Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
van toepassing op:![]() Azure SQL Database-
Azure SQL Database-
Dit artikel bevat een overzicht van resourcebeheer in Azure SQL Database. Het biedt informatie over wat er gebeurt wanneer resourcelimieten worden bereikt en beschrijft mechanismen voor resourcebeheer die worden gebruikt om deze limieten af te dwingen.
Raadpleeg een van de volgende opties voor specifieke resourcelimieten per prijscategorie voor individuele databases:
- op DTU gebaseerde resourcelimieten voor individuele databases
- op vCore gebaseerde resourcelimieten voor individuele databases
Raadpleeg een van de volgende opties voor resourcelimieten voor elastische pools:
- resourcelimieten voor elastische pool op basis van DTU
- resourcelimieten voor elastische pool op basis van vCore
Raadpleeg voor limieten voor toegewezen SQL-pools in Azure Synapse Analytics:
Abonnements-vCore-limieten per regio
Vanaf maart 2024 hebben abonnementen de volgende vCore-limieten per regio per abonnement:
| Abonnementstype | Standaardlimieten voor vCore |
|---|---|
| Ondernemingsovereenkomst (EA) | 2000 |
| Gratis proefversies | 10 |
| Microsoft voor start-ups | 100 |
| MSDN/MPN/Imagine/AzurePass/Azure for Students | 40 |
| Betalen per gebruik (PAYG) | 150 |
Houd rekening met het volgende:
- Deze limieten zijn van toepassing op nieuwe en bestaande abonnementen.
- Databases en elastische pools die zijn ingericht met het DTU-aankoopmodel worden meegeteld voor het vCore-quotum en omgekeerd. Elke verbruikte vCore wordt beschouwd als equivalent aan 100 DTU's die worden gebruikt voor het quotum op serverniveau.
- Standaardlimieten zijn zowel de vCores die zijn geconfigureerd voor ingerichte rekendatabases/elastische pools en de maximum aantal vCores geconfigureerd voor serverloze databases.
- U kunt de -abonnementsgebruiken gebruiken: haal REST API-aanroep op om uw huidige vCore-gebruik voor uw abonnement te bepalen.
- Als u een hoger vCore-quotum wilt aanvragen dan de standaardwaarde, dient u een nieuwe ondersteuningsaanvraag in azure Portal in. Zie Quotumverhogingen aanvragen voor Azure SQL Database en SQL Managed Instancevoor meer informatie.
Limieten voor logische servers
| Hulpbron | Grens |
|---|---|
| Databases per logische server | 5.000 |
| Standaardaantal logische servers per abonnement in een regio | 250 |
| Maximum aantal logische servers per abonnement in een regio | 250 |
| Maximaal aantal elastische pools per logische server | Beperkt door het aantal DTU's of vCores. Als elke pool bijvoorbeeld 1000 DTU's is, kan een server 54 pools ondersteunen. |
Belangrijk
Naarmate het aantal databases de limiet per logische server nadert, kan het volgende gebeuren:
- Toenemende latentie bij het uitvoeren van query's voor de
master-database. Dit omvat weergaven van statistieken over resourcegebruik, zoalssys.resource_stats. - Toenemende latentie in beheerbewerkingen en weergaveportal-uitkijkpunten die betrekking hebben op het inventariseren van databases op de server.
Wat gebeurt er wanneer resourcelimieten worden bereikt
CPU berekenen
Wanneer het CPU-gebruik van de database hoog wordt, neemt de querylatentie toe en kunnen query's zelfs een time-out veroorzaken. Onder deze omstandigheden kunnen query's in de wachtrij worden geplaatst door de service en worden resources geleverd voor uitvoering wanneer resources gratis worden.
Als u een hoog rekengebruik ziet, zijn de risicobeperkingsopties onder andere:
- Verhoog de rekenkracht van de database of elastische pool om de database meer rekenresources te bieden. Zie Resources voor één database schalen en Resources voor elastische pools schalen.
- Query's optimaliseren om het CPU-resourcegebruik van elke query te verminderen. Zie queryafstemming/hintingvoor meer informatie.
Opslag
Wanneer de gebruikte gegevensruimte de maximale limiet voor gegevensgrootte bereikt, hetzij op databaseniveau of op het niveau van de elastische pool, worden ingevoegd en bijgewerkt die de gegevensgrootte vergroten, en ontvangen clients een foutbericht. SELECT- en DELETE-instructies blijven ongewijzigd.
In premium- en bedrijfskritieke servicelagen ontvangen clients ook een foutbericht als het gecombineerde opslagverbruik per gegevens, transactielogboek en tempdb voor één database of een elastische pool de maximale lokale opslaggrootte overschrijdt. Zie Storage space governancevoor meer informatie.
Als u een hoog gebruik van opslagruimte bekijkt, zijn de risicobeperkingsopties onder andere:
- Verhoog de maximale gegevensgrootte van de database of elastische pool of schaal omhoog naar een servicedoelstelling met een hogere maximale gegevensgroottelimiet. Zie Resources voor één database schalen en Resources voor elastische pools schalen.
- Als de database zich in een elastische pool bevindt, kan de database ook buiten de pool worden verplaatst, zodat de opslagruimte niet wordt gedeeld met andere databases.
- Verklein een database om ongebruikte ruimte vrij te maken. Zie Bestandsruimte voor databases beherenvoor meer informatie.
- In elastische pools biedt het verkleinen van een database meer opslagruimte voor andere databases in de pool.
- Controleer of het gebruik van hoge ruimte wordt veroorzaakt door een piek in de grootte van Persistent Version Store (PVS). PVS maakt deel uit van elke database en wordt gebruikt voor het implementeren van versneld databaseherstel. Zie Problemen met versneld databaseherstel oplossenom de huidige PVS-grootte te bepalen. Een veelvoorkomende reden voor grote PVS-grootte is een transactie die gedurende lange tijd (uren) is geopend, waardoor het opschonen van oudere versies van rijen in PVS wordt voorkomen.
- Voor databases en elastische pools in Premium- en Bedrijfskritieke servicelagen die grote hoeveelheden opslagruimte verbruiken, ontvangt u mogelijk een out-of-space-fout, zelfs als de gebruikte ruimte in de database of elastische pool onder de maximale limiet voor gegevensgrootte ligt. Dit kan gebeuren als
tempdbof transactielogboekbestanden een grote hoeveelheid opslagruimte verbruiken naar de maximale lokale opslaglimiet. failover-overschakeling de database of elastische pool omtempdbopnieuw in te stellen op de oorspronkelijke kleinere grootte, of transactielogboek verkleinen om het lokale opslagverbruik te verminderen.
Sessies, werknemers en aanvragen
Sessies, werknemers en aanvragen worden als volgt gedefinieerd:
- Een sessie vertegenwoordigt een proces dat is verbonden met de database-engine.
- Een aanvraag is de logische weergave van een query of batch. Een aanvraag wordt uitgegeven door een client die is verbonden met een sessie. Na verloop van tijd kunnen meerdere aanvragen worden uitgegeven in dezelfde sessie.
- Een werkrolthread, ook wel een werkrol of thread genoemd, is een logische weergave van een besturingssysteemthread. Een aanvraag kan veel werkrollen hebben wanneer deze worden uitgevoerd met een parallel uitvoeringsplan voor query's of één werkrol wanneer deze wordt uitgevoerd met een serieel (één threaded) uitvoeringsplan. Werknemers zijn ook vereist om activiteiten buiten aanvragen te ondersteunen: een werknemer is bijvoorbeeld vereist om een aanmeldingsaanvraag te verwerken wanneer een sessie verbinding maakt.
Zie de Thread- en taakarchitectuurhandleidingvoor meer informatie over deze concepten.
Het maximum aantal werkrollen wordt bepaald door de servicelaag en rekenkracht. Nieuwe aanvragen worden geweigerd wanneer sessie- of werklimieten worden bereikt en clients een foutbericht ontvangen. Hoewel het aantal verbindingen kan worden beheerd door de toepassing, is het aantal gelijktijdige werknemers vaak moeilijker te schatten en te beheren. Dit geldt met name tijdens piekbelastingsperioden wanneer databaseresourcelimieten worden bereikt en werkrollen zich opstapelen vanwege langere query's, grote blokkerende ketens of overmatige parallelle uitvoering van query's.
Notitie
De eerste aanbieding van Azure SQL Database ondersteunde alleen query's met één thread. Op dat moment was het aantal aanvragen altijd gelijk aan het aantal werknemers. Foutbericht 10928 in Azure SQL Database bevat alleen de formulering The request limit for the database is *N* and has been reached voor achterwaartse compatibiliteit. De limiet is in feite het aantal werknemers.
Als de maximale mate van parallelle uitvoering (MAXDOP) gelijk is aan nul of groter is dan één, kan het aantal werkrollen veel hoger zijn dan het aantal aanvragen en kan de limiet veel sneller worden bereikt dan wanneer MAXDOP gelijk is aan één.
- Meer informatie over fout 10928 in Fouten in resourcebeheer.
- Meer informatie over de uitputting van aanvragen in Fouten 10928 en 10936.
U kunt het benaderen of bereiken van werk- of sessielimieten beperken door:
- De servicelaag of rekenkracht van de database of elastische pool vergroten. Zie Resources voor één database schalen en Resources voor elastische pools schalen.
- Query's optimaliseren om het resourcegebruik te verminderen als de oorzaak van toegenomen werkrollen conflicten is voor rekenresources. Zie queryafstemming/hintingvoor meer informatie.
- Optimaliseer de queryworkload om het aantal exemplaren en de duur van het blokkeren van query's te verminderen. Zie Problemen met blokkeringen begrijpen en oplossenvoor meer informatie.
- Verminder indien nodig de MAXDOP--instelling.
Werkrol- en sessielimieten zoeken voor Azure SQL Database op servicelaag en rekenkracht:
- resourcelimieten voor individuele databases met behulp van het vCore-aankoopmodel
- Resourcelimieten voor elastische pools met behulp van het vCore-aankoopmodel
- Resourcelimieten voor individuele databases met behulp van het DTU-aankoopmodel
- Resourcelimieten voor elastische pools met behulp van het DTU-aankoopmodel
Meer informatie over het oplossen van specifieke fouten voor sessie- of werkrollimieten in Fouten in resourcebeheer.
Externe verbindingen
Het aantal gelijktijdige verbindingen met externe eindpunten dat via sp_invoke_external_rest_endpoint wordt uitgevoerd, wordt beperkt tot 10% werkrolthreads, met een vaste limiet van maximaal 150 werkrollen.
Geheugen
In tegenstelling tot andere resources (CPU, werkrollen, opslag), heeft het bereiken van de geheugenlimiet geen negatieve invloed op queryprestaties en veroorzaakt dit geen fouten en fouten. Zoals beschreven in architectuurhandleiding voor geheugenbeheer, maakt de database-engine vaak gebruik van alle beschikbare geheugen. Geheugen wordt voornamelijk gebruikt voor het opslaan van gegevens in de cache om tragere opslagtoegang te voorkomen. Daarom verbetert het hogere geheugengebruik de queryprestaties vanwege snellere leesbewerkingen uit het geheugen, in plaats van tragere leesbewerkingen uit de opslag.
Na het opstarten van de database-engine, terwijl de workload begint met het lezen van gegevens uit de opslag, slaat de database-engine gegevens in het geheugen agressief op in de cache. Na deze eerste oplopende periode is het gebruikelijk dat de kolommen avg_memory_usage_percent en avg_instance_memory_percent in sys.dm_db_resource_statsworden weergegeven, en de metrische gegevens van Azure Monitor sql_instance_memory_percent dicht bij 100%liggen, met name voor databases die niet inactief zijn en die niet volledig in het geheugen passen.
Notitie
De metrische sql_instance_memory_percent weerspiegelt het totale geheugenverbruik door de database-engine. Deze metrische waarde bereikt mogelijk niet 100% zelfs niet wanneer workloads met een hoge intensiteit worden uitgevoerd. Dit komt doordat een klein deel van het beschikbare geheugen is gereserveerd voor andere kritieke geheugentoewijzingen dan de gegevenscache, zoals threadstacks en uitvoerbare modules.
Naast de gegevenscache wordt geheugen gebruikt in andere onderdelen van de database-engine. Wanneer er behoefte is aan geheugen en al het beschikbare geheugen door de gegevenscache is gebruikt, vermindert de database-engine de grootte van de gegevenscache om geheugen beschikbaar te maken voor andere onderdelen en groeit de gegevenscache dynamisch wanneer andere onderdelen geheugen vrijlaten.
In zeldzame gevallen kan een voldoende veeleisende workload leiden tot een onvoldoende geheugenvoorwaarde, wat leidt tot onvoldoende geheugenfouten. Fouten met onvoldoende geheugen kunnen optreden op elk niveau van geheugengebruik tussen 0% en 100%. Onvoldoende geheugenfouten treden waarschijnlijk op bij kleinere rekenkracht die proportioneel kleinere geheugenlimieten hebben en/of met workloads die meer geheugen gebruiken voor queryverwerking, zoals in dichte elastische pools.
Als u fouten met onvoldoende geheugen krijgt, zijn de risicobeperkingsopties onder andere:
- Bekijk de details van de OOM-voorwaarde in sys.dm_os_out_of_memory_events.
- De servicelaag of rekenkracht van de database of elastische pool vergroten. Zie Resources voor één database schalen en Resources voor elastische pools schalen.
- Query's en configuratie optimaliseren om het geheugengebruik te verminderen. Algemene oplossingen worden beschreven in de volgende tabel.
| Oplossing | Beschrijving |
|---|---|
| De grootte van geheugentoelagen verkleinen | Zie de Inzicht in SQL Server-geheugen verleent blogbericht voor meer informatie over geheugentoelagen. Een veelvoorkomende oplossing om overmatig grote geheugentoelagen te voorkomen, is door statistieken up-to-date te houden. Dit resulteert in nauwkeurigere schattingen van het geheugenverbruik door de query-engine, waardoor grote geheugentoekenningen worden vermeden. Standaard kan de database-engine in databases met compatibiliteitsniveau 140 en hoger automatisch de grootte van de geheugentoe kennen aanpassen met behulp van Batch-modus geheugentoekoppeling. Op dezelfde manier gebruikt de database-engine in databases met compatibiliteitsniveau 150 en hoger ook geheugen voor rijmodus feedbackvoor meer algemene query's in de rijmodus. Deze ingebouwde functionaliteit helpt bij het voorkomen van geheugenfouten vanwege grote geheugentoelagen. |
| De grootte van de cache van het queryplan verkleinen | De database-engine slaat queryplannen in het geheugen op in de cache om te voorkomen dat er een queryplan wordt gemaakt voor elke uitvoering van de query. Om cache-bloat van queryplannen te voorkomen die worden veroorzaakt door cacheabonnementen die slechts eenmaal worden gebruikt, moet u geparameteriseerde query's gebruiken en overwegen OPTIMIZE_FOR_AD_HOC_WORKLOADS databaseconfiguratie-in te schakelen. |
| De grootte van het vergrendelingsgeheugen verkleinen | De database-engine gebruikt geheugen voor vergrendelingen. Vermijd, indien mogelijk, grote transacties die een groot aantal vergrendelingen kunnen verkrijgen en een hoog geheugenverbruik voor vergrendeling kunnen veroorzaken. |
Resourceverbruik door gebruikersworkloads en interne processen
Voor Azure SQL Database zijn rekenresources vereist voor het implementeren van kernservicefuncties zoals hoge beschikbaarheid en herstel na noodgevallen, back-up en herstel van databases, bewaking, Query Store, Automatisch afstemmen, enzovoort. Het systeem zet een beperkt deel van de totale resources voor deze interne processen opzij met behulp van mechanismen voor resourcebeheer, waardoor de rest van de resources beschikbaar is voor gebruikersworkloads. Op momenten dat interne processen geen rekenresources gebruiken, maakt het systeem deze beschikbaar voor gebruikersworkloads.
Het totale CPU- en geheugenverbruik door gebruikersworkloads en interne processen wordt gerapporteerd in de sys.dm_db_resource_stats- en sys.resource_stats weergaven, in avg_instance_cpu_percent en avg_instance_memory_percent kolommen. Deze gegevens worden ook gerapporteerd via de metrische gegevens van sql_instance_cpu_percent en sql_instance_memory_percent Azure Monitor voor individuele databases en elastische pools op poolniveau.
Notitie
De metrische gegevens van Azure Monitor sql_instance_cpu_percent en sql_instance_memory_percent zijn beschikbaar sinds juli 2023. Ze zijn volledig gelijk aan de eerder beschikbare sqlserver_process_core_percent en sqlserver_process_memory_percent metrische gegevens. De laatste twee metrische gegevens blijven beschikbaar, maar worden in de toekomst verwijderd. Gebruik de oudere metrische gegevens niet om onderbrekingen in databasebewaking te voorkomen.
Deze metrische gegevens zijn niet beschikbaar voor databases die gebruikmaken van de servicedoelstellingen Basic, S1 en S2. Dezelfde gegevens zijn beschikbaar in de volgende dynamische beheerweergaven.
CPU- en geheugenverbruik door gebruikersworkloads in elke database worden gerapporteerd in de sys.dm_db_resource_stats- en sys.resource_stats weergaven, in avg_cpu_percent en avg_memory_usage_percent kolommen. Voor elastische pools wordt resourceverbruik op poolniveau gerapporteerd in de sys.elastic_pool_resource_stats weergave (voor historische rapportagescenario's) en in sys.dm_elastic_pool_resource_stats voor realtime bewaking. Cpu-verbruik van gebruikersworkloads wordt ook gerapporteerd via de metrische gegevens van cpu_percent Azure Monitor voor individuele databases en elastische pools op poolniveau.
Een gedetailleerdere uitsplitsing van recent resourceverbruik door gebruikersworkloads en interne processen wordt gerapporteerd in de sys.dm_resource_governor_resource_pools_history_ex- en sys.dm_resource_governor_workload_groups_history_ex weergaven. Zie Resource governance-voor meer informatie over resourcegroepen en workloadgroepen waarnaar in deze weergaven wordt verwezen. Deze weergaven rapporteren over resourcegebruik door gebruikersworkloads en specifieke interne processen in de bijbehorende resourcegroepen en workloadgroepen.
Fooi
Bij het bewaken of oplossen van problemen met workloadprestaties is het belangrijk om rekening te houden met zowel cpu-verbruik van gebruikers als (avg_cpu_percent, cpu_percent) en totaal CPU-verbruik door gebruikersworkloads en interne processen (avg_instance_cpu_percent,sql_instance_cpu_percent). De prestaties kunnen merkbaar worden beïnvloed als van deze metrische gegevens zich in het bereik van 70-100% bevindt.
CPU-verbruik van gebruikers wordt gedefinieerd als een percentage voor de CPU-limiet van de gebruikersworkload in elke servicedoelstelling. Op dezelfde manier wordt totale CPU-verbruik gedefinieerd als het percentage voor de CPU-limiet voor alle workloads. Omdat de twee limieten verschillen, worden de gebruikers en het totale CPU-verbruik gemeten op verschillende schalen en zijn ze niet rechtstreeks vergelijkbaar met elkaar.
Als cpu-verbruik van gebruikers 100%bereikt, betekent dit dat de gebruikersworkload volledig gebruikmaakt van de CPU-capaciteit die beschikbaar is in de geselecteerde servicedoelstelling, zelfs als totale CPU-verbruik onder de 100%blijft.
Wanneer totale CPU-verbruik het bereik van 70-100% bereikt, is het mogelijk om de doorvoer van gebruikersworkloads af te vlakken en querylatentie te verhogen, zelfs als gebruikers-CPU-verbruik aanzienlijk lager blijft dan 100%. Dit is waarschijnlijker wanneer u kleinere servicedoelstellingen gebruikt met een gemiddelde toewijzing van rekenresources, maar relatief intensieve gebruikersworkloads, zoals in dichte elastische pools. Dit kan ook gebeuren met kleinere servicedoelstellingen wanneer voor interne processen tijdelijk meer resources nodig zijn, bijvoorbeeld bij het maken van een nieuwe replica van de database of het maken van een back-up van de database.
Wanneer cpu-verbruik van gebruikers het bereik van 70-100% bereikt, neemt de doorvoer van gebruikersworkloads en querylatentie toe, zelfs als totaal CPU-verbruik ruim onder de limiet ligt.
Wanneer het CPU-verbruik van gebruiker of totaal CPU-verbruik hoog is, zijn risicobeperkingsopties hetzelfde als in de sectie Reken-CPU- en omvatten het verhogen van servicedoelstelling en/of optimalisatie van gebruikersworkloads.
Notitie
Zelfs bij een volledig niet-actieve database of elastische pool is totale CPU-verbruik nooit nul is vanwege activiteiten van de database-engine op de achtergrond. Het kan variëren in een breed scala, afhankelijk van de specifieke achtergrondactiviteiten, rekenkracht en vorige gebruikersworkload.
Resourcebeheer
Voor het afdwingen van resourcelimieten maakt Azure SQL Database gebruik van een implementatie van resourcebeheer die is gebaseerd op SQL Server Resource Governor, gewijzigd en uitgebreid voor uitvoering in de cloud. In SQL Database bieden meerdere resourcegroepen en workloadgroepen, met resourcelimieten die zijn ingesteld op groep- en groepsniveau, een evenwichtige Database-as-a-Service-. Gebruikersworkloads en interne workloads worden geclassificeerd in afzonderlijke resourcegroepen en workloadgroepen. De werkbelasting van de gebruiker op de primaire en leesbare secundaire replica's, inclusief geo-replica's, wordt geclassificeerd in de SloSharedPool1 resourcegroep en UserPrimaryGroup.DBId[N] workloadgroepen, waarbij [N] staat voor de waarde van de database-id. Daarnaast zijn er meerdere resourcegroepen en workloadgroepen voor verschillende interne workloads.
Naast het gebruik van Resource Governor om resources binnen de database-engine te beheren, maakt Azure SQL Database ook gebruik van Windows Job Objects voor resourcebeheer op procesniveau en Windows Bestandsserverbronbeheer (FSRM) voor opslagquotabeheer.
Azure SQL Database-resourcebeheer is hiërarchisch van aard. Van boven naar beneden worden limieten afgedwongen op besturingssysteemniveau en op het niveau van het opslagvolume met behulp van mechanismen voor besturingssysteemresourcebeheer en Resource Governor, vervolgens op resourcegroepniveau met behulp van Resource Governor en vervolgens op het niveau van de workloadgroep met behulp van Resource Governor. Resourcebeheerlimieten die van kracht zijn voor de huidige database of elastische pool, worden gerapporteerd in de weergave sys.dm_user_db_resource_governance.
Gegevens-I/O-governance
Gegevens-I/O-beheer is een proces in Azure SQL Database dat wordt gebruikt om zowel lees- als schrijf-I/O te beperken voor gegevensbestanden van een database. IOPS-limieten worden ingesteld voor elk serviceniveau om het effect 'lawaaierige buren' te minimaliseren, om resourcetoewijzing eerlijk te maken in een multitenant-service en om binnen de mogelijkheden van de onderliggende hardware en opslag te blijven.
Voor individuele databases worden limieten voor workloadgroepen toegepast op alle opslag-I/O's voor de database. Voor elastische pools gelden limieten voor werkbelastinggroepen voor elke database in de pool. Daarnaast is de limiet voor de resourcegroep ook van toepassing op de cumulatieve I/O van de elastische pool. In tempdbis I/O onderworpen aan limieten voor werkbelastinggroepen, met uitzondering van de servicelaag Basic, Standard en Algemeen gebruik, waarbij hogere tempdb I/O-limieten van toepassing zijn. Over het algemeen kunnen resourcegroeplimieten mogelijk niet worden bereikt door de workload op basis van een database (één of gegroepeerd), omdat de limieten van de werkbelastinggroep lager zijn dan de limieten van de resourcegroep en de IOPS/doorvoer sneller beperken. Poollimieten kunnen echter worden bereikt door de gecombineerde workload ten opzichte van meerdere databases in dezelfde pool.
Als een query bijvoorbeeld 1000 IOPS genereert zonder I/O-resourcebeheer, maar de maximale IOPS-limiet voor de workloadgroep is ingesteld op 900 IOPS, kan de query niet meer dan 900 IOPS genereren. Als de maximale IOPS-limiet voor de resourcegroep echter is ingesteld op 1500 IOPS en de totale I/O van alle workloadgroepen die aan de resourcegroep zijn gekoppeld, hoger is dan 1500 IOPS, kan de I/O van dezelfde query worden verlaagd onder de werkgroeplimiet van 900 IOPS.
De IOPS- en doorvoerlimietwaarden die worden geretourneerd door de weergave sys.dm_user_db_resource_governance fungeren als limieten/limieten, niet als garanties. Bovendien garandeert resourcebeheer geen specifieke opslaglatentie. De best haalbare latentie, IOPS en doorvoer voor een bepaalde gebruikersworkload zijn niet alleen afhankelijk van I/O-resourcebeheerlimieten, maar ook van de combinatie van gebruikte I/O-grootten en de mogelijkheden van de onderliggende opslag. SQL Database maakt gebruik van I/O-bewerkingen die variëren in grootte tussen 512 bytes en 4 MB. Voor het afdwingen van IOPS-limieten wordt elke I/O verantwoordelijk, ongeacht de grootte, met uitzondering van databases met gegevensbestanden in Azure Storage. In dat geval worden IOS's die groter zijn dan 256 kB als meerdere I/Os van 256 kB opgegeven om te worden afgestemd op Azure Storage I/O-boekhouding.
Voor Basic-, Standard- en Algemeen gebruiksdatabases, die gebruikmaken van gegevensbestanden in Azure Storage, is de primary_group_max_io waarde mogelijk niet haalbaar als een database niet voldoende gegevensbestanden heeft om dit aantal IOPS cumulatief op te geven, of als gegevens niet gelijkmatig over bestanden worden gedistribueerd, of als de prestatielaag van onderliggende blobs IOPS/doorvoer onder de limieten voor resourcebeheer beperkt. Net als bij kleine logboek-I/O-bewerkingen die worden gegenereerd door frequente doorvoeringen van transacties, is de primary_max_log_rate waarde mogelijk niet mogelijk door een workload vanwege de IOPS-limiet voor de onderliggende Azure Storage-blob. Voor databases met Azure Premium Storage gebruikt Azure SQL Database voldoende grote opslagblobs om de benodigde IOPS/doorvoer te verkrijgen, ongeacht de grootte van de database. Voor grotere databases worden meerdere gegevensbestanden gemaakt om de totale IOPS-/doorvoercapaciteit te verhogen.
Waarden voor resourcegebruik, zoals avg_data_io_percent en avg_log_write_percent, die worden gerapporteerd in de sys.dm_db_resource_stats, sys.resource_stats, sys.dm_elastic_pool_resource_statsen sys.elastic_pool_resource_stats weergaven, worden berekend als percentages van maximale resourcebeheerlimieten. Daarom is het mogelijk om, wanneer andere factoren dan resourcebeheer IOPS/doorvoer beperken, IOPS/doorvoer afvlakken en latenties toenemen naarmate de workload toeneemt, ook al blijft het gerapporteerde resourcegebruik lager dan 100%.
Als u de IOPS, doorvoer en latentie per databasebestand wilt controleren, gebruikt u de sys.dm_io_virtual_file_stats()-functie. Met deze functie wordt alle I/O voor de database weergegeven, inclusief I/O op de achtergrond die niet is verantwoordelijk voor avg_data_io_percent, maar IOPS en doorvoer van de onderliggende opslag gebruikt en kan dit van invloed zijn op waargenomen opslaglatentie. De functie rapporteert aanvullende latentie die kan worden geïntroduceerd door I/O-resourcebeheer voor lees- en schrijfbewerkingen, respectievelijk in de io_stall_queued_read_ms en io_stall_queued_write_ms kolommen.
Beheer van transactielogboeksnelheid
Beheer van transactielogboeksnelheid is een proces in Azure SQL Database dat wordt gebruikt om hoge opnamesnelheden te beperken voor workloads zoals bulksgewijs invoegen, SELECT INTO en index builds. Deze limieten worden bijgehouden en afgedwongen op subsecondenniveau tot de snelheid van het genereren van logboekrecords, waardoor de doorvoer wordt beperkt, ongeacht het aantal IOS's dat kan worden uitgegeven voor gegevensbestanden. Het genereren van transactielogboeken wordt momenteel lineair geschaald tot een punt dat afhankelijk is van hardwareafhankelijke en servicelaagafhankelijk.
Logboeksnelheden worden zo ingesteld dat ze in verschillende scenario's kunnen worden bereikt en ondersteund, terwijl het algehele systeem de functionaliteit kan behouden met een geminimaliseerde impact op de gebruikersbelasting. Beheer van logboeksnelheid zorgt ervoor dat back-ups van transactielogboeken binnen gepubliceerde SLA's voor herstelmogelijkheden blijven. Deze governance voorkomt ook een overmatige achterstand op secundaire replica's die anders leiden tot langere dan verwachte downtime tijdens failovers.
De werkelijke fysieke IOs voor transactielogboekbestanden zijn niet beheerd of beperkt. Wanneer logboekrecords worden gegenereerd, wordt elke bewerking geëvalueerd en beoordeeld of deze moet worden vertraagd om een maximale gewenste logboeksnelheid (MB/s per seconde) te behouden. De vertragingen worden niet toegevoegd wanneer de logboekrecords worden leeggemaakt naar de opslag, maar beheer van logboeksnelheid wordt toegepast tijdens het genereren van logboeksnelheid zelf.
De werkelijke snelheid voor het genereren van logboeken tijdens runtime wordt ook beïnvloed door feedbackmechanismen, waardoor de toegestane logboeksnelheden tijdelijk worden verminderd, zodat het systeem zich kan stabiliseren. Beheer van de ruimte voor logboekbestanden, om te voorkomen dat er onvoldoende ruimte is voor logboeken en mechanismen voor gegevensreplicatie kunnen de algemene systeemlimieten tijdelijk verlagen.
Het vormgeven van verkeer van logboeksnelheid wordt weergegeven via de volgende wachttypen (weergegeven in de sys.dm_exec_requests en sys.dm_os_wait_stats weergaven):
| Wachttype | Notities |
|---|---|
LOG_RATE_GOVERNOR |
Databasebeperking |
POOL_LOG_RATE_GOVERNOR |
Groepsbeperking |
INSTANCE_LOG_RATE_GOVERNOR |
Limiet op exemplaarniveau |
HADR_THROTTLE_LOG_RATE_SEND_RECV_QUEUE_SIZE |
Feedbackbeheer, fysieke replicatie van beschikbaarheidsgroepen in Premium/Bedrijfskritiek blijven niet bij |
HADR_THROTTLE_LOG_RATE_LOG_SIZE |
Besturingselement voor feedback, beperkingspercentages om te voorkomen dat er geen ruimte meer is voor logboeken |
HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO |
Feedbackbeheer voor geo-replicatie, het beperken van de logboeksnelheid om hoge gegevenslatentie en onbeschikbaarheid van geo-secundaire bestanden te voorkomen |
Houd rekening met de volgende opties bij het tegenkomen van een logboeksnelheidslimiet die de gewenste schaalbaarheid belemmert:
- Schaal omhoog naar een hoger serviceniveau om de maximale logboeksnelheid van een servicelaag te verkrijgen of over te schakelen naar een andere servicelaag.
- Voor geoptimaliseerde hardware uit de Premium-serie en premium-serie biedt de ingerichte Hyperscale-servicelaag 150 MiB/s-logboeksnelheid per database en 150 MiB/s per elastische pool.
- Voor andere hardwarereeksen biedt de Hyperscale-servicelaag 100 MiB/s-logboeksnelheid per database en 125 MiB/s per elastische pool.
- Als gegevens die worden geladen tijdelijk zijn, zoals faseringsgegevens in een ETL-proces, kunnen deze worden geladen in
tempdb(die minimaal zijn vastgelegd). - Voor analysescenario's laadt u in een gegroepeerde columnstore tabel of een tabel met indexen die gebruikmaken van gegevenscompressie. Dit vermindert de vereiste logboeksnelheid. Deze techniek verhoogt het CPU-gebruik en is alleen van toepassing op gegevenssets die profiteren van geclusterde columnstore-indexen of gegevenscompressie.
Governance van opslagruimte
In premium- en bedrijfskritieke servicelagen worden klantgegevens, inclusief gegevensbestanden, transactielogboekbestanden en tempdb-bestanden, opgeslagen op de lokale SSD-opslag van de computer die als host fungeert voor de database of elastische pool. Lokale SSD-opslag biedt hoge IOPS en doorvoer en lage I/O-latentie. Naast klantgegevens wordt lokale opslag gebruikt voor het besturingssysteem, beheersoftware, bewakingsgegevens en logboeken en andere bestanden die nodig zijn voor systeembewerking.
De grootte van lokale opslag is eindig en is afhankelijk van de hardwaremogelijkheden, die bepalen welke maximale lokale opslag limiet, of lokale opslag die is gereserveerd voor klantgegevens. Deze limiet is ingesteld om de opslag van klantgegevens te maximaliseren, terwijl veilige en betrouwbare systeembewerkingen worden gegarandeerd. Zie de documentatie voor resourcelimieten voor individuele databases en elastische poolsvoor de maximale lokale opslag voor elke servicedoelstelling.
U kunt deze waarde ook vinden en de hoeveelheid lokale opslag die momenteel wordt gebruikt door een bepaalde database of elastische pool, met behulp van de volgende query:
SELECT server_name, database_name, slo_name, user_data_directory_space_quota_mb, user_data_directory_space_usage_mb
FROM sys.dm_user_db_resource_governance
WHERE database_id = DB_ID();
| Kolom | Beschrijving |
|---|---|
server_name |
Naam van logische server |
database_name |
Databasenaam |
slo_name |
Naam van servicedoelstelling, inclusief hardwaregeneratie |
user_data_directory_space_quota_mb |
Maximale lokale opslag, in MB |
user_data_directory_space_usage_mb |
Huidig lokaal opslagverbruik door gegevensbestanden, transactielogboekbestanden en tempdb-bestanden, in MB. Elke vijf minuten bijgewerkt. |
Deze query moet worden uitgevoerd in de gebruikersdatabase, niet in de master-database. Voor elastische pools kan de query worden uitgevoerd in elke database in de pool. Gerapporteerde waarden zijn van toepassing op de hele pool.
Belangrijk
Als de werkbelasting in premium- en bedrijfskritieke servicelagen probeert het gecombineerde lokale opslagverbruik te verhogen door gegevensbestanden, transactielogboekbestanden en tempdb bestanden boven de maximale lokale opslaglimiet limiet, treedt er een fout met onvoldoende ruimte op. Dit gebeurt zelfs als de gebruikte ruimte in een databasebestand de maximale grootte van het bestand niet heeft bereikt.
Lokale SSD-opslag wordt ook gebruikt door databases in andere servicelagen dan Premium en Bedrijfskritiek voor de tempdb-database en Hyperscale RBPEX-cache. Naarmate databases worden gemaakt, verwijderd en groter of kleiner worden, fluctueert het totale lokale opslagverbruik op een machine in de loop van de tijd. Als het systeem detecteert dat de beschikbare lokale opslag op een computer laag is en een database of elastische pool geen ruimte meer heeft, verplaatst het de database of elastische pool naar een andere computer met voldoende lokale opslag.
Deze verplaatsing vindt plaats op een online manier, vergelijkbaar met een schaalbewerking voor databases en heeft een vergelijkbaar impact, inclusief een korte (seconden) failover aan het einde van de bewerking. Met deze failover worden geopende verbindingen beëindigd en worden transacties teruggedraaid die mogelijk van invloed zijn op toepassingen die de database op dat moment gebruiken.
Omdat alle gegevens worden gekopieerd naar lokale opslagvolumes op verschillende computers, kan het verplaatsen van grotere databases in premium- en bedrijfskritieke servicelagen een aanzienlijke hoeveelheid tijd vergen. Wanneer het verbruik van lokale ruimte door een database of elastische pool of door de tempdb database in die periode snel toeneemt, neemt het risico op onvoldoende ruimte toe. Het systeem initieert databaseverplaatsing op een evenwichtige manier om out-of-space-fouten te minimaliseren en onnodige failovers te voorkomen.
tempdb grootte
De groottelimieten voor tempdb in Azure SQL Database zijn afhankelijk van het aankoop- en implementatiemodel.
Raadpleeg tempdb groottelimieten voor meer informatie voor:
- vCore-aankoopmodel: individuele databases, gegroepeerde databases
- DTU-aankoopmodel: individuele databases, gegroepeerde databases.
Eerder beschikbare hardware
Deze sectie bevat details over eerder beschikbare hardware.
- Gen4-hardware is buiten gebruik gesteld en is niet beschikbaar voor inrichting, schaalaanpassing of omlaag schalen. Migreer uw database naar een ondersteunde hardwaregeneratie voor een breder scala aan schaalbaarheid van vCore en opslag, versneld netwerken, de beste I/O-prestaties en minimale latentie. Zie Ondersteuning is beëindigd voor Gen 4-hardware op Azure SQL Databasevoor meer informatie.
U kunt Azure Resource Graph Explorer gebruiken om alle Azure SQL Database-resources te identificeren die momenteel gebruikmaken van Gen4-hardware, of u kunt de hardware controleren die door resources wordt gebruikt voor een specifieke logische server in Azure Portal.
U moet ten minste read machtigingen hebben voor het Azure-object of de objectgroep om resultaten te kunnen zien in Azure Resource Graph Explorer.
Als u Resource Graph Explorer- wilt gebruiken om Azure SQL-resources te identificeren die nog steeds gebruikmaken van Gen4-hardware, voert u de volgende stappen uit:
Ga naar de Azure Portal.
Zoek
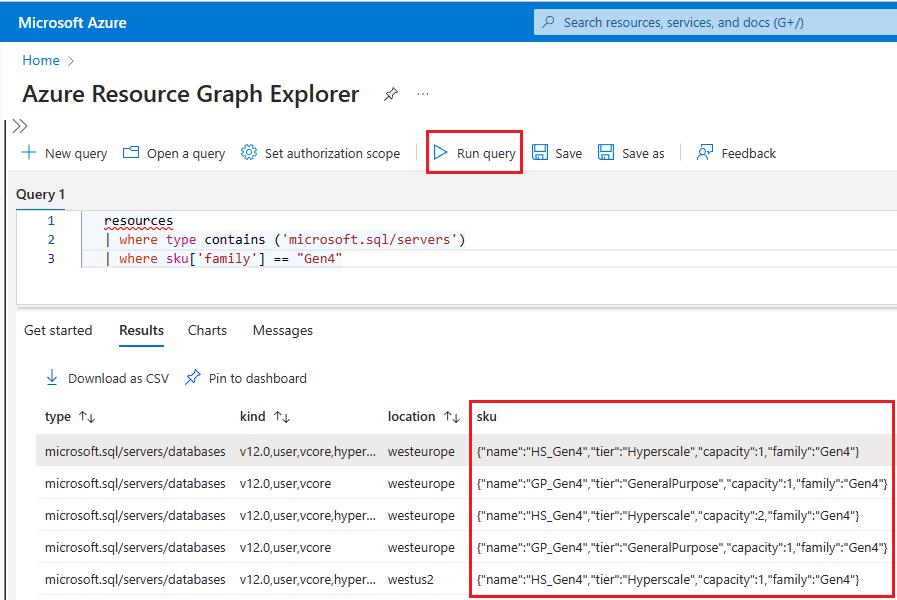
Resource graphin het zoekvak en kies de Resource Graph Explorer--service in de zoekresultaten.Typ in het queryvenster de volgende query en selecteer Query uitvoeren:
resources | where type contains ('microsoft.sql/servers') | where sku['family'] == "Gen4"In het deelvenster Resultaten worden alle momenteel geïmplementeerde resources in Azure weergegeven die gebruikmaken van Gen4-hardware.
Voer de volgende stappen uit om de hardware te controleren die wordt gebruikt door resources voor een specifieke logische server in Azure:
- Ga naar de Azure Portal.
- Zoek
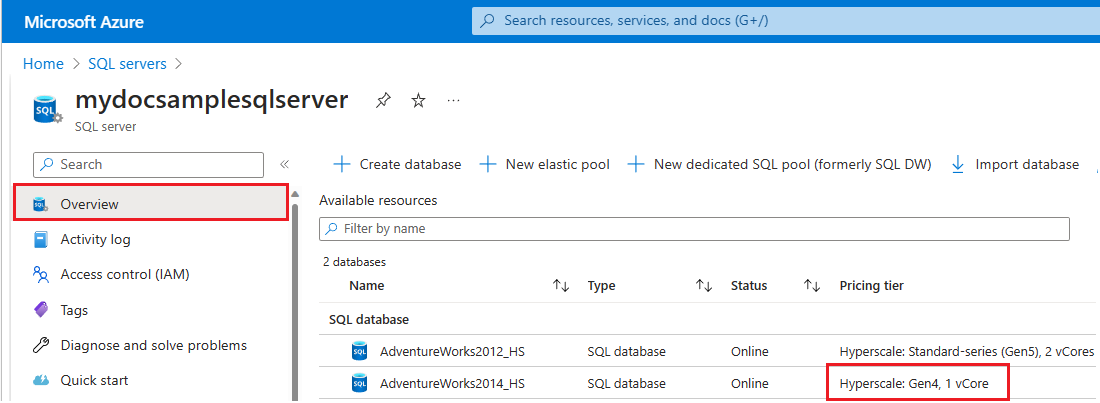
SQL serversin het zoekvak en kies SQL-servers in de zoekresultaten om de SQL-servers pagina te openen en alle servers voor de gekozen abonnementen weer te geven. - Selecteer de gewenste server om de pagina Overzicht voor de server te openen.
- Schuif omlaag naar de beschikbare resources en controleer de prijscategorie kolom voor resources die gebruikmaken van gen4-hardware.
Raadpleeg Hardwarewijzigen om resources te migreren naar hardware uit de standard-serie.
Verwante inhoud
- Zie Azure-abonnements- en servicelimieten, quota en beperkingenvoor meer informatie over algemene Azure-limieten.
- Zie DTU's en eDTU'svoor informatie over DTU's en eDTU's.
- Zie voor meer informatie over
tempdbgroottelimieten enkele vCore-databases, gegroepeerde vCore-databases, individuele DTU-databasesen gegroepeerde DTU-databases.