Prestaties en probleemoplossing voor SAP-gegevensextractie
Dit artikel maakt deel uit van de artikelreeks 'SAP extend and innovate data: Best practices'.
- SAP-gegevensbronnen identificeren
- De beste SAP-connector kiezen
- Prestaties en probleemoplossing voor SAP-gegevensextractie
- Beveiliging van gegevensintegratie voor SAP in Azure
- Algemene architectuur voor SAP-gegevensintegratie
Er zijn veel manieren om verbinding te maken met het SAP-systeem voor gegevensintegratie. In de onderstaande secties worden algemene en connectorspecifieke overwegingen en aanbevelingen beschreven.
Prestaties
Het is belangrijk om optimale instellingen voor de bron en het doel te configureren, zodat u de beste prestaties kunt behalen tijdens het extraheren en verwerken van gegevens.
Algemene overwegingen
- Zorg ervoor dat de juiste SAP-parameters zijn ingesteld voor een maximale gelijktijdige verbinding.
- Overweeg het aanmeldingstype van de SAP-groep te gebruiken voor betere prestaties en belastingsdistributie.
- Zorg ervoor dat de zelf-hostende SHIR-vm (Integration Runtime) voldoende grootte heeft en maximaal beschikbaar is.
- Wanneer u met grote gegevenssets werkt, controleert u of de connector die u gebruikt een partitioneringsmogelijkheid biedt. Veel van de SAP-connectors ondersteunen partitionerings- en parallelle mogelijkheden om het laden van gegevens te versnellen. Wanneer u deze methode gebruikt, worden gegevens verpakt in kleinere segmenten die kunnen worden geladen met behulp van verschillende parallelle processen. Zie connectorspecifieke documentatie voor meer informatie.
Algemene aanbevelingen
Gebruik de SAP-transactie RZ12 om waarden te wijzigen voor het maximum aantal gelijktijdige verbindingen.
SAP-parameters voor RFC - RZ12: de volgende parameter kan het aantal RFC-aanroepen beperken dat is toegestaan voor één gebruiker of één toepassing, dus zorg ervoor dat deze beperking geen knelpunt veroorzaakt.
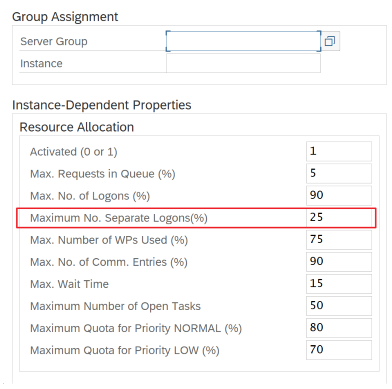
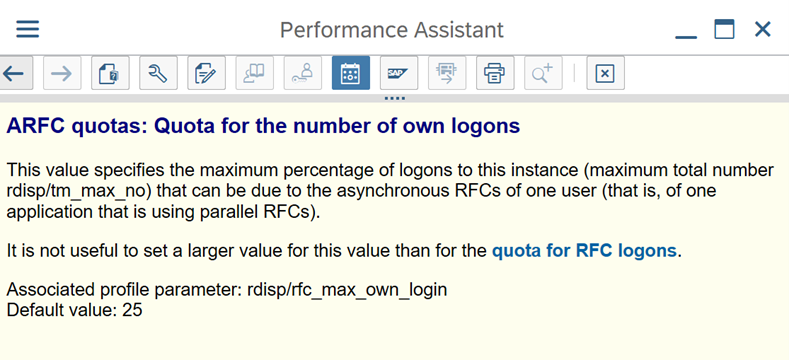
Verbinding met SAP met behulp van aanmeldingsgroep: SHIR (zelf-hostende Integration Runtime) moet verbinding maken met SAP met behulp van een SAP-aanmeldingsgroep (via een berichtenserver) en niet met een specifieke toepassingsserver om een verdeling van de werkbelasting over alle beschikbare toepassingsservers te garanderen.
Notitie
Gegevensstroom Spark-cluster en SHIR zijn krachtig. Veel interne SAP-kopieeractiviteiten, bijvoorbeeld 16, kunnen worden geactiveerd en uitgevoerd. Maar als het gelijktijdige verbindingsnummer van de SAP-server klein is, bijvoorbeeld 8, worden gegevens van de SAP-zijde gelezen.
Begin met 4vCPU's en vm's van 16 GB voor SHIR. In de volgende stappen ziet u de verbinding van het dialoogvensterwerkproces in SAP met SHIR.
- Controleer of de klant een slechte fysieke machine gebruikt om SHIR in te stellen en te installeren om een interne SAP-kopie uit te voeren.
- Ga naar de Azure Data Factory portal en zoek de gerelateerde gekoppelde SAP CDC-service die in de gegevensstroom wordt gebruikt. Controleer de SHIR-naam waarnaar wordt verwezen.
- Controleer de CPU-, geheugen-, netwerk- en schijfinstellingen van de fysieke computer waarop SHIR is geïnstalleerd.
- Controleer hoeveel
diawp.exeer worden uitgevoerd op de SHIR-machine. Udiawp.exekunt één kopieeractiviteit uitvoeren. Het aantal is gebaseerd op de CPU-, geheugen-, netwerk- en schijfinstellingen vandiawp.exede machine.
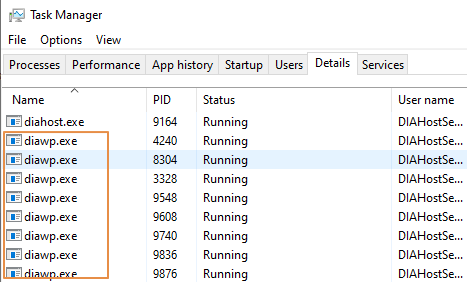
Als u meerdere partities tegelijk wilt uitvoeren op SHIR, gebruikt u een krachtige virtuele machine om SHIR in te stellen. Of gebruik uitschalen met behulp van SHIR-functies voor hoge beschikbaarheid en schaalbaarheid om meerdere knooppunten te hebben. Zie Hoge beschikbaarheid en schaalbaarheid voor meer informatie.
Partities
In de volgende sectie wordt het partitioneringsproces voor een SAP CDC-connector beschreven. Het proces is hetzelfde voor een SAP Table- en SAP BW Open Hub-connector.

Schalen kan worden uitgevoerd op de zelf-hostende IR of de Azure IR, afhankelijk van uw prestatievereisten. Bekijk het CPU-verbruik van de SHIR om metrische gegevens weer te geven om u te helpen bij het bepalen van uw schaalbenadering. De SHIR kan verticaal of horizontaal worden geschaald op basis van uw behoeften. U wordt aangeraden de Azure IR met een lagere SKU te implementeren. Schaal omhoog om te voldoen aan uw prestatievereisten, zoals bepaald door belastingstests, in plaats van onnodig aan de hogere kant te beginnen.
Notitie
Als u een capaciteit van 70% bereikt, schaalt u omhoog of uit voor SHIR.

Partitionering is handig voor initiële of grote volledige belasting en is doorgaans niet vereist voor deltabelastingen. Als u de partitie niet opgeeft, haalt standaard 1 'producer' in het SAP-systeem (meestal één batchproces) de brongegevens op in de ODQ (Operational Data Queue) en haalt SHIR de gegevens op uit ODQ. Standaard gebruikt SHIR vier threads om de gegevens op te halen uit ODQ, zodat er op dat moment mogelijk vier dialoogvensterprocessen in SAP worden gebruikt.
Het idee van partitioneren is om een grote initiële gegevensset te splitsen in meerdere kleinere niet-aaneengesloten subsets die idealiter even groot zijn en parallel kunnen worden verwerkt. Deze methode verkort de tijd die nodig is om de gegevens uit de brontabel op een lineaire manier in de ODQ te produceren. Bij deze methode wordt ervan uitgegaan dat er voldoende resources aan de SAP-zijde zijn om de belasting te verwerken.
Notitie
- Het aantal partities dat parallel wordt uitgevoerd, wordt beperkt door het aantal stuurprogrammakernen in de Azure IR. Er wordt momenteel een oplossing voor deze beperking uitgevoerd.
- Elke eenheid of elk pakket in SAP-transactie ODQMON is één bestand in de map fasering.
Ontwerpoverwegingen bij het uitvoeren van de pijplijnen met CDC
Controleer de duur van sap naar fase.
Controleer de runtimeprestaties in de sink.
Overweeg het gebruik van de partitioneringsfunctie om de prestaties te verbeteren voor een betere doorvoer.
Als de duur van de SAP to-fase traag is, kunt u overwegen om de grootte van SHIR naar hogere specificaties te wijzigen.
Controleer of de verwerkingstijd van de sink te traag is.
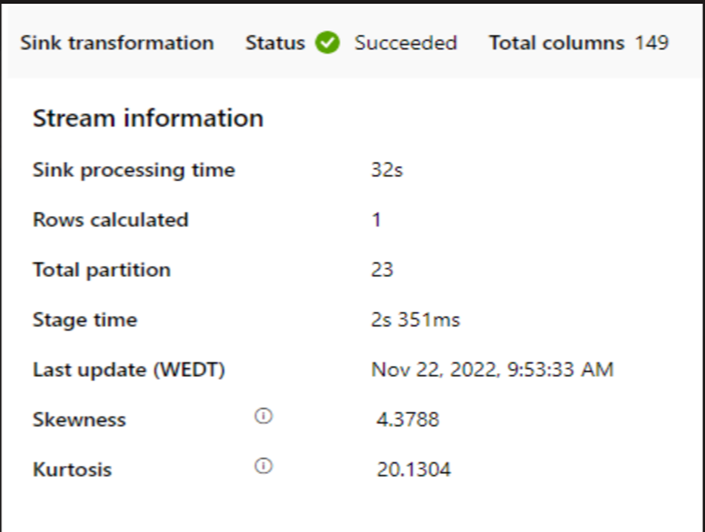
Als een klein cluster wordt gebruikt om de toewijzingsgegevensstroom uit te voeren, kan dit van invloed zijn op de prestaties in de sink. Gebruik een groot cluster, bijvoorbeeld 16 + 256 kernen, zodat de prestatie de gegevens uit de fase leest en naar de sink schrijft.
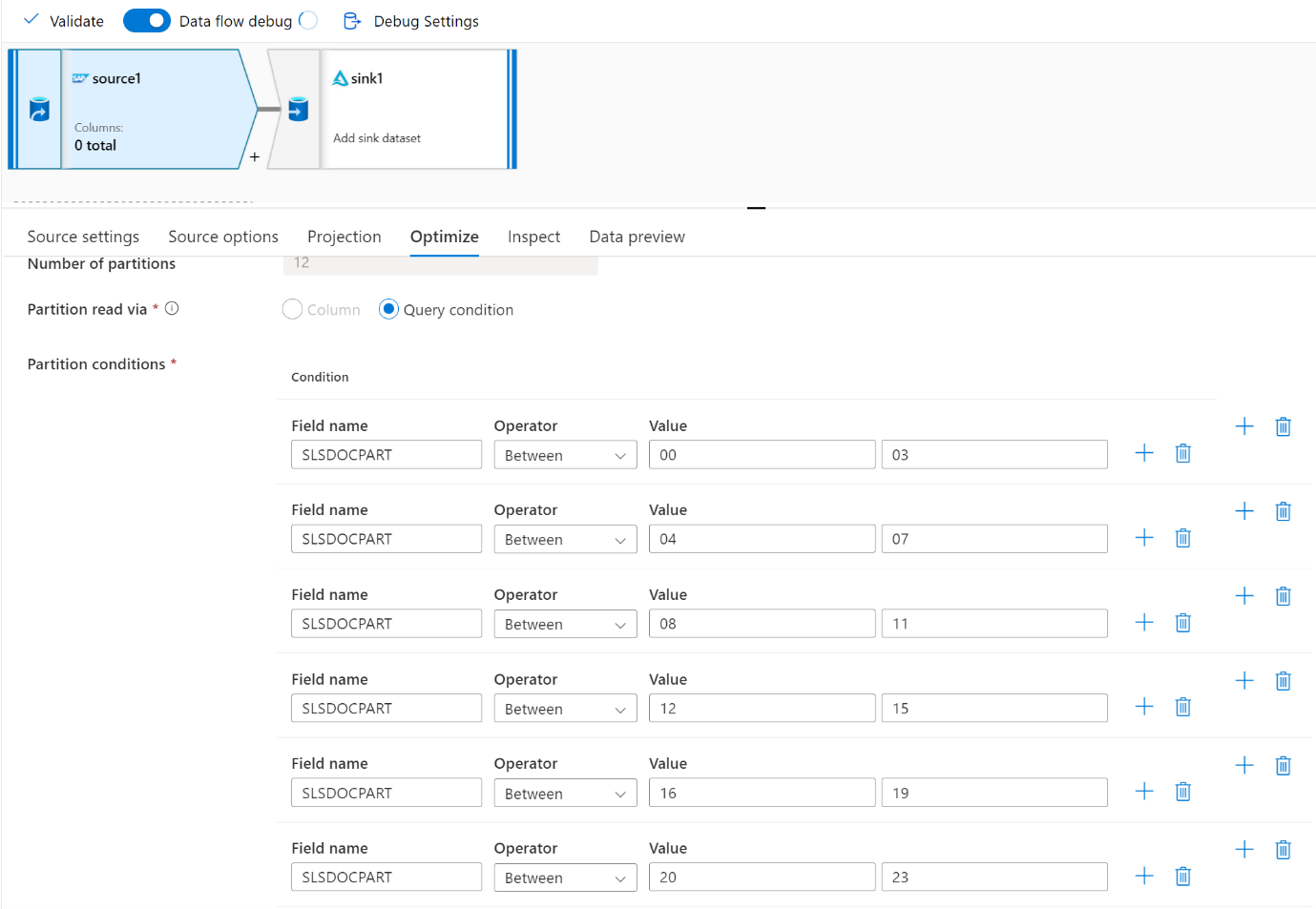
Voor grote gegevensvolumes raden we u aan de belasting te partitioneren om parallelle taken uit te voeren, maar het aantal partities kleiner dan of gelijk te houden aan de Azure IR-kern, ook wel de Spark-clusterkern genoemd.
Gebruik het tabblad Optimaliseren om de partities te definiëren. U kunt bronpartitionering gebruiken in de CDC-connector.
Notitie
- Er is een directe correlatie tussen het aantal partities met SHIR-kernen en Azure IR-knooppunten.
- De SAP CDC-connector wordt vermeld als Odata-abonneetype Odata-toegang voor operationele gegevensinrichting onder ODQMON in het SAP-systeem.
Ontwerpoverwegingen bij het gebruik van een tabelconnector
- Optimaliseer de partitionering voor betere prestaties.
- Bekijk de mate van parallelle uitvoering van SAP-tabel.
- Overweeg een enkel bestandsontwerp voor de doelsink.
- Benchmark de doorvoer wanneer u grote gegevensvolumes gebruikt.
Ontwerpaanbeveling bij het gebruik van een tabelconnector
Partitie: Wanneer u partitioneert in de SAP-tabelconnector, wordt één onderliggende select-instructie gesplitst in verschillende door gebruik te maken van waar-componenten zich in een geschikt veld bevinden, bijvoorbeeld een veld met een hoge kardinaliteit. Als uw SAP-tabel een grote hoeveelheid gegevens bevat, schakelt u partitionering in om de gegevens op te splitsen in kleinere partities. Probeer het aantal partities (parameter
maxPartitionsNumber) te optimaliseren, zodat de partities klein genoeg zijn om geheugendumps in SAP te voorkomen, maar groot genoeg om extractie te versnellen.Parallellisme: De mate van kopieerparallellisme (parameter
parallelCopies) werkt in combinatie met partitionering en instrueert de SHIR om parallelle RFC-aanroepen naar het SAP-systeem te maken. Als u deze parameter bijvoorbeeld instelt op 4, genereert en voert de service gelijktijdig vier query's uit op basis van de opgegeven partitieoptie en -instellingen. Elke query haalt een deel van de gegevens op uit uw SAP-tabel.Voor optimale resultaten moet het aantal partities een veelvoud zijn van het aantal van de mate van parallelle kopieerbewerking.
Wanneer u gegevens kopieert van SAP-tabel naar binaire sinks, wordt het werkelijke parallelle aantal automatisch aangepast op basis van de hoeveelheid geheugen die beschikbaar is in SHIR. Noteer de grootte van de SHIR-VM voor elke testcyclus, de mate van kopieerparallellisme en het aantal partities. Bekijk de prestaties van de SHIR-VM, de prestaties van het bron-SAP-systeem en de gewenste versus de werkelijke mate van parallelle uitvoering. Gebruik een iteratief proces om de optimale instellingen en de ideale grootte voor de SHIR-VM te identificeren. Houd rekening met alle opnamepijplijnen die tegelijkertijd gegevens laden vanuit een of meer SAP-systemen.
Let op het waargenomen aantal RFC-aanroepen naar SAP op basis van de geconfigureerde mate van parallelle uitvoering. Als het aantal RFC-aanroepen naar SAP kleiner is dan de mate van parallelle uitvoering, controleert u of de SHIR-VM voldoende geheugen en CPU-resources beschikbaar heeft. Kies indien nodig een grotere virtuele machine. Het bron-SAP-systeem is geconfigureerd om het aantal parallelle verbindingen te beperken. Zie de sectie Algemene aanbevelingen in dit artikel voor meer informatie.
Aantal bestanden: Wanneer u gegevens kopieert naar een gegevensarchief op basis van een bestand en de beoogde sink is geconfigureerd als een map, worden standaard meerdere bestanden gegenereerd. Als u de
fileNameeigenschap in de sink instelt, worden de gegevens naar één bestand geschreven. Het is raadzaam om naar een map te schrijven als meerdere bestanden, omdat hiermee een hogere schrijfdoorvoer wordt verkregen in vergelijking met het schrijven naar één bestand.Prestatiebenchmark: We raden u aan de oefening prestatiebenchmarking te gebruiken om grote hoeveelheden gegevens op te nemen. Deze methode varieert parameters, zoals partitionering, mate van parallelle uitvoering en het aantal bestanden om de optimale instelling voor de opgegeven architectuur, het volume en het type gegevens te bepalen. Verzamel gegevens van tests in de volgende indeling.


Problemen oplossen
Voor trage of mislukte extractie uit het SAP-systeem gebruikt u SAP-logboeken van SM37 en koppelt u deze aan de metingen in Data Factory.
Als er slechts één batchtaak wordt geactiveerd, stelt u de SAP-bronpartities in op prestatieverbetering in de toewijzingsgegevensstroom in Data Factory. Zie stap 6 in Eigenschappen van gegevensstroom toewijzen voor meer informatie.
Als er meerdere batchtaken worden geactiveerd in het SAP-systeem en er een aanzienlijk verschil is tussen de begintijd van elke batchtaak, wijzigt u de grootte van Azure IR. Wanneer u het aantal stuurprogrammaknooppunten in Azure IR verhoogt, neemt de parallelle uitvoering van batchtaken in de SAP-zijde toe.
Notitie
Het maximum aantal stuurprogrammaknooppunten voor Azure IR is 16. Elk stuurprogrammaknooppunt kan slechts één batchproces activeren.
Controleer de logboeken in SHIR. Als u logboeken wilt weergeven, gaat u naar SHIR VM. Open Logboeken > Toepassingen en servicelogboeken > Integratieruntime connectors > .
Als u logboeken naar de ondersteuning wilt verzenden, gaat u naar SHIR VM. Open de Integration Runtime Logboeken voor diagnostische > verzending van Configuration Manager>. Met deze actie worden de logboeken van de afgelopen zeven dagen verzonden en krijgt u een rapport-id. U hebt deze rapport-id en RunId van uw uitvoering nodig. Documenteer de rapport-id voor toekomstig gebruik.
Wanneer u de SAP CDC-connector gebruikt in een SLT-scenario:
Zorg ervoor dat aan de vereisten wordt voldaan. Rollen zijn vereist voor de gebruiker van SAP Landscape Transformation (SLT), bijvoorbeeld ADFSLTUSER in OLTP-systemen of ECC om SLT-replicatie te laten werken. Zie Welke autorisaties en rollen zijn nodig voor meer informatie.
Als er fouten optreden in een SLT-scenario, raadpleegt u de aanbevelingen voor analyse. Isoleer en test eerst het scenario binnen de SAP-oplossing. Test het bijvoorbeeld buiten Data Factory door het testprogramma van SAP
RODPS_REPL_TESTin SE38 uit te voeren. Als het probleem zich aan de SAP-zijde bevindt, krijgt u dezelfde fout wanneer u het rapport gebruikt. U kunt de gegevensextractie in SAP analyseren met behulp van de transactiecodeODQMON.Als de replicatie werkt wanneer u dit testrapport gebruikt, maar niet met Data Factory, neemt u contact op met de ondersteuning van Azure of Data Factory.
In het volgende voorbeeld ziet u een rapport voor
RODPS_REPL_TESTin SE38: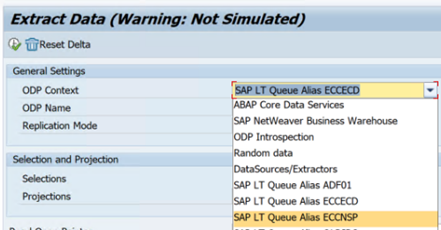
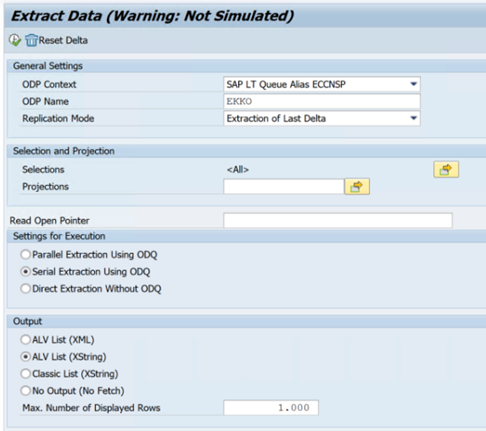

In het volgende voorbeeld ziet u de transactiecode
ODQMON: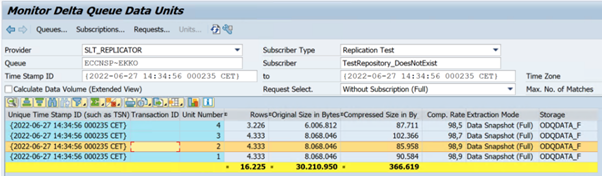
Wanneer de gekoppelde Data Factory-service verbinding maakt met het SLT-systeem, worden de SLT-id's voor massaoverdracht niet weergegeven wanneer u het veld Context vernieuwt.
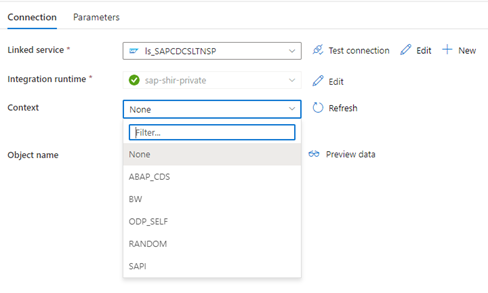
Als u het ODP-/ODQ-replicatiescenario voor de SAP LT-replicatieserver wilt uitvoeren, activeert u de volgende implementatie van de zakelijke invoegtoepassing (BAdI).
Badi:
BADI_ODQ_QUEUE_MODELVerbeterde implementatie:
ODQ_ENH_SLT_REPLICATIONGa in transactie LTRC naar het tabblad Expert-functie en selecteer BAdI-implementatie activeren/deactiveren om de implementatie te activeren.
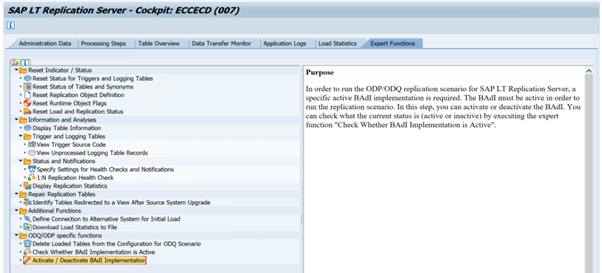
Selecteer Ja.
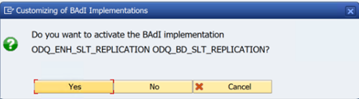
Selecteer in de map ODQ/ODP-specifieke functiescontroleren of BAdI-implementatie actief is.

In het dialoogvenster wordt de activiteit van het programma weergegeven.
Abonnementen opnieuw instellen. Als u wilt beginnen met een nieuwe extractie of replicatie wilt stoppen, verwijdert u het abonnement in de ODQMON. Met deze actie worden ook vermeldingen uit LTRC verwijderd. Nadat u het abonnement opnieuw hebt ingesteld, kan het enkele minuten duren voordat u het effect in LTRC ziet. Odp-schoonmaaktaken (Operational Data Provisioning) plannen om de deltawachtrijen schoon te houden, bijvoorbeeld
ODQ_CLEANUP_CLIENT_004CDS_VIEW (DHCDCMON-transactie). Vanaf S/4HANA 1909 repliceert SAP gegevens uit CDS-weergaven die gebruikmaken van op gegevens gebaseerde triggers in plaats van datumkolommen. Het concept is vergelijkbaar met SLT, maar in plaats van de LTRC-transactie te gebruiken om deze te bewaken, gebruikt u de DHCDCMON-transactie.
Problemen met SLT oplossen
SLT Replication Server biedt realtime gegevensreplicatie van SAP-bronnen en/of niet-SAP-bronnen naar SAP-doelen en/of niet-SAP-doelen. Er zijn drie soorten toolsets om de extractie van SLT naar Azure te bewaken.
- ODQMON is het algemene bewakingsprogramma voor gegevensextractie. Start de analyse met ODQMON om inconsistenties in gegevens bij te houden, de initiële prestatieanalyse en open abonnements- en extractieaanvragen.
- LTRC is de transactie die moet worden gebruikt om de prestatieanalyse te controleren. Dit is handig als u problemen hebt met gegevensreplicatie van het bronsysteem naar ODP, omdat u de gegevensstroom kunt bewaken en inconsistenties kunt vinden.
- SM37 biedt gedetailleerde bewaking van elke SLT-extractiestap.
De normale huishouding moet worden gedaan met behulp van ODQMON, waar u het abonnement rechtstreeks kunt beheren en u mag LTRC niet gebruiken voor hetzelfde.
U kunt problemen ondervinden bij het extraheren van gegevens uit SLT, zoals:
De extractie wordt niet uitgevoerd. Controleer of de SAP CDC-verbinding een verbinding heeft gemaakt in ODQMON en controleer of het abonnement bestaat.
Gegevens inconsistenties. Controleer ODQMON om de afzonderlijke aanvraag van gegevens te bekijken en controleer of u daar gegevens kunt zien. Als u de gegevens wel in ODQMON ziet, maar niet in Azure Synapse of Data Factory, moet het onderzoek aan de Azure-zijde worden uitgevoerd. Als u de gegevens niet kunt zien in ODQMON, voert u een analyse van het SLT-framework uit met behulp van LTRC.
Prestatieproblemen. Gegevensextractie is een benadering in twee stappen. Eerst leest SLT gegevens uit het bronsysteem en draagt deze over naar ODP. Ten tweede haalt de SAP CDC-connector de gegevens op van ODP en draagt deze over naar het gekozen gegevensarchief. Met de LTRC-transactie kunt u het eerste deel van het extractieproces analyseren. Als u de gegevensextractie van ODP naar Azure wilt analyseren, gebruikt u ODQMON and Data Factory of Synapse-bewakingshulpprogramma's.
Notitie
Zie deze resources voor meer informatie:
SLT-prestaties
In de initiële laadmodus (ODPSLT) zijn er drie stappen om gegevens uit SLT naar ODP te extraheren:
- Migratieobjecten maken. Dit proces duurt slechts een paar seconden.
- Toegang tot de planberekening waarmee de brontabel wordt gesplitst in kleinere segmenten. Deze stap is afhankelijk van de initiële laadmodus die u selecteert tijdens de SLT-configuratie en de grootte van de tabel. De optie voor geoptimaliseerde resources wordt aanbevolen.
- De gegevensbelasting draagt de gegevens over van het bronsysteem naar ODP.
Elke stap wordt bepaald door de achtergrondtaken. U kunt de SM37- en LTRC-transacties gebruiken om de duur te controleren. Als uw systeem te veel wordt gebruikt, worden de achtergrondtaken mogelijk later gestart omdat er onvoldoende vrije batchwerkprocessen zijn. Wanneer taken niet actief zijn, gaan de prestaties achteruit.
Als de berekening van het toegangsplan lang duurt en uw initiële belastingsmodus is ingesteld op 'geoptimaliseerd voor prestaties', wijzigt u deze in 'geoptimaliseerd voor resources' en voert u de extractie opnieuw uit. Als het laden van gegevens lang duurt, verhoogt u het aantal parallelle threads in de configuratie.
Als u een zelfstandige architectuur gebruikt voor SLT-replicatie (toegewezen SLT-replicatieserver), kan de netwerkdoorvoer tussen het bronsysteem en de replicatieserver van invloed zijn op de extractieprestaties.
Voor replicatie:
- Zorg ervoor dat u voldoende taken voor gegevensoverdracht hebt die niet zijn gereserveerd voor de eerste belasting.
- Controleer of u geen onverwerkte logboekregistratietabelrecord in de belastingsstatistieken hebt.
- Zorg ervoor dat de replicatieoptie is ingesteld op realtime.
Geavanceerde replicatie-instellingen zijn beschikbaar in LTRS. Zie de handleiding voor het oplossen van problemen met SLT voor meer informatie.
Verschillende SAP-releases hebben verschillende LTRC-gebruikersinterfaces. In de volgende schermopnamen wordt dezelfde pagina weergegeven voor twee verschillende releases.
SAP S/4HANA:

SAP ECC:



Monitor
Zie de volgende resources voor informatie over het bewaken van sap-gegevensextractie:
Volgende stappen
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor