Prestatieproblemen met Intelligent Insights oplossen - Azure SQL Database en Azure SQL Managed Instance
Van toepassing op:![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Deze pagina bevat informatie over prestatieproblemen met Azure SQL Database en Azure SQL Managed Instance die zijn gedetecteerd via het Intelligent Insights-resourcelogboek . Metrische gegevens en resourcelogboeken kunnen worden gestreamd naar Azure Monitor-logboeken, Azure Event Hubs, Azure Storage of een oplossing van derden voor aangepaste DevOps-waarschuwingen en rapportagemogelijkheden.
Notitie
Zie het stroomdiagram Aanbevolen stroomdiagram voor probleemoplossing in dit document voor een snelle probleemoplossingsgids voor het oplossen van problemen met Intelligent Insights.
Intelligente inzichten is een preview-functie die niet beschikbaar is in de volgende regio's: Europa - west, Europa - noord, VS - west 1 en VS - oost 1.
Detecteerbare databaseprestatiepatronen
Intelligent Insights detecteert automatisch prestatieproblemen op basis van wachttijden, fouten of time-outs voor queryuitvoering. Intelligent Insights heeft prestatiepatronen gedetecteerd in het resourcelogboek. Detecteerbare prestatiepatronen worden samengevat in de onderstaande tabel.
| Detecteerbare prestatiepatronen | Azure SQL Database | Azure SQL Managed Instance |
|---|---|---|
| Resourcelimieten bereiken | Het verbruik van beschikbare resources (DTU's), databasewerkthreads of databaseaanmeldingssessies die beschikbaar zijn voor het bewaakte abonnement, heeft de resourcelimieten bereikt. Dit is van invloed op de prestaties. | Het verbruik van CPU-resources bereikt de resourcelimieten. Dit is van invloed op de databaseprestaties. |
| Werkbelasting verhogen | Er is een toename van de werkbelasting of continue accumulatie van werkbelasting in de database gedetecteerd. Dit is van invloed op de prestaties. | Er is een toename van de werkbelasting gedetecteerd. Dit is van invloed op de databaseprestaties. |
| Geheugendruk | Werknemers die geheugentoekenningen hebben aangevraagd, moeten wachten op geheugentoewijzingen voor statistisch significante hoeveelheden tijd of een verhoogde accumulatie van werknemers die geheugentoekenningen hebben aangevraagd. Dit is van invloed op de prestaties. | Werknemers die geheugentoekenningen hebben aangevraagd, wachten op geheugentoewijzingen voor een statistisch significante hoeveelheid tijd. Dit is van invloed op de databaseprestaties. |
| Vergrendelen | Overmatige databasevergrendeling is gedetecteerd die van invloed is op de prestaties. | Overmatige databasevergrendeling is gedetecteerd die van invloed is op de databaseprestaties. |
| Verhoogd MAXDOP | De maximale mate van parallelle uitvoering (MAXDOP) is gewijzigd die van invloed is op de efficiëntie van de queryuitvoering. Dit is van invloed op de prestaties. | De maximale mate van parallelle uitvoering (MAXDOP) is gewijzigd die van invloed is op de efficiëntie van de queryuitvoering. Dit is van invloed op de prestaties. |
| Pagelatch-conflicten | Meerdere threads proberen gelijktijdig toegang te krijgen tot dezelfde in-memory gegevensbufferpagina's, wat resulteert in verhoogde wachttijden en conflicten tussen pagelatch veroorzaken. Dit is van invloed op de prestaties. | Meerdere threads proberen gelijktijdig toegang te krijgen tot dezelfde in-memory gegevensbufferpagina's, wat resulteert in verhoogde wachttijden en conflicten tussen pagelatch veroorzaken. Dit heeft invloed op de prestaties van de database. |
| Ontbrekende index | Er is een ontbrekende index gedetecteerd die van invloed is op de prestaties. | Er is een ontbrekende index gedetecteerd die van invloed is op de prestaties van de database. |
| Nieuwe query | Er is een nieuwe query gedetecteerd die van invloed is op de algehele prestaties. | Er is een nieuwe query gedetecteerd die van invloed is op de algehele databaseprestaties. |
| Verhoogde wachtstatistiek | Er zijn verhoogde databasewachttijden gedetecteerd die van invloed zijn op de prestaties. | Er zijn verhoogde wachttijden voor de database gedetecteerd die van invloed zijn op de databaseprestaties. |
| TempDB-conflicten | Meerdere threads proberen toegang te krijgen tot dezelfde tempdb resource die een knelpunt veroorzaakt. Dit is van invloed op de prestaties. |
Meerdere threads proberen toegang te krijgen tot dezelfde tempdb resource die een knelpunt veroorzaakt. Dit is van invloed op de databaseprestaties. |
| DTU-tekort elastische pool | Tekort aan beschikbare eDTU's in de elastische pool is van invloed op de prestaties. | Niet beschikbaar voor Azure SQL Managed Instance omdat het gebruikmaakt van het vCore-model. |
| Regressie plannen | Er is een nieuw plan of een wijziging in de workload van een bestaand plan gedetecteerd. Dit is van invloed op de prestaties. | Er is een nieuw plan of een wijziging in de workload van een bestaand plan gedetecteerd. Dit is van invloed op de databaseprestaties. |
| Wijziging van configuratiewaarde in databasebereik | Er is een configuratiewijziging op de database gedetecteerd die van invloed is op de prestaties van de database. | Er is een configuratiewijziging op de database gedetecteerd die van invloed is op de prestaties van de database. |
| Trage client | Trage toepassingsclient kan geen uitvoer van de database snel genoeg verbruiken. Dit is van invloed op de prestaties. | Trage toepassingsclient kan geen uitvoer van de database snel genoeg verbruiken. Dit is van invloed op de databaseprestaties. |
| Downgrade van prijscategorie | De downgradeactie voor de prijscategorie heeft de beschikbare resources verminderd. Dit is van invloed op de prestaties. | De downgradeactie voor de prijscategorie heeft de beschikbare resources verminderd. Dit is van invloed op de databaseprestaties. |
Tip
Schakel automatisch afstemmen in voor continue prestatieoptimalisatie van databases. Deze ingebouwde functie voor intelligentie bewaakt continu uw database, past automatisch indexen toe en past correcties in het uitvoeringsplan voor query's toe.
In de volgende sectie worden detecteerbare prestatiepatronen gedetailleerder beschreven.
Resourcelimieten bereiken
Wat gebeurt er
Dit detecteerbare prestatiepatroon combineert prestatieproblemen die betrekking hebben op het bereiken van beschikbare resourcelimieten, werkrollimieten en sessielimieten. Nadat dit prestatieprobleem is gedetecteerd, geeft een beschrijvingsveld van het diagnostische logboek aan of het prestatieprobleem te maken heeft met resource-, werkrol- of sessielimieten.
Resources in Azure SQL Database worden doorgaans aangeduid met DTU- of vCore-resources en resources in Azure SQL Managed Instance worden vCore-resources genoemd. Het patroon van het bereiken van resourcelimieten wordt herkend wanneer gedetecteerde prestatievermindering van query's wordt veroorzaakt door het bereiken van een van de gemeten resourcelimieten.
De sessie beperkt de resource geeft het aantal beschikbare gelijktijdige aanmeldingen aan de database aan. Dit prestatiepatroon wordt herkend wanneer toepassingen die zijn verbonden met de databases het aantal beschikbare gelijktijdige aanmeldingen voor de database hebben bereikt. Als toepassingen meer sessies proberen te gebruiken dan beschikbaar zijn in een database, worden de queryprestaties beïnvloed.
Het bereiken van werkrollimieten is een specifiek geval van het bereiken van resourcelimieten, omdat beschikbare werkrollen niet worden geteld in het DTU- of vCore-gebruik. Het bereiken van werkrollimieten voor een database kan leiden tot de toename van resourcespecifieke wachttijden, waardoor de prestaties van query's afnemen.
Problemen oplossen
Het diagnostische logboek voert query-hashes uit van query's die van invloed zijn op de prestatie- en resourceverbruikspercentages. U kunt deze informatie gebruiken als uitgangspunt voor het optimaliseren van uw databaseworkload. U kunt met name de query's optimaliseren die van invloed zijn op de prestatievermindering door indexen toe te voegen. Of u kunt toepassingen optimaliseren met een gelijkmatigere workloaddistributie. Als u geen workloads kunt verminderen of optimalisaties kunt maken, kunt u overwegen om de prijscategorie van uw databaseabonnement te verhogen om de hoeveelheid beschikbare resources te verhogen.
Als u de beschikbare sessielimieten hebt bereikt, kunt u uw toepassingen optimaliseren door het aantal aanmeldingen in de database te verminderen. Als u het aantal aanmeldingen van uw toepassingen naar de database niet kunt verminderen, kunt u overwegen de prijscategorie van uw databaseabonnement te verhogen. U kunt uw database ook splitsen en verplaatsen naar meerdere databases voor een evenwichtigere workloaddistributie.
Zie Hoe u de limieten voor maximale aanmeldingen kunt oplossen voor meer suggesties voor het oplossen van sessielimieten. Zie Overzicht van resourcelimieten op een server voor informatie over limieten op server- en abonnementsniveaus.
Workload verhogen
Wat gebeurt er
Dit prestatiepatroon identificeert problemen die worden veroorzaakt door een toename van de werkbelasting of, in de ernstigere vorm, een opstapeling van werkbelastingen.
Deze detectie wordt uitgevoerd via een combinatie van verschillende metrische gegevens. De metrische basisgegevens detecteren een toename van de workload vergeleken met de vorige workloadbasislijn. De andere vorm van detectie is gebaseerd op het meten van een grote toename van actieve werkrolthreads die groot genoeg zijn om de queryprestaties te beïnvloeden.
In de ernstigere vorm kan de workload zich continu opstapelen vanwege het onvermogen van een database om de workload te verwerken. Het resultaat is een voortdurend groeiende workloadgrootte. Dit is de opstapelvoorwaarde van de werkbelasting. Vanwege deze voorwaarde neemt de tijd die de workload wacht op uitvoering toe. Deze voorwaarde vertegenwoordigt een van de ernstigste prestatieproblemen in de database. Dit probleem wordt gedetecteerd door de toename van het aantal afgebroken werkrolthreads te controleren.
Problemen oplossen
Het diagnostische logboek voert het aantal query's uit waarvan de uitvoering is toegenomen en de query-hash van de query met de grootste bijdrage aan de werkbelastingstoename. U kunt deze informatie gebruiken als uitgangspunt voor het optimaliseren van de workload. De query die is geïdentificeerd als de grootste bijdrager aan de werkbelastingstoename, is vooral handig als uitgangspunt.
U kunt overwegen om de workloads gelijkmatiger naar de database te distribueren. Overweeg om de query te optimaliseren die van invloed is op de prestaties door indexen toe te voegen. U kunt uw workload ook verdelen over meerdere databases. Als deze oplossingen niet mogelijk zijn, kunt u overwegen de prijscategorie van uw databaseabonnement te verhogen om de beschikbare hoeveelheid resources te verhogen.
Geheugendruk
Wat gebeurt er
Dit prestatiepatroon duidt op afname van de huidige databaseprestaties die worden veroorzaakt door geheugenbelasting, of in de ernstigere vorm een stapelvoorwaarde voor geheugen, vergeleken met de prestatiebasislijn van de afgelopen zeven dagen.
Geheugendruk geeft een prestatievoorwaarde aan waarin een groot aantal werkrolthreads die geheugentoekenningen aanvragen. Het hoge volume veroorzaakt een hoge geheugengebruiksvoorwaarde waarbij de database geen efficiënt geheugen kan toewijzen aan alle werkrollen die dit aanvragen. Een van de meest voorkomende redenen voor dit probleem is gerelateerd aan de hoeveelheid geheugen die beschikbaar is voor de database. Aan de andere kant veroorzaakt een toename van de werkbelasting de toename van werkthreads en de geheugendruk.
De ernstigere vorm van geheugendruk is de opstapeling van het geheugen. Deze voorwaarde geeft aan dat een hoger aantal werkrolthreads geheugentoekenningen aanvraagt dan er query's zijn die het geheugen vrijgeven. Dit aantal werkrolthreads dat geheugenaanvragen aanvraagt, kan ook voortdurend toenemen (opstapelen) omdat de database-engine onvoldoende geheugen kan toewijzen om aan de vraag te voldoen. De voorwaarde voor het opstapelen van geheugen vertegenwoordigt een van de ernstigste prestatieproblemen in de database.
Problemen oplossen
Het diagnostische logboek voert de details van het geheugenobjectarchief uit met de clerk (dat wil gezegd: werkrolthread) gemarkeerd als de hoogste reden voor hoog geheugengebruik en relevante tijdstempels. U kunt deze informatie gebruiken als basis voor het oplossen van problemen.
U kunt query's met betrekking tot de medewerkers optimaliseren of verwijderen met het hoogste geheugengebruik. U kunt er ook voor zorgen dat u geen query's uitvoert op gegevens die u niet van plan bent te gebruiken. Het is raadzaam altijd een WHERE-component in uw query's te gebruiken. Daarnaast raden we u aan niet-geclusterde indexen te maken om de gegevens te zoeken in plaats van deze te scannen.
U kunt de workload ook verminderen door deze te optimaliseren of te distribueren over meerdere databases. U kunt uw workload ook verdelen over meerdere databases. Als deze oplossingen niet mogelijk zijn, kunt u overwegen de prijscategorie van uw database te verhogen om de hoeveelheid geheugenbronnen te verhogen die beschikbaar zijn voor de database.
Zie Geheugen verleent meditatie voor aanvullende suggesties voor probleemoplossing: de mysterieuze SQL Server-geheugengebruiker met veel namen. Zie Problemen met onvoldoende geheugen in Azure SQL Database oplossen voor meer informatie over geheugenfouten in Azure SQL Database.
Vergrendelen
Wat gebeurt er
Dit prestatiepatroon geeft aan dat de prestaties van de huidige database afnemen, waarbij overmatige databasevergrendeling wordt gedetecteerd in vergelijking met de prestatiebasislijn van de afgelopen zeven dagen.
In moderne RDBMS is vergrendeling essentieel voor het implementeren van multithreaded-systemen waarin de prestaties worden gemaximaliseerd door waar mogelijk meerdere gelijktijdige werkrollen en parallelle databasetransacties uit te voeren. Vergrendeling in deze context verwijst naar het ingebouwde toegangsmechanisme waarin slechts één transactie uitsluitend toegang heeft tot de rijen, pagina's, tabellen en bestanden die vereist zijn en die niet met een andere transactie voor resources concurreren. Wanneer de transactie die de resources voor gebruik heeft vergrendeld, wordt de vergrendeling voor deze resources vrijgegeven, waardoor andere transacties toegang hebben tot vereiste resources. Zie Vergrendeling in de database-engine voor meer informatie over het vergrendelen.
Als transacties die door de SQL-engine worden uitgevoerd, lange tijdsperioden wachten om toegang te krijgen tot resources die zijn vergrendeld voor gebruik, zorgt deze wachttijd ervoor dat de prestaties van de workload worden vertraagd.
Problemen oplossen
Het diagnostische logboek voert vergrendelingsgegevens uit die u kunt gebruiken als basis voor het oplossen van problemen. U kunt de gerapporteerde blokkerende query's analyseren, dat wil gezegd, de query's die leiden tot de verslechtering van de vergrendelingsprestaties en ze verwijderen. In sommige gevallen kunt u de blokkerende query's optimaliseren.
De eenvoudigste en veiligste manier om het probleem te verhelpen, is door transacties kort te houden en de vergrendelingsvoetafdruk van de duurste query's te verminderen. U kunt een grote batch bewerkingen opsplitsen in kleinere bewerkingen. Het is een goede gewoonte om de footprint van de queryvergrendeling te verminderen door de query zo efficiënt mogelijk te maken. Verminder grote scans omdat ze de kans op impasses vergroten en de algehele databaseprestaties nadelig beïnvloeden. Voor geïdentificeerde query's die vergrendeling veroorzaken, kunt u nieuwe indexen maken of kolommen toevoegen aan de bestaande index om te voorkomen dat de tabelscans worden uitgevoerd.
Zie voor meer suggesties:
- Blokkerende problemen met Azure SQL begrijpen en oplossen
- Blokkerende problemen oplossen die worden veroorzaakt door escalatie van vergrendelingen in SQL Server
Verhoogd MAXDOP
Wat gebeurt er
Dit detecteerbare prestatiepatroon geeft een voorwaarde aan waarin een gekozen queryuitvoeringsplan meer is geparallelliseerd dan het zou moeten zijn. De queryoptimalisatie kan de prestaties van de werkbelasting verbeteren door query's parallel uit te voeren om dingen waar mogelijk te versnellen. In sommige gevallen besteden parallelle werkrollen die een query verwerken meer tijd aan elkaar om resultaten te synchroniseren en samen te voegen vergeleken met het uitvoeren van dezelfde query met minder parallelle werkrollen, of zelfs in sommige gevallen vergeleken met één werkrolthread.
Het expertsysteem analyseert de huidige databaseprestaties vergeleken met de basislijnperiode. Het bepaalt of een eerder uitgevoerde query langzamer wordt uitgevoerd dan voorheen, omdat het uitvoeringsplan van de query meer parallel is dan het zou moeten zijn.
De maxDOP-serverconfiguratieoptie wordt gebruikt om te bepalen hoeveel CPU-kernen kunnen worden gebruikt om dezelfde query parallel uit te voeren.
Problemen oplossen
Het diagnostische logboek voert query-hashes uit die betrekking hebben op query's waarvoor de duur van de uitvoering is toegenomen, omdat ze meer parallel zijn geparallelliseerd dan ze hadden moeten zijn. Het logboek voert ook CXP-wachttijden uit. Deze keer vertegenwoordigt de tijd dat één thread voor organisator/coördinator (thread 0) wacht tot alle andere threads zijn voltooid voordat de resultaten worden samengevoegd en verdergaan. Bovendien voert het diagnostische logboek de wachttijden uit die de slecht presterende query's in het algemeen in uitvoering hadden gewacht. U kunt deze informatie gebruiken als basis voor het oplossen van problemen.
Optimaliseer of vereenvoudig eerst complexe query's. Het is een goede gewoonte om lange batchtaken op te splitsen in kleinere taken. Zorg er bovendien voor dat u indexen hebt gemaakt ter ondersteuning van uw query's. U kunt ook handmatig de maximale mate van parallelle uitvoering (MAXDOP) afdwingen voor een query die als slecht presteert. Als u deze bewerking wilt configureren met behulp van T-SQL, raadpleegt u de configuratieoptie MAXDOP-server configureren.
Het instellen van de maxDOP-serverconfiguratieoptie op nul (0) als een standaardwaarde geeft aan dat database alle beschikbare CPU-kernen kan gebruiken om threads te parallelliseren voor het uitvoeren van één query. Het instellen van MAXDOP op één (1) geeft aan dat slechts één kern kan worden gebruikt voor één queryuitvoering. In de praktijk betekent dit dat parallellisme wordt uitgeschakeld. Afhankelijk van de case-per-case, beschikbare kernen voor de database en diagnostische logboekgegevens, kunt u de MAXDOP-optie afstemmen op het aantal kernen dat wordt gebruikt voor parallelle queryuitvoering waarmee het probleem in uw geval kan worden opgelost.
Pagelatch-conflicten
Wat gebeurt er
Dit prestatiepatroon geeft aan dat de prestaties van de huidige databaseworkload afnemen vanwege conflicten tussen pagelatch en de basislijn voor de workload van de afgelopen zeven dagen.
Latches zijn lichtgewicht synchronisatiemechanismen die worden gebruikt om multithreading mogelijk te maken. Ze garanderen consistentie van in-memory structuren die indexen, gegevenspagina's en andere interne structuren bevatten.
Er zijn veel soorten latches beschikbaar. Ter vereenvoudiging worden buffervergrendelingen gebruikt om in-memory pagina's in de buffergroep te beveiligen. IO-latches worden gebruikt om pagina's te beveiligen die nog niet in de buffergroep zijn geladen. Wanneer gegevens naar een pagina in de buffergroep worden geschreven of gelezen, moet een werkrolthread eerst een buffervergrendeling voor de pagina verkrijgen. Wanneer een werkrolthread toegang probeert te krijgen tot een pagina die nog niet beschikbaar is in de buffergroep in het geheugen, wordt er een IO-aanvraag gedaan om de vereiste gegevens uit de opslag te laden. Deze reeks gebeurtenissen geeft een ernstigere vorm van prestatievermindering aan.
Conflicten op de paginavergrendelingen treden op wanneer meerdere threads gelijktijdig proberen om vergrendelingen op dezelfde in-memory structuur te verkrijgen, wat een verhoogde wachttijd voor het uitvoeren van query's introduceert. In het geval van pagelatch IO-conflicten, wanneer gegevens moeten worden geopend vanuit de opslag, is deze wachttijd nog groter. Dit kan de prestaties van de werkbelasting aanzienlijk beïnvloeden. Pagelatch-conflicten zijn het meest voorkomende scenario van threads die op elkaar wachten en concurreren voor resources op meerdere CPU-systemen.
Problemen oplossen
Het diagnostische logboek voert paginalatch-conflictdetails uit. U kunt deze informatie gebruiken als basis voor het oplossen van problemen.
Omdat een pagelatch een intern controlemechanisme is, wordt automatisch bepaald wanneer deze moeten worden gebruikt. Toepassingsbeslissingen, waaronder schemaontwerp, kunnen invloed hebben op paginalatchgedrag vanwege het deterministische gedrag van latches.
Een methode voor het verwerken van vergrendelingsconflicten is het vervangen van een sequentiële indexsleutel door een niet-opeenvolgende sleutel om inserts gelijkmatig over een indexbereik te verdelen. Normaal gesproken distribueert een voorloopkolom in de index de workload proportioneel. Een andere methode om rekening mee te houden is tabelpartitionering. Het maken van een hashpartitioneringsschema met een berekende kolom in een gepartitioneerde tabel is een algemene benadering voor het beperken van overmatige vergrendelingsconflicten. In het geval van conflict tussen pagelatch-IO's helpt het introduceren van indexen dit prestatieprobleem te verhelpen.
Zie Vergrendelingsconflicten vaststellen en oplossen op SQL Server (PDF-download) voor meer informatie.
Ontbrekende index
Wat gebeurt er
Dit prestatiepatroon geeft aan dat de prestaties van de huidige databaseworkload afnemen ten opzichte van de afgelopen zevendaagse basislijn vanwege een ontbrekende index.
Een index wordt gebruikt om de prestaties van query's te versnellen. Het biedt snelle toegang tot tabelgegevens door het aantal gegevenssetpagina's te verminderen dat moet worden bezocht of gescand.
Specifieke query's die prestatievermindering hebben veroorzaakt, worden geïdentificeerd via deze detectie waarvoor het maken van indexen nuttig is voor de prestaties.
Problemen oplossen
Het diagnostische logboek voert query-hashes uit voor de query's die zijn geïdentificeerd om de workloadprestaties te beïnvloeden. U kunt indexen maken voor deze query's. U kunt deze query's ook optimaliseren of verwijderen als ze niet nodig zijn. Een goede gewoonte is om query's uit te voeren op gegevens die u niet gebruikt.
Tip
Wist u dat ingebouwde intelligentie automatisch de best presterende indexen voor uw databases kan beheren?
Voor continue prestatieoptimalisatie raden we u aan automatische afstemming in te schakelen. Deze unieke ingebouwde intelligentiefunctie bewaakt continu uw database en maakt automatisch indexen voor uw databases.
Nieuwe query
Wat gebeurt er
Dit prestatiepatroon geeft aan dat er een nieuwe query wordt gedetecteerd die slecht presteert en invloed heeft op de prestaties van de werkbelasting in vergelijking met de prestatiebasislijn van zeven dagen.
Het schrijven van een goed presterende query kan soms een uitdagende taak zijn. Zie SQL-query's schrijven voor meer informatie over het schrijven van query's. Zie Queryafstemming om de bestaande queryprestaties te optimaliseren.
Problemen oplossen
Het diagnostische logboek levert gegevens op tot twee nieuwe query's die de meeste CPU verbruiken, inclusief hun query-hashes. Omdat de gedetecteerde query van invloed is op de prestaties van de werkbelasting, kunt u uw query optimaliseren. Het is raadzaam om alleen gegevens op te halen die u moet gebruiken. We raden u ook aan query's te gebruiken met een WHERE-component. We raden u ook aan om complexe query's te vereenvoudigen en op te splitsen in kleinere query's. Een andere goede gewoonte is om grote batchquery's op te splitsen in kleinere batchquery's. Het introduceren van indexen voor nieuwe query's is doorgaans een goede gewoonte om dit prestatieprobleem te verhelpen.
Overweeg het gebruik van Query Performance Insight in Azure SQL Database.
Verhoogde wachtstatistiek
Wat gebeurt er
Dit detecteerbare prestatiepatroon geeft een verslechtering van de workloadprestaties aan waarin slecht presterende query's worden geïdentificeerd in vergelijking met de basislijn van de afgelopen zeven dagen.
In dit geval kan het systeem de slecht presterende query's niet classificeren in andere standaard detecteerbare prestatiecategorieën, maar de wachtstatistiek die verantwoordelijk is voor de regressie gedetecteerd. Daarom worden ze beschouwd als query's met verhoogde wachtstatistieken, waarbij de wachtstatistiek die verantwoordelijk is voor de regressie ook wordt weergegeven.
Problemen oplossen
Het diagnostische logboek levert informatie over meer wachttijddetails en query-hashes van de betrokken query's.
Omdat het systeem de hoofdoorzaak voor de slecht presterende query's niet kan identificeren, is de diagnostische informatie een goed uitgangspunt voor het handmatig oplossen van problemen. U kunt de prestaties van deze query's optimaliseren. Een goede gewoonte is om alleen gegevens op te halen die u nodig hebt om complexe query's te vereenvoudigen en op te splitsen in kleinere query's.
Zie Queryafstemming voor meer informatie over het optimaliseren van queryprestaties.
TempDB-conflict
Wat gebeurt er
Dit detecteerbare prestatiepatroon geeft een databaseprestatievoorwaarde aan waarin een knelpunt van threads die toegang proberen te krijgen tot tempdb resources bestaat. (Deze voorwaarde is niet gerelateerd aan IO.) Het typische scenario voor dit prestatieprobleem is honderden gelijktijdige query's die allemaal kleine tempdb tabellen maken, gebruiken en neerzetten. Het systeem heeft gedetecteerd dat het aantal gelijktijdige query's met dezelfde tempdb tabellen is toegenomen met voldoende statistische significantie om de databaseprestaties te beïnvloeden in vergelijking met de prestatiebasislijn van de afgelopen zeven dagen.
Problemen oplossen
Het diagnostische logboek voert tempdb conflicten uit. U kunt de informatie gebruiken als uitgangspunt voor het oplossen van problemen. Er zijn twee dingen die u kunt uitvoeren om dit soort conflicten te verlichten en de doorvoer van de algehele workload te verhogen: u kunt stoppen met het gebruik van de tijdelijke tabellen. U kunt ook tabellen gebruiken die zijn geoptimaliseerd voor geheugen.
Zie Inleiding tot tabellen die zijn geoptimaliseerd voor geheugen voor meer informatie.
DTU-tekort elastische pool
Wat gebeurt er
Dit detecteerbare prestatiepatroon duidt op een verslechtering van de prestaties van de huidige databaseworkload in vergelijking met de afgelopen zevendaagse basislijn. Dit komt door het tekort aan beschikbare DTU's in de elastische pool van uw abonnement.
Resources voor elastische Azure-pools worden gebruikt als een pool met beschikbare resources die worden gedeeld tussen meerdere databases voor schaalaanpassing. Wanneer beschikbare eDTU-resources in uw elastische pool niet voldoende groot zijn om alle databases in de pool te ondersteunen, wordt een DTU-tekort aan elastische pools gedetecteerd door het systeem.
Problemen oplossen
Het diagnostische logboek levert informatie over de elastische pool, een lijst van de meest gebruikte DTU-databases en geeft een percentage van de DTU van de pool die wordt gebruikt door de meest gebruikte database.
Omdat deze prestatievoorwaarde is gerelateerd aan meerdere databases die gebruikmaken van dezelfde pool eDTU's in de elastische pool, richten de stappen voor probleemoplossing zich op de belangrijkste DTU-verbruikende databases. U kunt de workload voor de meest verbruikende databases verminderen, waaronder optimalisatie van de meest verbruikende query's op deze databases. U kunt er ook voor zorgen dat u geen query's uitvoert op gegevens die u niet gebruikt. Een andere benadering is het optimaliseren van toepassingen met behulp van de meest gebruikte DTU-databases en het herdistribueren van de workload tussen meerdere databases.
Als het verminderen en optimaliseren van de huidige werkbelasting op de meest DTU-verbruikende databases niet mogelijk is, kunt u overwegen de prijscategorie voor elastische pools te verhogen. Een dergelijke toename resulteert in de toename van de beschikbare DTU's in de elastische pool.
Regressie plannen
Wat gebeurt er
Dit detecteerbare prestatiepatroon geeft een voorwaarde aan waarin de database gebruikmaakt van een suboptimaal uitvoeringsplan voor query's. Het suboptimale plan veroorzaakt doorgaans een verhoogde uitvoering van query's, wat leidt tot langere wachttijden voor de huidige en andere query's.
De database-engine bepaalt het uitvoeringsplan voor query's met de minste kosten voor een queryuitvoering. Naarmate het type query's en workloads verandert, zijn de bestaande plannen soms niet meer efficiënt of heeft de database-engine geen goede evaluatie gemaakt. Bij correctie kunnen queryuitvoeringsplannen handmatig worden geforceerd.
Dit detecteerbare prestatiepatroon combineert drie verschillende gevallen van planregressie: nieuwe planregressie, oude planregressie en bestaande plannen zijn gewijzigd. Het specifieke type planregressie dat is opgetreden, wordt opgegeven in de eigenschap Details in het diagnostische logboek.
De nieuwe regressievoorwaarde van het plan verwijst naar een status waarin de database-engine begint met het uitvoeren van een nieuw queryuitvoeringsplan dat niet zo efficiënt is als het oude plan. De oude regressievoorwaarde van het plan verwijst naar de status wanneer de database-engine overschakelt van het gebruik van een nieuw, efficiënter plan naar het oude plan, wat niet zo efficiënt is als het nieuwe plan. De bestaande plannen veranderende workloadregressie verwijst naar de status waarin de oude en de nieuwe plannen continu wisselen, waarbij het evenwicht meer naar het slecht presterende plan gaat.
Zie Wat is planregressie in SQL Server? voor meer informatie over planregressies.
Problemen oplossen
Het diagnostische logboek voert de query-hashes, een goede plan-id, een ongeldige plan-id en query-id's uit. U kunt deze informatie gebruiken als basis voor het oplossen van problemen.
U kunt analyseren welk plan beter presteert voor uw specifieke query's die u kunt identificeren met de opgegeven query-hashes. Nadat u hebt vastgesteld welk plan beter werkt voor uw query's, kunt u dit handmatig forceren.
Zie Meer informatie over hoe SQL Server regressies van plannen voorkomt.
Tip
Wist u dat de ingebouwde intelligence-functie automatisch de best presterende queryuitvoeringsplannen voor uw databases kan beheren?
Voor continue prestatieoptimalisatie raden we u aan automatische afstemming in te schakelen. Deze ingebouwde intelligence-functie bewaakt uw database continu en maakt automatisch de best presterende queryuitvoeringsplannen voor uw databases.
Wijziging van configuratiewaarde in databasebereik
Wat gebeurt er
Dit detecteerbare prestatiepatroon geeft een voorwaarde aan waarin een wijziging in de configuratie met databasebereik prestatieregressie veroorzaakt die wordt gedetecteerd in vergelijking met het gedrag van de afgelopen zevendaagse databaseworkload. Dit patroon geeft aan dat een recente wijziging in de configuratie met databasebereik niet nuttig lijkt te zijn voor de prestaties van uw database.
Configuratiewijzigingen in databasebereik kunnen worden ingesteld voor elke afzonderlijke database. Deze configuratie wordt per geval gebruikt om de afzonderlijke prestaties van uw database te optimaliseren. De volgende opties kunnen worden geconfigureerd voor elke afzonderlijke database: MAXDOP, LEGACY_CARDINALITY_ESTIMATION, PARAMETER_SNIFFING, QUERY_OPTIMIZER_HOTFIXES en CLEAR-PROCEDURE_CACHE.
Problemen oplossen
Het diagnostische logboek voert configuratiewijzigingen in databasebereik uit die onlangs zijn aangebracht, waardoor de prestaties afnemen vergeleken met het gedrag van de vorige zevendaagse workload. U kunt de configuratiewijzigingen terugzetten naar de vorige waarden. U kunt de waarde ook afstemmen op waarde totdat het gewenste prestatieniveau is bereikt. U kunt configuratiewaarden voor databasebereik kopiëren uit een vergelijkbare database met bevredigende prestaties. Als u geen problemen met de prestaties kunt oplossen, gaat u terug naar de standaardwaarden en probeert u te beginnen met deze basislijn.
Zie Alter database-scoped configuration (Transact-SQL) voor meer informatie over het optimaliseren van databaseconfiguratie en T-SQL-syntaxis voor het wijzigen van de configuratie.
Trage client
Wat gebeurt er
Dit detecteerbare prestatiepatroon geeft een voorwaarde aan waarin de client die de database gebruikt, de uitvoer van de database niet zo snel kan gebruiken als de database de resultaten verzendt. Omdat de database geen resultaten van de uitgevoerde query's in een buffer opslaat, wordt deze vertraagd en wordt gewacht totdat de client de verzonden query-uitvoer verbruikt voordat u doorgaat. Deze voorwaarde kan ook betrekking hebben op een netwerk dat niet voldoende snel genoeg is om uitvoer van de database naar de verbruikende client te verzenden.
Deze voorwaarde wordt alleen gegenereerd als er een prestatieregressie wordt gedetecteerd in vergelijking met het gedrag van de afgelopen zevendaagse databaseworkload. Dit prestatieprobleem wordt alleen gedetecteerd als er een statistisch significante prestatievermindering optreedt in vergelijking met het eerdere prestatiegedrag.
Problemen oplossen
Dit detecteerbare prestatiepatroon geeft een voorwaarde aan aan de clientzijde. Probleemoplossing is vereist in de clienttoepassing of het netwerk aan de clientzijde. Het diagnostische logboek voert de query-hashes en wachttijden uit die het meest wachten totdat de client deze binnen de afgelopen twee uur verbruikt. U kunt deze informatie gebruiken als basis voor het oplossen van problemen.
U kunt de prestaties van uw toepassing optimaliseren voor gebruik van deze query's. U kunt ook rekening houden met mogelijke problemen met netwerklatentie. Omdat het prestatiedegradatieprobleem is gebaseerd op wijzigingen in de prestatiebasislijn van de afgelopen zeven dagen, kunt u onderzoeken of recente wijzigingen in de toepassings- of netwerkvoorwaarde deze prestatieregressiegebeurtenis hebben veroorzaakt.
Downgrade van prijscategorie
Wat gebeurt er
Dit detecteerbare prestatiepatroon geeft een voorwaarde aan waarin de prijscategorie van uw databaseabonnement is gedowngraded. Vanwege het verminderen van resources (DTU's) die beschikbaar zijn voor de database, heeft het systeem een daling gedetecteerd in de huidige databaseprestaties in vergelijking met de afgelopen zevendaagse basislijn.
Daarnaast kan er een voorwaarde zijn waarin de prijscategorie van uw databaseabonnement is gedowngraded en vervolgens binnen een korte periode naar een hogere laag is geüpgraded. Detectie van deze tijdelijke prestatievermindering wordt uitgevoerd in de sectie details van het diagnostische logboek als downgrade en upgrade van de prijscategorie.
Problemen oplossen
Als u de prijscategorie hebt verlaagd en daarom de beschikbare DTU's en u tevreden bent met de prestaties, hoeft u niets te doen. Als u de prijscategorie hebt verlaagd en u niet tevreden bent met de prestaties van uw database, vermindert u uw databaseworkloads of kunt u overwegen om de prijscategorie naar een hoger niveau te verhogen.
Aanbevolen stroom voor probleemoplossing
Volg het stroomdiagram voor een aanbevolen benadering voor het oplossen van prestatieproblemen met behulp van Intelligent Insights.
Toegang tot Intelligent Insights via Azure Portal door naar Azure SQL Analytics te gaan. Probeer de binnenkomende prestatiewaarschuwing te vinden en selecteer deze. Bepaal wat er gebeurt op de detectiepagina. Bekijk de opgegeven hoofdoorzaakanalyse van het probleem, querytekst, trends in querytijd en incidentontwikkeling. Probeer het probleem op te lossen met behulp van de aanbeveling Intelligent Insights om het prestatieprobleem te beperken.
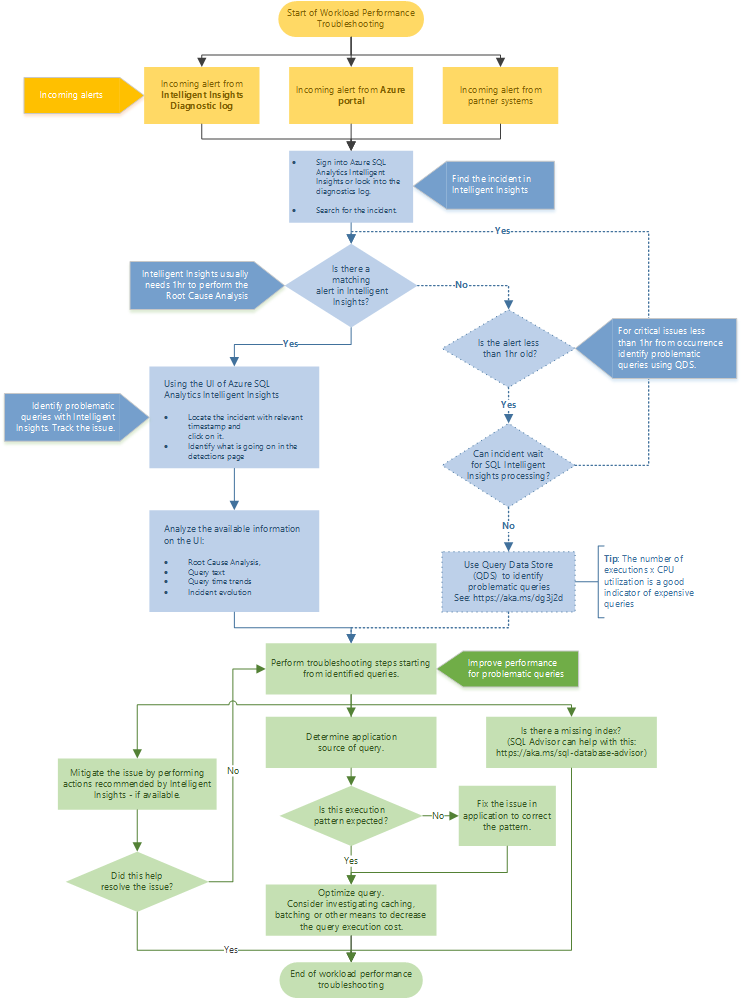
Tip
Selecteer het stroomdiagram om een PDF-versie te downloaden.
Intelligent Insights heeft meestal een uur tijd nodig om de hoofdoorzaakanalyse van het prestatieprobleem uit te voeren. Als u uw probleem niet kunt vinden in Intelligent Insights en het essentieel voor u is, gebruikt u Query Store om de hoofdoorzaak van het prestatieprobleem handmatig te identificeren. (Deze problemen zijn doorgaans minder dan één uur oud.) Zie Prestaties bewaken met behulp van de Query Store voor meer informatie.
Volgende stappen
- Leer intelligente inzichtenconcepten .
- Gebruik het diagnostische logboek voor Intelligent Insights-prestaties.
- Bewaken met behulp van Azure SQL Analytics.
- Meer informatie over het verzamelen en gebruiken van logboekgegevens van uw Azure-resources.