Een failovergroep configureren voor Azure SQL Database
Van toepassing op:![]() Azure SQL Database
Azure SQL Database
In dit artikel leert u hoe u een failovergroep configureert voor individuele en pooldatabases in Azure SQL Database met behulp van Azure Portal, Azure PowerShell en de Azure CLI.
Voor end-to-endscripts bekijkt u hoe u één database toevoegt aan een failovergroep met Azure PowerShell of de Azure CLI.
Vereisten
Houd rekening met de volgende vereisten voor het maken van uw failovergroep voor één database:
- De serveraanmelding en firewallinstellingen voor de secundaire server moeten overeenkomen met die van uw primaire server.
Failovergroep maken
Maak uw failovergroep en voeg uw individuele database eraan toe met behulp van Azure Portal.
Selecteer Azure SQL in het menu aan de linkerkant van de Azure-portal. Als Azure SQL niet in de lijst staat, selecteert u Alle services en typt u Azure SQL in het zoekvak. (Optioneel) Selecteer de ster naast Azure SQL om deze te favoriseren en voeg deze als item in de linkernavigatiebalk toe.
Selecteer de database die u wilt toevoegen aan de failovergroep.
Selecteer de naam van de server onder Servernaam om de instellingen voor de server te openen.

Selecteer Failovergroepen onder het deelvenster Instellingen en selecteer vervolgens Groep toevoegen om een nieuwe failovergroep te maken.
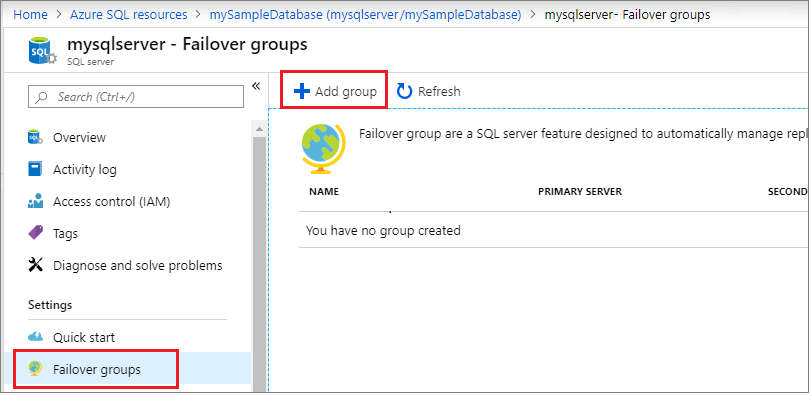
Voer op de pagina Failovergroep de vereiste waarden in of selecteer deze en selecteer vervolgens Maken. Maak een nieuwe secundaire server of selecteer een bestaande secundaire server. De secundaire server in de failovergroep moet zich in een andere regio bevinden dan de primaire server.
- Databases in de groep: kies de database die u wilt toevoegen aan uw failovergroep. Door de database aan de failovergroep toe te voegen, wordt het proces voor geo-replicatie automatisch gestart.
Geplande failover testen
Test de failover van uw failovergroep zonder gegevensverlies met behulp van Azure Portal of PowerShell.
Test de failover van uw failovergroep met behulp van de Azure-portal.
Selecteer Azure SQL in het menu aan de linkerkant van de Azure-portal. Als Azure SQL zich niet in de lijst bevindt, selecteert u Alle services en typt u 'Azure SQL' in het zoekvak. (Optioneel) Selecteer de ster naast Azure SQL om deze te favoriseren en voeg deze als item in de linkernavigatiebalk toe.
Selecteer de database die u wilt toevoegen aan de failovergroep.
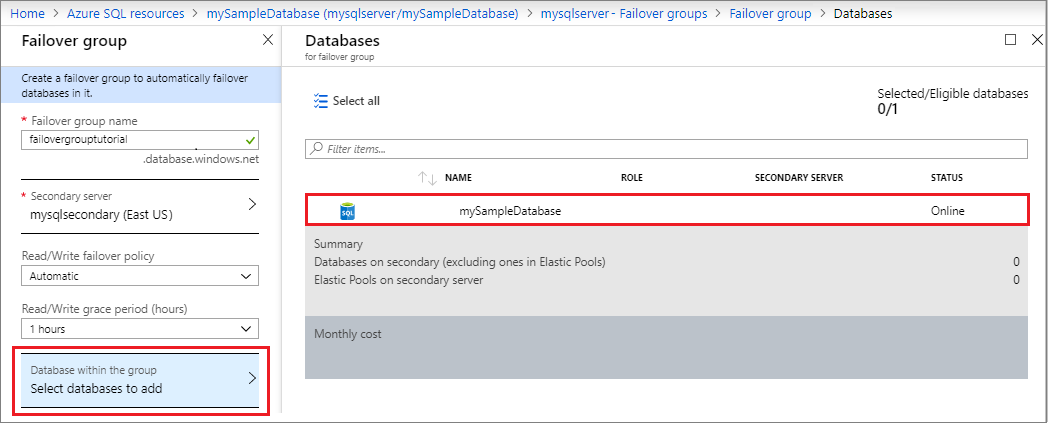
Selecteer Failovergroepen in het deelvenster Instellingen en kies vervolgens de failovergroep die u zojuist hebt gemaakt.
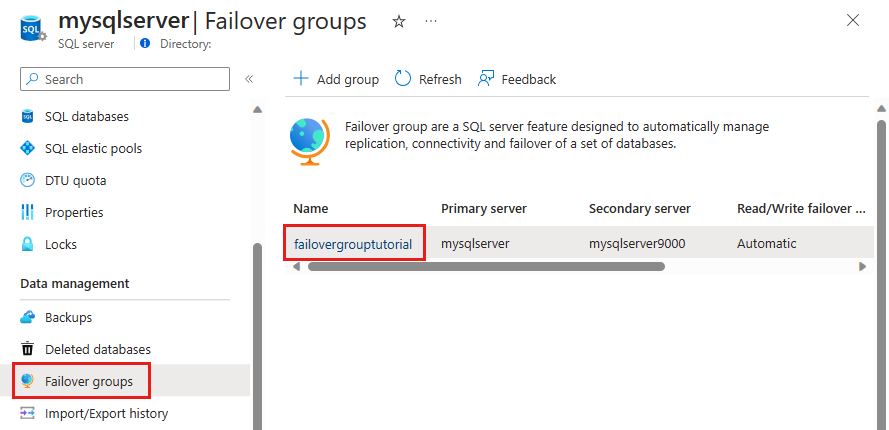
Controleer welke server primair en welke server secundair is.
Selecteer Failover in het taakvenster om een failover van uw failovergroep met uw database uit te voeren.
Selecteer Ja bij de waarschuwing die u laat weten dat TDS-sessies worden losgekoppeld.
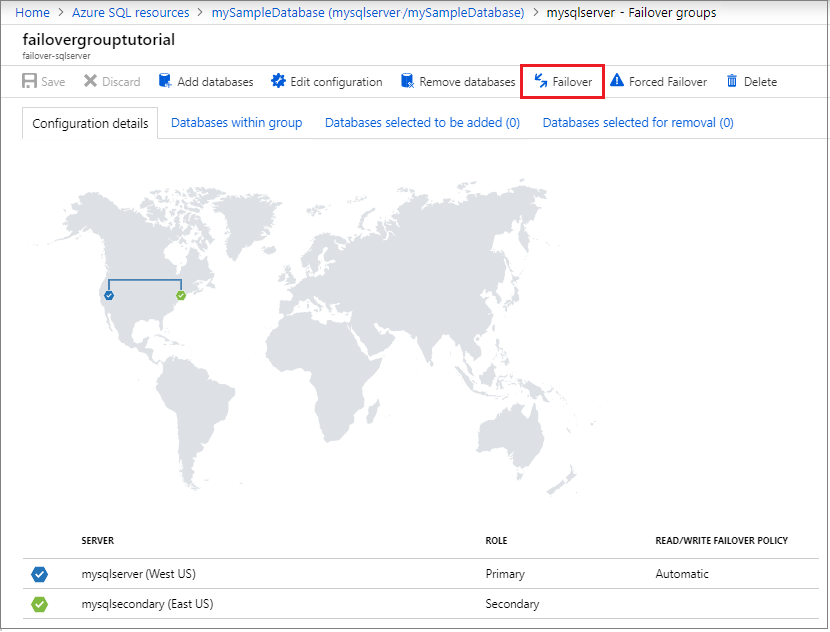
Controleer welke server nu primair en welke server secundair is. Als de failover is geslaagd, moeten de twee servers van rol zijn gewisseld.
Selecteer opnieuw Failover om de oorspronkelijke rollen van de servers te herstellen.
Belangrijk
Als u de secundaire database wilt verwijderen, verwijdert u deze uit de failovergroep voordat u deze verwijdert. Het wissen van een secundaire database voordat deze uit de failovergroep is verwijderd, kan onvoorspelbaar gedrag veroorzaken.
Bekijk hoe u een elastische pool toevoegt aan een failovergroep met Azure PowerShell of de Azure CLI voor end-to-endscripts.
Vereisten
Houd rekening met de volgende vereisten voor het maken van uw failovergroep voor een pooldatabase:
- De serveraanmelding en firewallinstellingen voor de secundaire server moeten overeenkomen met die van uw primaire server.
Failovergroep maken
Maak de failovergroep voor uw elastische pool met behulp van Azure Portal of PowerShell.
Maak uw failovergroep en voeg uw elastische pool eraan toe met behulp van Azure Portal.
Selecteer Azure SQL in het menu aan de linkerkant van de Azure-portal. Als Azure SQL zich niet in de lijst bevindt, selecteert u Alle services en typt u 'Azure SQL' in het zoekvak. (Optioneel) Selecteer de ster naast Azure SQL om deze te favoriseren en voeg deze als item in de linkernavigatiebalk toe.
Selecteer de elastische pool die u wilt toevoegen aan de failovergroep.
Selecteer in het deelvenster Overzicht de naam van de server onder Servernaam om de instellingen voor de server te openen.
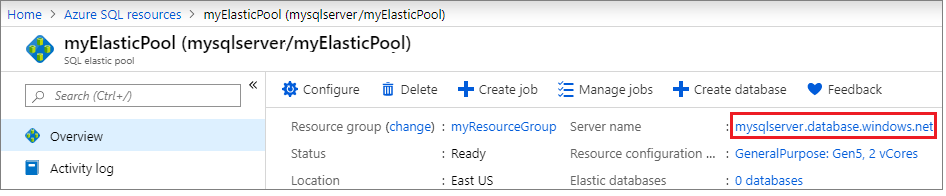
Selecteer Failovergroepen onder het deelvenster Instellingen en selecteer vervolgens Groep toevoegen om een nieuwe failovergroep te maken.
Voer op de pagina Failovergroep de vereiste waarden in of selecteer deze en selecteer vervolgens Maken. Maak een nieuwe secundaire server of selecteer een bestaande secundaire server.
Selecteer Databases in de groep en kies de elastische pool die u wilt toevoegen aan de failovergroep. Als er nog geen elastische pool op de secundaire server bestaat, wordt u gevraagd een elastische pool te maken op de secundaire server. Selecteer de waarschuwing en selecteer vervolgens OK om de elastische pool te maken op de secundaire server.
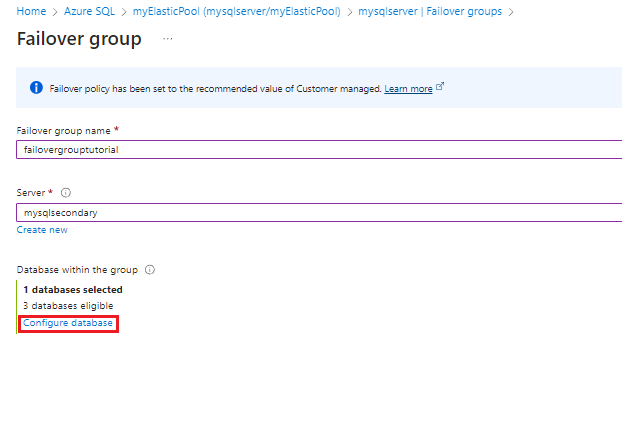
Gebruik Select om de instellingen van uw elastische pool toe te passen op de failovergroep en selecteer vervolgens Maken om uw failovergroep te maken. Door de elastische pool aan de failovergroep toe te voegen, wordt het proces voor geo-replicatie automatisch gestart.
Geplande failover testen
Test failover zonder gegevensverlies van uw elastische pool met behulp van Azure Portal of PowerShell.
Voer een failovergroep uit naar de secundaire server en voer vervolgens een failback uit met behulp van Azure Portal.
Selecteer Azure SQL in het menu aan de linkerkant van de Azure-portal. Als Azure SQL zich niet in de lijst bevindt, selecteert u Alle services en typt u 'Azure SQL' in het zoekvak. (Optioneel) Selecteer de ster naast Azure SQL om deze te favoriseren en voeg deze als item in de linkernavigatiebalk toe.
Selecteer de elastische pool waarvoor u een failover wilt uitvoeren.
Selecteer in het deelvenster Overzicht de naam van de server onder Servernaam om de instellingen voor de server te openen.
Selecteer Failovergroepen onder Instellingen en kies vervolgens de failovergroep die u eerder hebt gemaakt.
Controleer welke server primair en welke server secundair is.
Selecteer in het taakvenster Failover om een failover van uw failovergroep met elastische groepen uit te voeren.
Selecteer Ja bij de waarschuwing die u laat weten dat TDS-sessies worden losgekoppeld.
Controleer welke server primair en welke server secundair is. Als de failover is geslaagd, moeten de twee servers van rol zijn gewisseld.
Selecteer opnieuw Failover om de failovergroep te herstellen naar de oorspronkelijke instellingen.
Belangrijk
Als u de secundaire database wilt verwijderen, verwijdert u deze uit de failovergroep voordat u deze verwijdert. Het wissen van een secundaire database voordat deze uit de failovergroep is verwijderd, kan onvoorspelbaar gedrag veroorzaken.
Private Link gebruiken
Met een privékoppeling kunt u een logische server koppelen aan een specifiek privé-IP-adres binnen het virtuele netwerk en subnet.
Ga als volgt te werk om een privékoppeling te gebruiken met uw failovergroep:
- Zorg ervoor dat uw primaire en secundaire servers zich in een gekoppelde regio bevinden.
- Maak het virtuele netwerk en subnet in elke regio om privé-eindpunten te hosten voor primaire en secundaire servers, zodat ze niet-overlapping VAN IP-adresruimten hebben. Bijvoorbeeld: het adresbereik van het primaire virtuele netwerk van 10.0.0.0/16 en het adresbereik van het secundaire virtuele netwerk van 10.0.0.1/16 overlappen. Raadpleeg de blog over het ontwerpen van virtuele Azure-netwerken voor meer informatie over adresbereiken van virtuele netwerken.
- Maak een privé-eindpunt en een privé Azure DNS-zone voor de primaire server.
- Maak ook een privé-eindpunt voor de secundaire server, maar kies er deze keer voor om de privé DNS-zone die voor de primaire server is gemaakt, opnieuw te gebruiken.
- Zodra de private link tot stand is gebracht, kunt u de failovergroep maken volgens de stappen die eerder in dit artikel zijn beschreven.
Listener-eindpunt zoeken
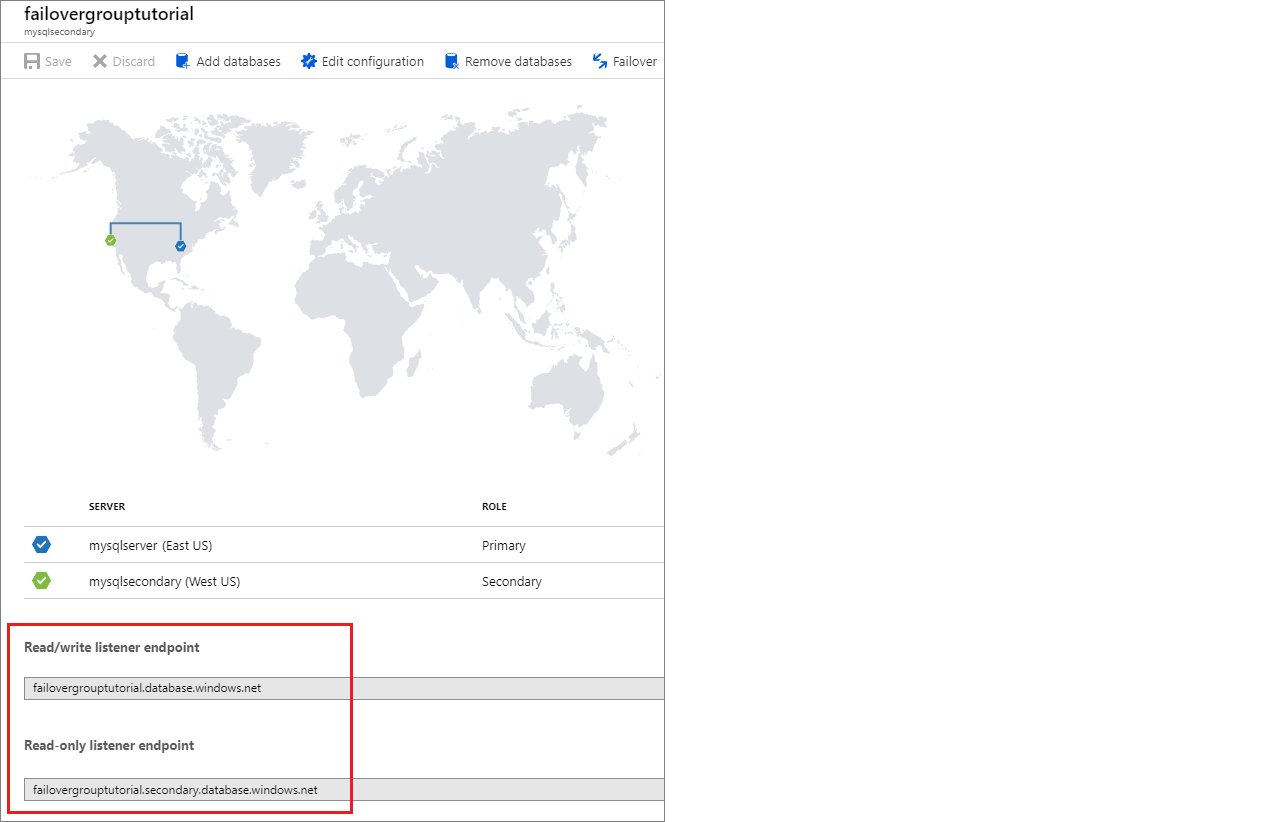
Zodra uw failovergroep is geconfigureerd, werkt u de verbindingsreeks voor uw toepassing bij naar het listener-eindpunt. Hierdoor blijft uw toepassing verbonden met de listener van de failovergroep in plaats van de primaire database of elastische pool. Op die manier hoeft u de verbindingsreeks niet handmatig bij te werken telkens wanneer uw database-entiteit een failover uitvoert en verkeer wordt doorgestuurd naar de entiteit die momenteel primair is.
Het listener-eindpunt heeft de vorm van fog-name.database.windows.neten is zichtbaar in Azure Portal bij het weergeven van de failovergroep:
Databases schalen in een failovergroep
U kunt de primaire database omhoog of omlaag schalen naar een andere rekenkracht (binnen dezelfde servicelaag) zonder de verbinding met geo-secundaire databases te verbreken. Wanneer u omhoog schaalt, raden we u aan om eerst de geo-secundaire locatie omhoog te schalen en vervolgens de primaire op te schalen. Wanneer u omlaag schaalt, draait u de volgorde om: schaal eerst de primaire database omlaag en schaal vervolgens de secundaire database omlaag. Wanneer u een database schaalt naar een andere servicelaag, wordt deze aanbeveling afgedwongen.
Deze reeks wordt specifiek aanbevolen om te voorkomen dat het probleem waarbij de geo-secundaire bij een lagere SKU overbelast raakt en opnieuw moet worden verzonden tijdens een upgrade- of downgradeproces. U kunt dit probleem ook vermijden door het primaire exemplaar alleen-lezen te maken. Dit gaat ten koste van alle lezen/schrijven-werkbelastingen die zijn gekoppeld aan het primaire exemplaar.
Notitie
Als u een geo-secundaire database hebt gemaakt als onderdeel van een failovergroepsconfiguratie, wordt het afgeraden de geo-secundaire omlaag te schalen. Zo zorgt u ervoor dat uw gegevenslaag voldoende capaciteit heeft om uw normale workload te verwerken nadat een geo-failover is geactiveerd. Mogelijk kunt u geen geo-secundaire schaal schalen na een ongeplande failover wanneer de voormalige geo-primaire niet beschikbaar is vanwege een storing. Dit is een bekende beperking.
Verlies van kritieke gegevens voorkomen
Vanwege de hoge latentie van wide area networks maakt geo-replicatie gebruik van een asynchroon replicatiemechanisme. Asynchrone replicatie maakt de mogelijkheid van gegevensverlies onvermijdelijk als de primaire mislukt. Een toepassingsontwikkelaar kan de sp_wait_for_database_copy_sync opgeslagen procedure onmiddellijk na het doorvoeren van de transactie aanroepen om kritieke transacties te beschermen tegen gegevensverlies. Het aanroepen sp_wait_for_database_copy_sync blokkeert de aanroepende thread totdat de laatste doorgevoerde transactie is verzonden en beperkt in het transactielogboek van de secundaire database. Er wordt echter niet gewacht totdat de verzonden transacties opnieuw worden afgespeeld (opnieuw worden afgespeeld) op de secundaire. sp_wait_for_database_copy_sync is gericht op een specifieke geo-replicatiekoppeling. Elke gebruiker met de verbindingsrechten voor de primaire database kan deze procedure aanroepen.
Notitie
sp_wait_for_database_copy_sync voorkomt gegevensverlies na geo-failover voor specifieke transacties, maar garandeert geen volledige synchronisatie voor leestoegang. De vertraging die wordt veroorzaakt door een sp_wait_for_database_copy_sync procedure-aanroep kan aanzienlijk zijn en is afhankelijk van de grootte van het nog niet verzonden transactielogboek op de primaire op het moment van de oproep.
De secundaire regio wijzigen
Ter illustratie van de wijzigingsreeks gaan we ervan uit dat server A de primaire server is, server B de bestaande secundaire server is en server C de nieuwe secundaire is in de derde regio. Voer de volgende stappen uit om de overgang te maken:
- Maak extra secundaire databases van elke database op server A naar server C met behulp van actieve geo-replicatie. Elke database op server A heeft twee secundaire bestanden, één op server B en één op server C. Dit garandeert dat de primaire databases tijdens de overgang beveiligd blijven.
- Verwijder de failovergroep. Op dit moment beginnen aanmeldingspogingen met behulp van failovergroepeindpunten te mislukken.
- Maak de failovergroep opnieuw met dezelfde naam tussen servers A en C.
- Voeg alle primaire databases op server A toe aan de nieuwe failovergroep. Op dit moment mislukken aanmeldingspogingen.
- Server B verwijderen. Alle databases op B worden automatisch verwijderd.
De primaire regio wijzigen
Ter illustratie van de wijzigingsreeks gaan we ervan uit dat server A de primaire server is, server B de bestaande secundaire server is en server C de nieuwe primaire server in de derde regio is. Voer de volgende stappen uit om de overgang te maken:
- Voer een geplande geo-failover uit om de primaire server over te zetten naar B. Server A wordt de nieuwe secundaire server. De failover kan enkele minuten downtime tot gevolg hebben. De werkelijke tijd is afhankelijk van de grootte van de failovergroep.
- Maak extra secundaire databases van elke database op server B naar server C met behulp van actieve geo-replicatie. Elke database op server B heeft twee secundaire bestanden, één op server A en één op server C. Dit garandeert dat de primaire databases tijdens de overgang beveiligd blijven.
- Verwijder de failovergroep. Op dit moment beginnen aanmeldingspogingen met behulp van failovergroepeindpunten te mislukken.
- Maak de failovergroep opnieuw met dezelfde naam tussen servers B en C.
- Voeg alle primaire databases op B toe aan de nieuwe failovergroep. Op dit moment mislukken aanmeldingspogingen.
- Voer een geplande geo-failover van de failovergroep uit om over te schakelen tussen B en C. Server C wordt nu de primaire en B de secundaire. Alle secundaire databases op server A worden automatisch gekoppeld aan de primaries op C. Net als in stap 1 kan de failover leiden tot enkele minuten downtime.
- Server A verwijderen. Alle databases op A worden automatisch verwijderd.
Belangrijk
Wanneer de failovergroep wordt verwijderd, worden de DNS-records voor de listener-eindpunten ook verwijderd. Op dat moment is er een niet-nul waarschijnlijkheid dat iemand anders een failovergroep of een server-DNS-alias met dezelfde naam maakt. Omdat namen van failovergroepen en DNS-aliassen wereldwijd uniek moeten zijn, voorkomt u dat u dezelfde naam opnieuw gebruikt. Gebruik geen algemene namen van failovergroepen om dit risico te minimaliseren.
Failovergroepen en netwerkbeveiliging
Voor sommige toepassingen moeten de beveiligingsregels ervoor zorgen dat de netwerktoegang tot de gegevenslaag wordt beperkt tot een specifiek onderdeel of een specifiek onderdeel, zoals een VM, webservice, enzovoort. Deze vereiste biedt enkele uitdagingen voor het ontwerp van bedrijfscontinuïteit en het gebruik van failovergroepen. Houd rekening met de volgende opties bij het implementeren van dergelijke beperkte toegang.
Failovergroepen en service-eindpunten voor virtuele netwerken gebruiken
Als u service-eindpunten en regels voor virtuele netwerken gebruikt om de toegang tot uw database te beperken, moet u er rekening mee houden dat elk service-eindpunt van het virtuele netwerk slechts van toepassing is op slechts één Azure-regio. Met het eindpunt kunnen andere regio's geen communicatie van het subnet accepteren. Daarom kunnen alleen de clienttoepassingen die in dezelfde regio zijn geïmplementeerd, verbinding maken met de primaire database. Omdat een geo-failover resulteert in de SQL Database-clientsessies die worden omgeleid naar een server in een andere (secundaire) regio, kunnen deze sessies mislukken als deze afkomstig zijn van een client buiten die regio. Daarom kan het door Microsoft beheerde failoverbeleid niet worden ingeschakeld als de deelnemende servers zijn opgenomen in de regels voor het virtuele netwerk. Voer de volgende stappen uit om handmatig failoverbeleid te ondersteunen:
- Richt redundante kopieën van de front-endonderdelen van uw toepassing (webservice, virtuele machines enzovoort) in de secundaire regio in.
- Configureer regels voor virtuele netwerken afzonderlijk voor de primaire en secundaire server.
- Schakel front-endfailover in met behulp van een Traffic Manager-configuratie.
- Start een handmatige geo-failover wanneer de storing wordt gedetecteerd. Deze optie is geoptimaliseerd voor toepassingen die consistente latentie tussen de front-end en de gegevenslaag vereisen en ondersteuning biedt voor herstel wanneer front-end, gegevenslaag of beide worden beïnvloed door de storing.
Notitie
Als u de alleen-lezen-listener gebruikt om een alleen-lezen workload te verdelen, moet u ervoor zorgen dat deze werkbelasting wordt uitgevoerd in een VIRTUELE machine of een andere resource in de secundaire regio, zodat deze verbinding kan maken met de secundaire database.
Failovergroepen en firewallregels gebruiken
Als voor uw bedrijfscontinuïteitsplan failover met failovergroepen is vereist, kunt u de toegang tot uw SQL Database beperken met behulp van openbare IP-firewallregels. Deze configuratie zorgt ervoor dat een geo-failover verbindingen van front-endonderdelen niet blokkeert en ervan uitgaat dat de toepassing de langere latentie tussen de front-end en de gegevenslaag kan tolereren.
Voer de volgende stappen uit om failovergroepfailover te ondersteunen:
- Maak een openbaar IP-adres.
- Maak een openbare load balancer en wijs het openbare IP-adres eraan toe.
- Maak een virtueel netwerk en de virtuele machines voor uw front-endonderdelen.
- Maak een netwerkbeveiligingsgroep en configureer binnenkomende verbindingen.
- Zorg ervoor dat de uitgaande verbindingen zijn geopend voor Azure SQL Database in een regio met behulp van een
Sql.<Region>servicetag. - Maak een SQL Database-firewallregel om inkomend verkeer toe te staan van het openbare IP-adres dat u in stap 1 maakt.
Zie uitgaande verbindingen van Load Balancer voor meer informatie over het configureren van uitgaande toegang en welk IP-adres moet worden gebruikt in de firewallregels.
Belangrijk
Als u bedrijfscontinuïteit wilt garanderen tijdens regionale storingen, moet u geografische redundantie garanderen voor zowel front-endonderdelen als databases.
Bevoegdheden
Machtigingen voor een failovergroep worden beheerd via op rollen gebaseerd toegangsbeheer van Azure (Azure RBAC).
Schrijftoegang van Azure RBAC is nodig voor het maken en beheren van failovergroepen. De rol INzender voor SQL Server heeft alle benodigde machtigingen voor het beheren van failovergroepen.
De volgende tabel bevat specifieke machtigingsbereiken voor Azure SQL Database:
| Actie | Machtiging | Scope |
|---|---|---|
| Failovergroep maken | Schrijftoegang van Azure RBAC | Secundaire server primaire server Alle databases in failovergroep |
| Failovergroep bijwerken | Schrijftoegang van Azure RBAC | Failovergroep Alle databases op de huidige primaire server |
| Failovergroep | Schrijftoegang van Azure RBAC | Failovergroep op nieuwe server |
Beperkingen
Houd rekening met de volgende beperkingen:
- Failovergroepen kunnen niet worden gemaakt tussen twee servers in dezelfde Azure-regio.
- Failovergroepen ondersteunen geo-replicatie van alle databases in de groep naar slechts één secundaire logische server in een andere regio.
- Namen van failovergroepen kunnen niet worden gewijzigd. U moet de groep verwijderen en opnieuw maken met een andere naam.
- De naam van de database wordt niet ondersteund voor databases in een failovergroep. U moet de failovergroep tijdelijk verwijderen om de naam van een database te kunnen wijzigen of de database te verwijderen uit de failovergroep.
- Het verwijderen van een failovergroep voor een enkele of pooldatabase stopt de replicatie niet en verwijdert de gerepliceerde database niet. U moet geo-replicatie handmatig stoppen en de database verwijderen van de secundaire server als u een individuele of pooldatabase weer wilt toevoegen aan een failovergroep nadat deze is verwijderd. Als u dit niet doet, kan dit resulteren in een fout die vergelijkbaar is met
The operation cannot be performed due to multiple errorswanneer u de database probeert toe te voegen aan de failovergroep. - Naam van failovergroep is onderhevig aan naamgevingsbeperkingen.
Failovergroepen programmatisch beheren
Failovergroepen kunnen ook programmatisch worden beheerd met behulp van Azure PowerShell, Azure CLI en REST API. In de volgende tabellen wordt de set opdrachten beschreven die beschikbaar zijn. Failovergroepen bevatten een set Azure Resource Manager-API's voor beheer, waaronder de Azure SQL Database REST API en Azure PowerShell-cmdlets. Deze API's vereisen het gebruik van resourcegroepen en ondersteunen op rollen gebaseerd toegangsbeheer van Azure (Azure RBAC). Zie Op rollen gebaseerd toegangsbeheer van Azure (Azure RBAC) voor meer informatie over het implementeren van toegangsrollen.
| Cmdlet | Beschrijving |
|---|---|
| New-AzSqlDatabaseFailoverGroup | Met deze opdracht maakt u een failovergroep en registreert u deze op zowel primaire als secundaire servers |
| Remove-AzSqlDatabaseFailoverGroup | Hiermee verwijdert u een failovergroep van de server |
| Get-AzSqlDatabaseFailoverGroup | Hiermee wordt de configuratie van een failovergroep opgehaald |
| Set-AzSqlDatabaseFailoverGroup | Wijzigt de configuratie van een failovergroep |
| Switch-AzSqlDatabaseFailoverGroup | Hiermee wordt een failover van een failovergroep naar de secundaire server geactiveerd |
| Add-AzSqlDatabaseToFailoverGroup | Een of meer databases toevoegen aan een failovergroep |
Notitie
Het is mogelijk om uw failovergroep tussen abonnementen te implementeren met behulp van de -PartnerSubscriptionId parameter in Azure Powershell, te beginnen met Az.SQL 3.11.0. Raadpleeg het volgende voorbeeld voor meer informatie.
Volgende stappen
Zie geo-replicatie- en failovergroepen voor een overzicht van opties voor hoge beschikbaarheid van Azure SQL Database.