Prestaties van Microsoft Azure SQL Database bewaken met dynamische beheerweergaven
Van toepassing op:![]() Azure SQL Database
Azure SQL Database
Met Microsoft Azure SQL Database kan een subset van dynamische beheerweergaven prestatieproblemen vaststellen, die kunnen worden veroorzaakt door geblokkeerde of langdurige query's, resourceknelpunten, slechte queryplannen en meer.
Dit artikel bevat informatie over het detecteren van veelvoorkomende prestatieproblemen door query's uit te voeren op dynamische beheerweergaven via T-SQL. U kunt elk queryprogramma gebruiken, zoals:
Bevoegdheden
In Azure SQL Database, afhankelijk van de rekengrootte en implementatieoptie, is het mogelijk dat voor het uitvoeren van query's op een DMV de machtiging VIEW DATABASE STATE of VIEW SERVER STATE is vereist. De laatste machtiging kan worden verleend via lidmaatschap van de ##MS_ServerStateReader## serverfunctie.
Als u de VIEW DATABASE STATE-machtiging wilt verlenen aan een specifieke databasegebruiker, voert u de volgende query uit als voorbeeld:
GRANT VIEW DATABASE STATE TO database_user;
Als u lidmaatschap wilt verlenen aan de ##MS_ServerStateReader## serverfunctie voor een aanmelding voor de logische server in Azure, maakt u verbinding met de master database en voert u de volgende query uit als voorbeeld:
ALTER SERVER ROLE [##MS_ServerStateReader##] ADD MEMBER [login];
In een exemplaar van SQL Server en in Azure SQL Managed Instance retourneren dynamische beheerweergaven serverstatusgegevens. In Azure SQL Database retourneren ze alleen informatie met betrekking tot uw huidige logische database.
CPU-prestatieproblemen identificeren
Als het CPU-verbruik gedurende langere perioden hoger is dan 80%, kunt u de volgende stappen voor probleemoplossing overwegen of het CPU-probleem zich nu voordoet of in het verleden heeft plaatsgevonden.
Het CPU-probleem treedt nu op
Als het probleem zich op dit moment voordoet, zijn er twee mogelijke scenario's:
Veel afzonderlijke query's die cumulatief hoge CPU verbruiken
Gebruik de volgende query om topquery-hashes te identificeren:
PRINT '-- top 10 Active CPU Consuming Queries (aggregated)--'; SELECT TOP 10 GETDATE() runtime, * FROM (SELECT query_stats.query_hash, SUM(query_stats.cpu_time) 'Total_Request_Cpu_Time_Ms', SUM(logical_reads) 'Total_Request_Logical_Reads', MIN(start_time) 'Earliest_Request_start_Time', COUNT(*) 'Number_Of_Requests', SUBSTRING(REPLACE(REPLACE(MIN(query_stats.statement_text), CHAR(10), ' '), CHAR(13), ' '), 1, 256) AS "Statement_Text" FROM (SELECT req.*, SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ) AS query_stats GROUP BY query_hash) AS t ORDER BY Total_Request_Cpu_Time_Ms DESC;
Langlopende query's die CPU verbruiken, worden nog steeds uitgevoerd
Gebruik de volgende query om deze query's te identificeren:
PRINT '--top 10 Active CPU Consuming Queries by sessions--'; SELECT TOP 10 req.session_id, req.start_time, cpu_time 'cpu_time_ms', OBJECT_NAME(ST.objectid, ST.dbid) 'ObjectName', SUBSTRING(REPLACE(REPLACE(SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1), CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ORDER BY cpu_time DESC; GO
Het CPU-probleem is in het verleden opgetreden
Als het probleem zich in het verleden heeft voorgedaan en u de hoofdoorzaakanalyse wilt uitvoeren, gebruikt u Query Store. Gebruikers met databasetoegang kunnen T-SQL gebruiken om query's uit te voeren op Query Store-gegevens. Standaardconfiguraties van Query Store gebruiken een granulariteit van 1 uur.
Gebruik de volgende query om te kijken naar activiteit voor query's met een hoog CPU-verbruik. Deze query retourneert de top 15 CPU-verbruikende query's. Vergeet niet om het volgende te wijzigen
rsi.start_time >= DATEADD(hour, -2, GETUTCDATE():-- Top 15 CPU consuming queries by query hash -- Note that a query hash can have many query ids if not parameterized or not parameterized properly WITH AggregatedCPU AS ( SELECT q.query_hash ,SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms ,SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms ,MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms ,MAX(max_logical_io_reads) max_logical_reads ,COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans ,COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids ,SUM(CASE WHEN rs.execution_type_desc = 'Aborted' THEN count_executions ELSE 0 END) AS Aborted_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Regular' THEN count_executions ELSE 0 END) AS Regular_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Exception' THEN count_executions ELSE 0 END) AS Exception_Execution_Count ,SUM(count_executions) AS total_executions ,MIN(qt.query_sql_text) AS sampled_query_text FROM sys.query_store_query_text AS qt INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id WHERE rs.execution_type_desc IN ('Regular','Aborted','Exception') AND rsi.start_time >= DATEADD(HOUR, - 2, GETUTCDATE()) GROUP BY q.query_hash ) ,OrderedCPU AS ( SELECT query_hash ,total_cpu_ms ,avg_cpu_ms ,max_cpu_ms ,max_logical_reads ,number_of_distinct_plans ,number_of_distinct_query_ids ,total_executions ,Aborted_Execution_Count ,Regular_Execution_Count ,Exception_Execution_Count ,sampled_query_text ,ROW_NUMBER() OVER ( ORDER BY total_cpu_ms DESC ,query_hash ASC ) AS query_hash_row_number FROM AggregatedCPU ) SELECT OD.query_hash ,OD.total_cpu_ms ,OD.avg_cpu_ms ,OD.max_cpu_ms ,OD.max_logical_reads ,OD.number_of_distinct_plans ,OD.number_of_distinct_query_ids ,OD.total_executions ,OD.Aborted_Execution_Count ,OD.Regular_Execution_Count ,OD.Exception_Execution_Count ,OD.sampled_query_text ,OD.query_hash_row_number FROM OrderedCPU AS OD WHERE OD.query_hash_row_number <= 15 --get top 15 rows by total_cpu_ms ORDER BY total_cpu_ms DESC;Zodra u de problematische query's hebt geïdentificeerd, is het tijd om deze query's af te stemmen om het CPU-gebruik te verminderen. Als u geen tijd hebt om de query's af te stemmen, kunt u er ook voor kiezen om de SLO van de database bij te werken om het probleem te omzeilen.
Zie Problemen met hoge CPU in Azure SQL Database vaststellen en oplossen voor meer informatie over het afhandelen van CPU-prestatieproblemen in Azure SQL Database.
I/O-prestatieproblemen identificeren
Bij het identificeren van prestatieproblemen met opslaginvoer/uitvoer (I/O), zijn de belangrijkste wachttypen die zijn gekoppeld aan I/O-problemen:
PAGEIOLATCH_*Voor I/O-problemen met gegevensbestanden (inclusief
PAGEIOLATCH_SH,PAGEIOLATCH_EX,PAGEIOLATCH_UP). Als de naam van het wachttype IO bevat, verwijst deze naar een I/O-probleem. Als er geen IO in de wachtnaam van de paginavergrendeling staat, verwijst deze naar een ander type probleem (bijvoorbeeldtempdbconflicten).WRITE_LOGVoor I/O-problemen met transactielogboeken.
Als het I/O-probleem zich op dit moment voordoet
Gebruik de sys.dm_exec_requests of sys.dm_os_waiting_tasks om de wait_type en wait_timete zien.
I/O-gebruik van gegevens en logboeken identificeren
Gebruik de volgende query om gegevens te identificeren en I/O-gebruik te registreren. Als de gegevens of logboek-I/O hoger zijn dan 80%, betekent dit dat gebruikers de beschikbare I/O voor de Azure SQL Database-servicelaag hebben gebruikt.
SELECT
database_name = DB_NAME()
, UTC_time = end_time
, 'CPU Utilization In % of Limit' = rs.avg_cpu_percent
, 'Data IO In % of Limit' = rs.avg_data_io_percent
, 'Log Write Utilization In % of Limit' = rs.avg_log_write_percent
, 'Memory Usage In % of Limit' = rs.avg_memory_usage_percent
, 'In-Memory OLTP Storage in % of Limit' = rs.xtp_storage_percent
, 'Concurrent Worker Threads in % of Limit' = rs.max_worker_percent
, 'Concurrent Sessions in % of Limit' = rs.max_session_percent
FROM sys.dm_db_resource_stats AS rs --past hour only
ORDER BY rs.end_time DESC;
Zie de sectie Resourcegebruik bewaken verderop in dit artikel voor meer voorbeeldensys.dm_db_resource_stats.
Als de I/O-limiet is bereikt, hebt u twee opties:
- De rekengrootte of servicelaag upgraden
- Identificeer en stem de query's af die de meeste I/O gebruiken.
Buffergerelateerde I/O weergeven met behulp van de Query Store
Voor optie 2 kunt u de volgende query voor Query Store gebruiken voor buffergerelateerde I/O om de laatste twee uur bijgehouden activiteit weer te geven:
-- Top queries that waited on buffer
-- Note these are finished queries
WITH Aggregated AS (SELECT q.query_hash, SUM(total_query_wait_time_ms) total_wait_time_ms, SUM(total_query_wait_time_ms / avg_query_wait_time_ms) AS total_executions, MIN(qt.query_sql_text) AS sampled_query_text, MIN(wait_category_desc) AS wait_category_desc
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id=q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id=p.query_id
INNER JOIN sys.query_store_wait_stats AS waits ON waits.plan_id=p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id=waits.runtime_stats_interval_id
WHERE wait_category_desc='Buffer IO' AND rsi.start_time>=DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash), Ordered AS (SELECT query_hash, total_executions, total_wait_time_ms, sampled_query_text, wait_category_desc, ROW_NUMBER() OVER (ORDER BY total_wait_time_ms DESC, query_hash ASC) AS query_hash_row_number
FROM Aggregated)
SELECT OD.query_hash, OD.total_executions, OD.total_wait_time_ms, OD.sampled_query_text, OD.wait_category_desc, OD.query_hash_row_number
FROM Ordered AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_wait_time_ms
ORDER BY total_wait_time_ms DESC;
GO
Totale logboek-I/O weergeven voor WRITELOG-wachttijden
Als het wachttype is WRITELOG, gebruikt u de volgende query om de totale logboek-I/O per instructie weer te geven:
-- Top transaction log consumers
-- Adjust the time window by changing
-- rsi.start_time >= DATEADD(hour, -2, GETUTCDATE())
WITH AggregatedLogUsed
AS (SELECT q.query_hash,
SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms,
SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms,
SUM(count_executions * avg_log_bytes_used) AS total_log_bytes_used,
MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms,
MAX(max_logical_io_reads) max_logical_reads,
COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans,
COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids,
SUM( CASE
WHEN rs.execution_type_desc = 'Aborted' THEN
count_executions
ELSE 0
END
) AS Aborted_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Regular' THEN
count_executions
ELSE 0
END
) AS Regular_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Exception' THEN
count_executions
ELSE 0
END
) AS Exception_Execution_Count,
SUM(count_executions) AS total_executions,
MIN(qt.query_sql_text) AS sampled_query_text
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id
INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE rs.execution_type_desc IN ( 'Regular', 'Aborted', 'Exception' )
AND rsi.start_time >= DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash),
OrderedLogUsed
AS (SELECT query_hash,
total_log_bytes_used,
number_of_distinct_plans,
number_of_distinct_query_ids,
total_executions,
Aborted_Execution_Count,
Regular_Execution_Count,
Exception_Execution_Count,
sampled_query_text,
ROW_NUMBER() OVER (ORDER BY total_log_bytes_used DESC, query_hash ASC) AS query_hash_row_number
FROM AggregatedLogUsed)
SELECT OD.total_log_bytes_used,
OD.number_of_distinct_plans,
OD.number_of_distinct_query_ids,
OD.total_executions,
OD.Aborted_Execution_Count,
OD.Regular_Execution_Count,
OD.Exception_Execution_Count,
OD.sampled_query_text,
OD.query_hash_row_number
FROM OrderedLogUsed AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_log_bytes_used
ORDER BY total_log_bytes_used DESC;
GO
Tempdb-prestatieproblemen identificeren
Bij het identificeren van I/O-prestatieproblemen zijn de belangrijkste wachttypen die zijn gekoppeld aan tempdb problemen PAGELATCH_* (niet PAGEIOLATCH_*). PAGELATCH_* Wachttijden betekenen echter niet altijd dat u conflicten hebttempdb. Dit wachten kan ook betekenen dat er een conflict voor een gegevenspagina voor gebruikersobjecten is opgetreden vanwege gelijktijdige aanvragen voor dezelfde gegevenspagina. Als u nog meer conflicten wilt bevestigen tempdb , gebruikt u sys.dm_exec_requests om te bevestigen dat de wait_resource waarde begint met 2:x:y waar 2 de database-id is tempdb , x de bestands-id is en y de pagina-id is.
Voor tempdb conflicten is een algemene methode het verminderen of herschrijven van toepassingscode tempdbdie afhankelijk is van . Algemene tempdb gebruiksgebieden zijn onder andere:
- Tijdelijke tabellen
- Tabelvariabelen
- Tabelwaardeparameters
- Gebruik van versieopslag (gekoppeld aan langlopende transacties)
- Query's met queryplannen die gebruikmaken van sorteringen, hash joins en spools
Zie tempdb in Azure SQL voor meer informatie.
Topquery's die gebruikmaken van tabelvariabelen en tijdelijke tabellen
Gebruik de volgende query om de belangrijkste query's te identificeren die gebruikmaken van tabelvariabelen en tijdelijke tabellen:
SELECT plan_handle, execution_count, query_plan
INTO #tmpPlan
FROM sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_query_plan(plan_handle);
GO
WITH XMLNAMESPACES('http://schemas.microsoft.com/sqlserver/2004/07/showplan' AS sp)
SELECT plan_handle, stmt.stmt_details.value('@Database', 'varchar(max)') AS 'Database'
, stmt.stmt_details.value('@Schema', 'varchar(max)') AS 'Schema'
, stmt.stmt_details.value('@Table', 'varchar(max)') AS 'table'
INTO #tmp2
FROM
(SELECT CAST(query_plan AS XML) sqlplan, plan_handle FROM #tmpPlan) AS p
CROSS APPLY sqlplan.nodes('//sp:Object') AS stmt(stmt_details);
GO
SELECT t.plan_handle, [Database], [Schema], [table], execution_count
FROM
(SELECT DISTINCT plan_handle, [Database], [Schema], [table]
FROM #tmp2
WHERE [table] LIKE '%@%' OR [table] LIKE '%#%') AS t
INNER JOIN #tmpPlan AS t2 ON t.plan_handle=t2.plan_handle;
GO
DROP TABLE #tmpPlan
DROP TABLE #tmp2
Langlopende transacties identificeren
Gebruik de volgende query om langlopende transacties te identificeren. Langdurige transacties verhinderen het opschonen van permanente versieopslag (PVS). Zie Problemen met versneld databaseherstel oplossen voor meer informatie.
SELECT DB_NAME(dtr.database_id) 'database_name',
sess.session_id,
atr.name AS 'tran_name',
atr.transaction_id,
transaction_type,
transaction_begin_time,
database_transaction_begin_time,
transaction_state,
is_user_transaction,
sess.open_transaction_count,
TRIM(REPLACE(
REPLACE(
SUBSTRING(
SUBSTRING(
txt.text,
(req.statement_start_offset / 2) + 1,
((CASE req.statement_end_offset
WHEN -1 THEN
DATALENGTH(txt.text)
ELSE
req.statement_end_offset
END - req.statement_start_offset
) / 2
) + 1
),
1,
1000
),
CHAR(10),
' '
),
CHAR(13),
' '
)
) Running_stmt_text,
recenttxt.text 'MostRecentSQLText'
FROM sys.dm_tran_active_transactions AS atr
INNER JOIN sys.dm_tran_database_transactions AS dtr
ON dtr.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_tran_session_transactions AS sess
ON sess.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_exec_requests AS req
ON req.session_id = sess.session_id
AND req.transaction_id = sess.transaction_id
LEFT JOIN sys.dm_exec_connections AS conn
ON sess.session_id = conn.session_id
OUTER APPLY sys.dm_exec_sql_text(req.sql_handle) AS txt
OUTER APPLY sys.dm_exec_sql_text(conn.most_recent_sql_handle) AS recenttxt
WHERE atr.transaction_type != 2
AND sess.session_id != @@spid
ORDER BY start_time ASC;
Problemen met wachttijden voor geheugentoekenning identificeren
Als uw belangrijkste wachttype is RESOURCE_SEMAPHORE en u geen probleem hebt met hoog CPU-gebruik, is er mogelijk een probleem met de geheugentoekenning.
Bepalen of een RESOURCE_SEMAPHORE wachten een topwacht is
Gebruik de volgende query om te bepalen of een RESOURCE_SEMAPHORE wachttijd een topwacht is. Indicatief zou ook een stijgende wachttijdsrang zijn van RESOURCE_SEMAPHORE in de recente geschiedenis. Zie Problemen met trage prestaties of onvoldoende geheugen oplossen die worden veroorzaakt door geheugentoelagen in SQL Server voor meer informatie over het oplossen van wachtproblemen met geheugentoelagen.
SELECT wait_type,
SUM(wait_time) AS total_wait_time_ms
FROM sys.dm_exec_requests AS req
INNER JOIN sys.dm_exec_sessions AS sess
ON req.session_id = sess.session_id
WHERE is_user_process = 1
GROUP BY wait_type
ORDER BY SUM(wait_time) DESC;
Instructies voor hoog geheugengebruik identificeren
Als er onvoldoende geheugenfouten optreden in Azure SQL Database, raadpleegt u sys.dm_os_out_of_memory_events. Zie Problemen met onvoldoende geheugen oplossen met Azure SQL Database voor meer informatie.
Wijzig eerst het onderstaande script om relevante waarden van start_time en end_timebij te werken. Voer vervolgens de volgende query uit om instructies te identificeren die veel geheugen verbruiken:
SELECT IDENTITY(INT, 1, 1) rowId,
CAST(query_plan AS XML) query_plan,
p.query_id
INTO #tmp
FROM sys.query_store_plan AS p
INNER JOIN sys.query_store_runtime_stats AS r
ON p.plan_id = r.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS i
ON r.runtime_stats_interval_id = i.runtime_stats_interval_id
WHERE start_time > '2018-10-11 14:00:00.0000000'
AND end_time < '2018-10-17 20:00:00.0000000';
GO
;WITH cte
AS (SELECT query_id,
query_plan,
m.c.value('@SerialDesiredMemory', 'INT') AS SerialDesiredMemory
FROM #tmp AS t
CROSS APPLY t.query_plan.nodes('//*:MemoryGrantInfo[@SerialDesiredMemory[. > 0]]') AS m(c) )
SELECT TOP 50
cte.query_id,
t.query_sql_text,
cte.query_plan,
CAST(SerialDesiredMemory / 1024. AS DECIMAL(10, 2)) SerialDesiredMemory_MB
FROM cte
INNER JOIN sys.query_store_query AS q
ON cte.query_id = q.query_id
INNER JOIN sys.query_store_query_text AS t
ON q.query_text_id = t.query_text_id
ORDER BY SerialDesiredMemory DESC;
De tien belangrijkste actieve geheugentoelagen identificeren
Gebruik de volgende query om de tien belangrijkste actieve geheugentoelagen te identificeren:
SELECT TOP 10
CONVERT(VARCHAR(30), GETDATE(), 121) AS runtime,
r.session_id,
r.blocking_session_id,
r.cpu_time,
r.total_elapsed_time,
r.reads,
r.writes,
r.logical_reads,
r.row_count,
wait_time,
wait_type,
r.command,
OBJECT_NAME(txt.objectid, txt.dbid) 'Object_Name',
TRIM(REPLACE(REPLACE(SUBSTRING(SUBSTRING(TEXT, (r.statement_start_offset / 2) + 1,
( (
CASE r.statement_end_offset
WHEN - 1
THEN DATALENGTH(TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset
) / 2
) + 1), 1, 1000), CHAR(10), ' '), CHAR(13), ' ')) AS stmt_text,
mg.dop, --Degree of parallelism
mg.request_time, --Date and time when this query requested the memory grant.
mg.grant_time, --NULL means memory has not been granted
mg.requested_memory_kb / 1024.0 requested_memory_mb, --Total requested amount of memory in megabytes
mg.granted_memory_kb / 1024.0 AS granted_memory_mb, --Total amount of memory actually granted in megabytes. NULL if not granted
mg.required_memory_kb / 1024.0 AS required_memory_mb, --Minimum memory required to run this query in megabytes.
max_used_memory_kb / 1024.0 AS max_used_memory_mb,
mg.query_cost, --Estimated query cost.
mg.timeout_sec, --Time-out in seconds before this query gives up the memory grant request.
mg.resource_semaphore_id, --Non-unique ID of the resource semaphore on which this query is waiting.
mg.wait_time_ms, --Wait time in milliseconds. NULL if the memory is already granted.
CASE mg.is_next_candidate --Is this process the next candidate for a memory grant
WHEN 1 THEN
'Yes'
WHEN 0 THEN
'No'
ELSE
'Memory has been granted'
END AS 'Next Candidate for Memory Grant',
qp.query_plan
FROM sys.dm_exec_requests AS r
INNER JOIN sys.dm_exec_query_memory_grants AS mg
ON r.session_id = mg.session_id
AND r.request_id = mg.request_id
CROSS APPLY sys.dm_exec_sql_text(mg.sql_handle) AS txt
CROSS APPLY sys.dm_exec_query_plan(r.plan_handle) AS qp
ORDER BY mg.granted_memory_kb DESC;
Verbindingen bewaken
U kunt de weergave sys.dm_exec_connections gebruiken om informatie op te halen over de verbindingen die tot stand zijn gebracht met een specifieke database of elastische pool en de details van elke verbinding. Daarnaast is de weergave sys.dm_exec_sessions handig bij het ophalen van informatie over alle actieve gebruikersverbindingen en interne taken.
Huidige sessies weergeven
De volgende query haalt informatie op over de huidige verbinding. Als u alle sessies wilt weergeven, verwijdert u de WHERE component.
U ziet alle uitvoersessies op de database alleen als u de machtiging DATABASESTATUS WEERGEVEN hebt voor de database bij het uitvoeren van de sys.dm_exec_requests en sys.dm_exec_sessions weergaven. Anders ziet u alleen de huidige sessie.
SELECT
c.session_id, c.net_transport, c.encrypt_option,
c.auth_scheme, s.host_name, s.program_name,
s.client_interface_name, s.login_name, s.nt_domain,
s.nt_user_name, s.original_login_name, c.connect_time,
s.login_time
FROM sys.dm_exec_connections AS c
INNER JOIN sys.dm_exec_sessions AS s
ON c.session_id = s.session_id
WHERE c.session_id = @@SPID; --Remove to view all sessions, if permissions allow
Resourcegebruik bewaken
U kunt het resourcegebruik van Azure SQL Database op queryniveau bewaken met behulp van SQL Database Query Performance Insight in Azure Portal of de Query Store.
U kunt ook het gebruik bewaken met behulp van deze weergaven:
sys.dm_db_resource_stats
U kunt de sys.dm_db_resource_stats weergave in elke database gebruiken. In sys.dm_db_resource_stats de weergave ziet u recente gegevens over resourcegebruik ten opzichte van de servicelaag. Gemiddelde percentages voor CPU, gegevens-I/O, schrijfbewerkingen in logboeken en geheugen worden elke 15 seconden geregistreerd en worden gedurende 1 uur bijgehouden.
Omdat deze weergave een gedetailleerder overzicht biedt van het gebruik van resources, gebruikt sys.dm_db_resource_stats u eerst voor een analyse van de huidige status of probleemoplossing. In deze query ziet u bijvoorbeeld het gemiddelde en maximale resourcegebruik voor de huidige database in het afgelopen uur:
SELECT
Database_Name = DB_NAME(),
tier_limit = COALESCE(rs.dtu_limit, cpu_limit), --DTU or vCore limit
AVG(avg_cpu_percent) AS 'Average CPU use in percent',
MAX(avg_cpu_percent) AS 'Maximum CPU use in percent',
AVG(avg_data_io_percent) AS 'Average data IO in percent',
MAX(avg_data_io_percent) AS 'Maximum data IO in percent',
AVG(avg_log_write_percent) AS 'Average log write use in percent',
MAX(avg_log_write_percent) AS 'Maximum log write use in percent',
AVG(avg_memory_usage_percent) AS 'Average memory use in percent',
MAX(avg_memory_usage_percent) AS 'Maximum memory use in percent'
FROM sys.dm_db_resource_stats AS rs --past hour only
GROUP BY rs.dtu_limit, rs.cpu_limit;
Zie de voorbeelden in sys.dm_db_resource_stats voor andere query's.
sys.resource_stats
De sys.resource_stats weergave in de master database bevat aanvullende informatie waarmee u de prestaties van uw database kunt bewaken op de specifieke servicelaag en rekenkracht. De gegevens worden om de 5 minuten verzameld en worden ongeveer 14 dagen bewaard. Deze weergave is handig voor een langetermijnanalyse van de wijze waarop uw database gebruikmaakt van resources.
In de volgende grafiek ziet u het cpu-resourcegebruik voor een Premium-database met de P2-rekenkracht voor elk uur in een week. Deze grafiek begint op een maandag, toont vijf werkdagen en geeft vervolgens een weekend weer, wanneer er veel minder gebeurt in de toepassing.
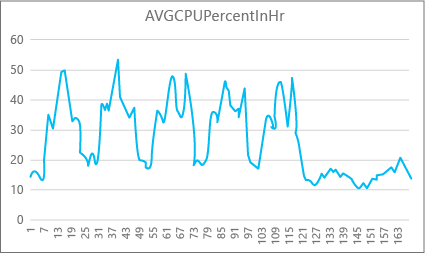
Uit de gegevens heeft deze database momenteel een piekbelasting van meer dan 50 procent CPU-gebruik ten opzichte van de P2-rekenkracht (dinsdagochtend). Als CPU de dominante factor is in het resourceprofiel van de toepassing, kunt u besluiten dat P2 de juiste rekenkracht is om ervoor te zorgen dat de workload altijd past. Als u verwacht dat een toepassing na verloop van tijd groeit, is het een goed idee om een extra resourcebuffer te hebben, zodat de toepassing nooit de limiet op prestatieniveau bereikt. Als u de rekenkracht verhoogt, kunt u helpen bij het voorkomen van door de klant zichtbare fouten die kunnen optreden wanneer een database niet over voldoende vermogen beschikt om aanvragen effectief te verwerken, met name in latentiegevoelige omgevingen. Een voorbeeld is een database die ondersteuning biedt voor een toepassing die webpagina's schildert op basis van de resultaten van databaseaanroepen.
Andere toepassingstypen kunnen dezelfde grafiek anders interpreteren. Als een toepassing bijvoorbeeld elke dag loongegevens probeert te verwerken en dezelfde grafiek heeft, kan dit soort 'batchtaak'-model prima werken met een P1-rekenkracht. De P1-rekenkracht heeft 100 DTU's vergeleken met 200 DTU's bij de P2-rekenkracht. De P1-rekenkracht biedt de helft van de prestaties van de P2-rekenkracht. Dus 50 procent van het CPU-gebruik in P2 is gelijk aan 100 procent CPU-gebruik in P1. Als de toepassing geen time-outs heeft, maakt het mogelijk niet uit of het 2 uur of 2,5 uur duurt voordat een taak is voltooid, als deze vandaag wordt uitgevoerd. Een toepassing in deze categorie kan waarschijnlijk een P1-rekenkracht gebruiken. U kunt profiteren van het feit dat er perioden zijn gedurende de dag waarop het resourcegebruik lager is, zodat elke 'grote piek' later in de dag kan overlopen in een van de dalen. De P1-rekenkracht kan goed zijn voor dat soort toepassingen (en geld besparen), zolang de taken elke dag op tijd kunnen worden voltooid.
De database-engine toont verbruikte resourcegegevens voor elke actieve database in de sys.resource_stats weergave van de master database op elke server. De gegevens in de tabel worden geaggregeerd voor intervallen van vijf minuten. Met de servicelagen Basic, Standard en Premium kunnen de gegevens langer dan 5 minuten in de tabel worden weergegeven, zodat deze gegevens nuttiger zijn voor historische analyses in plaats van bijna realtime-analyse. Voer een query uit in de sys.resource_stats weergave om de recente geschiedenis van een database te bekijken en te controleren of de reservering die u hebt gekozen, de gewenste prestaties heeft geleverd wanneer dat nodig is.
Notitie
In Azure SQL Database moet u zijn verbonden met de master database om een query uit te voeren sys.resource_stats in de volgende voorbeelden.
In dit voorbeeld ziet u hoe de gegevens in deze weergave worden weergegeven:
SELECT TOP 10 *
FROM sys.resource_stats
WHERE database_name = 'userdb1'
ORDER BY start_time DESC;
In het volgende voorbeeld ziet u verschillende manieren waarop u de sys.resource_stats catalogusweergave kunt gebruiken voor informatie over hoe uw database gebruikmaakt van resources:
Als u wilt kijken naar het resourcegebruik van de afgelopen week voor de gebruikersdatabase
userdb1, kunt u deze query uitvoeren, waarbij u uw eigen databasenaam vervangt:SELECT * FROM sys.resource_stats WHERE database_name = 'userdb1' AND start_time > DATEADD(day, -7, GETDATE()) ORDER BY start_time DESC;Als u wilt evalueren hoe goed uw workload past bij de rekenkracht, moet u inzoomen op elk aspect van de metrische resourcegegevens: CPU, leesbewerkingen, schrijfbewerkingen, aantal werkrollen en aantal sessies. Hier volgt een herziene query voor
sys.resource_statshet rapporteren van de gemiddelde en maximumwaarden van deze metrische resourcegegevens voor elke servicelaag waarvoor de database is ingericht:SELECT rs.database_name , rs.sku , storage_mb = MAX(rs.Storage_in_megabytes) , 'Average CPU Utilization In %' = AVG(rs.avg_cpu_percent) , 'Maximum CPU Utilization In %' = MAX(rs.avg_cpu_percent) , 'Average Data IO In %' = AVG(rs.avg_data_io_percent) , 'Maximum Data IO In %' = MAX(rs.avg_data_io_percent) , 'Average Log Write Utilization In %' = AVG(rs.avg_log_write_percent) , 'Maximum Log Write Utilization In %' = MAX(rs.avg_log_write_percent) , 'Average Requests In %' = AVG(rs.max_worker_percent) , 'Maximum Requests In %' = MAX(rs.max_worker_percent) , 'Average Sessions In %' = AVG(rs.max_session_percent) , 'Maximum Sessions In %' = MAX(rs.max_session_percent) FROM sys.resource_stats AS rs WHERE rs.database_name = 'userdb1' AND rs.start_time > DATEADD(day, -7, GETDATE()) GROUP BY rs.database_name, rs.sku;Met deze informatie over de gemiddelde en maximumwaarden van elke metrische resource kunt u beoordelen hoe goed uw workload past in de rekengrootte die u hebt gekozen. Normaal gesproken geven gemiddelde waarden
sys.resource_statsu een goede basislijn die u kunt gebruiken voor de doelgrootte. Het moet uw primaire meetstick zijn.Voor DTU-aankoopmodeldatabases :
U kunt bijvoorbeeld de Standard-servicelaag met S2-rekenkracht gebruiken. Het gemiddelde gebruikspercentage voor CPU- en I/O-lees- en schrijfbewerkingen is lager dan 40 procent, het gemiddelde aantal werkrollen is lager dan 50 en het gemiddelde aantal sessies is lager dan 200. Uw workload kan in de S1-rekenkracht passen. U kunt eenvoudig zien of uw database past in de werkrol- en sessielimieten. Als u wilt zien of een database in een lagere rekenkracht past, deelt u het DTU-nummer van de lagere rekenkracht door het DTU-getal van uw huidige rekenkracht en vermenigvuldigt u het resultaat met 100:
S1 DTU / S2 DTU * 100 = 20 / 50 * 100 = 40Het resultaat is het relatieve prestatieverschil tussen de twee rekengrootten in percentage. Als uw resourcegebruik deze hoeveelheid niet overschrijdt, kan uw workload in de lagere rekenkracht passen. U moet echter alle bereiken met resourcegebruikswaarden bekijken en bepalen hoe vaak uw databaseworkload in de lagere rekenkracht past. Met de volgende query wordt het passend percentage per resourcedimensie uitgevoerd op basis van de drempelwaarde van 40 procent die we in dit voorbeeld hebben berekend:
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;Op basis van uw databaseservicelaag kunt u bepalen of uw workload in de lagere rekenkracht past. Als uw databaseworkloaddoelstelling 99,9 procent is en de voorgaande query waarden retourneert die groter zijn dan 99,9 procent voor alle drie de resourcedimensies, past uw workload waarschijnlijk in de lagere rekenkracht.
Als u het passend percentage bekijkt, krijgt u ook inzicht in of u naar de volgende hogere rekenkracht moet gaan om aan uw doelstelling te voldoen. Bijvoorbeeld het CPU-gebruik voor een voorbeelddatabase in de afgelopen week:
Gemiddeld CPU-percentage Maximum CPU-percentage 24.5 100.00 De gemiddelde CPU is ongeveer een kwart van de limiet van de rekenkracht, die goed in de rekenkracht van de database past.
Voor DTU-aankoopmodel - en vCore-aankoopmodeldatabases :
De maximumwaarde laat zien dat de database de limiet van de rekenkracht bereikt. Moet u naar de volgende hogere rekenkracht gaan? Bekijk hoe vaak uw workload 100 procent bereikt en vergelijk deze vervolgens met de doelstelling van uw databaseworkload.
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;Deze percentages zijn het aantal steekproeven dat uw workload onder de huidige rekenkracht past. Als deze query een waarde retourneert die kleiner is dan 99,9 procent voor een van de drie resourcedimensies, heeft uw steekproefgemiddelde gemiddelde workload de limieten overschreden. Overweeg om over te stappen op de volgende hogere rekenkracht of gebruik technieken voor het afstemmen van toepassingen om de belasting van de database te verminderen.
Notitie
Voor elastische pools kunt u afzonderlijke databases in de pool bewaken met de technieken die in deze sectie zijn beschreven. U kunt de pool ook als geheel bewaken. Zie Een elastische pool bewaken en beheren voor meer informatie.
Maximum aantal gelijktijdige aanvragen
Als u het huidige aantal gelijktijdige aanvragen wilt zien, voert u deze query uit op uw gebruikersdatabase:
SELECT COUNT(*) AS [Concurrent_Requests]
FROM sys.dm_exec_requests AS R;
Als u de workload van een database wilt analyseren, wijzigt u deze query om te filteren op de specifieke database die u wilt analyseren. Werk eerst de naam van de database bij naar MyDatabase de gewenste database en voer vervolgens de volgende query uit om het aantal gelijktijdige aanvragen in die database te vinden:
SELECT COUNT(*) AS [Concurrent_Requests]
FROM sys.dm_exec_requests AS R
INNER JOIN sys.databases AS D
ON D.database_id = R.database_id
AND D.name = 'MyDatabase';
Dit is slechts een momentopname op een bepaald moment. Als u meer inzicht wilt krijgen in uw workload en gelijktijdige aanvraagvereisten, moet u in de loop van de tijd veel voorbeelden verzamelen.
Maximum aantal gelijktijdige aanmeldingsevenementen
U kunt uw gebruikers- en toepassingspatronen analyseren om een idee te krijgen van de frequentie van aanmeldingsevenementen. U kunt ook echte laadbewerkingen uitvoeren in een testomgeving om ervoor te zorgen dat u niet aan deze of andere limieten komt die in dit artikel worden besproken. Er is geen enkele query of dynamische beheerweergave (DMV) waarmee u gelijktijdige aanmeldingsaantallen of geschiedenis kunt weergeven.
Als meerdere clients dezelfde verbindingsreeks gebruiken, verifieert de service elke aanmelding. Als 10 gebruikers tegelijkertijd verbinding maken met een database met dezelfde gebruikersnaam en hetzelfde wachtwoord, zijn er 10 gelijktijdige aanmeldingen. Deze limiet geldt alleen voor de duur van de aanmelding en verificatie. Als dezelfde 10 gebruikers opeenvolgend verbinding maken met de database, is het aantal gelijktijdige aanmeldingen nooit groter dan 1.
Notitie
Deze limiet is momenteel niet van toepassing op databases in elastische pools.
Maximum aantal sessies
Als u het aantal huidige actieve sessies wilt zien, voert u deze query uit op uw database:
SELECT COUNT(*) AS [Sessions]
FROM sys.dm_exec_connections;
Als u een SQL Server-workload analyseert, wijzigt u de query zodat deze zich op een specifieke database richt. Deze query helpt u bij het bepalen van de mogelijke sessiebehoeften voor de database als u overweegt deze naar Azure te verplaatsen. Werk eerst de naam van de database bij naar MyDatabase de gewenste database en voer vervolgens de volgende query uit:
SELECT COUNT(*) AS [Sessions]
FROM sys.dm_exec_connections AS C
INNER JOIN sys.dm_exec_sessions AS S
ON (S.session_id = C.session_id)
INNER JOIN sys.databases AS D
ON (D.database_id = S.database_id)
WHERE D.name = 'MyDatabase';
Opnieuw retourneren deze query's een aantal punten in de tijd. Als u in de loop van de tijd meerdere voorbeelden verzamelt, hebt u het beste inzicht in uw sessiegebruik.
U kunt historische statistieken over sessies ophalen door een query uit te voeren op de sys.resource_stats catalogusweergave en de active_session_count kolom te bekijken.
Grootten van databases en objecten berekenen
Met de volgende query wordt de grootte van uw database geretourneerd (in megabytes):
-- Calculates the size of the database.
SELECT SUM(CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8192.) / 1024 / 1024 AS size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
Met de volgende query wordt de grootte van afzonderlijke objecten geretourneerd (in megabytes):
-- Calculates the size of individual database objects.
SELECT o.name, SUM(ps.reserved_page_count) * 8.0 / 1024 AS size_mb
FROM sys.dm_db_partition_stats AS ps
INNER JOIN sys.objects AS o
ON ps.object_id = o.object_id
GROUP BY o.name
ORDER BY size_mb DESC;
Queryprestaties bewaken
Trage of langdurige query's kunnen aanzienlijke systeembronnen verbruiken. In deze sectie ziet u hoe u dynamische beheerweergaven gebruikt om enkele veelvoorkomende problemen met queryprestaties te detecteren met behulp van de sys.dm_exec_query_stats dynamische beheerweergave. De weergave bevat één rij per query-instructie in het cacheplan en de levensduur van de rijen is gekoppeld aan het plan zelf. Wanneer een plan uit de cache wordt verwijderd, worden de bijbehorende rijen uit deze weergave verwijderd.
Topquery's zoeken op CPU-tijd
Het volgende voorbeeld retourneert informatie over de top 15 query's gerangschikt op gemiddelde CPU-tijd per uitvoering. In dit voorbeeld worden de query's samengevoegd op basis van hun query-hash, zodat logisch equivalente query's worden gegroepeerd op basis van het cumulatieve resourceverbruik.
SELECT TOP 15 query_stats.query_hash AS "Query Hash",
SUM(query_stats.total_worker_time) / SUM(query_stats.execution_count) AS "Avg CPU Time",
MIN(query_stats.statement_text) AS "Statement Text"
FROM
(SELECT QS.*,
SUBSTRING(ST.text, (QS.statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(ST.text)
ELSE QS.statement_end_offset END
- QS.statement_start_offset)/2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS QS
CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) AS ST
) AS query_stats
GROUP BY query_stats.query_hash
ORDER BY 2 DESC;
Queryplannen bewaken voor cumulatieve CPU-tijd
Een inefficiënt queryplan kan ook het CPU-verbruik verhogen. In het volgende voorbeeld wordt bepaald welke query gebruikmaakt van de meest cumulatieve CPU in de recente geschiedenis.
SELECT
highest_cpu_queries.plan_handle,
highest_cpu_queries.total_worker_time,
q.dbid,
q.objectid,
q.number,
q.encrypted,
q.[text]
FROM
(SELECT TOP 15
qs.plan_handle,
qs.total_worker_time
FROM
sys.dm_exec_query_stats AS qs
ORDER BY qs.total_worker_time desc
) AS highest_cpu_queries
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
ORDER BY highest_cpu_queries.total_worker_time DESC;
Geblokkeerde query's bewaken
Trage of langlopende query's kunnen bijdragen aan overmatig resourceverbruik en kunnen het gevolg zijn van geblokkeerde query's. De oorzaak van de blokkering kan een slecht toepassingsontwerp zijn, slechte queryplannen, het ontbreken van nuttige indexen, enzovoort.
U kunt de sys.dm_tran_locks weergave gebruiken om informatie op te halen over de huidige vergrendelingsactiviteit in de database. Zie bijvoorbeeld sys.dm_tran_locks. Zie Azure SQL-blokkeringsproblemen begrijpen en oplossen voor meer informatie over het oplossen van blokkeringsproblemen.
Impasses bewaken
In sommige gevallen kunnen twee of meer query's elkaar blokkeren, wat resulteert in een impasse.
U kunt een uitgebreide gebeurtenissen maken om een database in Azure SQL Database te traceren om impasse-gebeurtenissen vast te leggen en vervolgens gerelateerde query's en hun uitvoeringsplannen te vinden in Query Store. Meer informatie in Analyseren en impasses voorkomen in Azure SQL Database, waaronder een lab om een impasse in AdventureWorksLT te veroorzaken. Meer informatie over de typen resources die kunnen vastlopen.
Volgende stappen
- Inleiding tot Azure SQL Database en Azure SQL Managed Instance
- Problemen met hoog CPU-gebruik in Azure SQL Database vaststellen en oplossen
- Toepassingen en databases afstemmen voor prestaties in Azure SQL Database
- Problemen met blokkerende Azure SQL Database begrijpen en oplossen
- Impasses in Azure SQL Database analyseren en voorkomen