Wat is de analytische opslag van Azure Cosmos DB?
VAN TOEPASSING OP: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Gremlin
Gremlin
Belangrijk
Spiegeling van Azure Cosmos DB in Microsoft Fabric is nu beschikbaar voor NoSql-API. Deze functie biedt alle mogelijkheden van Azure Synapse Link met betere analytische prestaties, de mogelijkheid om uw gegevensdomein te combineren met Fabric OneLake en open toegang tot uw gegevens in Delta Parquet-indeling. Als u Azure Synapse Link overweegt, raden we u aan om spiegeling uit te voeren om de algehele geschiktheid voor uw organisatie te beoordelen. Aan de slag met spiegeling in Microsoft Fabric.
Ga naar 'Aan de slag met Azure Synapse Link' om aan de slag te gaan met Azure Synapse Link
Analytische opslag van Azure Cosmos DB is een volledig geïsoleerd kolomarchief voor het inschakelen van grootschalige analyses op basis van operationele gegevens in uw Azure Cosmos DB, zonder dat dit van invloed is op uw transactionele workloads.
Transactionele opslag van Azure Cosmos DB is schemaneutraal en hiermee kunt u uw transactionele toepassingen herhalen zonder dat u te maken hebt met schema- of indexbeheer. In tegenstelling tot dit wordt analytische opslag van Azure Cosmos DB geschematiseerd om te optimaliseren voor analytische queryprestaties. In dit artikel wordt gedetailleerde informatie over analytische opslag beschreven.
Uitdagingen met grootschalige analyses op operationele gegevens
De operationele gegevens met meerdere modellen in een Azure Cosmos DB-container worden intern opgeslagen in een geïndexeerd 'transactioneel archief'. De indeling van het rijarchief is ontworpen om snelle transactionele lees- en schrijfbewerkingen in de reactietijden van milliseconden en operationele query's mogelijk te maken. Als uw gegevensset groot wordt, kunnen complexe analytische query's duur zijn in termen van ingerichte doorvoer op de gegevens die in deze indeling zijn opgeslagen. Een hoog verbruik van ingerichte doorvoer heeft op zijn beurt invloed op de prestaties van transactionele workloads die worden gebruikt door uw realtime toepassingen en services.
Normaal gesproken worden operationele gegevens geëxtraheerd uit het transactionele archief van Azure Cosmos DB en opgeslagen in een afzonderlijke gegevenslaag om grote hoeveelheden gegevens te analyseren. De gegevens worden bijvoorbeeld opgeslagen in een datawarehouse of data lake in een geschikte indeling. Deze gegevens worden later gebruikt voor grootschalige analyses en geanalyseerd met behulp van rekenprogramma's zoals de Apache Spark-clusters. De scheiding van analytische gegevens resulteert in vertragingen voor analisten die de meest recente gegevens willen gebruiken.
De ETL-pijplijnen worden ook complex bij het verwerken van updates van de operationele gegevens in vergelijking met het verwerken van alleen nieuw opgenomen operationele gegevens.
Kolomgeoriënteerde analytische opslag
Analytische opslag van Azure Cosmos DB heeft betrekking op de complexiteit en latentieproblemen die optreden met de traditionele ETL-pijplijnen. Analytische opslag van Azure Cosmos DB kan uw operationele gegevens automatisch synchroniseren in een afzonderlijk kolomarchief. De kolomopslagindeling is geschikt voor grootschalige analytische query's die op een geoptimaliseerde manier moeten worden uitgevoerd, wat resulteert in het verbeteren van de latentie van dergelijke query's.
Met behulp van Azure Synapse Link kunt u nu no-ETL HTAP-oplossingen bouwen door rechtstreeks vanuit Azure Synapse Analytics te koppelen aan de analytische opslag van Azure Cosmos DB. Hiermee kunt u bijna realtime grootschalige analyses uitvoeren op uw operationele gegevens.
Functies van analytische opslag
Wanneer u analytische opslag inschakelt in een Azure Cosmos DB-container, wordt er intern een nieuw kolomarchief gemaakt op basis van de operationele gegevens in uw container. Dit kolomarchief wordt afzonderlijk van het transactionele archief met rijen voor die container bewaard, in een opslagaccount dat volledig wordt beheerd door Azure Cosmos DB, in een intern abonnement. Klanten hoeven geen tijd te besteden aan opslagbeheer. De invoegingen, updates en verwijderingen naar uw operationele gegevens worden automatisch gesynchroniseerd met analytische opslag. U hebt de wijzigingenfeed of ETL niet nodig om de gegevens te synchroniseren.
Kolomarchief voor analytische workloads op operationele gegevens
Analytische workloads omvatten doorgaans aggregaties en sequentiële scans van geselecteerde velden. De analytische gegevensopslag wordt opgeslagen in een kolomvolgorde, zodat waarden van elk veld, indien van toepassing, samen kunnen worden geserialiseerd. Deze indeling vermindert de IOPS die nodig zijn voor het scannen of berekenen van statistieken over specifieke velden. Het verbetert de reactietijden van query's aanzienlijk voor scans via grote gegevenssets.
Als uw operationele tabellen bijvoorbeeld de volgende indeling hebben:
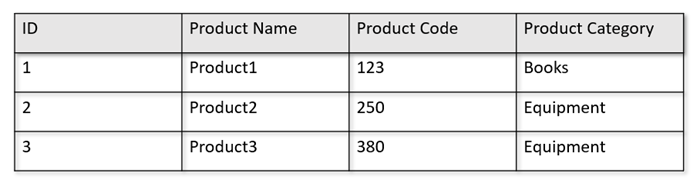
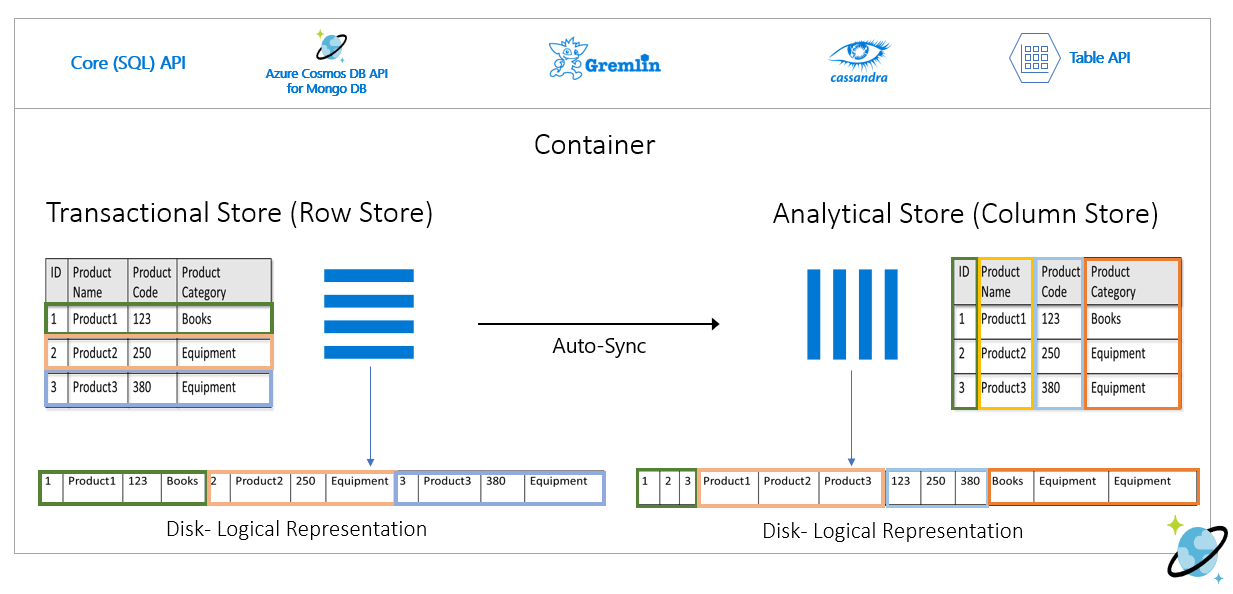
Het rijarchief bewaart de bovenstaande gegevens in een geserialiseerde indeling, per rij, op de schijf. Met deze indeling kunt u sneller transactionele leesbewerkingen, schrijfbewerkingen en operationele query's uitvoeren, zoals 'Retourinformatie over Product 1'. Naarmate de gegevensset echter groot wordt en als u complexe analytische query's wilt uitvoeren op de gegevens, kan dit duur zijn. Als u bijvoorbeeld 'de verkooptrends voor een product onder de categorie Apparatuur' in verschillende bedrijfseenheden en maanden wilt ophalen, moet u een complexe query uitvoeren. Grote scans op deze gegevensset kunnen duur worden in termen van ingerichte doorvoer en kunnen ook van invloed zijn op de prestaties van de transactionele workloads die uw realtime toepassingen en services mogelijk maken.
Analytische opslag, een kolomarchief, is beter geschikt voor dergelijke query's, omdat hiermee vergelijkbare velden met gegevens worden geserialiseerd en de schijf-IOPS worden verminderd.
In de volgende afbeelding ziet u transactionele rijopslag versus analytische kolomopslag in Azure Cosmos DB:
Losgekoppelde prestaties voor analytische workloads
Er is geen invloed op de prestaties van uw transactionele workloads vanwege analytische query's, omdat de analytische opslag losstaat van het transactionele archief. Voor analytische opslag hoeven geen afzonderlijke aanvraageenheden (RU's) te worden toegewezen.
Automatische synchronisatie
Automatische synchronisatie verwijst naar de volledig beheerde functionaliteit van Azure Cosmos DB, waarbij de invoegingen, updates, verwijderingen naar operationele gegevens automatisch worden gesynchroniseerd van transactionele opslag naar analytische opslag in bijna realtime. De latentie voor automatische synchronisatie is meestal binnen 2 minuten. In het geval van een gedeelde doorvoerdatabase met een groot aantal containers, kan de latentie van automatische synchronisatie van afzonderlijke containers hoger zijn en kan het tot vijf minuten duren.
Aan het einde van elke uitvoering van het automatische synchronisatieproces zijn uw transactionele gegevens onmiddellijk beschikbaar voor Azure Synapse Analytics-runtimes:
Azure Synapse Analytics Spark-pools kunnen alle gegevens lezen, inclusief de meest recente updates, via Spark-tabellen, die automatisch worden bijgewerkt of via de
spark.readopdracht, die altijd de laatste status van de gegevens leest.Serverloze Azure Synapse Analytics SQL-pools kunnen alle gegevens lezen, inclusief de meest recente updates, via weergaven, die automatisch worden bijgewerkt of via
SELECTdeOPENROWSETopdrachten, die altijd de meest recente status van de gegevens lezen.
Notitie
Uw transactionele gegevens worden gesynchroniseerd met analytische opslag, zelfs als uw transactionele time-to-live (TTL) kleiner is dan 2 minuten.
Notitie
Houd er rekening mee dat als u uw container verwijdert, ook analytische opslag wordt verwijderd.
Schaalbaarheid en elasticiteit
Azure Cosmos DB transactionele opslag maakt gebruik van horizontale partitionering om de opslag en doorvoer elastisch te schalen zonder uitvaltijd. Horizontale partitionering in het transactionele archief biedt schaalbaarheid en elasticiteit in automatische synchronisatie om ervoor te zorgen dat gegevens in bijna realtime worden gesynchroniseerd met de analytische opslag. De gegevenssynchronisatie vindt plaats ongeacht de transactionele verkeersdoorvoer, ongeacht of dit 1000 bewerkingen per seconde of 1 miljoen bewerkingen per seconde is en dit niet van invloed is op de ingerichte doorvoer in het transactionele archief.
Schema-updates automatisch verwerken
Transactionele opslag van Azure Cosmos DB is schemaneutraal en hiermee kunt u uw transactionele toepassingen herhalen zonder dat u te maken hebt met schema- of indexbeheer. In tegenstelling tot dit wordt analytische opslag van Azure Cosmos DB geschematiseerd om te optimaliseren voor analytische queryprestaties. Met de functie voor automatische synchronisatie beheert Azure Cosmos DB de schemadeductie over de meest recente updates uit het transactionele archief. Het beheert ook de schemaweergave in de analytische opslag out-of-the-box, waaronder het verwerken van geneste gegevenstypen.
Naarmate uw schema zich ontwikkelt en er na verloop van tijd nieuwe eigenschappen worden toegevoegd, wordt in de analytische opslag automatisch een samengevoegd schema weergegeven voor alle historische schema's in de transactionele opslag.
Notitie
In de context van analytische opslag beschouwen we de volgende structuren als eigenschap:
- JSON-elementen of tekenreeks-waardeparen gescheiden door een
:". - JSON-objecten, gescheiden door
{en}. - JSON-matrices, gescheiden door
[en].
Schemabeperkingen
De volgende beperkingen zijn van toepassing op de operationele gegevens in Azure Cosmos DB wanneer u analytische opslag inschakelt om het schema automatisch af te leiden en correct weer te geven:
U kunt maximaal 1000 eigenschappen hebben voor alle geneste niveaus in het documentschema en een maximale nestdiepte van 127.
- Alleen de eerste 1000 eigenschappen worden weergegeven in de analytische opslag.
- Alleen de eerste 127 geneste niveaus worden weergegeven in de analytische opslag.
- Het eerste niveau van een JSON-document is het
/hoofdniveau. - Eigenschappen op het eerste niveau van het document worden weergegeven als kolommen.
Voorbeeldscenario's:
- Als het eerste niveau van uw document 2000 eigenschappen heeft, vertegenwoordigt het synchronisatieproces de eerste 1000.
- Als uw documenten vijf niveaus met 200 eigenschappen in elk niveau hebben, vertegenwoordigt het synchronisatieproces alle eigenschappen.
- Als uw documenten 10 niveaus met 400 eigenschappen in elk niveau hebben, vertegenwoordigt het synchronisatieproces de twee eerste niveaus en slechts de helft van het derde niveau.
Het onderstaande hypothetische document bevat vier eigenschappen en drie niveaus.
- De niveaus zijn
root,myArrayen de geneste structuur binnen demyArray. - De eigenschappen zijn
id,myArray, enmyArray.nested1myArray.nested2. - De weergave van de analytische opslag heeft twee kolommen,
idenmyArray. U kunt Spark- of T-SQL-functies gebruiken om de geneste structuren ook beschikbaar te maken als kolommen.
- De niveaus zijn
{
"id": "1",
"myArray": [
"string1",
"string2",
{
"nested1": "abc",
"nested2": "cde"
}
]
}
Hoewel JSON-documenten (en Azure Cosmos DB-verzamelingen/-containers) hoofdlettergevoelig zijn vanuit het perspectief van uniekheid, is analytische opslag dat niet.
- In hetzelfde document: Eigenschappennamen op hetzelfde niveau moeten uniek zijn wanneer ze niet hoofdlettergevoelig worden vergeleken. Het volgende JSON-document heeft bijvoorbeeld 'Naam' en 'naam' op hetzelfde niveau. Hoewel het een geldig JSON-document is, voldoet het niet aan de beperking voor uniekheid en wordt het daarom niet volledig weergegeven in de analytische opslag. In dit voorbeeld zijn 'Naam' en 'naam' hetzelfde wanneer ze op een niet-hoofdlettergevoelige manier worden vergeleken. Alleen
"Name": "fred"worden weergegeven in analytische opslag, omdat dit het eerste exemplaar is. En"name": "john"wordt helemaal niet vertegenwoordigd.
{"id": 1, "Name": "fred", "name": "john"}- In verschillende documenten: Eigenschappen op hetzelfde niveau en met dezelfde naam, maar in verschillende gevallen, worden weergegeven in dezelfde kolom, met behulp van de naamnotatie van het eerste exemplaar. De volgende JSON-documenten hebben
"Name"bijvoorbeeld en"name"op hetzelfde niveau. Aangezien de eerste documentindeling is"Name", wordt dit gebruikt om de naam van de eigenschap in analytische opslag weer te geven. Met andere woorden, de kolomnaam in de analytische opslag is"Name"."john"Beide"fred"en worden weergegeven in de"Name"kolom.
{"id": 1, "Name": "fred"} {"id": 2, "name": "john"}- In hetzelfde document: Eigenschappennamen op hetzelfde niveau moeten uniek zijn wanneer ze niet hoofdlettergevoelig worden vergeleken. Het volgende JSON-document heeft bijvoorbeeld 'Naam' en 'naam' op hetzelfde niveau. Hoewel het een geldig JSON-document is, voldoet het niet aan de beperking voor uniekheid en wordt het daarom niet volledig weergegeven in de analytische opslag. In dit voorbeeld zijn 'Naam' en 'naam' hetzelfde wanneer ze op een niet-hoofdlettergevoelige manier worden vergeleken. Alleen
Het eerste document van de verzameling definieert het initiële analytische opslagschema.
- Documenten met meer eigenschappen dan het eerste schema genereert nieuwe kolommen in analytische opslag.
- Kolommen kunnen niet worden verwijderd.
- Als alle documenten in een verzameling worden verwijderd, wordt het schema voor analytische opslag niet opnieuw ingesteld.
- Er is geen schemaversiebeheer. De laatste versie die is afgeleid van transactionele opslag, is wat u ziet in de analytische opslag.
Momenteel kunnen in Azure Synapse Spark geen eigenschappen worden gelezen die enkele speciale tekens in hun namen bevatten, zoals hieronder wordt vermeld. Serverloze Azure Synapse SQL wordt niet beïnvloed.
- :
- `
- ,
- ;
- {}
- ()
- \n
- \t
- =
- "
Notitie
Spaties worden ook weergegeven in het Spark-foutbericht dat wordt geretourneerd wanneer u deze beperking bereikt. Maar we hebben een speciale behandeling toegevoegd voor witruimtes, bekijk meer informatie in de onderstaande items.
- Als u eigenschappennamen hebt met behulp van de bovenstaande tekens, zijn de alternatieven:
- Wijzig uw gegevensmodel van tevoren om deze tekens te voorkomen.
- Omdat we momenteel geen ondersteuning bieden voor het opnieuw instellen van schema's, kunt u uw toepassing wijzigen om een redundante eigenschap met een vergelijkbare naam toe te voegen, waardoor deze tekens worden vermeden.
- Gebruik De wijzigingenfeed om een gerealiseerde weergave van uw container te maken zonder deze tekens in eigenschappennamen.
- Gebruik de Spark-optie
dropColumnom de betreffende kolommen te negeren en alle andere kolommen in een DataFrame te laden. De syntaxis is:
# Removing one column:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName")\
.load()
# Removing multiple columns:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName;StreetName,StreetNumber")\
.option("spark.cosmos.dropMultiColumnSeparator", ";")\
.load()
- Azure Synapse Spark ondersteunt nu eigenschappen met spaties in hun naam. Hiervoor moet u de
allowWhiteSpaceInFieldNamesSpark-optie gebruiken om de betreffende kolommen in een DataFrame te laden, waarbij de oorspronkelijke naam behouden blijft. De syntaxis is:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.allowWhiteSpaceInFieldNames", "true")\
.load()
De volgende BSON-gegevenstypen worden niet ondersteund en worden niet weergegeven in de analytische opslag:
- Decimal128
- Gewone expressie
- DB-aanwijzer
- JavaScript
- Symbool
- MinKey/MaxKey
Wanneer u DateTime-tekenreeksen gebruikt die voldoen aan de ISO 8601 UTC-standaard, verwacht u het volgende gedrag:
- Spark-pools in Azure Synapse vertegenwoordigen deze kolommen als
string. - Serverloze SQL-pools in Azure Synapse vertegenwoordigen deze kolommen als
varchar(8000).
- Spark-pools in Azure Synapse vertegenwoordigen deze kolommen als
Eigenschappen met
UNIQUEIDENTIFIER (guid)typen worden weergegeven alsstringin analytische opslag en moeten worden geconverteerd naarVARCHARin SQL of instringSpark voor de juiste visualisatie.Serverloze SQL-pools in Azure Synapse ondersteunen resultatensets met maximaal 1000 kolommen en het beschikbaar maken van geneste kolommen telt ook mee voor die limiet. Het is een goede gewoonte om deze informatie in uw transactionele gegevensarchitectuur en modellering te overwegen.
Als u de naam van een eigenschap wijzigt, wordt deze in een of meer documenten beschouwd als een nieuwe kolom. Als u dezelfde naam in alle documenten in de verzameling uitvoert, worden alle gegevens gemigreerd naar de nieuwe kolom en wordt de oude kolom weergegeven met
NULLwaarden.
Schemarepresentatie
Er zijn twee methoden voor schemaweergave in de analytische opslag, geldig voor alle containers in het databaseaccount. Ze hebben een compromis tussen de eenvoud van query-ervaring versus het gemak van een inclusievere kolomweergave voor polymorfe schema's.
- Goed gedefinieerde schemaweergave, standaardoptie voor API voor NoSQL- en Gremlin-accounts.
- Schemaweergave met volledige betrouwbaarheid, standaardoptie voor API voor MongoDB-accounts.
Goed gedefinieerde schemaweergave
De goed gedefinieerde schemaweergave maakt een eenvoudige tabelweergave van de schemaagnostische gegevens in het transactionele archief. De goed gedefinieerde schemaweergave heeft de volgende overwegingen:
- Het eerste document definieert het basisschema en de eigenschappen moeten altijd hetzelfde type hebben voor alle documenten. De enige uitzonderingen zijn:
- Van
NULLnaar elk ander gegevenstype. Het eerste niet-null-exemplaar definieert het kolomgegevenstype. Een document dat niet het eerste niet-null-gegevenstype volgt, wordt niet weergegeven in de analytische opslag. - Van
floatininteger. Alle documenten worden weergegeven in analytische opslag. - Van
integerinfloat. Alle documenten worden weergegeven in analytische opslag. Als u deze gegevens echter wilt lezen met serverloze Azure Synapse SQL-pools, moet u een WITH-component gebruiken om de kolom te converteren naarvarchar. En na deze initiële conversie is het mogelijk om deze opnieuw te converteren naar een getal. Controleer het onderstaande voorbeeld, waarbij de aanvankelijke getalwaarde een geheel getal was en de tweede een float was.
- Van
SELECT CAST (num as float) as num
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
)
WITH (num varchar(100)) AS [IntToFloat]
Eigenschappen die niet voldoen aan het gegevenstype basisschema, worden niet weergegeven in de analytische opslag. Bekijk bijvoorbeeld de onderstaande documenten: het eerste document dat het basisschema van de analytische opslag heeft gedefinieerd. Het tweede document, waar
idis"2", heeft geen goed gedefinieerd schema, omdat de eigenschap"code"een tekenreeks is en het eerste document als een getal heeft"code". In dit geval registreert de analytische opslag het gegevenstype van"code"deintegerlevensduur van de container. Het tweede document wordt nog steeds opgenomen in de analytische opslag, maar"code"de eigenschap ervan niet.{"id": "1", "code":123}{"id": "2", "code": "123"}
Notitie
De bovenstaande voorwaarde is niet van toepassing op NULL eigenschappen. Is bijvoorbeeld {"a":123} and {"a":NULL} nog goed gedefinieerd.
Notitie
De bovenstaande voorwaarde verandert niet als u het document "1" bijwerkt "code" naar een tekenreeks in uw transactionele archief. In analytische opslag "code" wordt bewaard, omdat integer we momenteel geen ondersteuning bieden voor het opnieuw instellen van schema's.
- Matrixtypen moeten één herhaald type bevatten. Is bijvoorbeeld
{"a": ["str",12]}geen goed gedefinieerd schema omdat de matrix een combinatie van gehele getallen en tekenreekstypen bevat.
Notitie
Als de analytische opslag van Azure Cosmos DB de goed gedefinieerde schemaweergave volgt en de bovenstaande specificatie wordt geschonden door bepaalde items, worden deze items niet opgenomen in de analytische opslag.
Verwacht ander gedrag met betrekking tot verschillende typen in goed gedefinieerd schema:
- Spark-pools in Azure Synapse vertegenwoordigen deze waarden als
undefined. - Serverloze SQL-pools in Azure Synapse vertegenwoordigen deze waarden als
NULL.
- Spark-pools in Azure Synapse vertegenwoordigen deze waarden als
U kunt verschillende gedragingen verwachten met betrekking tot expliciete
NULLwaarden:- Spark-pools in Azure Synapse lezen deze waarden als
0(nul) en zodraundefinedde kolom een niet-null-waarde heeft. - Serverloze SQL-pools in Azure Synapse lezen deze waarden als
NULL.
- Spark-pools in Azure Synapse lezen deze waarden als
Verwacht ander gedrag met betrekking tot ontbrekende kolommen:
- Spark-pools in Azure Synapse vertegenwoordigen deze kolommen als
undefined. - Serverloze SQL-pools in Azure Synapse vertegenwoordigen deze kolommen als
NULL.
- Spark-pools in Azure Synapse vertegenwoordigen deze kolommen als
Tijdelijke oplossingen voor representatieproblemen
Het is mogelijk dat een oud document, met een onjuist schema, is gebruikt om het basisschema voor analytische opslag van uw container te maken. Op basis van alle bovenstaande regels ontvangt u mogelijk NULL bepaalde eigenschappen bij het uitvoeren van query's op uw analytische opslag met behulp van Azure Synapse Link. Als u de problematische documenten wilt verwijderen of bijwerken, helpt dit niet omdat het basisschema momenteel niet wordt ondersteund. De mogelijke oplossingen zijn:
- Als u de gegevens naar een nieuwe container wilt migreren, moet u ervoor zorgen dat alle documenten het juiste schema hebben.
- Als u de eigenschap met het verkeerde schema wilt verlaten en een nieuwe wilt toevoegen met een andere naam met het juiste schema in alle documenten. Voorbeeld: U hebt miljarden documenten in de container Orders , waarbij de statuseigenschap een tekenreeks is. Maar het eerste document in die container heeft de status gedefinieerd met een geheel getal. Het ene document heeft dus de status correct weergegeven en alle andere documenten hebben
NULL. U kunt de eigenschap status2 toevoegen aan alle documenten en deze gaan gebruiken in plaats van de oorspronkelijke eigenschap.
Schemaweergave voor volledige betrouwbaarheid
De weergave van het schema voor volledige betrouwbaarheid is ontworpen om de volledige breedte van polymorfe schema's in de schemaagnostische operationele gegevens te verwerken. In deze schemaweergave worden er geen items verwijderd uit de analytische opslag, zelfs als de goed gedefinieerde schemabeperkingen (dat geen velden met gemengde gegevenstypen of gemengde gegevenstypematrices zijn) worden geschonden.
Dit wordt bereikt door de bladeigenschappen van de operationele gegevens in de analytische opslag te vertalen als JSON-paren key-value , waarbij het gegevenstype het key is en de eigenschapsinhoud de value. Met deze JSON-objectweergave kunnen query's zonder dubbelzinnigheid worden uitgevoerd en kunt u elk gegevenstype afzonderlijk analyseren.
Met andere woorden, in de weergave van het schema voor volledige betrouwbaarheid genereert elk gegevenstype van elke eigenschap van elk document een key-valuepaar in een JSON-object voor die eigenschap. Ze tellen elk als een van de limiet van 1000 maximumeigenschappen.
Laten we bijvoorbeeld het volgende voorbeelddocument in het transactionele archief nemen:
{
name: "John Doe",
age: 32,
profession: "Doctor",
address: {
streetNo: 15850,
streetName: "NE 40th St.",
zip: 98052
},
salary: 1000000
}
Het geneste object address is een eigenschap op het hoofdniveau van het document en wordt weergegeven als een kolom. Elke bladeigenschap in het address object wordt weergegeven als een JSON-object: {"object":{"streetNo":{"int32":15850},"streetName":{"string":"NE 40th St."},"zip":{"int32":98052}}}.
In tegenstelling tot de goed gedefinieerde schemaweergave biedt de methode volledige betrouwbaarheid variatie in gegevenstypen. Als het volgende document in deze verzameling van het bovenstaande voorbeeld een tekenreeks heeft streetNo , wordt het als analytische opslag weergegeven als "streetNo":{"string":15850}. In een goed gedefinieerde schemamethode zou deze niet worden weergegeven.
Toewijzing van gegevenstypen voor schema met volledige betrouwbaarheid
Hier volgt een kaart van MongoDB-gegevenstypen en hun representaties in de analytische opslag in schemaweergave met volledige betrouwbaarheid. De onderstaande kaart is niet geldig voor NoSQL-API-accounts.
| Oorspronkelijk gegevenstype | Achtervoegsel | Opmerking |
|---|---|---|
| Dubbel | ".float64" | 24.99 |
| Matrix | ".array" | ["a", "b"] |
| Binary | ".binary" | 0 |
| Booleaanse waarde | ".bool" | Waar |
| Int32 | ".int32" | 123 |
| Int64 | ".int64" | 255486129307 |
| NULL | ". NULL" | NULL |
| String | ".string" | "ABC" |
| Tijdstempel | ".timestamp" | Tijdstempel(0, 0) |
| ObjectId | ".objectId" | ObjectId("5f3f7b59330ec25c132623a2") |
| Document | ".object" | {"a": "a"} |
U kunt verschillende gedragingen verwachten met betrekking tot expliciete
NULLwaarden:- Spark-pools in Azure Synapse lezen deze waarden als
0(nul). - Serverloze SQL-pools in Azure Synapse lezen deze waarden als
NULL.
- Spark-pools in Azure Synapse lezen deze waarden als
Verwacht ander gedrag met betrekking tot ontbrekende kolommen:
- Spark-pools in Azure Synapse vertegenwoordigen deze kolommen als
undefined. - Serverloze SQL-pools in Azure Synapse vertegenwoordigen deze kolommen als
NULL.
- Spark-pools in Azure Synapse vertegenwoordigen deze kolommen als
U kunt verschillende gedragingen verwachten met betrekking tot
timestampwaarden:- Spark-pools in Azure Synapse lezen deze waarden als
TimestampType,DateTypeofFloat. Dit is afhankelijk van het bereik en hoe de tijdstempel is gegenereerd. - Serverloze SQL-pools in Azure Synapse lezen deze waarden als
DATETIME2, variërend van tot9999-12-31en met0001-01-01. Waarden buiten dit bereik worden niet ondersteund en veroorzaken een uitvoeringsfout voor uw query's. Als dit uw geval is, kunt u het volgende doen:- Verwijder de kolom uit de query. Als u de weergave wilt behouden, kunt u een nieuwe eigenschap maken die deze kolom spiegelt, maar binnen het ondersteunde bereik. En gebruik deze in uw query's.
- Gebruik Change Data Capture uit analytische opslag, zonder kosten voor RU's, om de gegevens te transformeren en te laden in een nieuwe indeling, binnen een van de ondersteunde sinks.
- Spark-pools in Azure Synapse lezen deze waarden als
Schema voor volledige betrouwbaarheid gebruiken met Spark
Spark beheert elk gegevenstype als een kolom bij het laden in een DataFrame. We gaan ervan uit dat een verzameling met de onderstaande documenten wordt verzameld.
{
"_id" : "1" ,
"item" : "Pizza",
"price" : 3.49,
"rating" : 3,
"timestamp" : 1604021952.6790195
},
{
"_id" : "2" ,
"item" : "Ice Cream",
"price" : 1.59,
"rating" : "4" ,
"timestamp" : "2022-11-11 10:00 AM"
}
Hoewel het eerste document een getal en utc-indeling heeftrating, heeft rating het tweede document en timestamp als tekenreeksen.timestamp Ervan uitgaande dat deze verzameling zonder gegevenstransformatie is geladen DataFrame , is de uitvoer van het df.printSchema() volgende:
root
|-- _rid: string (nullable = true)
|-- _ts: long (nullable = true)
|-- id: string (nullable = true)
|-- _etag: string (nullable = true)
|-- _id: struct (nullable = true)
| |-- objectId: string (nullable = true)
|-- item: struct (nullable = true)
| |-- string: string (nullable = true)
|-- price: struct (nullable = true)
| |-- float64: double (nullable = true)
|-- rating: struct (nullable = true)
| |-- int32: integer (nullable = true)
| |-- string: string (nullable = true)
|-- timestamp: struct (nullable = true)
| |-- float64: double (nullable = true)
| |-- string: string (nullable = true)
|-- _partitionKey: struct (nullable = true)
| |-- string: string (nullable = true)
In goed gedefinieerde schemaweergave zouden beide rating en timestamp van het tweede document niet worden weergegeven. In het schema voor volledige betrouwbaarheid kunt u de volgende voorbeelden gebruiken om afzonderlijk toegang te krijgen tot elke waarde van elk gegevenstype.
In het onderstaande voorbeeld kunnen we een PySpark aggregatie uitvoeren:
df.groupBy(df.item.string).sum().show()
In het onderstaande voorbeeld kunnen we een andere aggregatie uitvoeren PySQL :
df.createOrReplaceTempView("Pizza")
sql_results = spark.sql("SELECT sum(price.float64),count(*) FROM Pizza where timestamp.string is not null and item.string = 'Pizza'")
sql_results.show()
Schema voor volledige betrouwbaarheid gebruiken met SQL
U kunt het volgende syntaxisvoorbeeld gebruiken, met dezelfde documenten van het Bovenstaande Spark-voorbeeld:
SELECT rating,timestamp_string,timestamp_utc
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating integer '$.rating.int32',
timestamp varchar(50) '$.timestamp.string',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp is not null or timestamp_utc is not null
U kunt transformaties implementeren met behulp van castconvert een andere T-SQL-functie om uw gegevens te bewerken. U kunt ook complexe gegevenstypestructuren verbergen met behulp van weergaven.
create view MyView as
SELECT MyRating=rating,MyTimestamp = convert(varchar(50),timestamp_utc)
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) (
rating integer '$.rating.int32',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp_utc is not null
union all
SELECT MyRating=convert(integer,rating_string),MyTimestamp = timestamp_string
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating_string varchar(50) '$.rating.string',
timestamp_string varchar(50) '$.timestamp.string'
) as HTAP
WHERE timestamp_string is not null
Werken met mongoDB-veld _id
MongoDB _id is fundamenteel voor elke verzameling in MongoDB en heeft oorspronkelijk een hexadecimale weergave. Zoals u in de bovenstaande tabel kunt zien, behoudt het schema met volledige betrouwbaarheid de kenmerken, waardoor een uitdaging ontstaat voor de visualisatie in Azure Synapse Analytics. Voor de juiste visualisatie moet u het _id gegevenstype als volgt converteren:
Werken met mongoDB-veld _id in Spark
In het onderstaande voorbeeld worden Spark 2.x- en 3.x-versies gebruikt:
val df = spark.read.format("cosmos.olap").option("spark.synapse.linkedService", "xxxx").option("spark.cosmos.container", "xxxx").load()
val convertObjectId = udf((bytes: Array[Byte]) => {
val builder = new StringBuilder
for (b <- bytes) {
builder.append(String.format("%02x", Byte.box(b)))
}
builder.toString
}
)
val dfConverted = df.withColumn("objectId", col("_id.objectId")).withColumn("convertedObjectId", convertObjectId(col("_id.objectId"))).select("id", "objectId", "convertedObjectId")
display(dfConverted)
Werken met MongoDB-veld _id in SQL
SELECT TOP 100 id=CAST(_id as VARBINARY(1000))
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
HTAP) WITH (_id VARCHAR(1000)) as HTAP
Werken met mongoDB-veld id
De id eigenschap in MongoDB-containers wordt automatisch overschreven met de Base64-weergave van de eigenschap '_id', zowel in analytische opslag. Het veld Id is bedoeld voor intern gebruik door MongoDB-toepassingen. Op dit moment is de enige tijdelijke oplossing om de naam van de eigenschap 'id' te wijzigen in iets anders dan 'id'.
Schema voor volledige betrouwbaarheid voor API voor NoSQL- of Gremlin-accounts
Het is mogelijk om schema voor volledige betrouwbaarheid te gebruiken voor API voor NoSQL-accounts, in plaats van de standaardoptie, door het schematype in te stellen bij het inschakelen van Synapse Link voor een Azure Cosmos DB-account voor de eerste keer. Hier volgen de overwegingen voor het wijzigen van het standaardtype schemaweergave:
- Als u Synapse Link inschakelt in uw NoSQL API-account met behulp van Azure Portal, wordt dit ingeschakeld en wordt het schema ook gedefinieerd.
- Als u momenteel een volledig betrouwbaarheidsschema wilt gebruiken met NoSQL- of Gremlin-API-accounts, moet u dit instellen op accountniveau in dezelfde CLI- of PowerShell-opdracht waarmee Synapse Link op accountniveau wordt ingeschakeld.
- Momenteel is Azure Cosmos DB voor MongoDB niet compatibel met deze mogelijkheid om de schemaweergave te wijzigen. Alle MongoDB-accounts hebben een schemaweergavetype met volledige betrouwbaarheid.
- De hierboven genoemde toewijzing van gegevenstypen voor het Full Fidelity-schema is niet geldig voor NoSQL-API-accounts die gebruikmaken van JSON-gegevenstypen. Als voorbeeld
floatintegerworden waarden weergegeven alsnumin analytische opslag. - Het is niet mogelijk om het schemaweergavetype opnieuw in te stellen, van goed gedefinieerde tot volledige betrouwbaarheid of omgekeerd.
- Op dit moment worden containersschema's in analytische opslag gedefinieerd wanneer de container wordt gemaakt, zelfs als Synapse Link niet is ingeschakeld in het databaseaccount.
- Containers of grafieken die zijn gemaakt voordat Synapse Link is ingeschakeld met een volledig betrouwbaarheidsschema op accountniveau, hebben een goed gedefinieerd schema.
- Containers of grafieken die zijn gemaakt nadat Synapse Link is ingeschakeld met een volledig betrouwbaarheidsschema op accountniveau, hebben een volledig betrouwbaarheidsschema.
De beslissing van het type schemaweergave moet worden genomen op hetzelfde moment dat Synapse Link is ingeschakeld voor het account, met behulp van Azure CLI of PowerShell.
Met de Azure CLI:
az cosmosdb create --name MyCosmosDBDatabaseAccount --resource-group MyResourceGroup --subscription MySubscription --analytical-storage-schema-type "FullFidelity" --enable-analytical-storage true
Notitie
Vervang in de bovenstaande opdracht door create update bestaande accounts.
Met PowerShell:
New-AzCosmosDBAccount -ResourceGroupName MyResourceGroup -Name MyCosmosDBDatabaseAccount -EnableAnalyticalStorage true -AnalyticalStorageSchemaType "FullFidelity"
Notitie
Vervang in de bovenstaande opdracht door New-AzCosmosDBAccount Update-AzCosmosDBAccount bestaande accounts.
Analytical Time-to-Live (TTL)
Analytische TTL (ATTL) geeft aan hoe lang gegevens moeten worden bewaard in uw analytische opslag, voor een container.
Analytische opslag is ingeschakeld wanneer ATTL is ingesteld met een andere waarde dan NULL en 0. Wanneer deze optie is ingeschakeld, worden invoegingen, updates, verwijderingen naar operationele gegevens automatisch gesynchroniseerd van transactionele opslag naar analytische opslag, ongeacht de transactionele TTL-configuratie (TTTL). De retentie van deze transactionele gegevens in analytische opslag kan worden beheerd op containerniveau door de AnalyticalStoreTimeToLiveInSeconds eigenschap.
De mogelijke ATTL-configuraties zijn:
Als de waarde is ingesteld op
0: de analytische opslag is uitgeschakeld en er worden geen gegevens gerepliceerd van transactionele opslag naar analytische opslag. Open een ondersteuningsaanvraag om analytische opslag in uw containers uit te schakelen.Als het veld wordt weggelaten, gebeurt er niets en wordt de vorige waarde bewaard.
Als de waarde is ingesteld op
-1: de analytische opslag behoudt alle historische gegevens, ongeacht de retentie van de gegevens in het transactionele archief. Deze instelling geeft aan dat de analytische opslag oneindige retentie van uw operationele gegevens heeftAls de waarde is ingesteld op een positief geheel getal
n: items verlopen van de analytische opslagnseconden na de laatste wijzigingstijd in het transactionele archief. Deze instelling kan worden gebruikt als u uw operationele gegevens gedurende een beperkte periode in de analytische opslag wilt bewaren, ongeacht de retentie van de gegevens in het transactionele archief
Enkele punten om in overweging te nemen:
- Nadat de analytische opslag is ingeschakeld met een ATTL-waarde, kan deze later worden bijgewerkt naar een andere geldige waarde.
- Hoewel TTTL kan worden ingesteld op container- of itemniveau, kan ATTL momenteel alleen worden ingesteld op containerniveau.
- U kunt langere retentie van uw operationele gegevens in de analytische opslag bereiken door ATTL >= TTTL in te stellen op containerniveau.
- De analytische opslag kan worden gemaakt om het transactionele archief te spiegelen door ATTL = TTTL in te stellen.
- Als u ATTL groter hebt dan TTTL, hebt u op een bepaald moment gegevens die alleen in de analytische opslag aanwezig zijn. Deze gegevens zijn alleen-lezen.
- Momenteel verwijderen we geen gegevens uit de analytische opslag. Als u uw ATTL instelt op een positief geheel getal, worden de gegevens niet opgenomen in uw query's en worden er geen kosten in rekening gebracht. Maar als u ATTL weer
-1wijzigt in , worden alle gegevens opnieuw weergegeven, wordt u gefactureerd voor alle gegevensvolumes.
Analytische opslag inschakelen voor een container:
In Azure Portal is de ATTL-optie, wanneer deze is ingeschakeld, ingesteld op de standaardwaarde van -1. U kunt deze waarde wijzigen in n seconden door te navigeren naar containerinstellingen onder Data Explorer.
Vanuit de Azure Management SDK, Azure Cosmos DB SDK's, PowerShell of Azure CLI kan de ATTL-optie worden ingeschakeld door deze in te stellen op -1 of n' seconden.
Zie voor meer informatie hoe u analytische TTL configureert op een container.
Kostenefficiënte analyse van historische gegevens
Gegevenslagen verwijzen naar de scheiding van gegevens tussen opslaginfrastructuren die zijn geoptimaliseerd voor verschillende scenario's. Hierdoor worden de algehele prestaties en kosteneffectiviteit van de end-to-end gegevensstack verbeterd. Met analytische opslag biedt Azure Cosmos DB nu ondersteuning voor het automatisch opslaan van gegevens uit de transactionele opslag naar analytische opslag met verschillende gegevensindelingen. Met analytische opslag die is geoptimaliseerd in termen van opslagkosten in vergelijking met de transactionele opslag, kunt u veel langere horizonten van operationele gegevens bewaren voor historische analyse.
Nadat de analytische opslag is ingeschakeld, op basis van de gegevensretentiebehoeften van de transactionele workloads, kunt u de eigenschap zodanig configureren transactional TTL dat records na een bepaalde periode automatisch uit het transactionele archief worden verwijderd. Op dezelfde manier analytical TTL kunt u de levenscyclus beheren van gegevens die in de analytische opslag worden bewaard, onafhankelijk van de transactionele opslag. Door analytische opslag in te schakelen en transactionele en analytische TTL eigenschappen te configureren, kunt u naadloos de gegevensretentieperiode voor de twee winkels definiëren en tieren.
Notitie
Wanneer analytical TTL deze is ingesteld op een waarde die groter is dan transactional TTL de waarde, bevat uw container gegevens die alleen in de analytische opslag aanwezig zijn. Deze gegevens zijn alleen-lezen en momenteel bieden we geen ondersteuning voor documentniveau TTL in analytische opslag. Als uw containergegevens op een bepaald moment in de toekomst mogelijk een update of verwijdering nodig hebben, gebruikt u niet analytical TTL groter dan transactional TTL. Deze mogelijkheid wordt aanbevolen voor gegevens die in de toekomst geen updates of verwijderingen nodig hebben.
Notitie
Als in uw scenario geen fysieke verwijderingen nodig zijn, kunt u een logische methode voor verwijderen/bijwerken gebruiken. Voeg in transactionele opslag een andere versie van hetzelfde document in die alleen bestaat in analytische opslag, maar heeft een logische verwijdering/update nodig. Misschien met een vlag die aangeeft dat het een verwijdering of een update van een verlopen document is. Beide versies van hetzelfde document bestaan samen in de analytische opslag en uw toepassing mag alleen rekening houden met de laatste versie.
Flexibiliteit
Analytische opslag is afhankelijk van Azure Storage en biedt de volgende beveiliging tegen fysieke fouten:
- Standaard wijzen Azure Cosmos DB-databaseaccounts analytische opslag toe in LRS-accounts (Lokaal redundante opslag). LRS biedt ten minste 99,9999999999% (11 negens) duurzaamheid van objecten gedurende een bepaald jaar.
- Als een geografisch gebied van het databaseaccount is geconfigureerd voor zoneredundantie, wordt het toegewezen in ZRS-accounts (Zone-redundant Storage). U moet Beschikbaarheidszones inschakelen voor een regio van hun Azure Cosmos DB-databaseaccount om analytische gegevens van die regio op te slaan in zone-redundante opslag. ZRS biedt duurzaamheid voor opslagresources van ten minste 99,999999999999% (12 9's) gedurende een bepaald jaar.
Zie deze koppeling voor meer informatie over duurzaamheid van Azure Storage.
Backup
Hoewel analytische opslag ingebouwde beveiliging heeft tegen fysieke fouten, kan back-up nodig zijn voor onbedoelde verwijderingen of updates in transactionele opslag. In dergelijke gevallen kunt u een container herstellen en de herstelde container gebruiken om de gegevens in de oorspronkelijke container te vullen of indien nodig de analytische opslag volledig opnieuw te bouwen.
Notitie
Er wordt momenteel geen back-up gemaakt van analytische opslag. Daarom kan deze niet worden hersteld. Uw back-upbeleid kan hierop niet worden gepland.
Synapse Link en analytische opslag hebben als gevolg hiervan verschillende compatibiliteitsniveaus met back-upmodi van Azure Cosmos DB:
- De periodieke back-upmodus is volledig compatibel met Synapse Link en deze 2 functies kunnen worden gebruikt in hetzelfde databaseaccount.
- Synapse Link voor databaseaccounts met behulp van continue back-upmodus is algemeen beschikbaar.
- De modus Continue back-up voor accounts met Synapse Link is in openbare preview. Op dit moment kunt u niet migreren naar continue back-up als u Synapse Link hebt uitgeschakeld voor een van uw verzamelingen in een Cosmos DB-account.
Back-upbeleid
Er zijn twee mogelijke back-upbeleidsregels en om te begrijpen hoe u deze kunt gebruiken, zijn de volgende details over Azure Cosmos DB-back-ups erg belangrijk:
- De oorspronkelijke container wordt hersteld zonder analytische opslag in beide back-upmodi.
- Azure Cosmos DB biedt geen ondersteuning voor het overschrijven van containers vanuit een herstelbewerking.
Laten we nu eens kijken hoe u back-ups en herstelbewerkingen kunt gebruiken vanuit het perspectief van de analytische opslag.
Een container herstellen met TTTL >= ATTL
Wanneer transactional TTL deze gelijk is aan of groter is dan analytical TTL, bestaan alle gegevens in de analytische opslag nog steeds in transactionele opslag. In het geval van een herstelbewerking hebt u twee mogelijke situaties:
- Als u de herstelde container wilt gebruiken als vervanging voor de oorspronkelijke container. Als u de analytische opslag opnieuw wilt opbouwen, schakelt u Synapse Link op accountniveau en containerniveau in.
- Als u de herstelde container wilt gebruiken als gegevensbron om de gegevens in de oorspronkelijke container te vullen of bij te werken. In dit geval geeft analytische opslag automatisch de gegevensbewerkingen weer.
Een container herstellen met TTTL ATTL <
Wanneer transactional TTL deze kleiner is dan analytical TTL, bestaan sommige gegevens alleen in de analytische opslag en bevinden ze zich niet in de herstelde container. Nogmaals, u hebt twee mogelijke situaties:
- Als u de herstelde container wilt gebruiken als vervanging voor de oorspronkelijke container. Wanneer u Synapse Link inschakelt op containerniveau, worden alleen de gegevens die zich in transactionele opslag bevinden, opgenomen in de nieuwe analytische opslag. Houd er echter rekening mee dat de analytische opslag van de oorspronkelijke container beschikbaar blijft voor query's zolang de oorspronkelijke container bestaat. Mogelijk wilt u uw toepassing wijzigen om een query uit te voeren op beide.
- Als u de herstelde container wilt gebruiken als gegevensbron om de gegevens in de oorspronkelijke container te backfillen of bij te werken:
- Analytische opslag geeft automatisch de gegevensbewerkingen weer voor de gegevens die zich in transactionele opslag bevinden.
- Als u gegevens die eerder zijn verwijderd uit transactionele opslag
transactional TTLopnieuw invoegt, worden deze gegevens gedupliceerd in de analytische opslag.
Voorbeeld:
- De container
OnlineOrdersheeft TTTL ingesteld op één maand en ATTL is één jaar ingesteld. - Wanneer u deze herstelt en
OnlineOrdersNewanalytische opslag inschakelt om deze opnieuw te bouwen, is er slechts één maand aan gegevens in zowel transactionele als analytische opslag. - De oorspronkelijke container
OnlineOrderswordt niet verwijderd en de analytische opslag is nog steeds beschikbaar. - Nieuwe gegevens worden alleen opgenomen in
OnlineOrdersNew. - Analytische query's voeren UNION ALL uit analytische archieven uit terwijl de oorspronkelijke gegevens nog steeds relevant zijn.
Als u de oorspronkelijke container wilt verwijderen, maar de analytische opslaggegevens niet wilt verliezen, kunt u de analytische opslag van de oorspronkelijke container in een andere Azure-gegevensservice behouden. Synapse Analytics biedt de mogelijkheid om joins uit te voeren tussen gegevens die zijn opgeslagen op verschillende locaties. Een voorbeeld: Een Synapse Analytics-query voegt analytische opslaggegevens samen met externe tabellen die zich in Azure Blob Storage, Azure Data Lake Store, enzovoort bevinden.
Het is belangrijk te weten dat de gegevens in de analytische opslag een ander schema hebben dan wat er in de transactionele opslag bestaat. Hoewel u momentopnamen van uw analytische opslaggegevens kunt genereren en deze kunt exporteren naar elke Azure Data-service, kunnen we niet garanderen dat deze momentopname zonder ru's wordt gebruikt om de transactionele opslag terug te voeren. Dit proces wordt niet ondersteund.
Wereldwijde distributie
Als u een wereldwijd gedistribueerd Azure Cosmos DB-account hebt nadat u analytische opslag voor een container hebt ingeschakeld, is dit beschikbaar in alle regio's van dat account. Wijzigingen in operationele gegevens worden globaal gerepliceerd in alle regio's. U kunt analytische query's effectief uitvoeren op de dichtstbijzijnde regionale kopie van uw gegevens in Azure Cosmos DB.
Partitionering
Partitionering van analytische opslag is volledig onafhankelijk van partitionering in het transactionele archief. Gegevens in analytische opslag worden standaard niet gepartitioneerd. Als uw analytische query's vaak filters hebben, hebt u de mogelijkheid om te partitioneren op basis van deze velden voor betere queryprestaties. Zie inleiding tot aangepaste partitionering en het configureren van aangepaste partitionering voor meer informatie.
Beveiliging
Verificatie met de analytische opslag is hetzelfde als het transactionele archief voor een bepaalde database.
Netwerkisolatie met behulp van privé-eindpunten : u kunt de netwerktoegang tot de gegevens in de transactionele en analytische opslag onafhankelijk beheren. Netwerkisolatie wordt uitgevoerd met afzonderlijke beheerde privé-eindpunten voor elke winkel, binnen beheerde virtuele netwerken in Azure Synapse-werkruimten. Zie het artikel Over het configureren van privé-eindpunten voor analytische opslag voor meer informatie.
Data-at-rest - De versleuteling van uw analytische opslag is standaard ingeschakeld.
Gegevensversleuteling met door de klant beheerde sleutels : u kunt de gegevens naadloos versleutelen in transactionele en analytische archieven met behulp van dezelfde door de klant beheerde sleutels op een automatische en transparante manier. Azure Synapse Link biedt alleen ondersteuning voor het configureren van door de klant beheerde sleutels met behulp van de beheerde identiteit van uw Azure Cosmos DB-account. U moet de beheerde identiteit van uw account configureren in uw Azure Key Vault-toegangsbeleid voordat u Azure Synapse Link inschakelt voor uw account. Zie voor meer informatie hoe u door de klant beheerde sleutels configureert met behulp van het artikel beheerde identiteiten van Azure Cosmos DB-accounts.
Notitie
Als u uw databaseaccount wijzigt van First Party in System of User Assigned Identy en Azure Synapse Link inschakelt in uw databaseaccount, kunt u niet terugkeren naar de first party-identiteit, omdat u Synapse Link niet kunt uitschakelen vanuit uw databaseaccount.
Ondersteuning voor meerdere Azure Synapse Analytics-runtimes
De analytische opslag is geoptimaliseerd om schaalbaarheid, elasticiteit en prestaties te bieden voor analytische workloads zonder enige afhankelijkheid van de berekeningsruntimes. De opslagtechnologie wordt zelf beheerd om uw analyseworkloads te optimaliseren zonder handmatige inspanningen.
Gegevens in de analytische opslag van Azure Cosmos DB kunnen tegelijkertijd worden opgevraagd vanuit de verschillende analyseruntimes die worden ondersteund door Azure Synapse Analytics. Azure Synapse Analytics ondersteunt Apache Spark en serverloze SQL-pool met analytische opslag van Azure Cosmos DB.
Notitie
U kunt alleen lezen uit analytische opslag met behulp van Azure Synapse Analytics-runtimes. En het tegenovergestelde is ook waar, Azure Synapse Analytics-runtimes kunnen alleen lezen uit analytische opslag. Alleen het proces voor automatische synchronisatie kan gegevens in analytische opslag wijzigen. U kunt gegevens terugschrijven naar de transactionele opslag van Azure Cosmos DB met behulp van azure Synapse Analytics Spark-pool met behulp van de ingebouwde Azure Cosmos DB OLTP SDK.
Prijzen
Analytische opslag volgt een prijsmodel op basis van verbruik waarvoor kosten in rekening worden gebracht:
Opslag: het volume van de gegevens die elke maand in de analytische opslag worden bewaard, inclusief historische gegevens zoals gedefinieerd door analytische TTL.
Analytische schrijfbewerkingen: de volledig beheerde synchronisatie van operationele gegevensupdates naar de analytische opslag vanuit het transactionele archief (automatische synchronisatie)
Analytische leesbewerkingen: de leesbewerkingen die worden uitgevoerd op basis van de analytische opslag vanuit de Spark-pool van Azure Synapse Analytics en runtimes voor serverloze SQL-pools.
Prijzen voor analytische opslag zijn gescheiden van het prijsmodel voor transactiearchieven. Er is geen concept van ingerichte RU's in de analytische opslag. Zie de pagina met prijzen van Azure Cosmos DB voor volledige informatie over het prijsmodel voor analytische opslag.
Gegevens in het analysearchief kunnen alleen worden geopend via Azure Synapse Link. Dit gebeurt in de Azure Synapse Analytics-runtimes: Azure Synapse Apache Spark-pools en serverloze SQL-pools van Azure Synapse. Zie de pagina met prijzen van Azure Synapse Analytics voor volledige informatie over het prijsmodel voor toegang tot gegevens in analytische opslag.
Als u een schatting van hoge kosten wilt maken om analytische opslag in te schakelen in een Azure Cosmos DB-container, kunt u vanuit het perspectief van de analytische opslag de Azure Cosmos DB-capaciteitsplanner gebruiken en een schatting krijgen van uw kosten voor analytische opslag en schrijfbewerkingen.
Schattingen van leesbewerkingen voor analytische opslag worden niet opgenomen in de Azure Cosmos DB-kostencalculator omdat ze een functie van uw analytische workload zijn. Maar als een schatting op hoog niveau resulteert scan van 1 TB aan gegevens in analytische opslag doorgaans in 130.000 analytische leesbewerkingen en resulteert dit in een kosten van $ 0,065. Als u bijvoorbeeld serverloze SQL-pools van Azure Synapse gebruikt om deze scan van 1 TB uit te voeren, kost dit $ 5,00 op basis van de prijzenpagina van Azure Synapse Analytics. De uiteindelijke totale kosten voor deze scan van 1 TB zijn $ 5,065.
Hoewel de bovenstaande schatting is voor het scannen van 1 TB aan gegevens in analytische opslag, vermindert het toepassen van filters het aantal gescande gegevens en bepaalt dit het exacte aantal analytische leesbewerkingen op basis van het prijsmodel voor verbruik. Een proof-of-concept rond de analytische workload zou een nauwkeurigere schatting bieden van analytische leesbewerkingen. Deze schatting omvat niet de kosten van Azure Synapse Analytics.
Volgende stappen
Zie de volgende documenten voor meer informatie:
Bekijk de trainingsmodule over het ontwerpen van hybride transactionele en analytische verwerking met behulp van Azure Synapse Analytics