AlwaysOn-beschikbaarheidsgroep op SQL Server op Azure-VM's
Van toepassing op:![]() SQL Server op Azure VM
SQL Server op Azure VM
In dit artikel maakt u kennis met AlwaysOn-beschikbaarheidsgroepen (AG) voor SQL Server op virtuele Azure-machines (VM's).
Zie de zelfstudie over de beschikbaarheidsgroep om aan de slag te gaan.
Overzicht
AlwaysOn-beschikbaarheidsgroepen op virtuele Azure-machines zijn vergelijkbaar met AlwaysOn-beschikbaarheidsgroepen on-premises en zijn afhankelijk van het onderliggende Windows Server-failovercluster. Omdat de virtuele machines echter in Azure worden gehost, zijn er ook enkele aanvullende overwegingen, zoals VM-redundantie en routeringsverkeer in het Azure-netwerk.
In het volgende diagram ziet u een beschikbaarheidsgroep voor SQL Server op Azure-VM's:
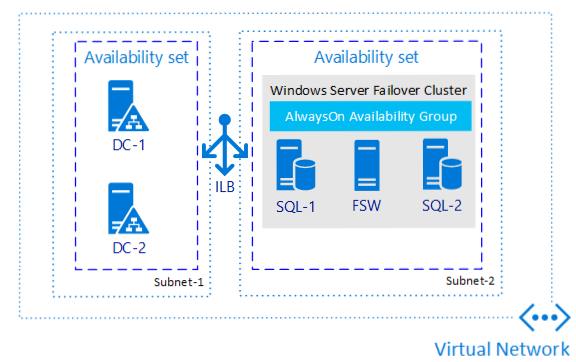
Notitie
Het is nu mogelijk om uw oplossing voor beschikbaarheidsgroepen te verplaatsen naar SQL Server op Azure-VM's met behulp van Azure Migrate. Zie Beschikbaarheidsgroep migreren voor meer informatie.
VM-redundantie
Om redundantie en de maximale beschikbaarheid te vergroten, moeten SQL Server-VM's zich in dezelfde beschikbaarheidsset bevinden of in verschillende beschikbaarheidszones.
Het plaatsen van een set virtuele machines in dezelfde beschikbaarheidsset beschermt tegen storingen in een datacenter die wordt veroorzaakt door een storing in de apparatuur (VM's in een beschikbaarheidsset delen geen resources) of van updates (VM's binnen een beschikbaarheidsset worden niet tegelijkertijd bijgewerkt).
Beschikbaarheidszones beschermen tegen het mislukken van een volledig datacenter, waarbij elke zone een set datacenters binnen een regio vertegenwoordigt. Door ervoor te zorgen dat resources in verschillende beschikbaarheidszones worden geplaatst, kan er geen storing op datacentrumniveau al uw VM's offline halen.
Wanneer u Azure-VM's maakt, met u kiezen tussen het configureren van beschikbaarheidssets en beschikbaarheidszones. Een Virtuele Azure-machine kan niet deelnemen aan beide.
Hoewel beschikbaarheidszones mogelijk betere beschikbaarheid bieden dan beschikbaarheidssets (99,99% versus 99,95%), moeten de prestaties ook een overweging zijn. VM's in een beschikbaarheidsset kunnen in een nabijheidsplaatsingsgroep worden geplaatst, waardoor ze zich dicht bij elkaar bevinden, waardoor de netwerklatentie ertussen wordt geminimaliseerd. VM's in verschillende beschikbaarheidszones hebben een grotere netwerklatentie ertussen, waardoor de tijd die nodig is voor het synchroniseren van gegevens tussen de primaire en secundaire replica('s) kan toenemen. Dit kan vertragingen veroorzaken op de primaire replica en de kans op gegevensverlies vergroten in het geval van een niet-geplande failover. Het is belangrijk om de voorgestelde oplossing onder belasting te testen en ervoor te zorgen dat deze voldoet aan SLA's voor zowel prestaties als beschikbaarheid.
Connectiviteit
Als u de on-premises ervaring voor het maken van verbinding wilt maken met uw listener voor beschikbaarheidsgroepen, implementeert u uw SQL Server-VM's naar meerdere subnetten binnen hetzelfde virtuele netwerk. Als u meerdere subnetten hebt, hoeft u niet meer afhankelijk te zijn van een Azure Load Balancer of een gedistribueerde netwerknaam (DNN) om uw verkeer naar uw listener te routeren.
Als u uw SQL Server-VM's implementeert in één subnet, kunt u een naam van een virtueel netwerk (VNN) en een Azure Load Balancer of een gedistribueerde netwerknaam (DNN) configureren om verkeer naar de listener van uw beschikbaarheidsgroep te routeren. Bekijk de verschillen tussen de twee en implementeer vervolgens een gedistribueerde netwerknaam (DNN) of een naam van een virtueel netwerk (VNN) voor uw beschikbaarheidsgroep.
De meeste SQL Server-functies werken transparant met beschikbaarheidsgroepen wanneer u de DNN gebruikt, maar er zijn bepaalde functies waarvoor mogelijk speciale overwegingen nodig zijn. Zie ag- en DNN-interoperabiliteit voor meer informatie.
Daarnaast zijn er enkele gedragsverschillen tussen de functionaliteit van de VNN-listener en DNN-listener die belangrijk zijn om te weten:
- Failovertijd: failovertijd is sneller wanneer u een DNN-listener gebruikt, omdat u niet hoeft te wachten totdat de netwerk load balancer de fout gebeurtenis detecteert en de routering ervan wijzigt.
- Bestaande verbindingen: verbindingen die zijn gemaakt met een specifieke database binnen een failover-overbeschikbaarheidsgroep, worden gesloten, maar andere verbindingen met de primaire replica blijven geopend omdat de DNN online blijft tijdens het failoverproces. Dit is anders dan een traditionele VNN-omgeving waarbij alle verbindingen met de primaire replica doorgaans sluiten wanneer de beschikbaarheidsgroep een failover uitvoert, de listener offline gaat en de primaire replica overgaat naar de secundaire rol. Wanneer u een DNN-listener gebruikt, moet u mogelijk toepassingsverbindingsreeksen aanpassen om ervoor te zorgen dat verbindingen worden omgeleid naar de nieuwe primaire replica na failover.
- Openstaande transacties: Open transacties voor een database in een failover-overbeschikbaarheidsgroep wordt gesloten en teruggedraaid en u moet handmatig opnieuw verbinding maken. Sluit bijvoorbeeld in SQL Server Management Studio het queryvenster en open een nieuw venster.
Voor het instellen van een VNN-listener in Azure is een load balancer vereist. Er zijn twee hoofdopties voor load balancers in Azure: extern (openbaar) of intern. De externe (openbare) load balancer is internetgericht en is gekoppeld aan een openbaar virtueel IP-adres dat toegankelijk is via internet. Een interne load balancer ondersteunt alleen clients binnen hetzelfde virtuele netwerk. Voor elk type load balancer moet u Direct Server Return inschakelen.
U kunt nog steeds afzonderlijk verbinding maken met elke beschikbaarheidsreplica door rechtstreeks verbinding te maken met het service-exemplaar. Omdat beschikbaarheidsgroepen achterwaarts compatibel zijn met databasespiegelingsclients, kunt u verbinding maken met de beschikbaarheidsreplica's, zoals partners voor databasespiegeling, zolang de replica's op dezelfde manier zijn geconfigureerd als databasespiegeling:
- Er is één primaire replica en één secundaire replica.
- De secundaire replica is geconfigureerd als niet-leesbaar (leesbare secundaire optie ingesteld op Nee).
Hier volgt een voorbeeld van een clientverbindingsreeks die overeenkomt met deze databasespiegeling-achtige configuratie met behulp van ADO.NET of SQL Server Native Client:
Data Source=ReplicaServer1;Failover Partner=ReplicaServer2;Initial Catalog=AvailabilityDatabase;
Zie voor meer informatie over clientconnectiviteit:
- Trefwoorden voor verbindingsreeksen gebruiken met sql Server Native Client
- Clients verbinden met een databasespiegelingssessie (SQL Server)
- Verbinding maken met listener voor beschikbaarheidsgroepen in hybride IT
- Listeners voor beschikbaarheidsgroepen, clientconnectiviteit en toepassingsfailover (SQL Server)
- Verbindingsreeksen voor databasespiegeling gebruiken met beschikbaarheidsgroepen
Eén subnet vereist load balancer
Wanneer u een listener voor een beschikbaarheidsgroep maakt op een traditioneel on-premises Windows Server Failover Cluster (WSFC), wordt er een DNS-record gemaakt voor de listener met het IP-adres dat u opgeeft. Dit IP-adres wordt toegewezen aan het MAC-adres van de huidige primaire replica in de ARP-tabellen van switches en routers in het on-premises netwerk. Het cluster doet dit met behulp van Gratuitous ARP (GARP), waarbij de meest recente IP-naar-MAC-adrestoewijzing naar het netwerk wordt uitgezonden wanneer een nieuwe primaire wordt geselecteerd na een failover. In dit geval is het IP-adres voor de listener en de MAC van de huidige primaire replica. De GARP dwingt een update van de ARP-tabelvermeldingen voor de switches en routers af en aan alle gebruikers die verbinding maken met het IP-adres van de listener, worden naadloos doorgestuurd naar de huidige primaire replica.
Het uitzenden van openbare clouds (Azure, Google, AWS) is om veiligheidsredenen niet toegestaan, dus het gebruik van ARPs en GARPs in Azure wordt niet ondersteund. Om dit verschil in netwerkomgevingen te overwinnen, zijn SQL Server-VM's in één subnet-beschikbaarheidsgroep afhankelijk van load balancers om verkeer naar de juiste IP-adressen te routeren. Load balancers worden geconfigureerd met een front-end-IP-adres dat overeenkomt met de listener en er wordt een testpoort toegewezen, zodat de Azure Load Balancer periodiek pollt naar de status van de replica's in de beschikbaarheidsgroep. Omdat alleen de sql Server-VM van de primaire replica reageert op de TCP-test, wordt binnenkomend verkeer doorgestuurd naar de VIRTUELE machine die met succes op de test reageert. Daarnaast wordt de bijbehorende testpoort geconfigureerd als het IP-adres van het WSFC-cluster, zodat de primaire replica reageert op de TCP-test.
Beschikbaarheidsgroepen die zijn geconfigureerd in één subnet, moeten een load balancer of gedistribueerde netwerknaam (DNN) gebruiken om verkeer naar de juiste replica te routeren. Om deze afhankelijkheden te voorkomen, configureert u uw beschikbaarheidsgroep in meerdere subnetten, zodat de listener van de beschikbaarheidsgroep is geconfigureerd met een IP-adres voor een replica in elk subnet en verkeer op de juiste manier kan routeren.
Als u uw beschikbaarheidsgroep al in één subnet hebt gemaakt, kunt u deze migreren naar een omgeving met meerdere subnetten.
Leasemechanisme
Voor SQL Server bepaalt het DLL-bestand van de AG-resource de status van de ag op basis van het leasemechanisme van de beschikbaarheidsgroep en alwayson-statusdetectie. De DLL van de AG-resource maakt de resourcestatus beschikbaar via de IsAlive-bewerking . De resourcemonitor peilt IsAlive op het heartbeat-interval van het cluster, dat wordt ingesteld door de waarden CrossSubnetDelay en SameSubnetDelay-clusterbreed. Op een primair knooppunt initieert de clusterservice een failover wanneer de IsAlive-aanroep naar het bron-DLL-bestand retourneert dat de beschikbaarheidsgroep niet in orde is.
De DLL van de AG-resource bewaakt de status van interne SQL Server-onderdelen. Sp_server_diagnostics rapporteert de status van deze onderdelen aan SQL Server op een interval dat wordt beheerd door HealthCheckTimeout.
In tegenstelling tot andere failovermechanismen speelt het SQL Server-exemplaar een actieve rol in het leasemechanisme. Het leasemechanisme wordt gebruikt als een LookAlive-validatie tussen de clusterresourcehost en het SQL Server-proces. Het mechanisme wordt gebruikt om ervoor te zorgen dat de twee zijden (de Cluster Service en SQL Server-service) regelmatig contact hebben, elkaars status controleren en uiteindelijk een split-brain-scenario voorkomen.
Bij het configureren van een beschikbaarheidsgroep in Azure-VM's is het vaak nodig om deze drempelwaarden anders te configureren dan in een on-premises omgeving. Als u drempelwaarde-instellingen wilt configureren op basis van aanbevolen procedures voor Virtuele Azure-machines, raadpleegt u de aanbevolen procedures voor clusters.
Netwerkconfiguratie
Implementeer waar mogelijk uw SQL Server-VM's in meerdere subnetten om de afhankelijkheid van een Azure Load Balancer of een gedistribueerde netwerknaam (DNN) te voorkomen om verkeer naar de listener van uw beschikbaarheidsgroep te routeren.
Op een Azure VM-failovercluster raden we één NIC per server (clusterknooppunt) aan. Azure-netwerken hebben fysieke redundantie, waardoor extra NIC's onnodig zijn op een Azure VM-failovercluster. Hoewel het clustervalidatierapport een waarschuwing geeft dat de knooppunten alleen bereikbaar zijn in één netwerk, kan deze waarschuwing veilig worden genegeerd op Azure VM-failoverclusters.
Basis beschikbaarheidsgroep
Omdat een eenvoudige beschikbaarheidsgroep niet meer dan één secundaire replica toestaat en er geen leestoegang tot de secundaire replica is, kunt u de verbindingsreeksen voor databasespiegeling gebruiken voor basis beschikbaarheidsgroepen. Als u de verbindingsreeks gebruikt, hoeft u geen listeners meer te hebben. Het verwijderen van de listener-afhankelijkheid is handig voor beschikbaarheidsgroepen op Virtuele Azure-machines omdat er geen load balancer meer nodig is of als u extra IP-adressen moet toevoegen aan de load balancer wanneer u meerdere listeners voor extra databases hebt.
Als u bijvoorbeeld expliciet verbinding wilt maken via TCP/IP met de AG-database AdventureWorks op Replica_A of Replica_B van een Basic-AG (of een ag met slechts één secundaire replica en de leestoegang niet is toegestaan in de secundaire replica), kan een clienttoepassing de volgende verbindingsreeks voor databasespiegeling opgeven om verbinding te maken met de AG
Server=Replica_A; Failover_Partner=Replica_B; Database=AdventureWorks; Network=dbmssocn
Implementatieopties
Fooi
Elimineer de noodzaak van een Azure Load Balancer of gedistribueerde netwerknaam (DNN) voor uw AlwaysOn-beschikbaarheidsgroep door uw SQL Server-VM's te maken in meerdere subnetten binnen hetzelfde virtuele Azure-netwerk.
Er zijn meerdere opties voor het implementeren van een beschikbaarheidsgroep voor SQL Server op virtuele Azure-machines, waarbij sommige opties geautomatiseerder zijn dan andere.
De volgende tabel bevat een vergelijking van de beschikbare opties:
| Azure-portal, | Azure CLI / PowerShell | Quickstartsjablonen | Handmatig (één subnet) | Handmatig (meerdere subnetten) | |
|---|---|---|---|---|---|
| SQL Server-versie | 2016 + | 2016 + | 2016 + | 2012 + | 2012 + |
| SQL Server-editie | Enterprise | Enterprise | Enterprise | Enterprise, Standard | Enterprise, Standard |
| Windows Server-versie | 2016 + | 2016 + | 2016 + | Alle | Alle |
| Het cluster wordt voor u gemaakt | Ja | Ja | Ja | No | Nee |
| Maakt de beschikbaarheidsgroep en listener voor u | Ja | No | Nee | Nee | Nee |
| De listener en load balancer worden onafhankelijk van elkaar gemaakt | N.v.t. | Nee | Nee | Ja | N.v.t. |
| Kan met deze methode een DNN-listener worden gemaakt? | N.v.t. | Nee | Nee | Ja | N.v.t. |
| Configuratie van WSFC-quorum | Cloudwitness | Cloudwitness | Cloudwitness | Alle | Alle |
| Herstel na noodgeval met meerdere regio's | Nee | Nee | Nee | Ja | Ja |
| Ondersteuning voor meerdere subnetten | Ja | No | Nee | N.v.t. | Ja |
| Ondersteuning voor een bestaande AD | Ja | Ja | Ja | Ja | Ja |
| Herstel na noodgeval met multizone in dezelfde regio | Ja | Ja | Ja | Ja | Ja |
| Gedistribueerde beschikbaarheidsgroep zonder AD | Nee | Nee | Nee | Ja | Ja |
| Gedistribueerde beschikbaarheidsgroep zonder cluster | Nee | Nee | Nee | Ja | Ja |
| Vereist een load balancer of DNN | Nee | Ja | Ja | Ja | Nee |
Volgende stappen
Als u aan de slag wilt gaan, bekijkt u de best practices voor HADR en implementeert u vervolgens uw beschikbaarheidsgroep handmatig met de zelfstudie over de beschikbaarheidsgroep.
Raadpleeg voor meer informatie: