Bestandsruimte voor databases in Azure SQL Database beheren
Van toepassing op:![]() Azure SQL Database
Azure SQL Database
In dit artikel worden verschillende typen opslagruimte voor databases in Azure SQL Database beschreven en stappen die kunnen worden uitgevoerd wanneer de toegewezen bestandsruimte expliciet moet worden beheerd.
Overzicht
Met Azure SQL Database zijn er workloadpatronen waarbij de toewijzing van onderliggende gegevensbestanden voor databases groter kan worden dan het aantal gebruikte gegevenspagina's. Deze voorwaarde kan optreden wanneer de gebruikte ruimte toeneemt en gegevens later worden verwijderd. De reden is omdat toegewezen bestandsruimte niet automatisch opnieuw wordt vrijgemaakt wanneer gegevens worden verwijderd.
Mogelijk moet u in de volgende scenario's het gebruik van bestandsruimte bewaken en gegevensbestanden verkleinen:
- Sta groei van gegevens in een elastische pool toe als de toegewezen bestandsruimte voor de databases de maximale grootte van de pool bereikt.
- Sta toe dat de maximale grootte van één database of elastische pool wordt verkleind.
- Sta toe dat databases en elastische pools afzonderlijk naar een andere servicelaag of prestatielaag kunnen worden omgezet met een kleinere maximale grootte.
Notitie
Verkleiningsbewerkingen mogen niet worden beschouwd als een normale onderhoudsbewerking. Voor gegevens- en logboekbestanden die groeien als gevolg van regelmatige, terugkerende bedrijfsbewerkingen zijn geen verkleiningsbewerkingen vereist.
Gebruik van bestandsruimte bewaken
De meeste metrische gegevens over opslagruimte die worden weergegeven in de volgende API's meten alleen de grootte van gebruikte gegevenspagina's:
- Api's voor metrische gegevens op basis van Azure Resource Manager, waaronder get-metrics van PowerShell
De volgende API's meten echter ook de grootte van de ruimte die is toegewezen voor databases en elastische pools:
- T-SQL: sys.resource_stats
- T-SQL: sys.elastic_pool_resource_stats
Inzicht in typen opslagruimte voor een database
Inzicht in de volgende hoeveelheden opslagruimte zijn belangrijk voor het beheren van de bestandsruimte van een database.
| Databasehoeveelheid | Definitie | Opmerkingen |
|---|---|---|
| Gebruikte gegevensruimte | De hoeveelheid ruimte die wordt gebruikt voor het opslaan van databasegegevens. | Over het algemeen neemt de gebruikte ruimte toe (neemt af) bij invoegingen (verwijderingen). In sommige gevallen verandert de gebruikte ruimte niet bij invoegingen of verwijderingen, afhankelijk van de hoeveelheid en het patroon van gegevens die betrokken zijn bij de bewerking en eventuele fragmentatie. Als u bijvoorbeeld één rij uit elke gegevenspagina verwijdert, wordt de gebruikte ruimte niet noodzakelijkerwijs verkleind. |
| Toegewezen gegevensruimte | De hoeveelheid opgemaakte bestandsruimte die beschikbaar is voor het opslaan van databasegegevens. | De hoeveelheid toegewezen ruimte groeit automatisch, maar neemt na verwijderen nooit af. Dit gedrag zorgt ervoor dat toekomstige invoegingen sneller zijn, omdat ruimte niet opnieuw hoeft te worden opgemaakt. |
| Toegewezen gegevensruimte, maar niet gebruikt | Het verschil tussen de hoeveelheid toegewezen gegevensruimte en de gebruikte gegevensruimte. | Deze hoeveelheid vertegenwoordigt de maximale hoeveelheid vrije ruimte die kan worden vrijgemaakt door databasegegevensbestanden te verkleinen. |
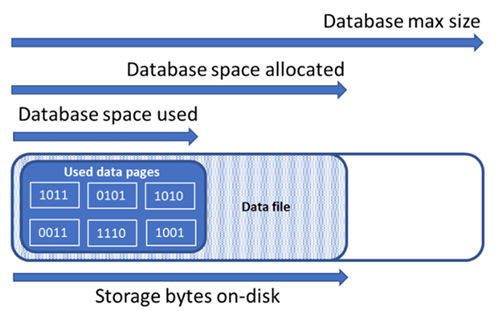
| Maximale grootte van gegevens | De maximale hoeveelheid ruimte die kan worden gebruikt voor het opslaan van databasegegevens. | De hoeveelheid toegewezen gegevensruimte kan niet groter worden dan de maximale grootte van de gegevens. |
In het volgende diagram ziet u de relatie tussen de verschillende typen opslagruimte voor een database.
Een query uitvoeren op één database voor informatie over de bestandsruimte
Gebruik de volgende query op sys.database_files om de hoeveelheid toegewezen databasebestandsruimte en de toegewezen hoeveelheid ongebruikte ruimte te retourneren. Eenheden van het queryresultaat zijn in MB.
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
Inzicht in typen opslagruimte voor een elastische pool
Inzicht in de volgende hoeveelheden opslagruimte zijn belangrijk voor het beheren van de bestandsruimte van een elastische pool.
| Aantal elastische pools | Definitie | Opmerkingen |
|---|---|---|
| Gebruikte gegevensruimte | De totale hoeveelheid gegevensruimte die wordt gebruikt voor alle databases in de elastische pool. | |
| Toegewezen gegevensruimte | De totale hoeveelheid gegevensruimte die is toegewezen voor alle databases in de elastische pool. | |
| Toegewezen gegevensruimte, maar niet gebruikt | Het verschil tussen de hoeveelheid toegewezen gegevensruimte en de gegevensruimte die wordt gebruikt door alle databases in de elastische pool. | Deze hoeveelheid vertegenwoordigt de maximale hoeveelheid ruimte die is toegewezen voor de elastische pool die kan worden vrijgemaakt door databasegegevensbestanden te verkleinen. |
| Maximale grootte van gegevens | De maximale hoeveelheid gegevensruimte die door de elastische pool voor alle databases kan worden gebruikt. | De toegewezen ruimte voor de elastische pool mag niet groter zijn dan de maximale grootte van de elastische pool. Als deze voorwaarde zich voordoet, kan de toegewezen ruimte die niet wordt gebruikt, worden vrijgemaakt door databasegegevensbestanden te verkleinen. |
Notitie
Het foutbericht 'De elastische pool heeft de opslaglimiet bereikt' geeft aan dat de databaseobjecten voldoende ruimte zijn toegewezen om te voldoen aan de opslaglimiet voor elastische pools, maar er kan ongebruikte ruimte zijn in de toewijzing van de gegevensruimte. Overweeg de opslaglimiet van de elastische pool te verhogen of als een kortetermijnoplossing om gegevensruimte vrij te maken met behulp van de voorbeelden in Ongebruikte toegewezen ruimte vrijmaken. U moet ook rekening houden met de mogelijke negatieve invloed op de prestaties van het verkleinen van databasebestanden. Zie Indexonderhoud na het verkleinen.
Een query uitvoeren op een elastische pool voor informatie over opslagruimte
De volgende query's kunnen worden gebruikt om de hoeveelheid opslagruimte voor een elastische pool te bepalen.
Gegevensruimte voor elastische pool gebruikt
Wijzig de volgende query om de hoeveelheid gebruikte elastische poolgegevensruimte te retourneren. Eenheden van het queryresultaat zijn in MB.
-- Connect to master
-- Elastic pool data space used in MB
SELECT TOP 1 avg_storage_percent / 100.0 * elastic_pool_storage_limit_mb AS ElasticPoolDataSpaceUsedInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Toegewezen en ongebruikte toegewezen ruimte voor elastische pools
Wijzig de volgende voorbeelden om een tabel te retourneren met de toegewezen ruimte en ongebruikte toegewezen ruimte voor elke database in een elastische pool. In de tabel worden databases van die databases met de grootste hoeveelheid ongebruikte toegewezen ruimte geordeerd naar de minste hoeveelheid ongebruikte toegewezen ruimte. Eenheden van het queryresultaat zijn in MB.
De queryresultaten voor het bepalen van de toegewezen ruimte voor elke database in de pool kunnen samen worden opgeteld om de totale ruimte te bepalen die is toegewezen voor de elastische pool. De toegewezen ruimte voor elastische pools mag niet groter zijn dan de maximale grootte van de elastische pool.
Belangrijk
De module PowerShell Azure Resource Manager wordt nog steeds ondersteund in Azure SQL Database, maar alle toekomstige ontwikkeling is voor de Az.Sql-module. De AzureRM-module blijft tot ten minste december 2020 bugfixes ontvangen. De argumenten voor de opdrachten in de Az-module en in de AzureRm-modules zijn vrijwel identiek. Zie Introductie van de nieuwe Az-module van Azure PowerShell voor meer informatie over de compatibiliteit van de argumenten.
Voor het PowerShell-script is sql Server PowerShell-module vereist. Zie PowerShell-module downloaden om te installeren.
$resourceGroupName = "<resourceGroupName>"
$serverName = "<serverName>"
$poolName = "<poolName>"
$userName = "<userName>"
$password = "<password>"
# get list of databases in elastic pool
$databasesInPool = Get-AzSqlElasticPoolDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName -ElasticPoolName $poolName
$databaseStorageMetrics = @()
# for each database in the elastic pool, get space allocated in MB and space allocated unused in MB
foreach ($database in $databasesInPool) {
$sqlCommand = "SELECT DB_NAME() as DatabaseName, `
SUM(size/128.0) AS DatabaseDataSpaceAllocatedInMB, `
SUM(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0) AS DatabaseDataSpaceAllocatedUnusedInMB `
FROM sys.database_files `
GROUP BY type_desc `
HAVING type_desc = 'ROWS'"
$serverFqdn = "tcp:" + $serverName + ".database.windows.net,1433"
$databaseStorageMetrics = $databaseStorageMetrics +
(Invoke-Sqlcmd -ServerInstance $serverFqdn -Database $database.DatabaseName `
-Username $userName -Password $password -Query $sqlCommand)
}
# display databases in descending order of space allocated unused
Write-Output "`n" "ElasticPoolName: $poolName"
Write-Output $databaseStorageMetrics | Sort -Property DatabaseDataSpaceAllocatedUnusedInMB -Descending | Format-Table
De volgende schermopname is een voorbeeld van de uitvoer van het script:

Maximale grootte van gegevens voor elastische pool
Wijzig de volgende T-SQL-query om de laatst opgenomen maximale grootte voor elastische pools te retourneren. Eenheden van het queryresultaat zijn in MB.
-- Connect to master
-- Elastic pools max size in MB
SELECT TOP 1 elastic_pool_storage_limit_mb AS ElasticPoolMaxSizeInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Niet-gebruikte toegewezen ruimte vrijmaken
Belangrijk
Verkleiningsopdrachten hebben invloed op de prestaties van de database tijdens het uitvoeren en moeten, indien mogelijk, worden uitgevoerd om momenten dat de database niet of weinig wordt gebruikt.
Gegevensbestanden verkleinen
Vanwege een mogelijke impact op databaseprestaties worden gegevensbestanden niet automatisch verkleind in Azure SQL Database. Klanten kunnen echter gegevensbestanden verkleinen via selfservice op een moment van hun keuze. Dit mag geen regelmatig geplande bewerking zijn, maar een eenmalige gebeurtenis als reactie op een grote vermindering van het gebruikte ruimteverbruik in gegevensbestanden.
Fooi
Het is niet raadzaam om gegevensbestanden te verkleinen als de normale workload van de toepassing ervoor zorgt dat de bestanden weer groter worden dan de toegewezen grootte.
In Azure SQL Database kunt u bestanden verkleinen die u kunt gebruiken DBCC SHRINKDATABASE of DBCC SHRINKFILE opdrachten:
DBCC SHRINKDATABASEverkleint alle gegevens en logboekbestanden in een database met één opdracht. De opdracht verkleint één gegevensbestand tegelijk, wat lang kan duren voor grotere databases. Het verkleint ook het logboekbestand, wat meestal niet nodig is, omdat Azure SQL Database logboekbestanden automatisch verkleint als dat nodig is.DBCC SHRINKFILEopdracht ondersteunt geavanceerdere scenario's:- Het kan naar behoefte zijn gericht op afzonderlijke bestanden in plaats van alle bestanden in de database te verkleinen.
- Elke
DBCC SHRINKFILEopdracht kan parallel worden uitgevoerd met andereDBCC SHRINKFILEopdrachten om meerdere bestanden tegelijkertijd te verkleinen en de totale tijd van verkleinen te verminderen, ten koste van een hoger resourcegebruik en een hogere kans op het blokkeren van gebruikersquery's, als ze tijdens het verkleinen worden uitgevoerd. - Als de staart van het bestand geen gegevens bevat, kan het toegewezen bestand veel sneller worden verkleind door het
TRUNCATEONLYargument op te geven. Hiervoor is geen gegevensverplaatsing in het bestand vereist.
- Zie DBCC SHRINKDATABASE en DBCC SHRINKFILE voor meer informatie over deze opdrachten voor verkleinen.
De volgende voorbeelden moeten worden uitgevoerd terwijl deze zijn verbonden met de doelgebruikersdatabase, niet de master database.
DBCC SHRINKDATABASE Als u alle gegevens en logboekbestanden in een bepaalde database wilt verkleinen:
-- Shrink database data space allocated.
DBCC SHRINKDATABASE (N'database_name');
In Azure SQL Database kan een database een of meer gegevensbestanden bevatten, die automatisch worden gemaakt naarmate de gegevens toenemen. Als u de bestandsindeling van uw database wilt bepalen, inclusief de gebruikte en toegewezen grootte van elk bestand, voert u een query uit in de sys.database_files catalogusweergave met behulp van het volgende voorbeeldscript:
-- Review file properties, including file_id and name values to reference in shrink commands
SELECT file_id,
name,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_file_size_mb
FROM sys.database_files
WHERE type_desc IN ('ROWS','LOG');
U kunt een verkleining uitvoeren op slechts één bestand via de DBCC SHRINKFILE opdracht, bijvoorbeeld:
-- Shrink database data file named 'data_0` by removing all unused at the end of the file, if any.
DBCC SHRINKFILE ('data_0', TRUNCATEONLY);
GO
Houd rekening met de mogelijke negatieve invloed op de prestaties van het verkleinen van databasebestanden. Zie Indexonderhoud na het verkleinen.
Transactielogboekbestand verkleinen
In tegenstelling tot gegevensbestanden, verkleint Azure SQL Database transactielogboekbestanden automatisch om overmatig ruimtegebruik te voorkomen dat kan leiden tot ruimtefouten. Klanten hoeven het transactielogboekbestand meestal niet te verkleinen.
In Premium- en Bedrijfskritiek-servicelagen, als het transactielogboek groot wordt, kan het aanzienlijk bijdragen aan het lokale opslagverbruik voor de maximale lokale opslaglimiet. Als het lokale opslagverbruik dicht bij de limiet ligt, kunnen klanten ervoor kiezen om het transactielogboek te verkleinen met behulp van de OPDRACHT DBCC SHRINKFILE , zoals wordt weergegeven in het volgende voorbeeld. Hiermee wordt lokale opslag vrijgegeven zodra de opdracht is voltooid, zonder te wachten op de periodieke automatische verkleiningsbewerking.
Het volgende voorbeeld moet worden uitgevoerd terwijl deze is verbonden met de doelgebruikersdatabase, niet met de master database.
-- Shrink the database log file (always file_id 2), by removing all unused space at the end of the file, if any.
DBCC SHRINKFILE (2, TRUNCATEONLY);
Automatisch verkleinen
Als alternatief voor het handmatig verkleinen van gegevensbestanden kan automatisch verkleinen worden ingeschakeld voor een database. Automatisch verkleinen kan echter minder effectief zijn bij het vrijmaken van bestandsruimte dan DBCC SHRINKDATABASE en DBCC SHRINKFILE.
Automatisch verkleinen is standaard uitgeschakeld. Dit wordt aanbevolen voor de meeste databases. Als het nodig is om automatisch verkleinen in te schakelen, wordt u aangeraden deze uit te schakelen zodra de doelstellingen voor ruimtebeheer zijn bereikt, in plaats van deze permanent ingeschakeld te houden. Zie Overwegingen voor AUTO_SHRINK voor meer informatie.
Automatisch verkleinen kan bijvoorbeeld handig zijn in het specifieke scenario waarin een elastische pool veel databases bevat die aanzienlijke groei en vermindering van de gebruikte gegevensbestanden ervaren, waardoor de pool de maximale groottelimiet nadert. Dit is geen veelvoorkomend scenario.
Als u automatisch verkleinen wilt inschakelen, voert u de volgende opdracht uit terwijl u verbinding hebt met uw database (niet de master database).
-- Enable auto-shrink for the current database.
ALTER DATABASE CURRENT SET AUTO_SHRINK ON;
Zie DATABASE SET-opties voor meer informatie over deze opdracht.
Indexonderhoud na verkleinen
Nadat een verkleiningsbewerking is voltooid voor gegevensbestanden, kunnen indexen worden gefragmenteerd. Dit vermindert de effectiviteit van de optimalisatie van prestaties voor bepaalde workloads, zoals query's met behulp van grote scans. Als prestatievermindering optreedt nadat de verkleiningsbewerking is voltooid, kunt u indexonderhoud overwegen om indexen opnieuw te bouwen. Houd er rekening mee dat voor het herbouwen van indexen vrije ruimte in de database is vereist, waardoor de toegewezen ruimte kan toenemen, waardoor het effect van de verkleining wordt tegengehouden.
Zie Indexonderhoud optimaliseren om de queryprestaties te verbeteren en het resourceverbruik te verminderen voor meer informatie over indexonderhoud.
Grote databases verkleinen
Wanneer de toegewezen databaseruimte in honderden gigabytes of hoger ligt, kan het zijn dat het verkleinen veel tijd nodig heeft om te voltooien, vaak gemeten in uren of dagen voor databases met meerdere terabyte. Er zijn procesoptimalisaties en aanbevolen procedures die u kunt gebruiken om dit proces efficiënter en minder impactvol te maken voor toepassingsworkloads.
Basislijn voor ruimtegebruik vastleggen
Voordat u begint met verkleinen, legt u de huidige gebruikte en toegewezen ruimte in elk databasebestand vast door de volgende query voor ruimtegebruik uit te voeren:
SELECT file_id,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
Zodra het verkleinen is voltooid, kunt u deze query opnieuw uitvoeren en het resultaat vergelijken met de eerste basislijn.
Gegevensbestanden afkappen
Het wordt aanbevolen om eerst een verkleining uit te voeren voor elk gegevensbestand met de TRUNCATEONLY parameter. Op deze manier, als er toegewezen maar ongebruikte ruimte aan het einde van het bestand is, wordt deze snel en zonder gegevensverplaatsing verwijderd. Met de volgende voorbeeldopdracht wordt het gegevensbestand afgekapt met file_id 4:
DBCC SHRINKFILE (4, TRUNCATEONLY);
Zodra deze opdracht is uitgevoerd voor elk gegevensbestand, kunt u de query voor ruimtegebruik opnieuw uitvoeren om de toegewezen ruimte te verminderen, indien van toepassing. U kunt ook toegewezen ruimte voor de database weergeven in Azure Portal.
Indexpaginadichtheid evalueren
Als het afkappen van gegevensbestanden niet leidt tot een voldoende vermindering van de toegewezen ruimte, moet u gegevensbestanden verkleinen. Als optionele maar aanbevolen stap moet u echter eerst de gemiddelde paginadichtheid voor indexen in de database bepalen. Voor dezelfde hoeveelheid gegevens wordt de verkleining sneller voltooid als de paginadichtheid hoog is, omdat deze minder pagina's moet verplaatsen. Als de paginadichtheid laag is voor sommige indexen, kunt u overwegen om onderhoud uit te voeren op deze indexen om de paginadichtheid te verhogen voordat u gegevensbestanden verkleint. Hierdoor kan er ook een grotere vermindering van de toegewezen opslagruimte worden bereikt.
Gebruik de volgende query om de paginadichtheid voor alle indexen in de database te bepalen. Paginadichtheid wordt gerapporteerd in de avg_page_space_used_in_percent kolom.
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
Als er indexen zijn met een hoog aantal pagina's met een paginadichtheid die lager is dan 60-70%, kunt u overwegen deze indexen opnieuw te bouwen of te herstructureren voordat u gegevensbestanden verkleint.
Notitie
Voor grotere databases kan het lang duren voordat de query de paginadichtheid bepaalt( uren). Daarnaast vereist het opnieuw opbouwen of opnieuw ordenen van grote indexen ook aanzienlijke tijd en resourcegebruik. Er is een compromis tussen het besteden van extra tijd aan het vergroten van de paginadichtheid aan de ene kant, en het verminderen van de duur van de verkleining en het bereiken van hogere ruimtebesparingen op een andere.
Als er meerdere indexen met lage paginadichtheid zijn, kunt u deze mogelijk parallel opnieuw bouwen op meerdere databasesessies om het proces te versnellen. Zorg er echter voor dat u de limieten voor databaseresources niet nadert door dit te doen en zorg ervoor dat er voldoende ruimte voor resources is voor toepassingsworkloads die mogelijk worden uitgevoerd. Bewaak het resourceverbruik (CPU, Data IO, Log IO) in azure Portal of gebruik de sys.dm_db_resource_stats weergave en start extra parallelle herbouwen alleen als het resourcegebruik voor elk van deze dimensies aanzienlijk lager blijft dan 100%. Als het CPU-, gegevens-IO- of logboek-IO-gebruik 100% is, kunt u de database omhoog schalen om meer CPU-kernen te hebben en de IO-doorvoer te verhogen. Hierdoor kunnen extra parallelle herbouwbewerkingen worden ingeschakeld om het proces sneller te voltooien.
Voorbeeld van opdracht voor opnieuw samenstellen van index
Hieronder volgt een voorbeeldopdracht voor het opnieuw samenstellen van een index en het verhogen van de paginadichtheid, met behulp van de INSTRUCTIE ALTER INDEX :
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
Met deze opdracht wordt een online en hervatbare index opnieuw opgebouwd. Hierdoor kunnen gelijktijdige workloads de tabel blijven gebruiken terwijl de herbouw wordt uitgevoerd en kunt u de herbouw hervatten als deze om welke reden dan ook wordt onderbroken. Dit type herbouw is echter langzamer dan een offline herbouwing, waardoor de toegang tot de tabel wordt geblokkeerd. Als er geen andere workloads toegang nodig hebben tot de tabel tijdens het opnieuw opbouwen, stelt u de ONLINE en RESUMABLE opties OFF in en verwijdert u de WAIT_AT_LOW_PRIORITY component.
Zie Indexonderhoud optimaliseren om de queryprestaties te verbeteren en het resourceverbruik te verminderen voor meer informatie over indexonderhoud.
Meerdere gegevensbestanden verkleinen
Zoals eerder vermeld, is verkleinen met gegevensverplaatsing een langlopend proces. Als de database meerdere gegevensbestanden heeft, kunt u het proces versnellen door meerdere gegevensbestanden parallel te verkleinen. U doet dit door meerdere databasesessies te openen en voor elke sessie met een andere file_id waarde te gebruikenDBCC SHRINKFILE. Net als bij het opnieuw opbouwen van indexen moet u ervoor zorgen dat u voldoende ruimte hebt voor resources (CPU, Data IO, Log IO) voordat u elke nieuwe parallelle verkleiningsopdracht start.
Met de volgende voorbeeldopdracht verkleint u het gegevensbestand met file_id 4 en probeert u de toegewezen grootte te verkleinen tot 52.000 MB door pagina's in het bestand te verplaatsen:
DBCC SHRINKFILE (4, 52000);
Als u de toegewezen ruimte voor het bestand zo min mogelijk wilt beperken, voert u de instructie uit zonder de doelgrootte op te geven:
DBCC SHRINKFILE (4);
Als een workload gelijktijdig met verkleinen wordt uitgevoerd, kan deze de opslagruimte gebruiken die is vrijgemaakt door te verkleinen voordat het verkleinen is voltooid en het bestand wordt afgekapt. In dit geval kan verkleinen de toegewezen ruimte voor het opgegeven doel niet verminderen.
U kunt dit beperken door elk bestand in kleinere stappen te verkleinen. Dit betekent dat u in de DBCC SHRINKFILE opdracht het doel instelt dat iets kleiner is dan de huidige toegewezen ruimte voor het bestand, zoals wordt weergegeven in de resultaten van de query voor het gebruik van basislijnruimte. Als bijvoorbeeld toegewezen ruimte voor bestand met file_id 4 200.000 MB is en u deze wilt verkleinen tot 100.000 MB, kunt u het doel eerst instellen op 170.000 MB:
DBCC SHRINKFILE (4, 170000);
Zodra deze opdracht is voltooid, is het bestand afgekapt en is de toegewezen grootte verkleind tot 170.000 MB. Vervolgens kunt u deze opdracht herhalen, het doel eerst instellen op 140.000 MB, vervolgens op 110.000 MB, enzovoort, totdat het bestand is verkleind tot de gewenste grootte. Als de opdracht is voltooid, maar het bestand niet is afgekapt, gebruikt u kleinere stappen, bijvoorbeeld 15.000 MB in plaats van 30.000 MB.
Als u de voortgang van de verkleining wilt controleren voor alle gelijktijdig uitgevoerde verkleinde sessies, kunt u de volgende query gebruiken:
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Notitie
De voortgang van de verkleining kan niet-lineair zijn en de waarde in de percent_complete kolom blijft mogelijk gedurende lange perioden ongewijzigd, ook al wordt de daling nog steeds uitgevoerd.
Zodra het verkleinen is voltooid voor alle gegevensbestanden, voert u de query voor ruimtegebruik opnieuw uit (of checkt u azure Portal in) om de resulterende vermindering van de toegewezen opslaggrootte te bepalen. Als er nog steeds een groot verschil is tussen gebruikte ruimte en toegewezen ruimte, kunt u indexen herbouwen zoals eerder is beschreven. Dit kan tijdelijk de toegewezen ruimte vergroten, maar het opnieuw verkleinen van gegevensbestanden na het herbouwen van indexen moet resulteren in een diepere vermindering van de toegewezen ruimte.
Tijdelijke fouten tijdens verkleinen
Soms kan een opdracht voor verkleinen mislukken met verschillende fouten, zoals time-outs en impasses. Over het algemeen zijn deze fouten tijdelijk en treden deze niet opnieuw op als dezelfde opdracht wordt herhaald. Als het verkleinen mislukt met een fout, blijft de voortgang die tot nu toe is geboekt bij het verplaatsen van gegevenspagina's behouden en kan dezelfde opdracht voor verkleinen opnieuw worden uitgevoerd om het bestand te blijven verkleinen.
In het volgende voorbeeldscript ziet u hoe u verkleind kunt uitvoeren in een lus voor opnieuw proberen om automatisch opnieuw te proberen tot een configureerbaar aantal keren dat een time-outfout of een impassefout optreedt. Deze benadering voor opnieuw proberen is van toepassing op veel andere fouten die kunnen optreden tijdens het verkleinen.
DECLARE @RetryCount int = 3; -- adjust to configure desired number of retries
DECLARE @Delay char(12);
-- Retry loop
WHILE @RetryCount >= 0
BEGIN
BEGIN TRY
DBCC SHRINKFILE (1); -- adjust file_id and other shrink parameters
-- Exit retry loop on successful execution
SELECT @RetryCount = -1;
END TRY
BEGIN CATCH
-- Retry for the declared number of times without raising an error if deadlocked or timed out waiting for a lock
IF ERROR_NUMBER() IN (1205, 49516) AND @RetryCount > 0
BEGIN
SELECT @RetryCount -= 1;
PRINT CONCAT('Retry at ', SYSUTCDATETIME());
-- Wait for a random period of time between 1 and 10 seconds before retrying
SELECT @Delay = '00:00:0' + CAST(CAST(1 + RAND() * 8.999 AS decimal(5,3)) AS varchar(5));
WAITFOR DELAY @Delay;
END
ELSE -- Raise error and exit loop
BEGIN
SELECT @RetryCount = -1;
THROW;
END
END CATCH
END;
Naast time-outs en impasses kan de verkleining fouten ondervinden vanwege bepaalde bekende problemen.
De geretourneerde fouten en risicobeperkingsstappen zijn als volgt:
- Foutnummer: 49503, foutbericht: %.*ls: Pagina %d:%d kan niet worden verplaatst omdat het een permanente versiearchiefpagina buiten de rij is. Reden voor pagina-bewaring: %ls. Tijdstempel voor pagina-bewaring: %I64d.
Deze fout treedt op wanneer er langlopende actieve transacties zijn die rijversies hebben gegenereerd in permanente versieopslag (PVS). De pagina's met deze rijversies kunnen niet worden verplaatst door te verkleinen, waardoor de voortgang niet kan worden gemaakt en mislukt met deze fout.
Om dit te verhelpen, moet u wachten totdat deze langlopende transacties zijn voltooid. U kunt deze langlopende transacties ook identificeren en beëindigen, maar dit kan van invloed zijn op uw toepassing als transactiefouten niet correct worden verwerkt. Een manier om langlopende transacties te vinden, is door de volgende query uit te voeren in de database waarin u de opdracht verkleinen hebt uitgevoerd:
-- Transactions sorted by duration
SELECT st.session_id,
dt.database_transaction_begin_time,
DATEDIFF(second, dt.database_transaction_begin_time, CURRENT_TIMESTAMP) AS transaction_duration_seconds,
dt.database_transaction_log_bytes_used,
dt.database_transaction_log_bytes_reserved,
st.is_user_transaction,
st.open_transaction_count,
ib.event_type,
ib.parameters,
ib.event_info
FROM sys.dm_tran_database_transactions AS dt
INNER JOIN sys.dm_tran_session_transactions AS st
ON dt.transaction_id = st.transaction_id
OUTER APPLY sys.dm_exec_input_buffer(st.session_id, default) AS ib
WHERE dt.database_id = DB_ID()
ORDER BY transaction_duration_seconds DESC;
U kunt een transactie beëindigen met behulp van de KILL opdracht en de bijbehorende session_id waarde uit het queryresultaat opgeven:
KILL 4242; -- replace 4242 with the session_id value from query results
Let op
Het beëindigen van een transactie kan negatieve gevolgen hebben voor workloads.
Zodra langlopende transacties zijn beëindigd of zijn voltooid, worden er na enige tijd geen rijversies meer nodig voor een interne achtergrondtaak opgeschoond. U kunt de PVS-grootte bewaken om de voortgang van het opschonen te meten met behulp van de volgende query. Voer de query uit in de database waarin u de opdracht Verkleinen hebt uitgevoerd:
SELECT pvss.persistent_version_store_size_kb / 1024. / 1024 AS persistent_version_store_size_gb,
pvss.online_index_version_store_size_kb / 1024. / 1024 AS online_index_version_store_size_gb,
pvss.current_aborted_transaction_count,
pvss.aborted_version_cleaner_start_time,
pvss.aborted_version_cleaner_end_time,
dt.database_transaction_begin_time AS oldest_transaction_begin_time,
asdt.session_id AS active_transaction_session_id,
asdt.elapsed_time_seconds AS active_transaction_elapsed_time_seconds
FROM sys.dm_tran_persistent_version_store_stats AS pvss
LEFT JOIN sys.dm_tran_database_transactions AS dt
ON pvss.oldest_active_transaction_id = dt.transaction_id
AND
pvss.database_id = dt.database_id
LEFT JOIN sys.dm_tran_active_snapshot_database_transactions AS asdt
ON pvss.min_transaction_timestamp = asdt.transaction_sequence_num
OR
pvss.online_index_min_transaction_timestamp = asdt.transaction_sequence_num
WHERE pvss.database_id = DB_ID();
Zodra de PVS-grootte die in de persistent_version_store_size_gb kolom is gerapporteerd aanzienlijk is verminderd in vergelijking met de oorspronkelijke grootte, moet het opnieuw uitvoeren van de verkleining lukken.
- Foutnummer: 5223, foutbericht: %.*ls: Lege pagina %d:%d kan de toewijzing niet ongedaan worden gemaakt.
Deze fout kan optreden als er lopende indexonderhoudsbewerkingen ALTER INDEXzoals . Voer de opdracht Verkleinen opnieuw uit nadat deze bewerkingen zijn voltooid.
Als deze fout zich blijft voordoen, moet de bijbehorende index mogelijk opnieuw worden opgebouwd. Voer de volgende query uit in dezelfde database waarin u de opdracht verkleinen hebt uitgevoerd om de index te vinden die opnieuw moet worden opgebouwd:
SELECT OBJECT_SCHEMA_NAME(pg.object_id) AS schema_name,
OBJECT_NAME(pg.object_id) AS object_name,
i.name AS index_name,
p.partition_number
FROM sys.dm_db_page_info(DB_ID(), <file_id>, <page_id>, default) AS pg
INNER JOIN sys.indexes AS i
ON pg.object_id = i.object_id
AND
pg.index_id = i.index_id
INNER JOIN sys.partitions AS p
ON pg.partition_id = p.partition_id;
Voordat u deze query uitvoert, vervangt u de <file_id> tijdelijke aanduidingen door <page_id> de werkelijke waarden uit het foutbericht dat u hebt ontvangen. Als het bericht bijvoorbeeld Lege pagina 1:62669 is , kan de toewijzing niet ongedaan worden gemaakt, dan <file_id> is 1 dat en <page_id> is 62669het .
Bouw de index opnieuw die is geïdentificeerd door de query en voer de opdracht Verkleinen opnieuw uit.
- Foutnummer: 5201, foutbericht: DBCC SHRINKDATABASE: Bestands-id %d van database-id %d is overgeslagen omdat het bestand onvoldoende vrije ruimte heeft om vrij te maken.
Deze fout betekent dat het gegevensbestand niet verder kan worden verkleind. U kunt verdergaan met het volgende gegevensbestand.
Volgende stappen
Zie voor meer informatie over de maximale grootte van databases:
- Aankoopmodellimieten op basis van Azure SQL Database vCore voor één database
- Resourcelimieten voor individuele databases met behulp van het DTU-aankoopmodel
- Aankoopmodellimieten op basis van Azure SQL Database vCore voor elastische pools
- Resourceslimieten voor elastische pools met behulp van het aankoopmodel op basis van DTU
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor