Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Azure Chaos Studio is een beheerde service die gebruikmaakt van chaos-engineering om u te helpen uw cloudtoepassing en servicetolerantie te meten, te begrijpen en te verbeteren. Chaos engineering is een methodologie waarmee u echte fouten in uw toepassing injecteert om gecontroleerde experimenten voor foutinjectie uit te voeren.
Tolerantie is de mogelijkheid van een systeem om onderbrekingen te verwerken en te herstellen. Toepassingsonderbrekingen kunnen fouten en fouten veroorzaken die uw bedrijf of missie nadelig kunnen beïnvloeden. Of u nu Azure-toepassingen ontwikkelt, migreert of gebruikt, het is belangrijk om de tolerantie van uw toepassing te valideren en te verbeteren.
Chaos Studio helpt u negatieve gevolgen te voorkomen door te valideren dat uw toepassing effectief reageert op onderbrekingen en storingen. U kunt Chaos Studio gebruiken om tolerantie te testen tegen echte incidenten, zoals storingen of hoog CPU-gebruik op virtuele machines (VM's).
De volgende video biedt meer achtergrondinformatie over Chaos Studio:
Chaos Studio scenario's
U kunt chaos-engineering gebruiken voor verschillende tolerantievalidatiescenario's die de levenscyclus van de serviceontwikkeling en operationele activiteiten omvatten. Er zijn twee soorten scenario's:
- Naar rechts verschuiven: in deze scenario's wordt gebruikgemaakt van een productie- of preproductieomgeving. Normaal gesproken voert u shift-right-scenario's uit met echt klantverkeer of gesimuleerde belasting.
- Naar links gaan: in deze scenario's kan een ontwikkel- of gedeelde testomgeving worden gebruikt. U kunt scenario's met shift-left uitvoeren zonder echt klantverkeer.
U kunt Chaos Studio gebruiken voor de volgende algemene chaos-engineeringscenario's:
- Reproduceer een incident dat van invloed is op uw toepassing om de fout beter te begrijpen. Zorg ervoor dat herstel na incidenten verhindert dat het incident terugkeert.
- Bereid u voor op een belangrijke gebeurtenis of seizoen met 'game day'-belasting, schaal, prestaties en tolerantievalidatie.
- Voer bedrijfscontinuïteit en noodherstelanalyses uit om ervoor te zorgen dat uw toepassing snel kan herstellen en kritieke gegevens in een noodgeval kan bewaren.
- Voer oefeningen voor hoge beschikbaarheid uit om de resiliteit van de toepassing te testen tegen regiostoringen, netwerkconfiguratiefouten, stressvolle gebeurtenissen of uitdagingen door luidruchtige buren.
- Ontwikkel benchmarks voor toepassingsprestaties.
- Capaciteitsbehoeften plannen voor productieomgevingen.
- Voer stresstests of belastingstests uit.
- Zorg ervoor dat services die zijn gemigreerd vanuit een on-premises of een andere cloudomgeving bestand blijven tegen bekende fouten.
- Bouw vertrouwen in services die zijn gebouwd op cloudeigen architecturen.
- Controleer of live site-tooling, observabiliteit gegevens en oproepprocessen nog steeds functioneren onder onverwachte omstandigheden.
Voor veel van deze scenario's bouwt u eerst tolerantie met behulp van ad-hoc chaos-experimenten. Vervolgens controleert u continu of nieuwe implementaties geen regressietolerantie hebben. U kunt dit controleren door chaosexperimenten uit te voeren als implementatiepoorten in uw pijplijnen voor continue integratie/continue implementatie.
Hoe Chaos Studio werkt
Met Chaos Studio kunt u veilige, gecontroleerde foutinjectie op uw Azure-resources organiseren. Chaos experimenten vormen de kern van Chaos Studio. Een chaos-experiment beschrijft de fouten die moeten worden geïntroduceerd en de resources waarop het experiment moet worden uitgevoerd. U kunt onderdelen ordenen om parallel of opeenvolgend uit te voeren, afhankelijk van uw behoeften.
Chaos Studio ondersteunt twee soorten fouten:
- Service-direct: deze fouten worden rechtstreeks uitgevoerd op een Azure-resource, zonder installatie of instrumentatie. Voorbeelden hiervan zijn het opnieuw opstarten van een Azure Cache voor Redis-cluster of het toevoegen van netwerklatentie aan Azure Kubernetes Service-pods.
- Agent-gebaseerd: Deze fouten treden op in VM's of virtuele-machineschaalsets om storingen binnen de gastomgeving uit te voeren. Voorbeelden hiervan zijn het toepassen van een virtuele geheugendruk of het doden van een proces.
Elke fout heeft specifieke parameters die u kunt configureren, zoals welk proces moet worden gedood of hoeveel geheugendruk moet worden gegenereerd.
Wanneer u een chaos-experiment bouwt, definieert u een of meer stappen die opeenvolgend worden uitgevoerd. Elke stap bevat één of meer vertakkingen die binnen de stap parallel worden uitgevoerd. Elke vertakking bevat een of meer acties, zoals het injecteren van een fout of wachten voor een bepaalde tijd.
U organiseert resourcedoelenvoor het uitvoeren van fouten in groepen genaamd selectors, zodat u eenvoudig naar een groep resources in elke actie kunt verwijzen.
In het volgende diagram ziet u de indeling van een chaos-experiment in Chaos Studio:
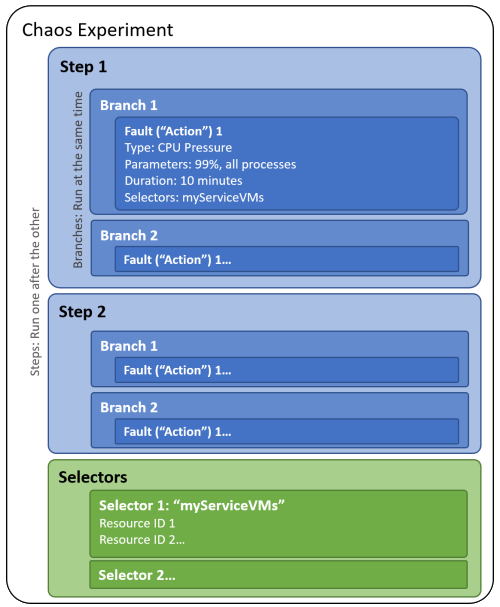
Een chaos-experiment is een Azure-resource in een abonnement en resourcegroep. U kunt Azure Portal of de Chaos Studio REST API gebruiken om de status van experimenten te maken, bij te werken, te starten, te annuleren en weer te geven.
Volgende stappen
Nu u begrijpt hoe u chaos-engineering kunt gebruiken, kunt u het volgende doen: