Budgetten, kosten en quota voor Azure Machine Learning op organisatieschaal beheren
Wanneer u rekenkosten beheert die zijn gemaakt van Azure Machine Learning, kunt u op organisatieschaal met veel workloads, veel teams en gebruikers talloze beheer- en optimalisatieproblemen oplossen.
In dit artikel presenteren we best practices voor het optimaliseren van kosten, het beheren van budgetten en het delen van quota met Azure Machine Learning. Het is een bundeling van de ervaringen en lessen die we bij Microsoft hebben geleerd tijdens het managen van interne machine learning-teams en tijdens de samenwerking met onze klanten. U leert het volgende:
- Optimaliseer rekenresources om te voldoen aan de workloadvereisten.
- Het beste gebruik van het budget van een team stimuleren.
- Budgetten, kosten en quota plannen, beheren en delen op ondernemingsniveau.
Compute optimaliseren om te voldoen aan de workloadvereisten
Wanneer u een nieuw machine learning-project start, is verkennend werk mogelijk nodig om een goed beeld te krijgen van de rekenvereisten. In deze sectie vindt u aanbevelingen voor het bepalen van de juiste vm-SKU-keuze voor training, deductie of als werkstation van waaruit u kunt werken.
De rekenkracht voor training bepalen
Hardwarevereisten voor uw trainingsworkload kunnen variëren van project tot project. Om aan deze vereisten te voldoen, biedt Azure Machine Learning Compute verschillende typen VM's:
- Algemeen gebruik: Evenwichtige CPU-verhouding tot geheugen.
- Geoptimaliseerd voor geheugen: een hoge verhouding tussen geheugen en CPU.
- Geoptimaliseerd voor rekenkracht: hoge CPU-verhouding tot geheugen.
- High performance compute: lever hoogwaardige prestaties, schaalbaarheid en kostenefficiëntie voor verschillende hpc-workloads in de echte wereld.
- Exemplaren met GPU's: Gespecialiseerde virtuele machines gericht op zware grafische rendering en videobewerking, evenals modeltraining en deductie (ND) met deep learning.
Mogelijk weet u nog niet wat uw rekenvereisten zijn. In dit scenario raden we u aan om te beginnen met een van de volgende kosteneffectieve standaardopties. Deze opties zijn bedoeld voor lichtgewicht testen en voor trainingsworkloads.
| Type | Grootte van virtuele machine | Specs |
|---|---|---|
| CPU | Standard_DS3_v2 | 4 kernen, 14 gigabyte (GB) RAM, 28 GB opslag |
| GPU | Standard_NC6 | 6 kernen, 56 gigabyte (GB) RAM, 380 GB opslag, NVIDIA Tesla K80 GPU |
Om de beste VM-grootte voor uw scenario te krijgen, kan dit bestaan uit een evaluatie en fout. Hier volgen verschillende aspecten die u moet overwegen.
- Als u een CPU nodig hebt:
- Gebruik een voor geheugen geoptimaliseerde VM als u traint op grote gegevenssets.
- Gebruik een voor berekening geoptimaliseerde VM als u realtime deductie of andere latentiegevoelige taken uitvoert.
- Gebruik een VIRTUELE machine met meer kernen en RAM om de trainingstijden te versnellen.
- Als u een GPU nodig hebt, raadpleegt u de voor GPU geoptimaliseerde VM-grootten voor informatie over het selecteren van een virtuele machine.
- Als u gedistribueerde training uitvoert, gebruikt u VM-grootten met meerdere GPU's.
- Als u gedistribueerde training uitvoert op meerdere knooppunten, gebruikt u GPU's met NVLink-verbindingen.
Terwijl u het VM-type en de SKU selecteert die het beste bij uw workload passen, evalueert u vergelijkbare VM-SKU's als een afweging tussen CPU- en GPU-prestaties en -prijzen. Vanuit het oogpunt van kostenbeheer kan een taak redelijk goed worden uitgevoerd op verschillende SKU's.
Bepaalde GPU's, zoals de NC-serie, met name NC_Promo SKU's, hebben vergelijkbare mogelijkheden als andere GPU's, zoals lage latentie en de mogelijkheid om meerdere rekenworkloads parallel te beheren. Ze zijn beschikbaar tegen kortingsprijzen vergeleken met een aantal van de andere GPU's. Als u VM-SKU's voor de workload selecteert, kunt u uiteindelijk aanzienlijk kosten besparen.
Een herinnering over het belang van het gebruik is om u aan te melden voor een groter aantal GPU's, niet noodzakelijkerwijs uitgevoerd met snellere resultaten. Zorg er in plaats daarvan voor dat de GPU's volledig worden gebruikt. Controleer bijvoorbeeld de behoefte aan NVIDIA CUDA. Hoewel het mogelijk vereist is voor gpu-uitvoering met hoge prestaties, neemt uw taak mogelijk geen afhankelijkheid.
De rekenkracht voor deductie bepalen
Rekenvereisten voor deductiescenario's verschillen van trainingsscenario's. Beschikbare opties verschillen afhankelijk van of uw scenario offlinedeductie in batch vereist of onlinedeductie in realtime vereist.
Houd rekening met de volgende suggesties voor realtime deductiescenario's:
- Gebruik profileringsmogelijkheden in uw model met Azure Machine Learning om te bepalen hoeveel CPU en geheugen u moet toewijzen voor het model bij het implementeren als een webservice.
- Als u realtime deductie uitvoert maar geen hoge beschikbaarheid nodig hebt, implementeert u in Azure Container Instances (geen SKU-selectie).
- Als u realtime deductie uitvoert maar hoge beschikbaarheid nodig hebt, implementeert u deze in Azure Kubernetes Service.
- Als u traditionele machine learning-modellen gebruikt en 10 query's per seconde ontvangt < , begint u met een CPU-SKU. SKU's uit de F-serie werken vaak goed.
- Als u deep learning-modellen gebruikt en 10 query's per seconde ontvangt > , probeert u een NVIDIA GPU-SKU (NCasT4_v3 vaak goed werkt) met Triton.
Houd rekening met de volgende suggesties voor batchdeductiescenario's:
- Wanneer u Azure Machine Learning-pijplijnen gebruikt voor batchdeductie, volgt u de richtlijnen in Bepalen van de rekenkracht voor training om de oorspronkelijke VM-grootte te kiezen.
- Optimaliseer kosten en prestaties door horizontaal te schalen. Een van de belangrijkste methoden voor het optimaliseren van kosten en prestaties is door de workload te parallelliseren met behulp van de parallelle uitvoeringsstap in Azure Machine Learning. Met deze pijplijnstap kunt u veel kleinere knooppunten gebruiken om de taak parallel uit te voeren, zodat u horizontaal kunt schalen. Er is echter sprake van overhead voor parallelle uitvoering. Afhankelijk van de workload en de mate van parallelle uitvoering die kan worden bereikt, kan een parallelle uitvoeringsstap wel of niet een optie zijn.
De grootte van het rekenproces bepalen
Voor interactieve ontwikkeling wordt het rekenproces van Azure Machine Learning aanbevolen. De aanbieding voor het rekenproces (CI) brengt rekenkracht van één knooppunt die is gebonden aan één gebruiker en kan worden gebruikt als een cloudwerkstation.
Sommige organisaties staan het gebruik van productiegegevens op lokale werkstations niet toe, hebben beperkingen voor de werkstationomgeving afgedwongen of de installatie van pakketten en afhankelijkheden in de IT-omgeving van het bedrijf beperkt. Een rekenproces kan worden gebruikt als werkstation om de beperking te overwinnen. Het biedt een veilige omgeving met toegang tot productiegegevens en wordt uitgevoerd op installatiekopieën die worden geleverd met populaire pakketten en hulpprogramma's voor data science die vooraf zijn geïnstalleerd.
Wanneer het rekenproces wordt uitgevoerd, wordt de gebruiker gefactureerd voor VM-rekenkracht, Standard Load Balancer (opgenomen lb/uitgaande regels en verwerkte gegevens), besturingssysteemschijf (premium SSD beheerde P10-schijf), tijdelijke schijf (het tijdelijke schijftype is afhankelijk van de gekozen VM-grootte) en openbaar IP-adres. Als u kosten wilt besparen, raden we gebruikers aan het volgende te overwegen:
- Start en stop het rekenproces wanneer deze niet in gebruik is.
- Werk met een voorbeeld van uw gegevens op een rekenproces en schaal uit naar rekenclusters om te werken met uw volledige set gegevens
- Verzend experimententaken in de lokale rekendoelmodus op het rekenproces tijdens het ontwikkelen of testen, of wanneer u overschakelt naar gedeelde rekencapaciteit wanneer u taken op volledige schaal verzendt. Bijvoorbeeld, veel tijdvakken, volledige set gegevens en hyperparameter zoeken.
Als u het rekenproces stopt, stopt het de facturering voor VM-rekenuren, tijdelijke schijven en de verwerkte kosten van Standard Load Balancer. Opmerking: gebruiker betaalt nog steeds voor besturingssysteemschijf en Standard Load Balancer bevat lb-/uitgaande regels, zelfs wanneer het rekenproces wordt gestopt. Alle gegevens die op de besturingssysteemschijf zijn opgeslagen, blijven behouden door te stoppen en opnieuw op te starten.
De gekozen VM-grootte afstemmen door het rekengebruik te bewaken
U kunt informatie bekijken over uw Azure Machine Learning-rekengebruik en -gebruik via Azure Monitor. U kunt details bekijken over modelimplementatie en -registratie, quotumdetails zoals actieve en niet-actieve knooppunten, uitvoeringsdetails zoals geannuleerde en voltooide uitvoeringen en rekengebruik voor GPU- en CPU-gebruik.
Op basis van de inzichten uit de bewakingsgegevens kunt u uw resourcegebruik beter plannen of aanpassen in het hele team. Als u bijvoorbeeld de afgelopen week veel niet-actieve knooppunten ziet, kunt u samenwerken met de bijbehorende werkruimte-eigenaren om de configuratie van het rekencluster bij te werken om deze extra kosten te voorkomen. Voordelen van het analyseren van de gebruikspatronen kunnen helpen bij het voorspellen van kosten en budgetverbeteringen.
U hebt rechtstreeks vanuit Azure Portal toegang tot deze metrische gegevens. Ga naar uw Azure Machine Learning-werkruimte en selecteer Metrische gegevens onder de sectie Bewaking in het linkerdeelvenster. Vervolgens kunt u details selecteren over wat u wilt weergeven, zoals metrische gegevens, aggregatie en tijdsperiode. Zie de documentatiepagina van Azure Machine Learning bewaken voor meer informatie.
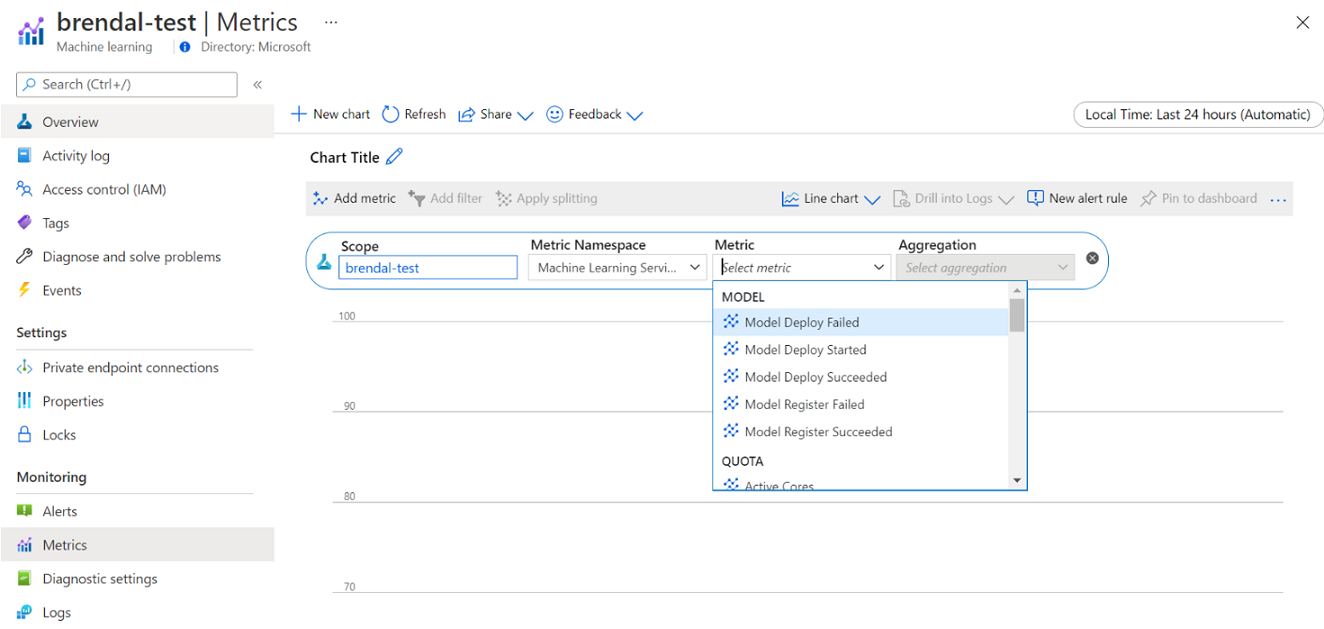
Schakelen tussen lokale cloud-, één-knooppunt- en cloud-rekenkracht met meerdere knooppunten tijdens het ontwikkelen
Er zijn verschillende reken- en hulpprogrammavereisten gedurende de levenscyclus van machine learning. Azure Machine Learning kan worden geinterfaced via een SDK- en CLI-interface vanaf vrijwel elke voorkeurswerkstationconfiguratie om aan deze vereisten te voldoen.
Als u kosten wilt besparen en productief wilt werken, is het raadzaam het volgende te doen:
- Kloon uw experimenteercodebasis lokaal met behulp van Git en verzend taken naar cloud-compute met behulp van de Azure Machine Learning SDK of CLI.
- Als uw gegevensset groot is, kunt u overwegen een voorbeeld van uw gegevens op uw lokale werkstation te beheren, terwijl u de volledige gegevensset in de cloudopslag houdt.
- Parametereer uw experimentatiecodebasis, zodat u uw taken kunt configureren voor uitvoering met een verschillend aantal tijdvakken of gegevenssets van verschillende grootten.
- Codeer het mappad van uw gegevensset niet. U kunt vervolgens eenvoudig dezelfde codebasis opnieuw gebruiken met verschillende gegevenssets en onder de context van lokale en clouduitvoering.
- Bootstrap uw experimententaken in de lokale rekendoelmodus tijdens het ontwikkelen of testen, of wanneer u overschakelt naar een gedeelde rekenclustercapaciteit wanneer u taken op volledige schaal verzendt.
- Als uw gegevensset groot is, kunt u werken met een voorbeeld van gegevens op uw lokale werkstation of rekenproces, terwijl u schaalt naar cloud-compute in Azure Machine Learning om te werken met uw volledige set gegevens.
- Wanneer het lang duurt voordat uw taken worden uitgevoerd, kunt u overwegen om uw codebasis voor gedistribueerde training te optimaliseren om horizontaal uit te schalen.
- Ontwerp uw gedistribueerde trainingsworkloads voor elasticiteit van knooppunten, zodat u flexibel gebruik kunt maken van rekenkracht met één knooppunt en meerdere knooppunten, en het gebruik van rekenkracht die kan worden versoepeld.
Rekentypen combineren met Behulp van Azure Machine Learning-pijplijnen
Wanneer u uw machine learning-werkstromen indelen, kunt u een pijplijn met meerdere stappen definiëren. Elke stap in de pijplijn kan worden uitgevoerd op een eigen rekentype. Zo kunt u de prestaties en kosten optimaliseren om te voldoen aan verschillende rekenvereisten gedurende de levenscyclus van machine learning.
Het beste gebruik van het budget van een team stimuleren
Hoewel beslissingen voor budgettoewijzing mogelijk buiten de controle van een afzonderlijk team vallen, is een team doorgaans gemachtigd om het toegewezen budget te gebruiken voor hun beste behoeften. Door taakprioriteit af te handelen versus prestaties en kosten, kan een team een hoger clustergebruik bereiken, de totale kosten verlagen en een groter aantal rekenuren van hetzelfde budget gebruiken. Dit kan leiden tot verbeterde teamproductiviteit.
De kosten van gedeelde rekenresources optimaliseren
De sleutel voor het optimaliseren van de kosten van gedeelde rekenresources is ervoor te zorgen dat ze worden gebruikt voor hun volledige capaciteit. Hier volgen enkele tips voor het optimaliseren van uw gedeelde resourcekosten:
- Wanneer u rekeninstanties gebruikt, schakelt u deze alleen in wanneer u code hebt om uit te voeren. Sluit ze af wanneer ze niet worden gebruikt.
- Wanneer u rekenclusters gebruikt, stelt u het minimumaantal knooppunten in op 0 en het maximumaantal knooppunten op een getal dat wordt geëvalueerd op basis van uw budgetbeperkingen. Gebruik de Azure-prijscalculator om de kosten van volledig gebruik van één VM-knooppunt van uw gekozen VM-SKU te berekenen. Met automatisch schalen worden alle rekenknooppunten omlaag geschaald wanneer niemand deze gebruikt. Hiermee wordt alleen omhoog geschaald naar het aantal knooppunten waarvoor u budget hebt. U kunt automatisch schalen configureren om alle rekenknooppunten omlaag te schalen.
- Bewaak uw resourcegebruik, zoals CPU-gebruik en GPU-gebruik bij het trainen van modellen. Als de resources niet volledig worden gebruikt, wijzigt u de code om resources beter te gebruiken of omlaag te schalen naar kleinere of goedkopere VM-grootten.
- Evalueer of u gedeelde rekenresources voor uw team kunt maken om inefficiënties te voorkomen die worden veroorzaakt door schaalbewerkingen voor clusters.
- Optimaliseer het beleid voor automatische schaalaanpassing van rekenclusters op basis van metrische gegevens over gebruik.
- Gebruik werkruimtequota om de hoeveelheid rekenresources te bepalen waartoe afzonderlijke werkruimten toegang hebben.
Planningsprioriteit introduceren door clusters te maken voor meerdere VM-SKU's
Als een team onder quotum- en budgetbeperkingen handelt, moet het tijdig uitvoeren van taken versus kosten afruilen om ervoor te zorgen dat belangrijke taken tijdig worden uitgevoerd en een budget op de best mogelijke manier wordt gebruikt.
Om het beste rekengebruik te ondersteunen, worden teams aanbevolen om clusters van verschillende grootten en met lage prioriteit en toegewezen VM-prioriteiten te maken. Berekeningen met lage prioriteit maken gebruik van overtollige capaciteit in Azure en worden daarom geleverd met kortingstarieven. Aan het nadeel kunnen deze machines worden afgewend wanneer een vraag met een hogere prioriteit binnenkomt.
Met behulp van de clusters met verschillende grootte en prioriteit kan een idee van planningsprioriteit worden geïntroduceerd. Wanneer experimentele en productietaken bijvoorbeeld concurreren voor hetzelfde NC GPU-quotum, kan een productietaak de voorkeur hebben om de experimentele taak uit te voeren. Voer in dat geval de productietaak uit op het toegewezen rekencluster en de experimentele taak op het rekencluster met lage prioriteit. Wanneer het quotum kort is, wordt de experimentele taak ten gunste van de productietaak verschoven.
Naast vm-prioriteit kunt u taken uitvoeren op verschillende VM-SKU's. Het kan zijn dat een taak langer duurt om uit te voeren op een VM-exemplaar met een P40 GPU dan op een V100 GPU. Aangezien V100 VM-exemplaren echter volledig kunnen worden gebruikt of het quotum kunnen worden gebruikt, kan de tijd voor voltooiing van de P40 nog steeds sneller zijn vanuit het perspectief van taakdoorvoer. U kunt ook overwegen om taken met een lagere prioriteit uit te voeren op minder presterende en goedkopere VM-exemplaren vanuit het oogpunt van kostenbeheer.
Een uitvoering vroegtijdig beëindigen wanneer de training niet convergeert
Wanneer u continu experimenteert om een model te verbeteren op basis van de basislijn, kunt u verschillende experimentuitvoeringen uitvoeren, elk met iets andere configuraties. Voor één uitvoering kunt u de invoergegevenssets aanpassen. Voor een andere uitvoering kunt u een hyperparameterwijziging aanbrengen. Niet alle wijzigingen zijn mogelijk net zo effectief als de andere. U detecteert vroeg dat een wijziging niet het beoogde effect heeft op de kwaliteit van uw modeltraining. Als u wilt detecteren of de training niet convergeert, controleert u de voortgang van de training tijdens een uitvoering. Bijvoorbeeld door metrische prestatiegegevens na elke trainingstijdvakken te registreren. Overweeg om de taak vroeg te beëindigen om resources en budget voor een andere proefversie vrij te maken.
Budgetten, kosten en quota plannen, beheren en delen
Naarmate een organisatie het aantal machine learning-gebruiksscenario's en teams vergroot, is een grotere operationele volwassenheid van IT en financiën vereist, evenals coördinatie tussen afzonderlijke machine learning-teams om efficiënte bewerkingen te garanderen. Capaciteits- en quotumbeheer op bedrijfsniveau wordt belangrijk om het schaarsheid van rekenresources aan te pakken en de beheeroverhead te overwinnen.
In deze sectie worden aanbevolen procedures besproken voor het plannen, beheren en delen van budgetten, kosten en quota op ondernemingsniveau. Het is gebaseerd op het leren van het beheren van veel GPU-trainingsresources voor machine learning intern bij Microsoft.
Informatie over resourceuitgaven met Azure Machine Learning
Een van de grootste uitdagingen als beheerder voor het plannen van rekenbehoeften is het starten van nieuwe gegevens zonder historische informatie als basislijnraming. In praktische zin zullen de meeste projecten beginnen met een klein budget als eerste stap.
Als u wilt weten waar het budget heen gaat, is het essentieel om te weten waar azure Machine Learning-kosten vandaan komen:
- Azure Machine Learning brengt alleen kosten in rekening voor de gebruikte rekeninfrastructuur en voegt geen toeslag toe aan de rekenkosten.
- Wanneer een Azure Machine Learning-werkruimte wordt gemaakt, zijn er ook enkele andere resources gemaakt om Azure Machine Learning in te schakelen: Key Vault, Application Insights, Azure Storage en Azure Container Registry. Deze resources worden gebruikt in Azure Machine Learning en u betaalt voor deze resources.
- Er zijn kosten verbonden aan beheerde berekeningen, zoals trainingsclusters, rekeninstanties en beheerde deductie-eindpunten. Met deze beheerde rekenresources zijn er de volgende infrastructuurkosten om rekening mee te houden: virtuele machines, virtueel netwerk, load balancer, bandbreedte en opslag.
Uitgavenpatronen bijhouden en betere rapportage bereiken met taggen
Beheer istrators willen vaak de kosten voor verschillende resources in Azure Machine Learning kunnen bijhouden. Taggen is een natuurlijke oplossing voor dit probleem en is afgestemd op de algemene benadering die wordt gebruikt door Azure en veel andere cloudserviceproviders. Met ondersteuning voor tags kunt u nu de kostenanalyse bekijken op rekenniveau, waardoor u toegang krijgt tot een gedetailleerdere weergave om u te helpen met betere kostenbewaking, verbeterde rapportage en meer transparantie.
Met taggen kunt u aangepaste tags op uw werkruimten en berekeningen plaatsen (van Azure Resource Manager-sjablonen en Azure Machine Learning-studio) om deze resources verder te filteren in Microsoft Cost Management op basis van deze tags om uitgavenpatronen te observeren. Deze functionaliteit kan het beste worden gebruikt voor interne kostenbackscenario's. Daarnaast kunnen tags handig zijn voor het vastleggen van metagegevens of details die zijn gekoppeld aan de berekening, zoals een project, een team of een bepaalde factureringscode. Dit maakt taggen zeer nuttig voor het meten van hoeveel geld u aan verschillende resources uitgeeft en daarom dieper inzicht krijgt in uw kosten- en uitgavenpatronen in teams of projecten.
Er zijn ook door het systeem geïnjecteerde tags geplaatst op berekeningen waarmee u kunt filteren op de pagina Kostenanalyse door de tag 'Rekentype' om een berekeningswijze uitsplitsing van uw totale uitgaven te bekijken en te bepalen welke categorie rekenresources het merendeel van uw kosten kan toewijzen. Dit is met name handig om meer inzicht te krijgen in uw trainings- en deductiekostenpatronen.
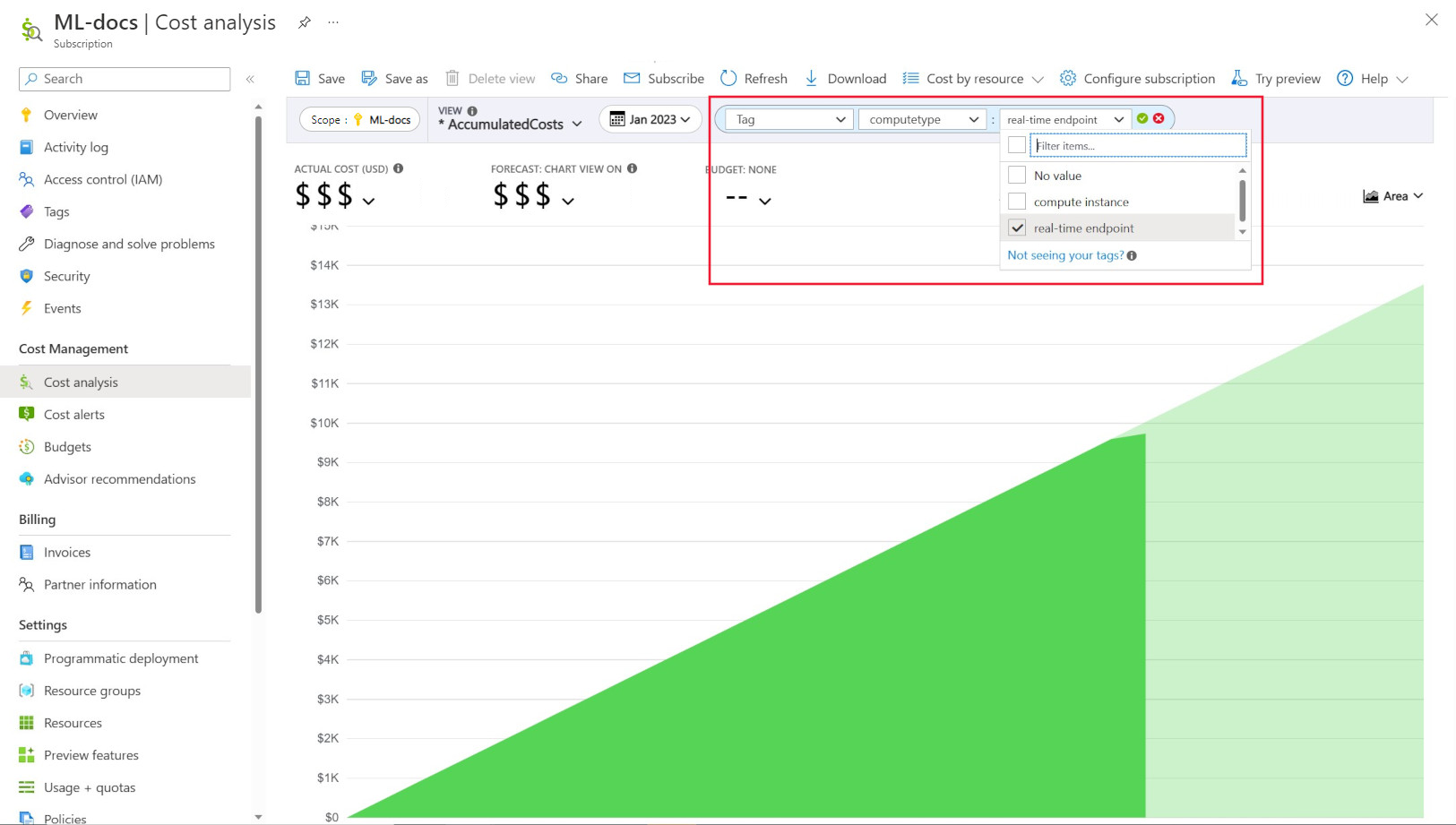
Rekengebruik beheren en beperken op basis van beleid
Wanneer u een Azure-omgeving met veel workloads beheert, kan het een uitdaging zijn om het overzicht van resourceuitgaven te behouden. Azure Policy kan helpen bij het beheren en beheren van resourceuitgaven door bepaalde gebruikspatronen in de Azure-omgeving te beperken.
In het bijzonder voor Azure Machine Learning raden we u aan beleidsregels in te stellen om alleen het gebruik van specifieke VM-SKU's toe te staan. Beleidsregels kunnen helpen bij het voorkomen en beheren van selectie van dure VM's. Beleidsregels kunnen ook worden gebruikt om het gebruik van VM-SKU's met lage prioriteit af te dwingen.
Quota toewijzen en beheren op basis van bedrijfsprioriteit
Met Azure kunt u limieten instellen voor quotumtoewijzing op abonnements- en Azure Machine Learning-werkruimteniveau. Door te beperken wie quota kan beheren via op rollen gebaseerd toegangsbeheer (RBAC) van Azure, kan het resourcegebruik en de voorspelbaarheid van kosten worden gegarandeerd.
De beschikbaarheid van GPU-quota kan schaars zijn voor uw abonnementen. Om een hoog quotumgebruik voor workloads te garanderen, raden we u aan te controleren of het quotum het beste wordt gebruikt en toegewezen aan workloads.
Bij Microsoft wordt periodiek bepaald of GPU-quota het beste worden gebruikt en toegewezen voor machine learning-teams door capaciteitsbehoeften te evalueren op basis van bedrijfsprioriteit.
Doorvoercapaciteit van tevoren
Als u een goede schatting hebt van de hoeveelheid rekenkracht die in het volgende jaar of de komende jaren wordt gebruikt, kunt u Gereserveerde VM-instanties van Azure aanschaffen tegen korting. Er zijn een- of driejarige aankoopvoorwaarden. Omdat gereserveerde VM-instanties van Azure korting krijgen, kunnen er aanzienlijke kostenbesparingen zijn in vergelijking met prijzen voor betalen per gebruik.
Azure Machine Learning ondersteunt gereserveerde rekeninstanties. Kortingen worden automatisch toegepast op door Azure Machine Learning beheerde compute.
Gegevensretentie beheren
Telkens wanneer een machine learning-pijplijn wordt uitgevoerd, kunnen tussenliggende gegevenssets worden gegenereerd bij elke pijplijnstap voor gegevenscache en hergebruik. De groei van gegevens als uitvoer van deze machine learning-pijplijnen kan een pijnpunt worden voor een organisatie die veel machine learning-experimenten uitvoert.
Gegevenswetenschappers besteden doorgaans geen tijd aan het opschonen van de tussenliggende gegevenssets die worden gegenereerd. Na verloop van tijd wordt de hoeveelheid gegenereerde gegevens opgetellen. Azure Storage biedt een mogelijkheid om het beheer van de levenscyclus van gegevens te verbeteren. Met behulp van levenscyclusbeheer van Azure Blob Storage kunt u algemeen beleid instellen om gegevens die niet worden gebruikt, te verplaatsen naar koudere opslaglagen en kosten te besparen.
Overwegingen voor optimalisatie van infrastructuurkosten
Netwerken
Azure-netwerkkosten worden gemaakt op basis van uitgaande bandbreedte van Het Azure-datacenter. Alle binnenkomende gegevens naar een Azure-datacenter zijn gratis. De sleutel voor het verlagen van de netwerkkosten is om waar mogelijk al uw resources in dezelfde datacenterregio te implementeren. Als u Een Azure Machine Learning-werkruimte kunt implementeren en berekenen in dezelfde regio met uw gegevens, kunt u profiteren van lagere kosten en hogere prestaties.
Mogelijk wilt u een privéverbinding tussen uw on-premises netwerk en uw Azure-netwerk hebben om een hybride cloudomgeving te hebben. Met ExpressRoute kunt u dat doen, maar gezien de hoge kosten van ExpressRoute is het mogelijk rendabeler om weg te gaan van een hybride cloudinstallatie en alle resources naar de Azure-cloud te verplaatsen.
Azure Container Registry
Voor Azure Container Registry zijn de bepalende factoren voor kostenoptimalisatie onder andere:
- Vereiste doorvoer voor downloads van Docker-installatiekopieën uit het containerregister naar Azure Machine Learning
- Vereisten voor bedrijfsbeveiligingsfuncties, zoals Azure Private Link
Voor productiescenario's waarbij hoge doorvoer of bedrijfsbeveiliging is vereist, wordt de Premium-SKU van Azure Container Registry aanbevolen.
Voor ontwikkel-/testscenario's waarbij doorvoer en beveiliging minder kritiek zijn, raden we aan Standard SKU of Premium SKU te gebruiken.
De Basic-SKU van Azure Container Registry wordt niet aanbevolen voor Azure Machine Learning. Het wordt niet aanbevolen vanwege de lage doorvoer en lage inbegrepen opslag, die snel kan worden overschreden door de relatief grote Docker-installatiekopieën van Azure Machine Learning (1+ GB).
Overweeg beschikbaarheid van rekentypen bij het kiezen van Azure-regio's
Wanneer u een regio voor uw berekening kiest, moet u rekening houden met de beschikbaarheid van het rekenquotum. Populaire en grotere regio's zoals VS - oost, VS - west en Europa - west hebben meestal hogere standaardquotumwaarden en een grotere beschikbaarheid van de meeste CPU's en GPU's, vergeleken met sommige andere regio's met strengere capaciteitsbeperkingen.
Meer informatie
Volgende stappen
Zie de Handleiding voor Machine Learning DevOps voor meer informatie over best practices voor Machine Learning DevOps met Azure Machine Learning.