Strategieën voor herstel na noodgevallen voor toepassingen die elastische Pools van Azure SQL Database gebruiken
Van toepassing op:![]() Azure SQL Database
Azure SQL Database
Azure SQL Database biedt verschillende mogelijkheden voor de bedrijfscontinuïteit van uw toepassing wanneer zich catastrofale incidenten voordoen. Elastische pools en individuele databases ondersteunen dezelfde mogelijkheden voor herstel na noodgevallen. In dit artikel worden verschillende DR-strategieën beschreven voor elastische pools die gebruikmaken van deze functies voor bedrijfscontinuïteit van Azure SQL Database.
In dit artikel wordt het volgende canonieke SaaS ISV-toepassingspatroon gebruikt:
Met een moderne webtoepassing in de cloud wordt één database ingericht voor elke eindgebruiker. De ISV heeft veel klanten en maakt daarom gebruik van veel databases, ook wel tenantdatabases genoemd. Omdat de tenantdatabases doorgaans onvoorspelbare activiteitspatronen hebben, maakt de ISV gebruik van een elastische pool om de database gedurende langere tijd zeer voorspelbaar te maken. De elastische pool vereenvoudigt ook het prestatiebeheer wanneer de gebruikersactiviteit piekt. Naast de tenantdatabases gebruikt de toepassing ook verschillende databases voor het beheren van gebruikersprofielen, beveiliging, het verzamelen van gebruikspatronen, enzovoort. De beschikbaarheid van de afzonderlijke tenants heeft geen invloed op de beschikbaarheid van de toepassing als geheel. De beschikbaarheid en prestaties van beheerdatabases zijn echter essentieel voor de functie van de toepassing en als de beheerdatabases offline zijn, is de hele toepassing offline.
In dit artikel worden dr-strategieën besproken die betrekking hebben op een reeks scenario's van kostengevoelige opstarttoepassingen tot scenario's met strenge beschikbaarheidsvereisten.
Notitie
Als u Premium of Bedrijfskritiek databases en elastische pools gebruikt, kunt u ze tolerant maken voor regionale storingen door ze te converteren naar zone-redundante implementatieconfiguratie. Zie zone-redundante databases.
Scenario 1. Kostengevoelig opstarten
Ik ben een startup bedrijf en ben uiterst kostengevoelig. Ik wil de implementatie en het beheer van de toepassing vereenvoudigen en ik kan een beperkte SLA hebben voor individuele klanten. Maar ik wil ervoor zorgen dat de toepassing als geheel nooit offline is.
Als u wilt voldoen aan de eenvoudsvereiste, implementeert u alle tenantdatabases in één elastische pool in de Azure-regio van uw keuze en implementeert u beheerdatabases als geografisch gerepliceerde individuele databases. Voor het herstel na noodgevallen van tenants gebruikt u geo-herstel, wat zonder extra kosten wordt geleverd. Om de beschikbaarheid van de beheerdatabases te garanderen, repliceert u ze naar een andere regio met behulp van een failovergroep (stap 1). De doorlopende kosten van de configuratie voor herstel na noodgevallen in dit scenario zijn gelijk aan de totale kosten van de secundaire databases. Deze configuratie wordt geïllustreerd in het volgende diagram.
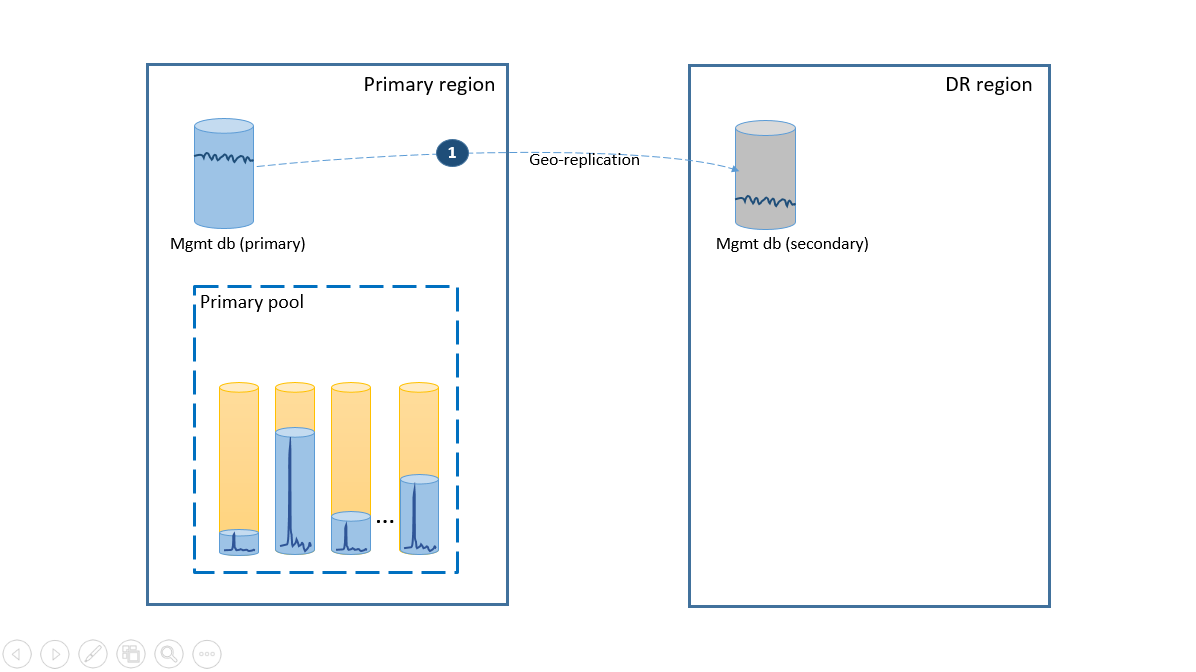
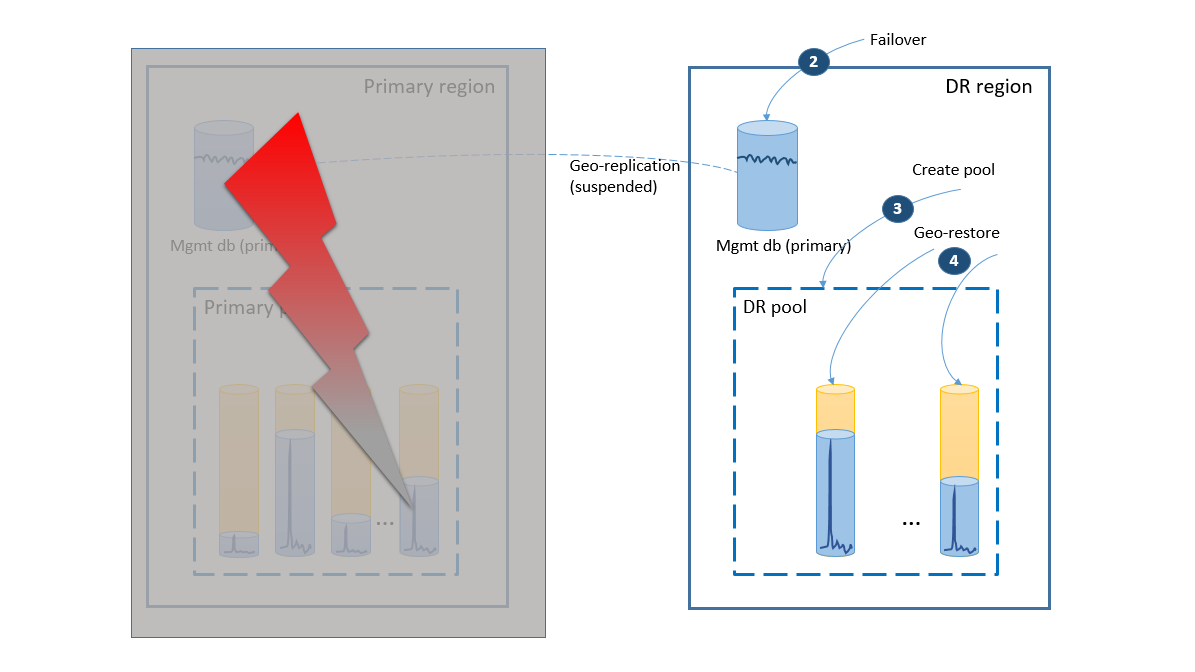
Als er een storing optreedt in de primaire regio, worden de herstelstappen voor het online brengen van uw toepassing geïllustreerd in het volgende diagram.
- De failovergroep initieert automatische failover van de beheerdatabase naar de dr-regio. De toepassing wordt automatisch opnieuw verbonden met de nieuwe primaire en alle nieuwe accounts en tenantdatabases worden gemaakt in de regio herstel na noodgeval. De bestaande klanten zien hun gegevens tijdelijk niet beschikbaar.
- Maak de elastische pool met dezelfde configuratie als de oorspronkelijke pool (2).
- Gebruik geo-herstel om kopieën van de tenantdatabases te maken (3). U kunt overwegen om de afzonderlijke herstelbewerkingen te activeren door de verbindingen van eindgebruikers of een ander toepassingsspecifiek prioriteitsschema te gebruiken.
Op dit moment is uw toepassing weer online in de dr-regio, maar sommige klanten ondervinden vertraging bij het openen van hun gegevens.
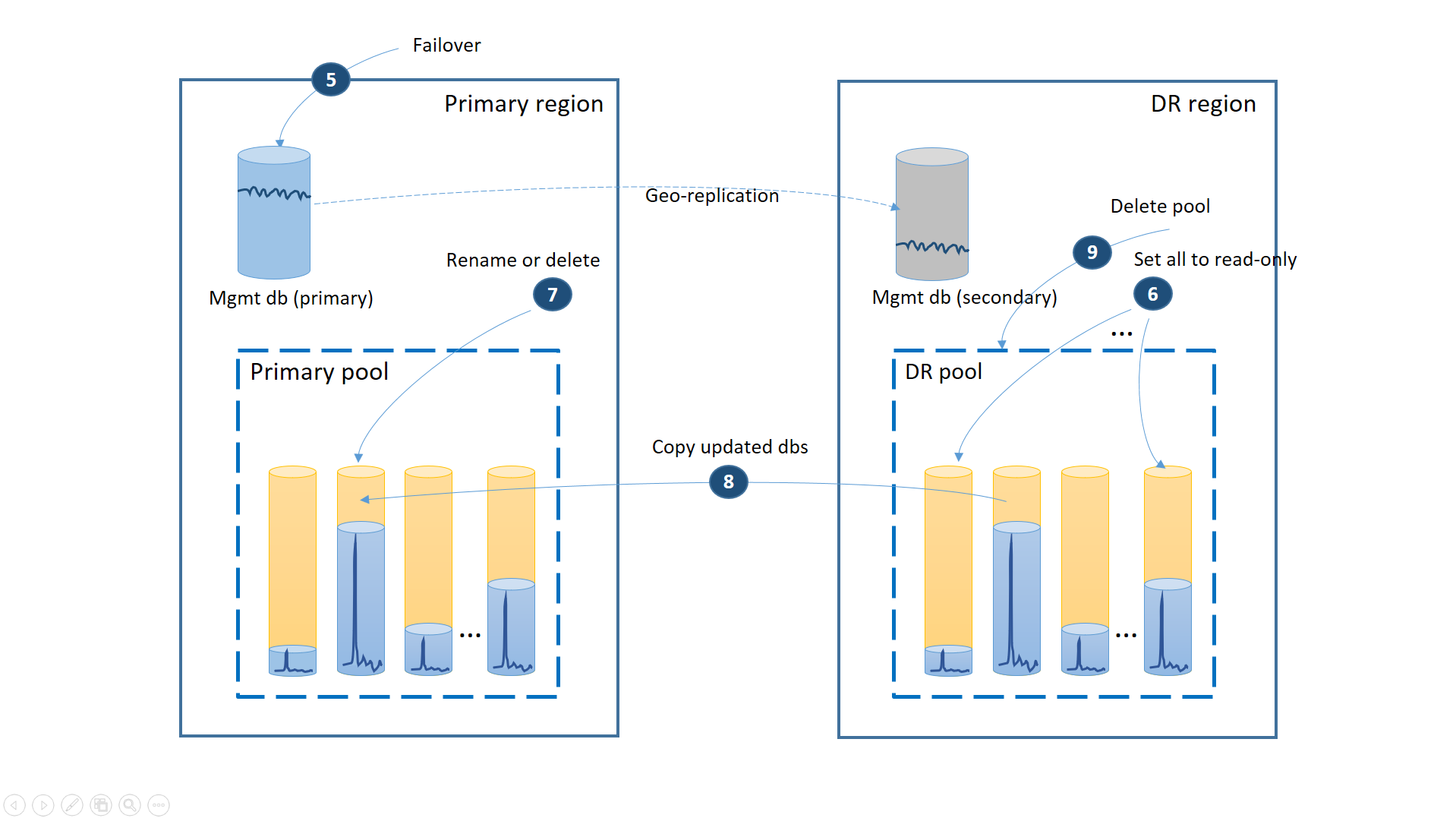
Als de storing tijdelijk was, is het mogelijk dat de primaire regio wordt hersteld door Azure voordat alle databaseherstelbewerkingen zijn voltooid in de dr-regio. In dit geval moet u het verplaatsen van de toepassing terugzetten naar de primaire regio. Het proces voert de stappen uit die in het volgende diagram worden geïllustreerd.
- Annuleer alle openstaande aanvragen voor geo-herstel.
- Failover van de beheerdatabases naar de primaire regio (5). Na het herstel van de regio worden de oude primaries automatisch secundair. Nu wisselen ze weer van rol.
- Wijzig de verbindingsreeks van de toepassing om terug te verwijzen naar de primaire regio. Nu worden alle nieuwe accounts en tenantdatabases gemaakt in de primaire regio. Sommige bestaande klanten zien hun gegevens tijdelijk niet beschikbaar.
- Stel alle databases in de dr-pool in op alleen-lezen om ervoor te zorgen dat ze niet kunnen worden gewijzigd in de dr-regio (6).
- Voor elke database in de DR-pool die is gewijzigd sinds het herstel, wijzigt of verwijdert u de bijbehorende databases in de primaire pool (7).
- Kopieer de bijgewerkte databases van de DR-pool naar de primaire pool (8).
- De DR-pool verwijderen (9)
Op dit moment is uw toepassing online in de primaire regio met alle tenantdatabases die beschikbaar zijn in de primaire pool.
Voordeel
Het belangrijkste voordeel van deze strategie is lage doorlopende kosten voor redundantie van gegevenslagen. Azure SQL Database maakt automatisch een back-up van databases zonder opnieuw schrijven van toepassingen zonder extra kosten. De kosten worden alleen gemaakt wanneer de elastische databases worden hersteld.
Trade-off
De afweging is dat het volledige herstel van alle tenantdatabases veel tijd in beslag neemt. De tijdsduur is afhankelijk van het totale aantal herstelbewerkingen dat u initieert in de dr-regio en de totale grootte van de tenantdatabases. Zelfs als u prioriteit geeft aan de herstelbewerkingen van sommige tenants ten opzichte van andere tenants, concurreren u met alle andere herstelbewerkingen die in dezelfde regio worden gestart als de service verwijst en beperkt om de algehele impact op de databases van bestaande klanten te minimaliseren. Bovendien kan het herstel van de tenantdatabases pas worden gestart als de nieuwe elastische pool in de dr-regio is gemaakt.
Scenario 2. Volwassen toepassing met gelaagde service
Ik ben een volwassen SaaS-toepassing met gelaagde serviceaanbiedingen en verschillende SLA's voor proefklanten en voor betalende klanten. Voor de proefklanten moet ik de kosten zoveel mogelijk verlagen. Proefklanten kunnen uitvaltijd nemen, maar ik wil de kans verkleinen. Voor de betalende klanten is downtime een vluchtrisico. Ik wil er dus voor zorgen dat betalende klanten altijd toegang hebben tot hun gegevens.
Om dit scenario te ondersteunen, scheidt u de proeftenants van betaalde tenants door ze in afzonderlijke elastische pools te plaatsen. De proefklanten hebben een lagere eDTU of vCores per tenant en een lagere SLA met een langere hersteltijd. De betalende klanten bevinden zich in een pool met een hogere eDTU of vCores per tenant en een hogere SLA. Om de laagste hersteltijd te garanderen, worden de tenantdatabases van de betalende klanten geo-gerepliceerd. Deze configuratie wordt geïllustreerd in het volgende diagram.
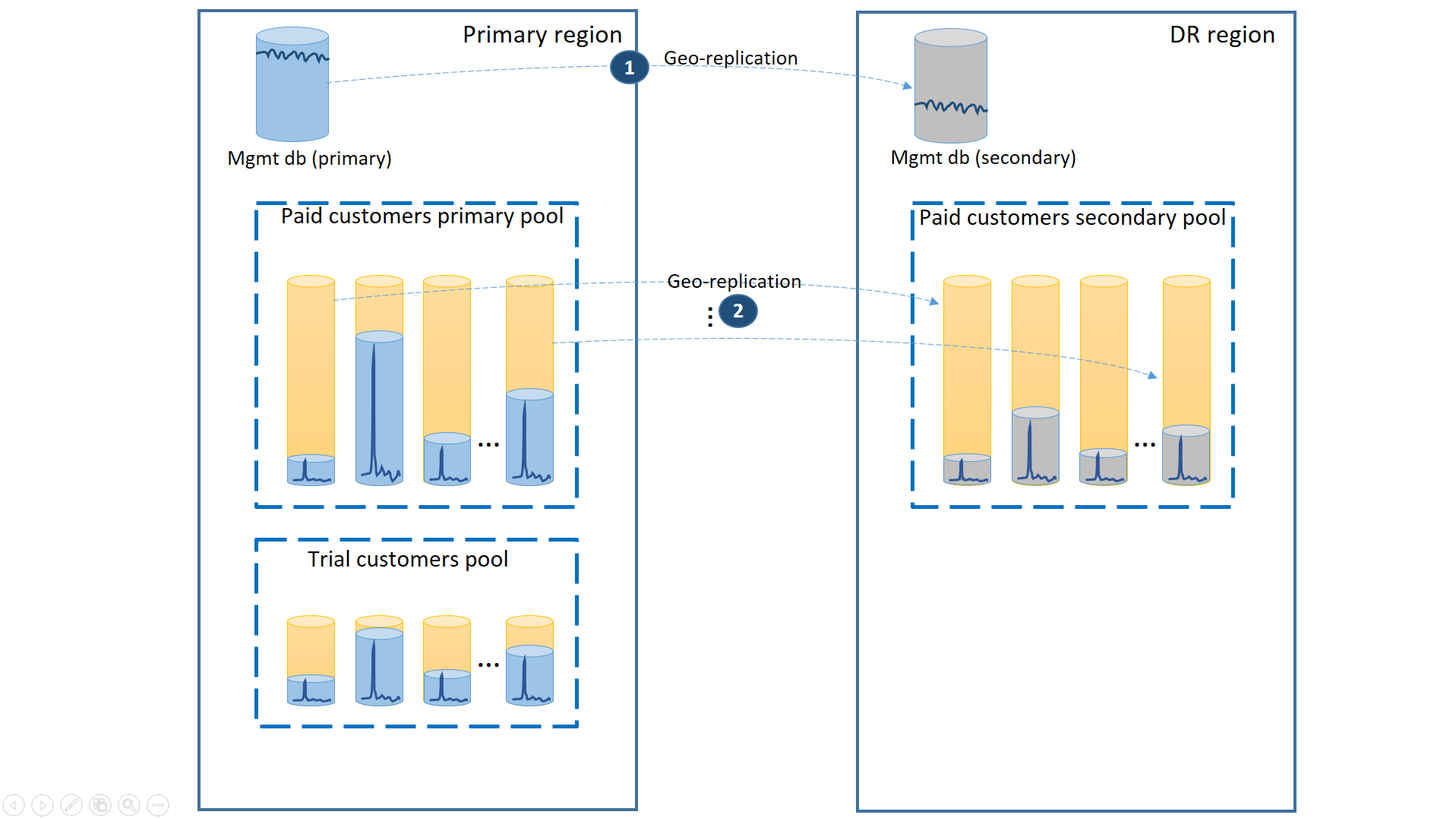
Net als in het eerste scenario zijn de beheerdatabases vrij actief, dus u gebruikt hiervoor één geo-gerepliceerde database (1). Dit zorgt voor de voorspelbare prestaties voor nieuwe klantabonnementen, profielupdates en andere beheerbewerkingen. De regio waarin de primaries van de beheerdatabases zich bevinden, is de primaire regio en de regio waarin de secundaire databases zich bevinden, is de dr-regio.
De tenantdatabases van betalende klanten hebben actieve databases in de betaalde pool die is ingericht in de primaire regio. Richt een secundaire pool in met dezelfde naam in de dr-regio. Elke tenant wordt geo-gerepliceerd naar de secundaire pool (2). Hierdoor kunnen alle tenantdatabases snel worden hersteld met behulp van failover.
Als er een storing optreedt in de primaire regio, worden de herstelstappen voor het online brengen van uw toepassing geïllustreerd in het volgende diagram:
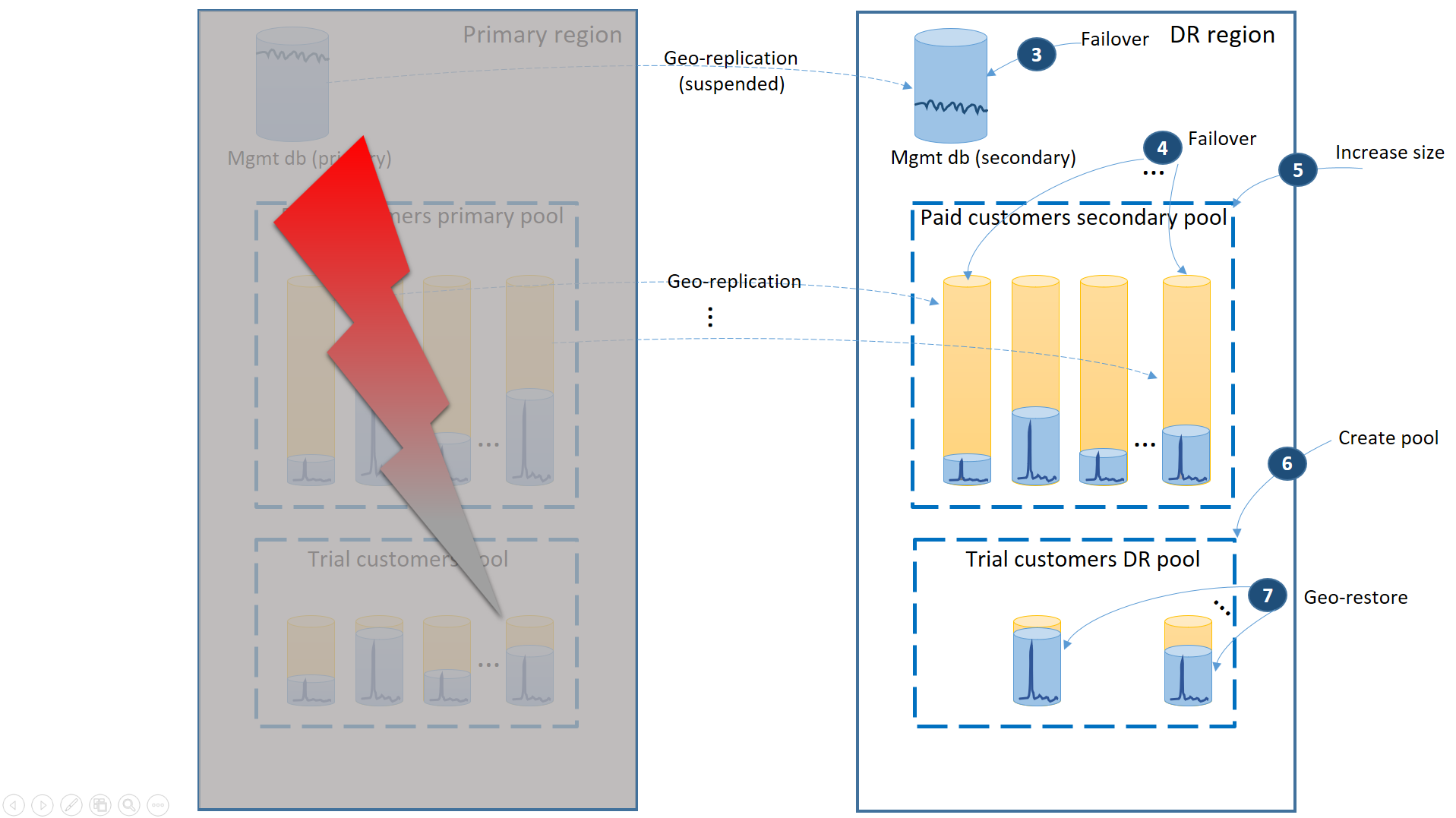
- Voer onmiddellijk een failover uit van de beheerdatabases naar de dr-regio (3).
- Wijzig de verbindingsreeks van de toepassing zodat deze verwijst naar de dr-regio. Nu worden alle nieuwe accounts en tenantdatabases gemaakt in de regio herstel na noodgeval. De bestaande proefklanten zien hun gegevens tijdelijk niet beschikbaar.
- Voer een failover uit van de databases van de betaalde tenant naar de pool in de dr-regio om de beschikbaarheid onmiddellijk te herstellen (4). Aangezien de failover een snelle wijziging op metagegevensniveau is, kunt u een optimalisatie overwegen waarbij de afzonderlijke failovers op aanvraag worden geactiveerd door de verbindingen van de eindgebruiker.
- Als de eDTU-grootte of vCore-waarde van uw secundaire pool lager was dan de primaire omdat de secundaire databases alleen de capaciteit nodig hadden om de wijzigingslogboeken te verwerken terwijl ze secundair waren, verhoogt u de poolcapaciteit onmiddellijk om de volledige workload van alle tenants (5) te kunnen verwerken.
- Maak de nieuwe elastische pool met dezelfde naam en dezelfde configuratie in de dr-regio voor de databases van de proefklanten (6).
- Zodra de pool van de proefklanten is gemaakt, gebruikt u geo-herstel om de individuele tenantdatabases voor proefversies te herstellen in de nieuwe pool (7). Overweeg om de afzonderlijke herstelbewerkingen te activeren door de verbindingen van de eindgebruiker of een ander toepassingsspecifiek prioriteitsschema te gebruiken.
Op dit moment is uw toepassing weer online in de regio dr. Alle betalende klanten hebben toegang tot hun gegevens terwijl de proefklanten vertraging ondervinden bij het openen van hun gegevens.
Wanneer de primaire regio wordt hersteld door Azure nadat u de toepassing in de regio herstel na noodgeval hebt hersteld, kunt u doorgaan met het uitvoeren van de toepassing in die regio of u kunt besluiten om een failback naar de primaire regio uit te voeren. Als de primaire regio wordt hersteld voordat het failoverproces is voltooid, kunt u direct een failback uitvoeren. De failback voert de stappen uit die worden geïllustreerd in het volgende diagram:
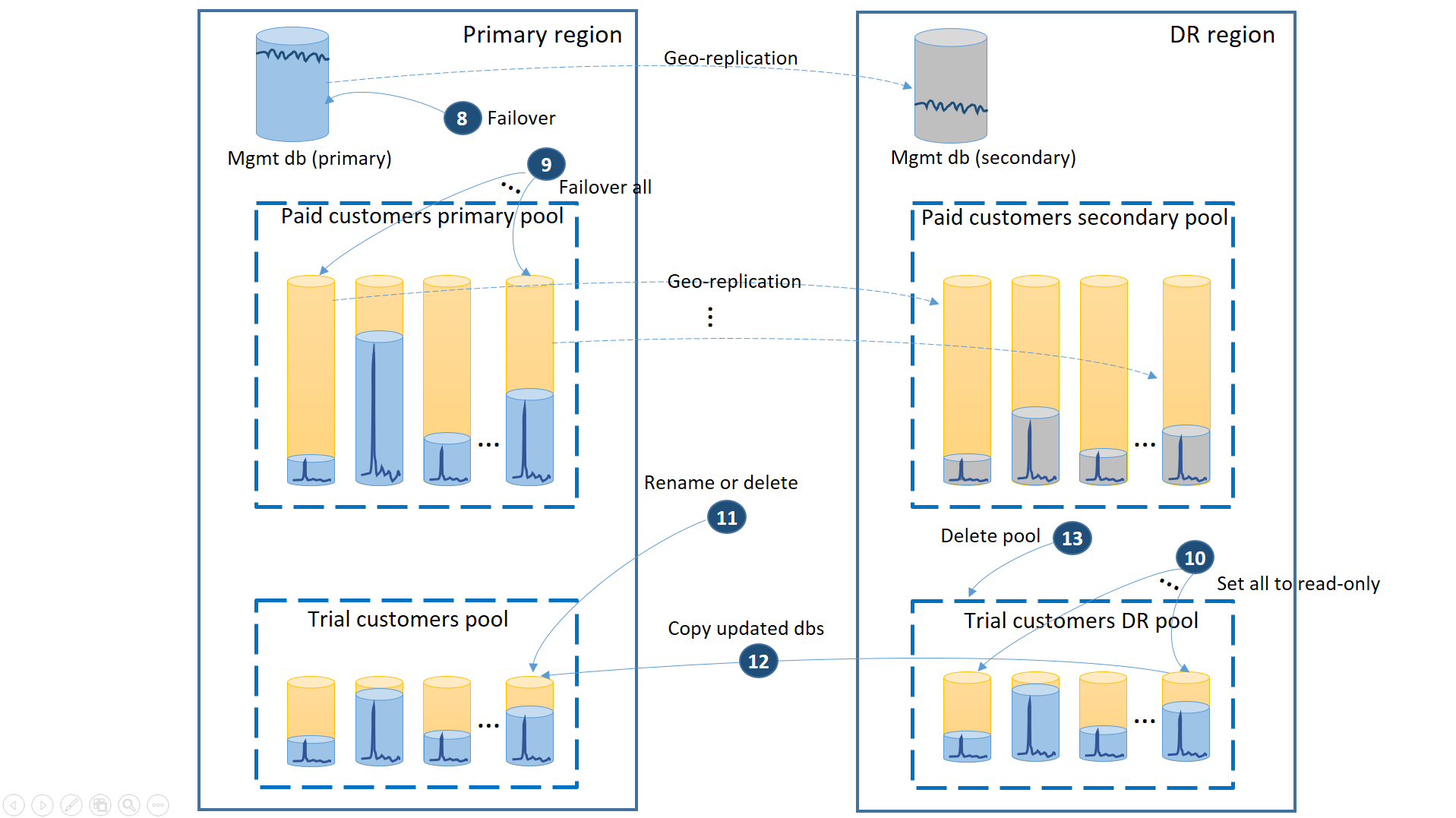
- Annuleer alle openstaande aanvragen voor geo-herstel.
- Failover van de beheerdatabases (8). Na het herstel van de regio wordt de oude primaire automatisch de secundaire. Nu wordt het weer de primaire.
- Failover van de betaalde tenantdatabases (9). Op dezelfde manier worden na het herstel van de regio de oude primaries automatisch de secundaire bestanden. Nu worden ze weer de primaries.
- Stel de herstelde proefdatabases in die zijn gewijzigd in de regio herstel na noodgeval op alleen-lezen (10).
- Voor elke database in de dr-pool van proefklanten die zijn gewijzigd sinds het herstel, wijzigt of verwijdert u de bijbehorende database in de primaire groep van proefklanten (11).
- Kopieer de bijgewerkte databases van de DR-pool naar de primaire pool (12).
- Verwijder de DR-pool (13).
Notitie
De failoverbewerking is asynchroon. Om de hersteltijd te minimaliseren, is het belangrijk dat u de failoveropdracht van de tenantdatabase uitvoert in batches van ten minste 20 databases.
Voordeel
Het belangrijkste voordeel van deze strategie is dat deze de hoogste SLA biedt voor de betalende klanten. Het garandeert ook dat de nieuwe proefversies worden gedeblokkeerd zodra de pool voor herstel na noodgeval is gemaakt.
Trade-off
De afweging is dat deze installatie de totale kosten van de tenantdatabases verhoogt door de kosten van de secundaire DR-pool voor betaalde klanten. Bovendien, als de secundaire pool een andere grootte heeft, ervaren de betalende klanten lagere prestaties na een failover totdat de poolupgrade in de regio herstel na noodgeval is voltooid.
Scenario 3. Geografisch gedistribueerde toepassing met gelaagde service
Ik heb een volwassen SaaS-toepassing met gelaagde serviceaanbiedingen. Ik wil een zeer agressieve SLA aanbieden aan mijn betaalde klanten en het risico op impact minimaliseren wanneer er storingen optreden, omdat zelfs korte onderbrekingen tot ontevreden klanten kunnen leiden. Het is essentieel dat de betalende klanten altijd toegang hebben tot hun gegevens. De proefversies zijn gratis en er wordt geen SLA aangeboden tijdens de proefperiode.
Gebruik drie afzonderlijke elastische pools om dit scenario te ondersteunen. Richt twee groepen met gelijke grootte in met hoge eDTU's of vCores per database in twee verschillende regio's om de tenantdatabases van de betaalde klanten te bevatten. De derde pool met de proeftenants kan lagere eDTU's of vCores per database hebben en worden ingericht in een van de twee regio's.
Om de laagste hersteltijd tijdens storingen te garanderen, worden de tenantdatabases van de betalende klanten geo-gerepliceerd met 50% van de primaire databases in elk van de twee regio's. Op dezelfde manier heeft elke regio 50% van de secundaire databases. Als een regio offline is, wordt slechts 50% van de databases van betaalde klanten beïnvloed en moet er een failover worden uitgevoerd. De andere databases blijven intact. Deze configuratie wordt geïllustreerd in het volgende diagram:
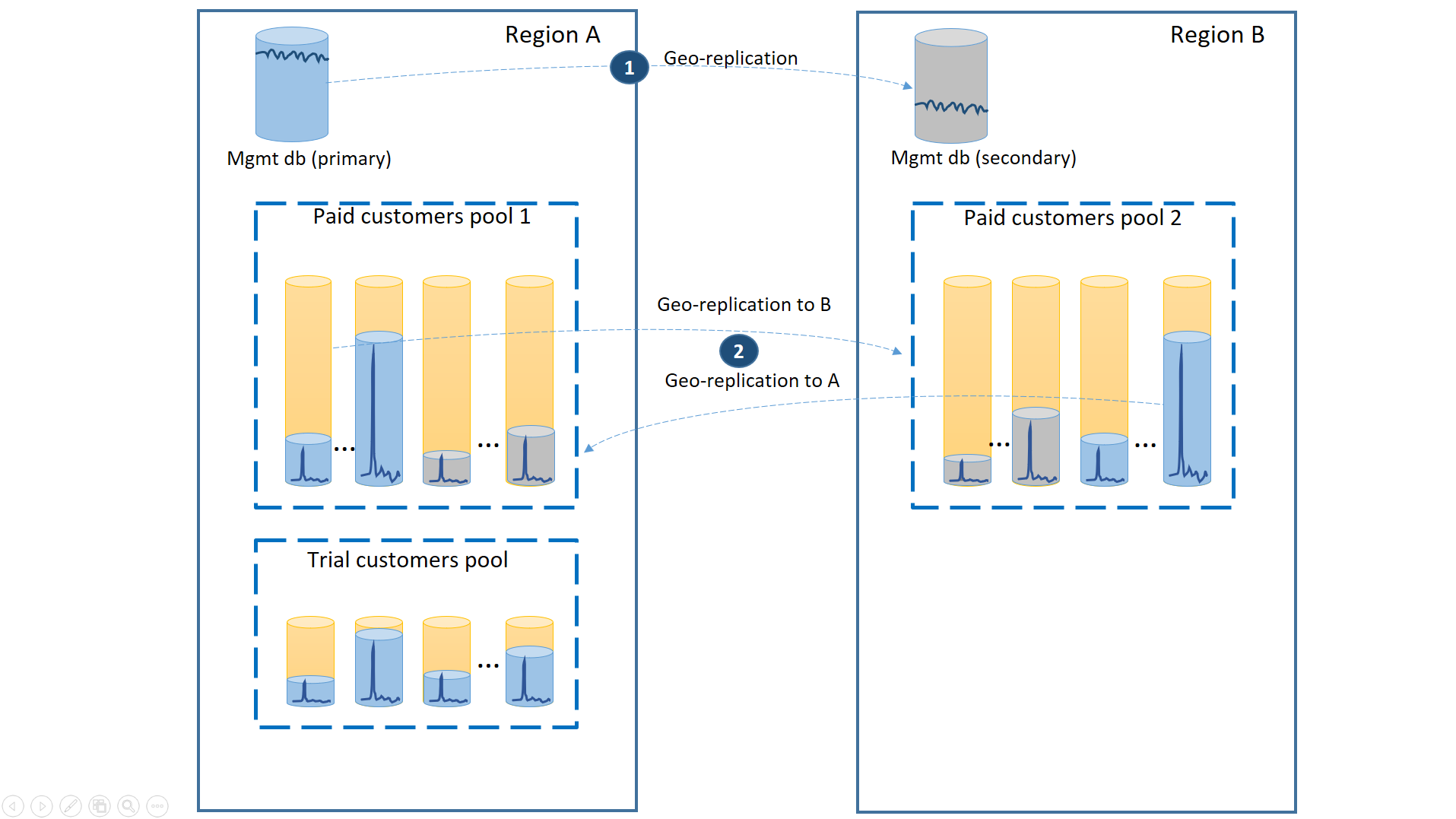
Net als in de vorige scenario's zijn de beheerdatabases vrij actief, dus configureer ze als individuele geo-gerepliceerde databases (1). Dit zorgt voor de voorspelbare prestaties van de nieuwe klantabonnementen, profielupdates en andere beheerbewerkingen. Regio A is de primaire regio voor de beheerdatabases en de regio B wordt gebruikt voor het herstel van de beheerdatabases.
De tenantdatabases van betalende klanten worden ook geo-gerepliceerd, maar met primaries en secundaire databases verdeeld tussen regio A en regio B (2). Op deze manier kunnen de primaire tenantdatabases die worden beïnvloed door de storing, een failover naar de andere regio uitvoeren en beschikbaar worden. De andere helft van de tenantdatabases wordt helemaal niet beïnvloed.
Het volgende diagram illustreert de herstelstappen die moeten worden uitgevoerd als er een storing optreedt in regio A.
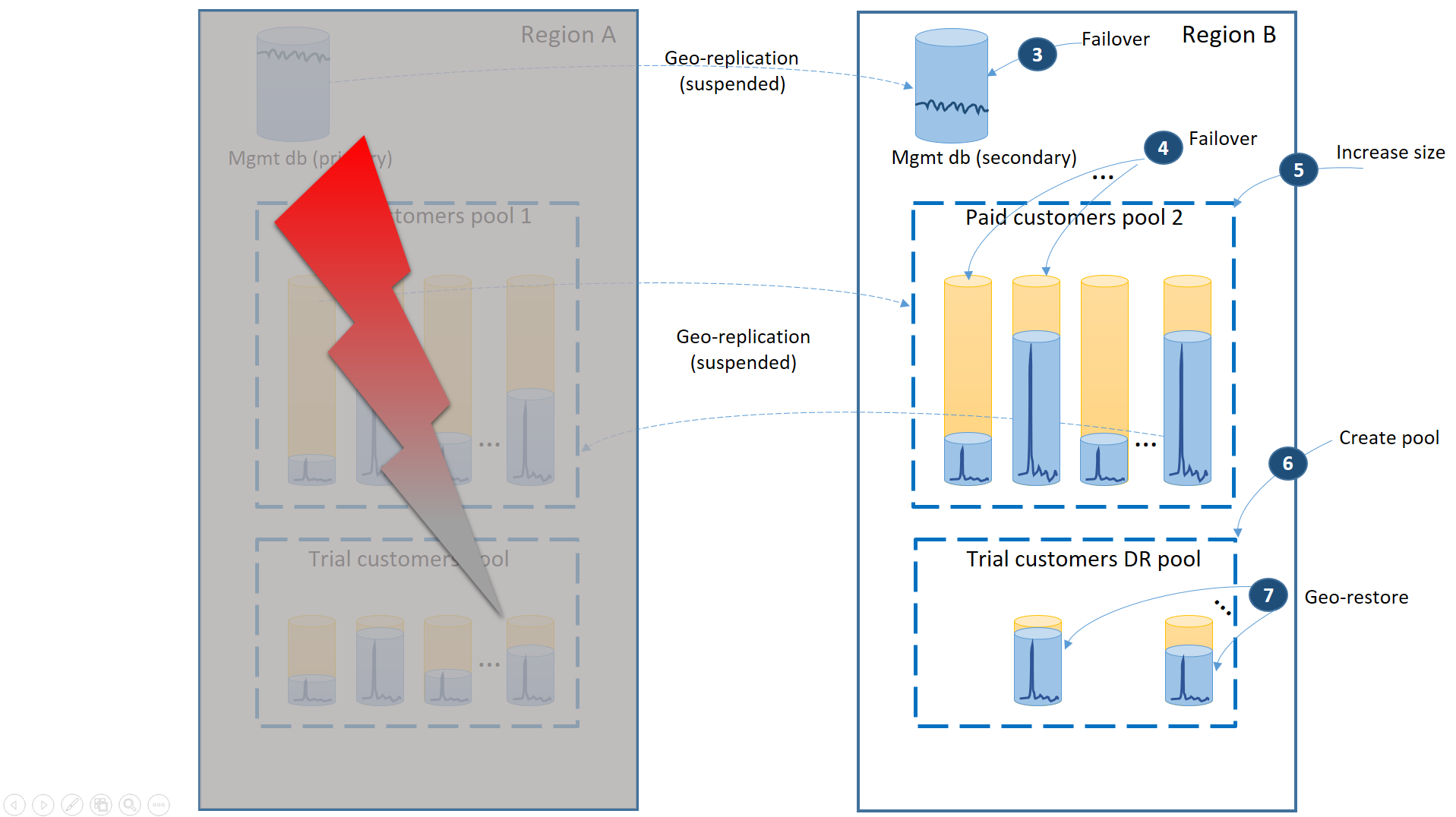
- Onmiddellijk een failover van de beheerdatabases naar regio B (3).
- Wijzig de verbindingsreeks van de toepassing zodat deze verwijst naar de beheerdatabases in regio B. Wijzig de beheerdatabases om ervoor te zorgen dat de nieuwe accounts en tenantdatabases worden gemaakt in regio B en dat de bestaande tenantdatabases daar ook worden gevonden. De bestaande proefklanten zien hun gegevens tijdelijk niet beschikbaar.
- Voer een failover uit van de databases van de betaalde tenant naar pool 2 in regio B om de beschikbaarheid onmiddellijk te herstellen (4). Aangezien de failover een snelle wijziging op metagegevensniveau is, kunt u een optimalisatie overwegen waarbij de afzonderlijke failovers op aanvraag worden geactiveerd door de verbindingen van de eindgebruiker.
- Omdat pool 2 nu alleen primaire databases bevat, neemt de totale workload in de pool toe en kan de eDTU-grootte (5) of het aantal vCores onmiddellijk worden verhoogd.
- Maak de nieuwe elastische pool met dezelfde naam en dezelfde configuratie in de regio B voor de databases van de proefklanten (6).
- Zodra de pool is gemaakt, gebruikt u geo-herstel om de individuele evaluatietenantdatabase te herstellen in de pool (7). U kunt overwegen om de afzonderlijke herstelbewerkingen te activeren door de verbindingen van eindgebruikers of een ander toepassingsspecifiek prioriteitsschema te gebruiken.
Notitie
De failoverbewerking is asynchroon. Om de hersteltijd te minimaliseren, is het belangrijk dat u de failoveropdracht van de tenantdatabases uitvoert in batches van ten minste 20 databases.
Op dit moment is uw toepassing weer online in regio B. Alle betalende klanten hebben toegang tot hun gegevens terwijl de proefklanten vertraging ondervinden bij het openen van hun gegevens.
Wanneer regio A wordt hersteld, moet u beslissen of u regio B wilt gebruiken voor proefklanten of failback voor het gebruik van de groep met proefklanten in regio A. Een criterium kan het percentage van de evaluatietenantdatabases zijn die zijn gewijzigd sinds het herstel. Ongeacht deze beslissing moet u de betaalde tenants tussen twee pools opnieuw verdelen. Het volgende diagram illustreert het proces wanneer de databases van de proeftenant een failback uitvoeren naar regio A.
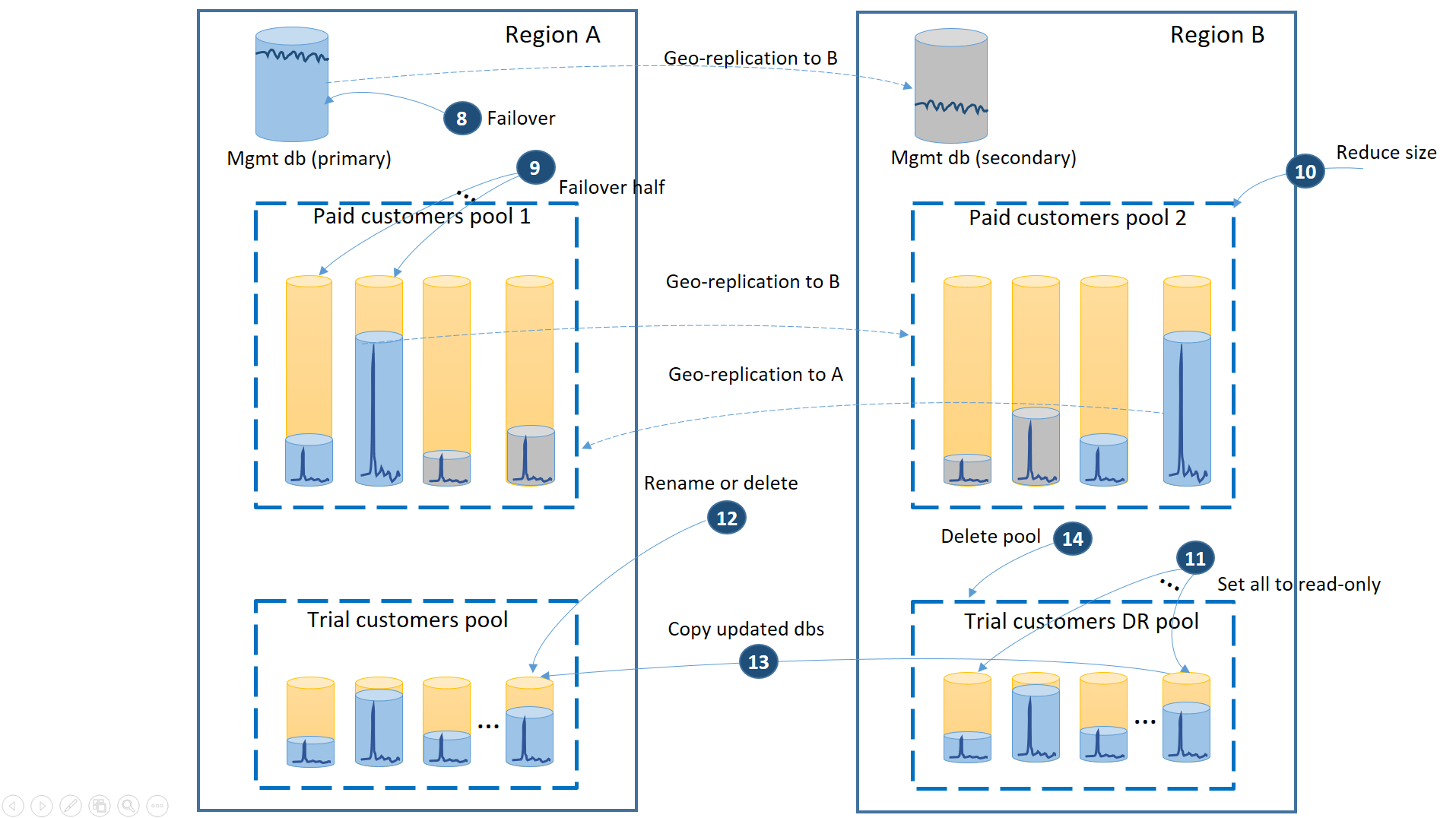
- Annuleer alle openstaande aanvragen voor geo-herstel naar de dr-pool voor de proefversie.
- Failover van de beheerdatabase (8). Na het herstel van de regio werd de oude primaire automatisch de secundaire. Nu wordt het weer de primaire.
- Selecteer welke betaalde tenantdatabases een failback uitvoeren naar pool 1 en failover naar hun secundaire bestanden initiëren (9). Na het herstel van de regio worden alle databases in groep 1 automatisch secundaire databases. Nu worden 50% van hen weer primaries.
- Verklein de grootte van pool 2 tot de oorspronkelijke eDTU (10) of het aantal vCores.
- Stel alle herstelde proefdatabases in de regio B in op alleen-lezen (11).
- Voor elke database in de evaluatie-HERSTELgroep die is gewijzigd sinds het herstel, wijzigt of verwijdert u de bijbehorende database in de primaire evaluatiegroep (12).
- Kopieer de bijgewerkte databases van de DR-pool naar de primaire pool (13).
- Verwijder de DR-pool (14).
Voordeel
De belangrijkste voordelen van deze strategie zijn:
- Het biedt ondersteuning voor de meest agressieve SLA voor de betalende klanten, omdat een storing niet meer dan 50% van de tenantdatabases kan beïnvloeden.
- Het garandeert dat de nieuwe proefversies worden gedeblokkeerd zodra de trail DR-pool wordt gemaakt tijdens het herstel.
- Het maakt efficiënter gebruik van de poolcapaciteit mogelijk omdat 50% van de secundaire databases in groep 1 en pool 2 gegarandeerd minder actief zijn dan de primaire databases.
Afwegingen
De belangrijkste afwegingen zijn:
- De CRUD-bewerkingen op basis van de beheerdatabases hebben een lagere latentie voor de eindgebruikers die zijn verbonden met regio A dan voor de eindgebruikers die zijn verbonden met regio B, omdat ze worden uitgevoerd op basis van de primaire van de beheerdatabases.
- Hiervoor is een complexer ontwerp van de beheerdatabase vereist. Elke tenantrecord heeft bijvoorbeeld een locatietag die moet worden gewijzigd tijdens de failover en failback.
- De betalende klanten kunnen lagere prestaties ervaren dan normaal totdat de poolupgrade in regio B is voltooid.
Samenvatting
Dit artikel is gericht op de strategieën voor herstel na noodgevallen voor de databaselaag die wordt gebruikt door een SaaS ISV-toepassing met meerdere tenants. De strategie die u kiest, is gebaseerd op de behoeften van de toepassing, zoals het bedrijfsmodel, de SLA die u aan uw klanten wilt aanbieden, budgetbeperking, enzovoort. Elke beschreven strategie geeft een overzicht van de voordelen en afwegingen, zodat u een weloverwogen beslissing kunt nemen. Uw specifieke toepassing bevat waarschijnlijk ook andere Azure-onderdelen. U controleert dus de richtlijnen voor bedrijfscontinuïteit en organiseert het herstel van de databaselaag met hen. Raadpleeg Cloudoplossingen ontwerpen voor herstel na noodgevallen voor meer informatie over het beheren van herstel van databasetoepassingen in Azure.
Volgende stappen
- Zie geautomatiseerde back-ups van Azure SQL Database voor meer informatie over geautomatiseerde back-ups van Azure SQL Database.
- Raadpleeg Overzicht van bedrijfscontinuïteit voor een bedrijfscontinuïteitsoverzicht en bedrijfscontinuïteitsscenario's.
- Voor meer informatie over het gebruik van geautomatiseerde back-ups voor herstel raadpleegt u het herstellen van een database vanuit de door de service geïnitieerde back-ups.
- Zie Actieve geo-replicatie en failovergroepen voor meer informatie over snellere herstelopties.
- Zie databasekopie voor meer informatie over het gebruik van geautomatiseerde back-ups voor archivering.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor