Aankoopmodel voor vCore - Azure SQL Database
Van toepassing op:![]() Azure SQL Database
Azure SQL Database
In dit artikel wordt het vCore-aankoopmodel voor Azure SQL Database beoordeeld.
Overzicht
Een virtuele kern (vCore) vertegenwoordigt een logische CPU en biedt u de mogelijkheid om de fysieke kenmerken van de hardware te kiezen (bijvoorbeeld het aantal kernen, het geheugen en de opslaggrootte). Het aankoopmodel op basis van vCore biedt u flexibiliteit, controle, transparantie van het individuele resourceverbruik en een eenvoudige manier om on-premises workloadvereisten te vertalen naar de cloud. Dit model optimaliseert de prijs en stelt u in staat om reken-, geheugen- en opslagresources te kiezen op basis van uw workloadbehoeften.
In het aankoopmodel op basis van vCore zijn uw kosten afhankelijk van de keuze en het gebruik van:
- Servicelaag
- Hardwareconfiguratie
- Rekenresources (het aantal vCores en de hoeveelheid geheugen)
- Gereserveerde databaseopslag
- Werkelijke back-upopslag
Belangrijk
Rekenresources, I/O en gegevens- en logboekopslag worden in rekening gebracht per database of elastische pool. Er worden kosten in rekening gebracht voor back-upopslag per database. Zie de pagina met prijzen voor Azure SQL Database voor meer informatie.
VCore- en DTU-aankoopmodellen vergelijken
Het vCore-aankoopmodel dat wordt gebruikt door Azure SQL Database biedt verschillende voordelen ten opzichte van het aankoopmodel op basis van DTU:
- Hogere reken-, geheugen-, I/O- en opslaglimieten.
- De keuze van de hardwareconfiguratie om beter overeen te komen met de reken- en geheugenvereisten van de workload.
- Prijskortingen voor Azure Hybrid Benefit (AHB).
- Grotere transparantie in de hardwaredetails die de rekenkracht inschakelen, waardoor het plannen van migraties vanuit on-premises implementaties wordt vergemakkelijkt.
- Prijzen voor gereserveerde instanties zijn alleen beschikbaar voor het vCore-aankoopmodel.
- Hogere schaalgranulariteit met meerdere rekengrootten beschikbaar.
Compute
Het aankoopmodel op basis van vCore heeft een ingerichte rekenlaag en een serverloze rekenlaag. In de ingerichte rekenlaag weerspiegelen de rekenkosten de totale rekencapaciteit die continu is ingericht voor de toepassing, onafhankelijk van de workloadactiviteit. Kies de resourcetoewijzing die het beste past bij uw bedrijfsbehoeften op basis van vCore- en geheugenvereisten en schaal resources vervolgens omhoog en omlaag, indien nodig door uw workload. In de serverloze rekenlaag voor Azure SQL Database worden rekenresources automatisch geschaald op basis van de workloadcapaciteit en gefactureerd voor de hoeveelheid gebruikte rekenkracht per seconde.
Samenvatting:
- Hoewel de ingerichte rekenlaag een specifieke hoeveelheid rekenresources biedt die continu worden ingericht, onafhankelijk van de workloadactiviteit, schaalt de serverloze rekenlaag automatisch rekenresources op basis van workloadactiviteit.
- Terwijl de ingerichte rekenlaag wordt gefactureerd voor het aantal rekenkracht dat is ingericht tegen een vaste prijs per uur, worden de serverloze rekenlagen gefactureerd voor het gebruikte rekenproces, per seconde.
Ongeacht de rekenlaag worden drie extra secundaire replica's met hoge beschikbaarheid automatisch toegewezen in de servicelaag Bedrijfskritiek om een hoge tolerantie te bieden voor storingen en snelle failovers. Deze extra replica's maken de kosten ongeveer 2,7 keer hoger dan in de servicelaag Algemeen gebruik. Op dezelfde manier weerspiegelen de hogere opslagkosten per GB in de servicelaag Bedrijfskritiek de hogere I/O-limieten en lagere latentie van de lokale SSD-opslag.
In Hyperscale bepalen klanten het aantal extra replica's met hoge beschikbaarheid van 0 tot 4 om het tolerantieniveau te verkrijgen dat hun toepassingen nodig hebben en tegelijkertijd de kosten te beheersen.
Zie Rekenresources (CPU en geheugen) voor meer informatie over berekeningen in Azure SQL Database.
Bronlimieten
Voor vCore-resourcelimieten controleert u de beschikbare hardwareconfiguraties en controleert u vervolgens de resourcelimieten voor:
Gegevens- en logboekopslag
De volgende factoren zijn van invloed op de hoeveelheid opslagruimte die wordt gebruikt voor gegevens- en logboekbestanden, en zijn van toepassing op de lagen Algemeen gebruik en Bedrijfskritiek.
- Elke rekenkracht ondersteunt een configureerbare maximale gegevensgrootte, met een standaardwaarde van 32 GB.
- Wanneer u de maximale gegevensgrootte configureert, wordt automatisch een extra 30 procent van de factureerbare opslag toegevoegd voor het logboekbestand.
- In de servicelaag
tempdbAlgemeen gebruik maakt u gebruik van lokale SSD-opslag en zijn deze opslagkosten inbegrepen in de vCore-prijs. - In de servicelaag Bedrijfskritiek deelt
tempdbu lokale SSD-opslag met gegevens- en logboekbestanden, entempdbde opslagkosten zijn inbegrepen in de vCore-prijs. - In de lagen Algemeen gebruik en Bedrijfskritiek worden kosten in rekening gebracht voor de maximale opslaggrootte die is geconfigureerd voor een database of elastische pool.
- Voor SQL Database kunt u elke maximale gegevensgrootte tussen 1 GB en de ondersteunde opslaggrootte selecteren in stappen van 1 GB.
De volgende opslagoverwegingen zijn van toepassing op Hyperscale:
- De maximale grootte van gegevensopslag is ingesteld op 100 TB en kan niet worden geconfigureerd.
- Er worden alleen kosten in rekening gebracht voor de toegewezen gegevensopslag, niet voor maximale gegevensopslag.
- Er worden geen kosten in rekening gebracht voor logboekopslag.
tempdbmaakt gebruik van lokale SSD-opslag en de kosten zijn inbegrepen in de vCore-prijs. Als u de huidige toegewezen en gebruikte gegevensopslaggrootte in SQL Database wilt bewaken, gebruikt u respectievelijk de metrische gegevens van allocated_data_storage en opslag van Azure Monitor.
Als u de huidige toegewezen en gebruikte opslaggrootte van afzonderlijke gegevens en logboekbestanden in een database wilt bewaken met behulp van T-SQL, gebruikt u de sys.database_files-weergave en de functie FILEPROPERTY(... , 'SpaceUsed').
Tip
In sommige gevallen moet u een database mogelijk verkleinen om ongebruikte ruimte vrij te maken. Zie Bestandsruimte beheren in Azure SQL Database voor meer informatie.
Back-upopslag
Opslag voor databaseback-ups wordt toegewezen ter ondersteuning van de mogelijkheden voor herstel naar een bepaald tijdstip (PITR) en langetermijnretentie (LTR) van SQL Database. Deze opslag is gescheiden van de opslag van gegevens- en logboekbestanden en wordt afzonderlijk gefactureerd.
- PITR: In de lagen Algemeen gebruik en Bedrijfskritiek worden afzonderlijke databaseback-ups automatisch gekopieerd naar Azure Storage. De opslaggrootte neemt dynamisch toe naarmate er nieuwe back-ups worden gemaakt. De opslag wordt gebruikt door volledige, differentiële en back-ups van transactielogboeken. Het opslagverbruik is afhankelijk van de snelheid van wijziging van de database en de bewaarperiode die is geconfigureerd voor back-ups. U kunt een afzonderlijke bewaarperiode configureren voor elke database tussen 1 en 35 dagen voor SQL Database. Er wordt geen extra kosten in rekening gebracht voor de hoeveelheid back-upopslag die gelijk is aan de geconfigureerde maximale gegevensgrootte.
- LTR: U kunt ook langetermijnretentie van volledige back-ups tot 10 jaar configureren. Als u een LTR-beleid instelt, worden deze back-ups automatisch opgeslagen in Azure Blob Storage, maar kunt u bepalen hoe vaak de back-ups worden gekopieerd. Als u aan verschillende nalevingsvereisten wilt voldoen, kunt u verschillende bewaarperioden selecteren voor wekelijkse, maandelijkse en/of jaarlijkse back-ups. De configuratie die u kiest, bepaalt hoeveel opslagruimte wordt gebruikt voor LTR-back-ups. Zie Langetermijnretentie van back-ups voor meer informatie.
Zie Automatische back-ups voor Hyperscale-databases voor back-upopslag in Hyperscale.
Servicelagen
Opties voor servicelagen in het vCore-aankoopmodel omvatten Algemeen gebruik, Bedrijfskritiek en Hyperscale. De servicelaag bepaalt over het algemeen het opslagtype en de prestaties, opties voor hoge beschikbaarheid en herstel na noodgevallen en de beschikbaarheid van bepaalde functies, zoals OLTP in het geheugen.
| Gebruiksscenario | Algemeen doel | Bedrijfskritiek | Hyperscale |
|---|---|---|---|
| Het beste voor | De meeste zakelijke workloads. Biedt budgetgerichte, gebalanceerde en schaalbare reken- en opslagopties. | Biedt zakelijke toepassingen de hoogste tolerantie voor storingen met behulp van verschillende secundaire replica's met hoge beschikbaarheid en biedt de hoogste I/O-prestaties. | De meest uiteenlopende workloads, waaronder die workloads met zeer schaalbare opslag- en leesschaalvereisten. Biedt een hogere tolerantie voor storingen door configuratie van meer dan één secundaire replica met hoge beschikbaarheid toe te staan. |
| Rekenkracht | 2 tot 128 vCores | 2 tot 128 vCores | 2 tot 128 vCores |
| Opslagtype | Premium externe opslag (per exemplaar) | Super snelle lokale SSD-opslag (per exemplaar) | Losgekoppelde opslag met lokale SSD-cache (per rekenreplica) |
| Opslaggrootte | 1 GB – 4 TB | 1 GB – 4 TB | 10 GB – 100 TB |
| IOPS | 320 IOPS per vCore met maximaal 16.000 IOPS | 4.000 IOPS per vCore met maximaal 327.680 IOPS | 327.680 IOPS met maximale lokale SSD Hyperscale is een architectuur met meerdere lagen met caching op meerdere niveaus. Effectieve IOPS is afhankelijk van de workload. |
| Geheugen/vCore | 5,1 GB | 5,1 GB | 5,1 GB of 10,2 GB |
| Back-ups | Een keuze uit geografisch redundante, zone-redundante of lokaal redundante back-upopslag, retentie van 1-35 dagen (standaard 7 dagen) Langetermijnretentie beschikbaar tot 10 jaar |
Een keuze uit geografisch redundante, zone-redundante of lokaal redundante back-upopslag, retentie van 1-35 dagen (standaard 7 dagen) Langetermijnretentie beschikbaar tot 10 jaar |
Een keuze uit lokaal redundante opslag (LRS), zone-redundant (ZRS) of geografisch redundante opslag (GRS) Retentie van 1-35 dagen (standaard 7 dagen), met maximaal 10 jaar langetermijnretentie beschikbaar |
| Beschikbaarheid | Eén replica, geen replica's op leesschaal, zone-redundante hoge beschikbaarheid (HA) |
Drie replica's, één replica met leesschaal, zone-redundante hoge beschikbaarheid (HA) |
zone-redundante hoge beschikbaarheid (HA) |
| Prijzen/facturering | Er worden kosten in rekening gebracht voor vCore, gereserveerde opslag en back-upopslag . IOPS worden niet in rekening gebracht. |
Er worden kosten in rekening gebracht voor vCore, gereserveerde opslag en back-upopslag . IOPS worden niet in rekening gebracht. |
vCore voor elke replica en gebruikte opslag worden in rekening gebracht. IOPS worden niet in rekening gebracht. |
| Kortingsmodellen | Gereserveerde exemplaren Azure Hybrid Benefit (niet beschikbaar voor dev/test-abonnementen) Enterprise - en Pay-As-You-Go Dev/Test-abonnementen |
Gereserveerde exemplaren Azure Hybrid Benefit (niet beschikbaar voor dev/test-abonnementen) Enterprise - en Pay-As-You-Go Dev/Test-abonnementen |
Azure Hybrid Benefit (niet beschikbaar voor dev/test-abonnementen) 1 Enterprise - en Pay-As-You-Go Dev/Test-abonnementen |
1 Vereenvoudigde prijzen voor SQL Database Hyperscale binnenkort beschikbaar. Raadpleeg de blog over prijzen van Hyperscale voor meer informatie.
Raadpleeg de resourcelimieten voor logische server, individuele databases en pooldatabases voor meer informatie.
Algemeen gebruik
Het architectuurmodel voor de servicelaag Algemeen gebruik is gebaseerd op een scheiding van rekenkracht en opslag. Dit architectuurmodel is afhankelijk van de hoge beschikbaarheid en betrouwbaarheid van Azure Blob-opslag die op transparante wijze databasebestanden repliceert en garandeert geen gegevensverlies als de onderliggende infrastructuur mislukt.
In de volgende afbeelding ziet u vier knooppunten in het standaardarchitectuurmodel met de gescheiden reken- en opslaglagen.
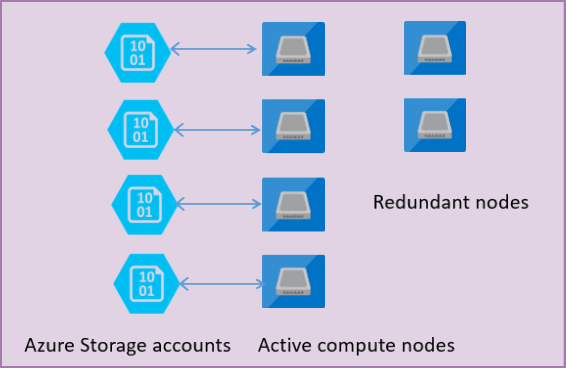
In het architectuurmodel voor de servicelaag Algemeen gebruik zijn er twee lagen:
- Een staatloze rekenlaag die het
sqlservr.exeproces uitvoert en alleen tijdelijke en in de cache opgeslagen gegevens bevat (bijvoorbeeld plancache, buffergroep, kolomopslaggroep). Dit staatloze knooppunt wordt beheerd door Azure Service Fabric waarmee het proces wordt geïnitialiseerd, de status van het knooppunt wordt beheerd en indien nodig een failover naar een andere locatie wordt uitgevoerd. - Een stateful gegevenslaag met databasebestanden (.mdf/.ldf) die zijn opgeslagen in Azure Blob Storage. Azure Blob Storage garandeert dat er geen gegevens verloren gaan van records die in een databasebestand worden geplaatst. Azure Storage heeft ingebouwde beschikbaarheid/redundantie van gegevens die ervoor zorgen dat elke record in het logboekbestand of elke pagina in het gegevensbestand behouden blijft, zelfs als het proces vastloopt.
Wanneer de database-engine of het besturingssysteem wordt bijgewerkt, mislukt een deel van de onderliggende infrastructuur of als er een kritiek probleem in het sqlservr.exe proces wordt gedetecteerd, verplaatst Azure Service Fabric het staatloze proces naar een ander staatloos rekenknooppunt. Er is een set reserveknooppunten die wachten om een nieuwe rekenservice uit te voeren als er een failover van het primaire knooppunt plaatsvindt om de failovertijd te minimaliseren. Gegevens in de Azure-opslaglaag worden niet beïnvloed en gegevens/logboekbestanden worden gekoppeld aan het zojuist geïnitialiseerde proces. Dit proces garandeert standaard een beschikbaarheid van 99,99% en een beschikbaarheid van 99,995% wanneer zoneredundantie is ingeschakeld. Er kunnen enkele prestatie-gevolgen zijn voor zware workloads die in de vlucht zijn vanwege de overgangstijd en het feit dat het nieuwe knooppunt begint met koude cache.
Wanneer u deze servicelaag kiest
De servicelaag Algemeen gebruik is de standaardservicelaag in Azure SQL Database die is ontworpen voor de meeste algemene workloads. Als u een volledig beheerde database-engine nodig hebt met een standaard-SLA en opslaglatentie tussen 5 ms en 10 ms, is de laag Algemeen gebruik de optie voor u.
Bedrijfskritiek
Het Bedrijfskritiek servicelaagmodel is gebaseerd op een cluster van database-engineprocessen. Dit architectuurmodel is afhankelijk van een quorum van database-engineknooppunten om de prestaties van uw workload te minimaliseren, zelfs tijdens onderhoudsactiviteiten. Upgrades en patches van het onderliggende besturingssysteem, stuurprogramma's en de database-engine vinden transparant plaats, met minimale uitlooptijd voor eindgebruikers.
In het Bedrijfskritiek model worden rekenkracht en opslag op elk knooppunt geïntegreerd. Replicatie van gegevens tussen database-engineprocessen op elk knooppunt van een cluster met vier knooppunten bereikt hoge beschikbaarheid, waarbij elk knooppunt lokaal gekoppelde SSD gebruikt als gegevensopslag. In het volgende diagram ziet u hoe de servicelaag Bedrijfskritiek een cluster met database-engineknooppunten in replica's van beschikbaarheidsgroepen ordent.
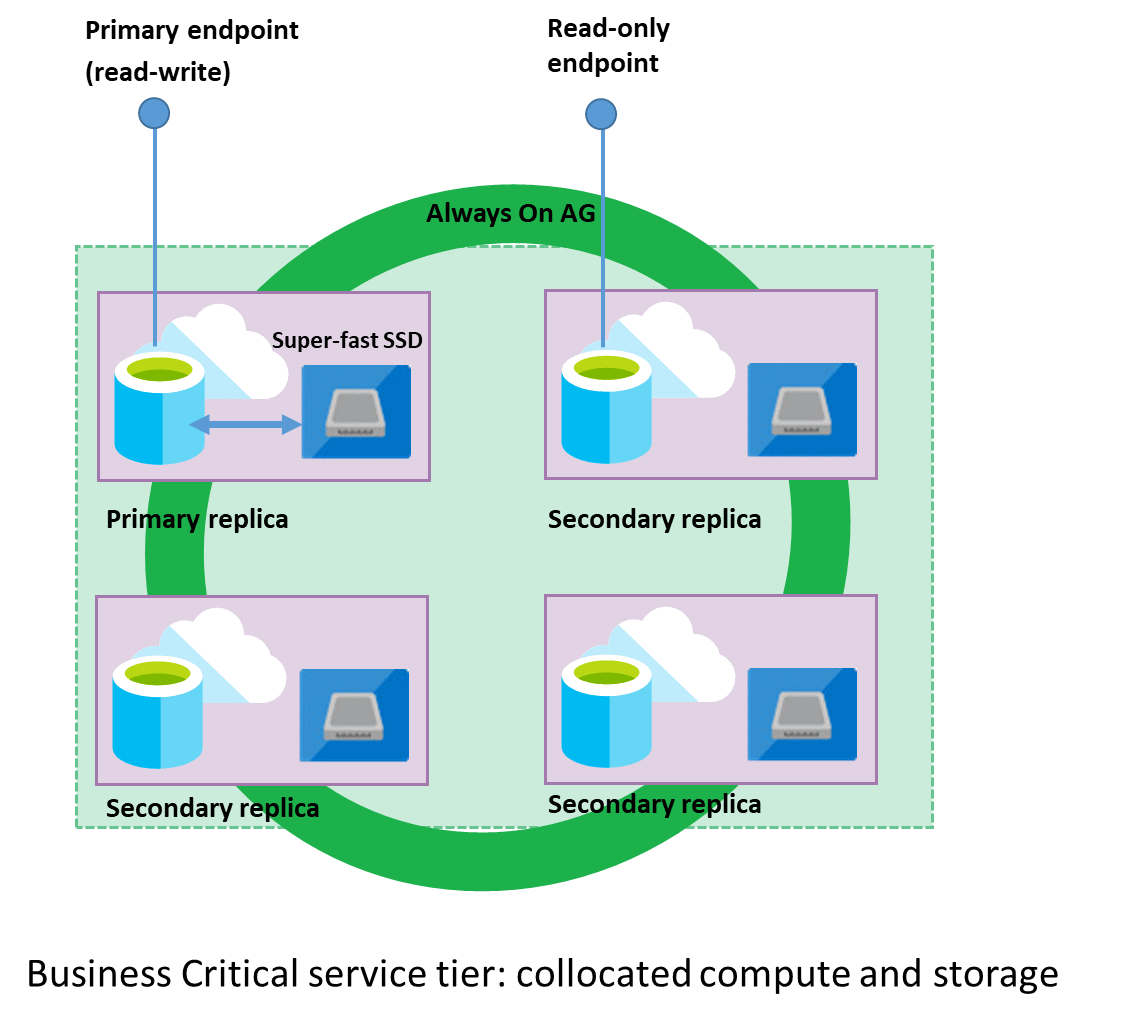
Zowel het database-engineproces als de onderliggende .mdf/.ldf-bestanden worden op hetzelfde knooppunt geplaatst met lokaal gekoppelde SSD-opslag, waardoor uw workload een lage latentie biedt. Hoge beschikbaarheid wordt geïmplementeerd met behulp van technologie die vergelijkbaar is met SQL Server AlwaysOn-beschikbaarheidsgroepen. Elke database is een cluster van databaseknooppunten met één primaire replica die toegankelijk is voor workloads van klanten en drie secundaire replica's die kopieën van gegevens bevatten. De primaire replica pusht voortdurend wijzigingen naar de secundaire replica's om ervoor te zorgen dat de gegevens beschikbaar zijn op secundaire replica's als de primaire om welke reden dan ook mislukt. Failover wordt verwerkt door de Service Fabric en de database-engine: één secundaire replica wordt de primaire en er wordt een nieuwe secundaire replica gemaakt om ervoor te zorgen dat er voldoende knooppunten in het cluster zijn. De workload wordt automatisch omgeleid naar de nieuwe primaire replica.
Bovendien heeft het Bedrijfskritiek-cluster een ingebouwde uitschaalfunctie voor lezen die een gratis alleen-lezenreplica biedt die wordt gebruikt voor het uitvoeren van alleen-lezenquery's (zoals rapporten) die geen invloed hebben op de prestaties van de werkbelasting op uw primaire replica.
Wanneer u deze servicelaag kiest
De Bedrijfskritiek-servicelaag is ontworpen voor toepassingen waarvoor reacties met lage latentie van de onderliggende SSD-opslag (gemiddeld 1-2 ms) nodig zijn, sneller herstel als de onderliggende infrastructuur uitvalt of rapporten, analyses en alleen-lezen query's naar de gratis leesbare secundaire replica van de primaire database moet worden uitgeschakeld.
De belangrijkste redenen waarom u Bedrijfskritiek servicelaag moet kiezen in plaats van de laag Algemeen gebruik, zijn:
- Lage I/O-latentievereisten: workloads die een consistent snelle reactie van de opslaglaag (gemiddeld 1-2 milliseconden) nodig hebben, moeten Bedrijfskritiek laag gebruiken.
- Workload met rapportage- en analysequery's waarbij één gratis secundaire replica met alleen-lezen voldoende is.
- Hogere tolerantie en sneller herstel na fouten. Als er een systeemfout optreedt, wordt de database op het primaire exemplaar uitgeschakeld en wordt een van de secundaire replica's onmiddellijk de nieuwe primaire database voor lezen/schrijven, klaar om query's te verwerken.
- Geavanceerde bescherming tegen beschadiging van gegevens. Omdat de Bedrijfskritiek-laag achter de schermen databasesreplica's gebruikt, gebruikt de service automatische paginaherstel die beschikbaar is met spiegeling en beschikbaarheidsgroepen om beschadiging van gegevens te helpen beperken. Als een replica een pagina niet kan lezen vanwege een probleem met gegevensintegriteit, wordt een nieuwe kopie van de pagina opgehaald uit een andere replica, waardoor de onleesbare pagina wordt vervangen zonder gegevensverlies of uitvaltijd van de klant. Deze functionaliteit is beschikbaar in de laag Algemeen gebruik als de database een geo-secundaire replica heeft.
- Hogere beschikbaarheid: de Bedrijfskritiek-laag in een configuratie met meerdere beschikbaarheidszones biedt tolerantie voor zonefouten en een SLA met een hogere beschikbaarheid.
- Snel geo-herstel: wanneer actieve geo-replicatie is geconfigureerd, heeft de Bedrijfskritiek-laag een gegarandeerdE RPO (Recovery Point Objective) van 5 seconden en RTO (Recovery Time Objective) van 30 seconden gedurende 100% van de geïmplementeerde uren.
Hyperscale
De Hyperscale-servicelaag is geschikt voor alle workloadtypen. De systeemeigen cloudarchitectuur biedt onafhankelijk schaalbare berekeningen en opslag ter ondersteuning van de breedste verscheidenheid aan traditionele en moderne toepassingen. Reken- en opslagresources in Hyperscale overschrijden aanzienlijk de resources die beschikbaar zijn in de lagen Algemeen gebruik en Bedrijfskritiek.
Raadpleeg de Hyperscale-servicelaag voor Azure SQL Database voor meer informatie.
Wanneer u deze servicelaag kiest
De Hyperscale-servicelaag verwijdert veel van de praktische limieten die traditioneel worden gezien in clouddatabases. Wanneer de meeste andere databases worden beperkt door de resources die beschikbaar zijn in één knooppunt, hebben databases in de Hyperscale-servicelaag dergelijke limieten niet. Met de flexibele opslagarchitectuur groeit een Hyperscale-database naar behoefte. U wordt alleen gefactureerd voor de opslagcapaciteit die u gebruikt.
Naast de geavanceerde schaalmogelijkheden is Hyperscale een uitstekende optie voor elke workload, niet alleen voor grote databases. Met Hyperscale kunt u het volgende doen:
- Bereik hoge tolerantie en snel herstel van fouten tijdens het beheren van de kosten door het aantal replica's met hoge beschikbaarheid van 0 tot en met 4 te kiezen.
- Verbeter hoge beschikbaarheid door zoneredundantie in te schakelen voor rekenkracht en opslag.
- Bereik een lage I/O-latentie (gemiddeld 1-2 milliseconden) voor het vaak gebruikte deel van uw database. Voor kleinere databases kan dit van toepassing zijn op de hele database.
- Implementeer een groot aantal uitschaalscenario's voor lezen met benoemde replica's .
- Profiteer van snel schalen, zonder te wachten tot gegevens worden gekopieerd naar lokale opslag op nieuwe knooppunten.
- Profiteer van continue databaseback-up en snelle herstelbewerkingen van nul.
- Ondersteuning voor bedrijfscontinuïteitsvereisten met behulp van failovergroepen en geo-replicatie.
Hardwareconfiguratie
Algemene hardwareconfiguraties in het vCore-model omvatten standard-series (Gen5), Fsv2-serie en DC-serie. Hyperscale biedt ook een optie voor voor premium-serie en premium-serie geoptimaliseerde hardware. Hardwareconfiguratie definieert reken- en geheugenlimieten en andere kenmerken die van invloed zijn op de prestaties van de werkbelasting.
Bepaalde hardwareconfiguraties, zoals standard-series (Gen5), kunnen meer dan één type processor (CPU) gebruiken, zoals beschreven in Rekenresources (CPU en geheugen). Hoewel een bepaalde database of elastische pool vaak lange tijd op de hardware blijft met hetzelfde CPU-type (meestal voor meerdere maanden), zijn er bepaalde gebeurtenissen die ertoe kunnen leiden dat een database of pool wordt verplaatst naar hardware die gebruikmaakt van een ander CPU-type. Een database of pool kan bijvoorbeeld worden verplaatst als u omhoog of omlaag schaalt naar een andere servicedoelstelling, of als de huidige infrastructuur in een datacenter de capaciteitslimieten nadert of als de momenteel gebruikte hardware buiten gebruik wordt gesteld vanwege het einde van de levensduur.
Voor sommige workloads kan een overstap naar een ander CPU-type de prestaties wijzigen. SQL Database configureert hardware met het doel voorspelbare workloadprestaties te bieden, zelfs als het CPU-type verandert, waardoor de prestatiewijzigingen binnen een smalle band blijven. In het brede spectrum van klantworkloads in SQL Database en wanneer er nieuwe typen CPU's beschikbaar komen, is het soms mogelijk om merkbare wijzigingen in prestaties te zien, als een database of pool naar een ander CPU-type wordt verplaatst.
Ongeacht het gebruikte CPU-type blijven resourcelimieten voor een database of elastische pool (zoals het aantal kernen, geheugen, maximale gegevens-IOPS, maximale logboeksnelheid en maximale gelijktijdige werkrollen) hetzelfde zolang de database op dezelfde servicedoelstelling blijft staan.
Rekenresources (CPU en geheugen)
In de volgende tabel worden rekenresources in verschillende hardwareconfiguraties en rekenlagen vergeleken:
| Hardwareconfiguratie | CPU | Geheugen |
|---|---|---|
| Standard-serie (Gen5) | Ingerichte rekenkracht - Intel® E5-2673 v4 (Broadwell) 2,3 GHz, Intel SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2,5 GHz*, Intel®® Xeon Platinum 8370C (Ice Lake)*, AMD EPYC 7763v (Milaan) processors - Maximaal 128 vCores inrichten (hyperthreaded) Serverloze compute - Intel® E5-2673 v4 (Broadwell) 2,3 GHz, Intel SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2,5 GHz*, Intel® Xeon® Platinum 8370C (Ice Lake)*, AMD EPYC 7763v (Milaan) processors - Automatisch schalen tot 80 vCores (hyperthreaded) - De verhouding tussen geheugen en vCore past zich dynamisch aan het geheugen- en CPU-gebruik aan op basis van de vraag naar werkbelasting en kan zo hoog zijn als 24 GB per vCore. Op een bepaald moment kan een workload bijvoorbeeld worden gebruikt en gefactureerd voor 240 GB geheugen en slechts 10 vCores. |
Ingerichte rekenkracht - 5,1 GB per vCore - Maximaal 625 GB inrichten Serverloze compute - Automatisch schalen tot 24 GB per vCore - Automatisch schalen tot maximaal 240 GB |
| Fsv2-serie | - Intel® 8168 (Skylake)-processors - Met een aanhoudende kern turbokloksnelheid van 3,4 GHz en een maximale turbokloksnelheid van één kern van 3,7 GHz. - Maximaal 72 vCores inrichten (hyperthreaded) |
- 1,9 GB per vCore - Maximaal 136 GB inrichten |
| DC-serie | - Intel® XEON E-2288G-processors - Met Intel Software Guard-extensie (Intel SGX) - Maximaal 8 vCores inrichten (fysiek) |
4,5 GB per vCore |
* In de sys.dm_user_db_resource_governance dynamische beheerweergave wordt hardwaregeneratie voor databases met Intel® SP-8160 -processors (Skylake) weergegeven als Gen6, hardwaregeneratie voor databases met Intel® 8272CL (Cascade Lake) wordt weergegeven als Gen7 en hardwaregeneratie voor databases met Intel Xeon® Platinum 8370C (Ice Lake) of AMD® EPYC® 7763v (Milaan) als Gen8. Voor een bepaalde rekenkracht en hardwareconfiguratie zijn resourcelimieten hetzelfde, ongeacht het CPU-type (Intel Broadwell, Skylake, Ice Lake, Cascade Lake of AMD Milaan).
Zie resourcelimieten voor individuele databases en elastische pools voor meer informatie.
Zie Hyperscale-rekenresources en -specificatie voor Hyperscale-rekenresources.
Standard-serie (Gen5)
- Standaardhardware (Gen5) biedt evenwichtige reken- en geheugenresources en is geschikt voor de meeste databaseworkloads.
Standaardhardware (Gen5) is beschikbaar in alle openbare regio's wereldwijd.
Hyperscale Premium-serie
- Hardwareopties uit de Premium-serie gebruiken de nieuwste CPU- en geheugentechnologie van Intel en AMD. Premium-serie biedt een boost voor de rekenprestaties ten opzichte van hardware uit de standard-serie.
- De optie Premium-serie biedt snellere CPU-prestaties vergeleken met Standard-serie en een hoger aantal maximale vCores.
- De optie geoptimaliseerd voor geheugen uit de Premium-serie biedt een dubbele hoeveelheid geheugen ten opzichte van de Standard-serie.
- Geoptimaliseerd geheugen uit de Standard-serie, premium-serie en premium-serie zijn beschikbaar voor elastische Hyperscale-pools (preview).
Zie de blogaankondiging van de Hyperscale Premium-serie voor meer informatie.
Zie beschikbaarheid van de Hyperscale Premium-serie voor regio's.
Fsv2-serie
- Fsv2-serie is een voor rekenkracht geoptimaliseerde hardwareconfiguratie die lage CPU-latentie en hoge kloksnelheid levert voor de meest veeleisende CPU-workloads. Net als bij hardwareconfiguraties uit de Hyperscale Premium-serie wordt fsv2-serie aangedreven door de nieuwste CPU- en geheugentechnologie van Intel en AMD, zodat klanten kunnen profiteren van de nieuwste hardware terwijl ze databases en elastische pools gebruiken in de servicelaag Algemeen gebruik.
- Afhankelijk van de workload kan fsv2-serie meer CPU-prestaties per vCore leveren dan andere typen hardware. De rekenkracht van 72 vCore Fsv2 kan bijvoorbeeld meer CPU-prestaties bieden dan 80 vCores op Standard-serie (Gen5), tegen lagere kosten.
- Fsv2 biedt minder geheugen en
tempdbper vCore dan andere hardware, dus workloads die gevoelig zijn voor deze limieten kunnen beter presteren op standard-series (Gen5).
Fsv2-serie wordt alleen ondersteund in de laag Algemeen gebruik. Zie De beschikbaarheid van de Fsv2-serie voor regio's waarin de Fsv2-serie beschikbaar is.
DC-serie
- Hardware uit de DC-serie maakt gebruik van Intel-processors met Software Guard Extensions (Intel SGX)-technologie.
- DC-serie is vereist voor Always Encrypted met beveiligde enclaves-workloads waarvoor sterkere beveiliging van hardware-enclaves is vereist, vergeleken met VBS-enclaves (Virtualization-based Security).
- DC-serie is ontworpen voor workloads die gevoelige gegevens verwerken en vertrouwelijke queryverwerkingsmogelijkheden vereisen, geleverd door Always Encrypted met beveiligde enclaves.
- Hardware uit de DC-serie biedt evenwichtige reken- en geheugenresources.
DC-serie wordt alleen ondersteund voor ingerichte rekenkracht (serverloos wordt niet ondersteund) en biedt geen ondersteuning voor zoneredundantie. Zie beschikbaarheid van DC-serie voor regio's waar DC-serie beschikbaar is.
Azure-aanbiedingstypen die worden ondersteund door DC-serie
Als u databases of elastische pools wilt maken op dc-seriehardware, moet het abonnement een betaald aanbiedingstype zijn, waaronder Betalen per gebruik of Enterprise Overeenkomst (EA). Zie huidige aanbiedingen zonder bestedingslimieten voor een volledige lijst met Azure-aanbiedingstypen die worden ondersteund door DC-serie.
Hardwareconfiguratie selecteren
U kunt hardwareconfiguratie selecteren voor een database of elastische pool in SQL Database op het moment dat deze is gemaakt. U kunt ook de hardwareconfiguratie van een bestaande database of elastische pool wijzigen.
Een hardwareconfiguratie selecteren bij het maken van een SQL Database of pool
Zie Een SQL Database maken voor gedetailleerde informatie.
Selecteer op het tabblad Basisinformatie de koppeling Database configureren in de sectie Compute en opslag en selecteer vervolgens de koppeling Configuratie wijzigen:
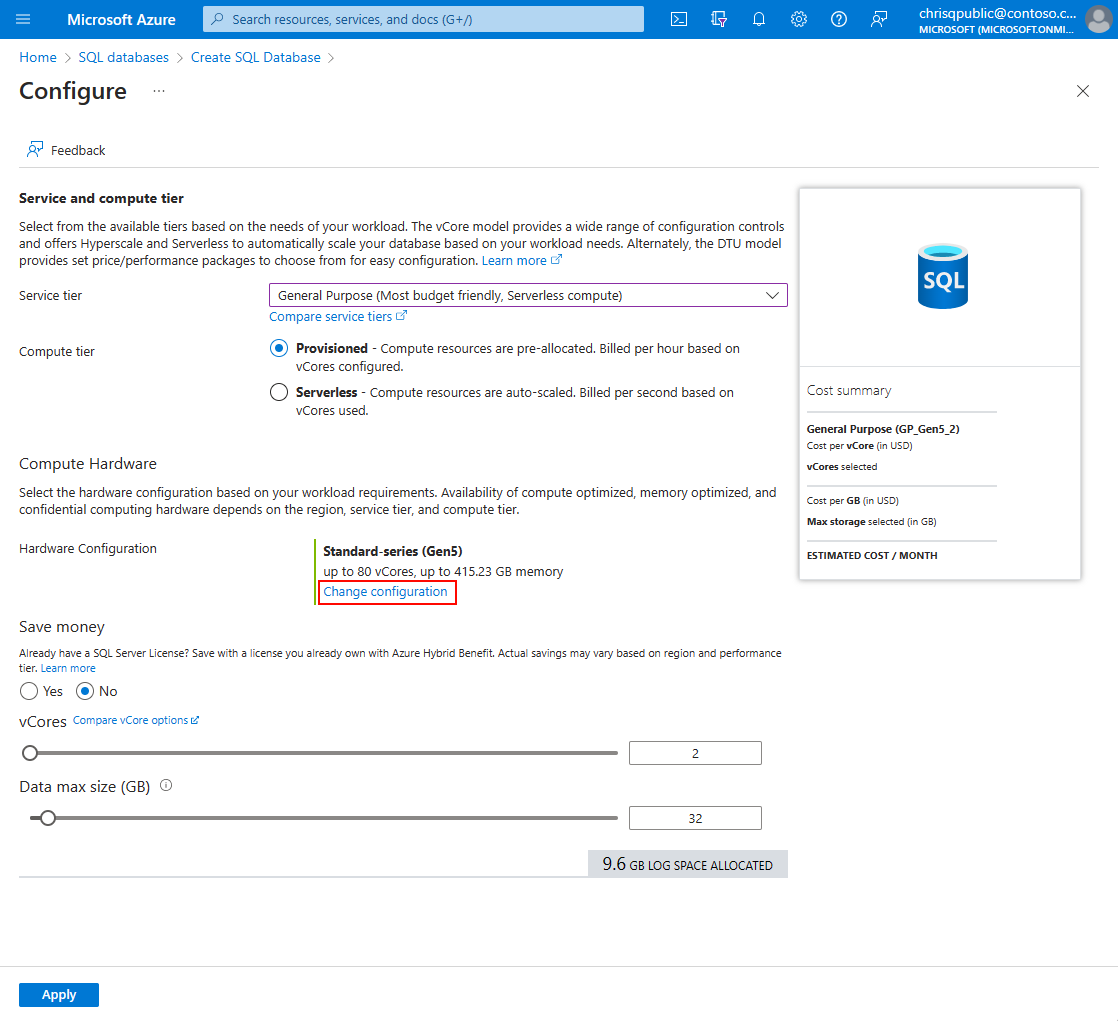
Selecteer de gewenste hardwareconfiguratie:
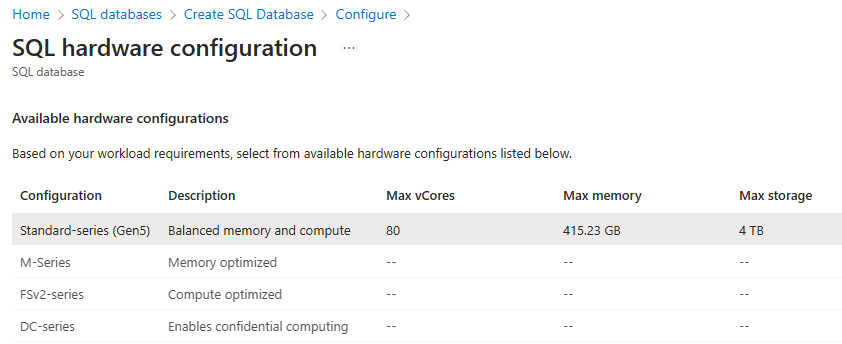
Hardwareconfiguratie van een bestaande SQL-database of -pool wijzigen
Selecteer voor een database op de pagina Overzicht de koppeling Prijscategorie :
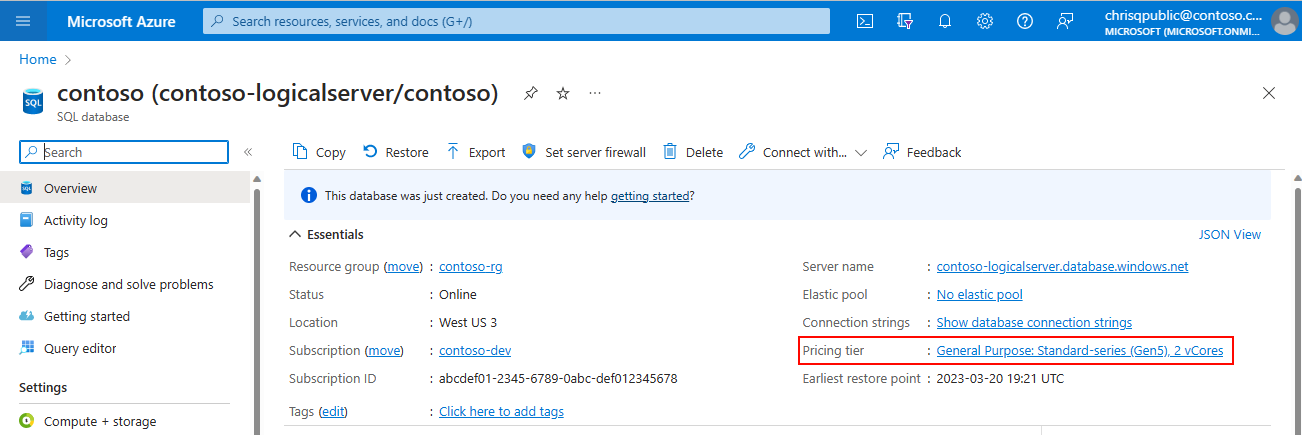
Selecteer Configureren voor een groep op de pagina Overzicht.
Volg de stappen om de configuratie te wijzigen en selecteer de hardwareconfiguratie, zoals beschreven in de vorige stappen.
Beschikbaarheid van hardware
Zie De beschikbaarheid van hardware van de vorige generatie voor informatie over hardware van de vorige generatie.
Standard-serie (Gen5)
Standaardhardware (Gen5) is beschikbaar in alle openbare regio's wereldwijd.
Hyperscale Premium-serie
Hyperscale-servicelaag premium-serie en premium-serie geoptimaliseerde hardware is beschikbaar voor individuele databases en elastische pools in de volgende regio's:
- Australië - oost
- Brazilië - zuid
- Canada - centraal **
- India - centraal
- Central US
- Azië - oost
- VS - oost **
- VS - oost 2
- Frankrijk - centraal
- Duitsland - west-centraal
- India - zuid
- Japan East
- Japan - west *
- VS - noord-centraal
- Europa - noord **
- Azië - zuidoost
- VS - zuid-centraal
- VK - zuid
- VS - west-centraal
- Europa - west **
- VS - west 1
- VS - west 2
- VS - west 3 **
* Geoptimaliseerde hardware uit de Premium-serie is momenteel niet beschikbaar.
** Bevat ondersteuning voor zoneredundantie.
Fsv2-serie
Fsv2-serie is beschikbaar in de volgende regio's:
- Australië - centraal
- Australië - centraal 2
- Australië - oost
- Australië - zuidoost
- Brazilië - zuid
- Canada - midden
- Azië - oost
- VS - oost
- Frankrijk - centraal
- India - centraal
- Korea - centraal
- Korea - zuid
- Europa - noord
- Zuid-Afrika - noord
- Azië - zuidoost
- Verenigd Koninkrijk Zuid
- Verenigd Koninkrijk West
- Europa -west
- VS - west 2
DC-serie
DC-serie is beschikbaar in de volgende regio's:
- Canada - midden
- VS - oost
- Europa - noord
- Verenigd Koninkrijk Zuid
- Europa -west
- VS - west
- Azië - zuidoost
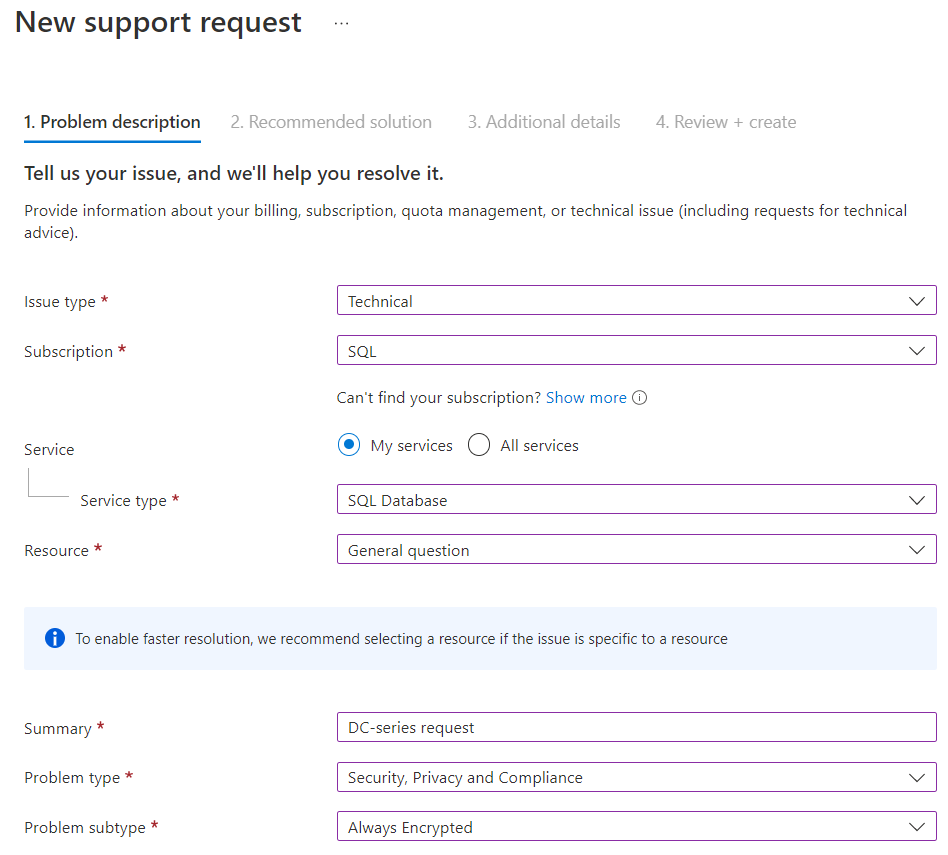
Als u DC-serie nodig hebt in een momenteel niet-ondersteunde regio, dient u een ondersteuningsaanvraag in. Geef op de pagina Basisinformatie het volgende op:
- Selecteer Voor type probleem de optie Technisch.
- Geef het gewenste abonnement op voor de hardware. Selecteer Volgende.
- Selecteer SQL Database voor servicetype.
- Voor Resource selecteert u Algemene vraag.
- Geef voor Samenvatting de gewenste hardware-beschikbaarheid en -regio op.
- Voor probleemtype selecteert u Beveiliging, Privé en Naleving.
- Bij subtype Probleem selecteert u Always Encrypted.
Hardware van vorige generatie
Gen4
Gen4-hardware is buiten gebruik gesteld en is niet beschikbaar voor inrichting, schaalaanpassing of omlaag schalen. Migreer uw database naar een ondersteunde hardwaregeneratie voor een breder scala aan schaalbaarheid van vCore en opslag, versneld netwerken, de beste I/O-prestaties en minimale latentie. Bekijk de hardwareopties voor individuele databases en hardwareopties voor elastische pools. Zie Ondersteuning is beëindigd voor Gen 4-hardware in Azure SQL Database voor meer informatie.
Gerelateerde inhoud
- Pagina met prijzen voor Azure SQL Database
- Resourcelimieten voor individuele databases met gebruikmaking van het vCore-aankoopmodel
- Resourcelimieten voor elastische pools met gebruikmaking van het vCore-aankoopmodel