Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Gegevenskwaliteit is een beheerfunctie van analyses op cloudschaal. Het bevindt zich in de landingszone voor gegevensbeheer en is een belangrijk onderdeel van governance.
Overwegingen voor gegevenskwaliteit
Gegevenskwaliteit is de verantwoordelijkheid van elke persoon die gegevensproducten maakt en verbruikt. Makers moeten voldoen aan de algemene en domeinregels, terwijl consumenten gegevensconsistentie moeten rapporteren aan het domein dat eigenaar is van gegevens via een feedbacklus.
Omdat de gegevenskwaliteit van invloed is op alle gegevens die aan het bord worden verstrekt, moet deze boven aan de organisatie beginnen. Het bestuur moet inzicht hebben in de kwaliteit van de gegevens die aan hen worden verstrekt.
Als u echter proactief bent, moet u nog steeds experts van gegevenskwaliteit hebben die buckets met gegevens kunnen opschonen waarvoor herstel is vereist. Vermijd het pushen van dit werk naar een centraal team en richt zich in plaats daarvan op het gegevensdomein, met specifieke gegevenskennis, om de gegevens op te schonen.
Metrische gegevens over gegevenskwaliteit
Metrische gegevens over gegevenskwaliteit zijn essentieel voor het beoordelen en verhogen van de kwaliteit van uw gegevensproducten. Op globaal en domeinniveau moet u beslissen over uw metrische kwaliteitsgegevens. We raden minimaal de volgende metrische gegevens aan:
| Metrische gegevens voor | Definities van metrische gegevens |
|---|---|
| Volledigheid = % totaal van niet-nullen + niet-lege waarden | Meet de beschikbaarheid van gegevens, velden in de gegevensset die niet leeg zijn en standaardwaarden die zijn gewijzigd. Als een record bijvoorbeeld 01/01/1900 als geboortedatum bevat, is het zeer waarschijnlijk dat het veld nooit is ingevuld. |
| Uniekheid = % van niet-ontdubbelde waarden | Meet afzonderlijke waarden in een bepaalde kolom vergeleken met het aantal rijen in de tabel. Als u bijvoorbeeld vier afzonderlijke kleurwaarden (rood, blauw, geel en groen) in een tabel met vijf rijen hebt, is dat veld 80% (of 4/5) uniek. |
| Consistentie = % van gegevens met patronen | Meet de naleving binnen een bepaalde kolom naar het verwachte gegevenstype of de verwachte indeling. Bijvoorbeeld een e-mailveld met opgemaakte e-mailadressen of een naamveld met numerieke waarden. |
| Geldigheid = % van verwijzingskoppeling | Meet geslaagde gegevens die overeenkomen met de domeinreferentieset. Als u bijvoorbeeld een land-/regioveld (voldoet aan taxonomiewaarden) in een transactioneel recordsysteem, is de waarde van 'VS van A' niet geldig. |
| Nauwkeurigheid = % van ongewijzigde waarden | Meet de succesvolle reproductie van de beoogde waarden in meerdere systemen. Als een factuur bijvoorbeeld een SKU en een uitgebreide prijs aangeeft die verschilt van de oorspronkelijke order, is het factuurregelitem onjuist. |
| Koppeling = % van goed geïntegreerde gegevens | Metingen die zijn gekoppeld aan de bijbehorende referentiedetails in een ander systeem. Als een factuur bijvoorbeeld een onjuiste SKU of productbeschrijving aangeeft, kan het factuurregelitem niet worden gekoppeld. |
Gegevensprofilering
Gegevensprofilering onderzoekt gegevensproducten die zijn geregistreerd in de gegevenscatalogus en verzamelt statistieken en informatie over die gegevens. Als u in de loop van de tijd overzichts- en trendweergaven wilt bieden over de kwaliteit van de gegevens, slaat u deze gegevens op in uw metagegevensopslagplaats op basis van het gegevensproduct.
Met gegevensprofielen kunnen gebruikers vragen over gegevensproducten beantwoorden, waaronder:
- Kan het worden gebruikt om mijn bedrijfsprobleem op te lossen?
- Voldoen de gegevens aan bepaalde standaarden of patronen?
- Wat zijn enkele afwijkingen van de gegevensbron?
- Wat zijn de mogelijke uitdagingen voor het integreren van deze gegevens in mijn toepassing?
Gebruikers kunnen het gegevensproductprofiel weergeven met behulp van een rapportagedashboard in hun gegevensmarktplaats.
U kunt rapporteren over items zoals:
- Volledigheid: Geeft het percentage gegevens aan dat niet leeg of null is.
- Uniekheid: geeft het percentage gegevens aan dat niet wordt gedupliceerd.
- Consistentie: Geeft gegevens aan waar de gegevensintegriteit wordt gehandhaafd.
Aanbevelingen voor gegevenskwaliteit
Als u gegevenskwaliteit wilt implementeren, moet u zowel menselijke als rekenkracht als volgt gebruiken:
Gebruik oplossingen die algoritmen, regels, gegevensprofilering en metrische gegevens bevatten.
Gebruik domeinexperts die kunnen instappen wanneer er een vereiste is om een algoritme te trainen vanwege een groot aantal fouten die via de rekenlaag worden doorgegeven.
Valideer vroeg. Traditionele oplossingen passen controles van gegevenskwaliteit toe na het extraheren, transformeren en laden van de gegevens. Op dit moment wordt het gegevensproduct al verbruikt en worden er fouten weergegeven voor downstreamgegevensproducten. Wanneer gegevens uit de bron worden opgenomen, implementeert u in plaats daarvan gegevenskwaliteitscontroles in de buurt van de bronnen en voordat downstreamgebruikers de gegevensproducten gebruiken. Als er batchopname van de data lake is, voert u deze controles uit wanneer u gegevens verplaatst van onbewerkt naar verrijkt.
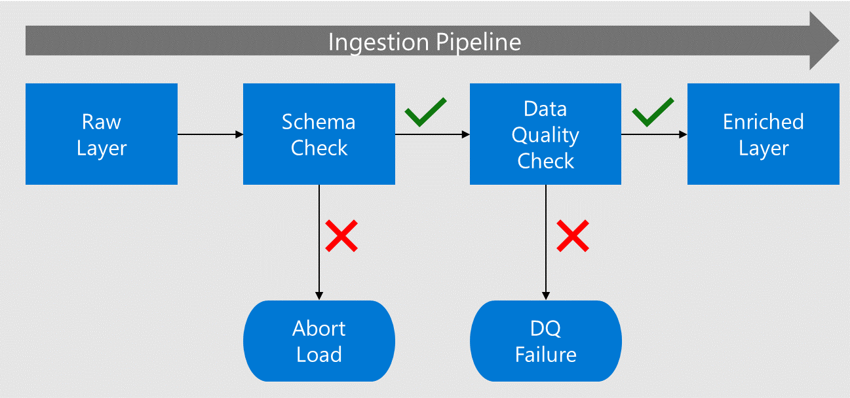
Voordat gegevens naar de verrijkte laag worden verplaatst, worden het schema en de kolommen ervan gecontroleerd op de metagegevens die zijn geregistreerd in de gegevenscatalogus.
Als de gegevens fouten bevatten, wordt de belasting gestopt en wordt het gegevenstoepassingsteam op de hoogte gesteld van de fout.
Als het schema en de kolom worden gecontroleerd, worden de gegevens geladen in de verrijkte lagen met conforme gegevenstypen.
Voordat u naar de verrijkte laag gaat, controleert een proces van gegevenskwaliteit op naleving van de algoritmen en regels.

Tip
Definieer gegevenskwaliteitsregels op zowel globaal als domeinniveau. Hierdoor kan het bedrijf de standaarden voor elk gemaakt gegevensproduct definiëren en kunnen gegevensdomeinen aanvullende regels maken die betrekking hebben op hun domein.
Oplossingen voor gegevenskwaliteit
We raden u aan om Microsoft Purview-gegevenskwaliteit te evalueren als een oplossing voor het beoordelen en beheren van gegevenskwaliteit, wat cruciaal is voor betrouwbare AI-gestuurde inzichten en besluitvorming. Deze bevat:
- Regels zonder code/weinig code: gegevenskwaliteit evalueren met out-of-the-box, door AI gegenereerde regels.
- Door AI gemaakte gegevensprofilering: beveelt kolommen aan voor profilering en maakt menselijke tussenkomst mogelijk voor verfijning.
- Scoren van gegevenskwaliteit: biedt scores voor gegevensassets, gegevensproducten en governancedomeinen.
- Waarschuwingen voor gegevenskwaliteit: waarschuwt gegevenseigenaren van kwaliteitsproblemen.
Zie Wat is gegevenskwaliteit voor meer informatie.
Als uw organisatie besluit Azure Databricks te implementeren om gegevens te manipuleren, moet u de controles voor gegevenskwaliteit, testen, bewaken en afdwingen evalueren die deze oplossing biedt. Het gebruik van verwachtingen kan problemen met gegevenskwaliteit vastleggen bij opname voordat ze van invloed zijn op gerelateerde onderliggende gegevensproducten. Zie Gegevenskwaliteitsstandaarden en Gegevenskwaliteitsbeheer instellen met Databricks voor meer informatie.
U kunt ook kiezen uit partners, opensource en aangepaste opties voor een oplossing voor gegevenskwaliteit.
Samenvatting van gegevenskwaliteit
Het oplossen van gegevenskwaliteit kan ernstige gevolgen hebben voor een bedrijf. Het kan leiden tot bedrijfseenheden die gegevensproducten op verschillende manieren interpreteren. Deze onjuiste interpretatie kan kostbaar zijn voor het bedrijf als beslissingen zijn gebaseerd op gegevensproducten met een lagere gegevenskwaliteit. Het herstellen van gegevensproducten met ontbrekende kenmerken kan een dure taak zijn en kan volledige herlaading van gegevens van verschillende perioden vereisen.
Valideer gegevenskwaliteit vroeg en stel processen in om proactief te reageren op slechte gegevenskwaliteit. Een gegevensproduct kan bijvoorbeeld pas worden vrijgegeven als het een bepaalde mate van volledigheid bereikt.
U kunt hulpprogramma's gebruiken als een vrije keuze, maar ervoor zorgen dat het verwachtingen (regels), metrische gegevens, profilering en de mogelijkheid om de verwachtingen te beveiligen, zodat u globale en domeingebaseerde verwachtingen kunt implementeren.