detecteert Traffic Manager de fout van het eindpunt web-app-2 in regio B en wordt deze gedegradeerd (1). Ondertussen schakelt de failovergroep de alleen-lezen listener over naar regio A (2). Deze storing heeft geen invloed op de ervaring van de eindgebruiker, maar de primaire database wordt tijdens de storing weergegeven. In het volgende diagram ziet u een fout in de secundaire regio:
Zodra de storing is verzacht, wordt de secundaire database onmiddellijk gesynchroniseerd met de primaire en wordt de alleen-lezenlistener teruggezet naar de secundaire database in regio B. Tijdens de synchronisatieprestaties van de primaire kan dit enigszins worden beïnvloed, afhankelijk van de hoeveelheid gegevens die moet worden gesynchroniseerd.
Dit ontwerppatroon heeft verschillende voordelen:
- Het voorkomt gegevensverlies tijdens de tijdelijke storingen.
- Downtime is alleen afhankelijk van hoe snel Traffic Manager de verbindingsfout detecteert, die kan worden geconfigureerd.
Het nadeel is dat de toepassing in de modus Alleen-lezen moet kunnen werken.
Planning voor bedrijfscontinuïteit: een toepassingsontwerp kiezen voor herstel na noodgevallen in de cloud
Uw specifieke strategie voor herstel na noodgevallen in de cloud kan deze ontwerppatronen combineren of uitbreiden om het beste te voldoen aan de behoeften van uw toepassing. Zoals eerder vermeld, is de strategie die u kiest gebaseerd op de SLA die u aan uw klanten wilt aanbieden en de topologie voor de implementatie van toepassingen. Om u te helpen bij het nemen van uw beslissing, vergelijkt de volgende tabel de keuzes op basis van RPO (Recovery Point Objective) en de geschatte hersteltijd (ERT).
| Patroon | RPO | ERT |
|---|---|---|
| Actief-passieve implementatie voor herstel na noodgevallen met co-locatie databasetoegang | Lees-schrijftoegang < 5 sec. | Foutdetectietijd + DNS TTL |
| Actief-actieve implementatie voor taakverdeling van toepassingen | Lees-schrijftoegang < 5 sec. | Foutdetectietijd + DNS TTL |
| Actief-passieve implementatie voor gegevensbehoud | Alleen-lezentoegang < 5 sec. | Alleen-lezentoegang = 0 |
| Lees-schrijftoegang = nul | Lees-schrijftoegang = Foutdetectietijd + respijtperiode met gegevensverlies |
Volgende stappen
- Zie Overzicht van bedrijfscontinuïteit en scenario's voor een overzicht van bedrijfscontinuïteit
- Zie Actieve geo-replicatie voor meer informatie over actieve geo-replicatie.
- Zie Failover-groepen voor meer informatie over failovergroepen.
- Zie strategieën voor herstel na noodgevallen voor elastische pools voor informatie over actieve geo-replicatie met elastische pools.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor