Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In dit artikel wordt uitgelegd hoe u Azure Cosmos DB MongoDB vCore verbindt vanuit Azure Databricks. Het begeleidt eenvoudige DML-bewerkingen (Data Manipulation Language), zoals Lezen, Filteren, SQLs, Aggregatiepijplijnen en Tabellen schrijven met behulp van Python-code.
Vereisten
- Richt een Azure Cosmos DB in voor een MongoDB vCore-cluster.
- Configureer uw gekozen Spark-omgeving Azure Databricks.
Afhankelijkheden configureren voor connectiviteit
Hier volgen de afhankelijkheden die nodig zijn om vanuit Azure Databricks verbinding te maken met Azure Cosmos DB voor MongoDB vCore:
-
Spark-connector voor MongoDB Spark-connector wordt gebruikt om verbinding te maken met Azure Cosmos DB voor MongoDB vCore. Identificeer en gebruik de versie van de connector in Maven Central die compatibel is met de Spark- en Scala-versies van uw Spark-omgeving. We raden een omgeving aan die Ondersteuning biedt voor Spark 3.2.1 of hoger en de Spark-connector die beschikbaar is op maven-coördinaten
org.mongodb.spark:mongo-spark-connector_2.12:3.0.1. - Azure Cosmos DB voor MongoDB-verbindingsreeksen: Uw Azure Cosmos DB voor MongoDB vCore-verbindingsreeks, gebruikersnaam en wachtwoorden.
Een Azure Databricks-werkruimte inrichten
U kunt de instructies volgen om een Azure Databricks-werkruimte in te richten. U kunt de standaard beschikbare rekenkracht gebruiken of een nieuwe rekenresource maken om uw notebook uit te voeren. Zorg ervoor dat u een Databricks-runtime selecteert die ten minste Spark 3.0 ondersteunt.
Afhankelijkheden toevoegen
Voeg de MongoDB-connector voor Spark-bibliotheek toe aan uw rekenproces om verbinding te maken met zowel systeemeigen MongoDB- als Azure Cosmos DB voor MongoDB-eindpunten. Selecteer in uw computer Bibliotheken>Nieuwe installeren>Maven en voeg vervolgens org.mongodb.spark:mongo-spark-connector_2.12:3.0.1 Maven-coördinaten toe.
Selecteer Installeren en start de berekening opnieuw wanneer de installatie is voltooid.
Notitie
Zorg ervoor dat u de Databricks-berekening opnieuw start nadat de MongoDB-connector voor Spark-bibliotheek is geïnstalleerd.
Daarna kunt u een Scala- of Python-notebook maken voor migratie.
Python-notebook maken om verbinding te maken met Azure Cosmos DB voor MongoDB vCore
Maak een Python-notebook in Databricks. Zorg ervoor dat u de juiste waarden voor de variabelen invoert voordat u de volgende codes uitvoert.
Spark-configuratie bijwerken met de Azure Cosmos DB voor MongoDB-verbindingsreeks
- Noteer de verbindingsreeks onder Instellingen ->Verbindingsreeksen in de Azure Cosmos DB MongoDB vCore-resource in Azure portal. Het heeft de vorm van 'mongodb+srv://<user>:<password>@<database_name.mongocluster.cosmos.azure.com>'
- Plak in uw rekenconfiguratie in Databricks onder Geavanceerde opties (onderaan de pagina) de verbindingsreeks voor zowel de
spark.mongodb.output.uri- alsspark.mongodb.input.uri-variabelen. Vul het veld gebruikersnaam en wachtwoord in dat geschikt is. Op deze manier gebruiken alle werkmappen, die op de compute draaien, deze configuratie. - U kunt ook
optionexpliciet instellen wanneer u API's aanroept, zoals:spark.read.format("mongo").option("spark.mongodb.input.uri", connectionString).load(). Als u de variabelen in het cluster configureert, hoeft u de optie niet in te stellen.
connectionString_vcore="mongodb+srv://<user>:<password>@<database_name>.mongocluster.cosmos.azure.com/?tls=true&authMechanism=SCRAM-SHA-256&retrywrites=false&maxIdleTimeMS=120000"
database="<database_name>"
collection="<collection_name>"
Gegevensvoorbeeldenset
Voor dit lab gebruiken we de CSV-gegevensset Citibike2019. U kunt het importeren: CitiBike Trip History 2019. We hebben het geladen in een database met de naam CitiBikeDB en de collectie CitiBike2019. We stellen de variabelendatabase en verzameling in om te verwijzen naar de gegevens die zijn geladen en we gebruiken variabelen in de voorbeelden.
database="CitiBikeDB"
collection="CitiBike2019"
Gegevens lezen uit Azure Cosmos DB voor MongoDB vCore
De algemene syntaxis ziet er als volgt uit:
df_vcore = spark.read.format("mongo").option("database", database).option("spark.mongodb.input.uri", connectionString_vcore).option("collection",collection).load()
U kunt het gegevensframe als volgt valideren:
df_vcore.printSchema()
display(df_vcore)
Laten we een voorbeeld bekijken:
df_vcore = spark.read.format("mongo").option("database", database).option("spark.mongodb.input.uri", connectionString_vcore).option("collection",collection).load()
df_vcore.printSchema()
display(df_vcore)
Uitvoer:
Schema
Schermopname
Gegevens filteren uit Azure Cosmos DB voor MongoDB vCore
De algemene syntaxis ziet er als volgt uit:
df_v = df_vcore.filter(df_vcore[column number/column name] == [filter condition])
display(df_v)
Laten we een voorbeeld bekijken:
df_v = df_vcore.filter(df_vcore[2] == 1970)
display(df_v)
Uitvoer: 
Maak een weergave of tijdelijke tabel en voer SQL-query's erop uit
De algemene syntaxis ziet er als volgt uit:
df_[dataframename].createOrReplaceTempView("[View Name]")
spark.sql("SELECT * FROM [View Name]")
Laten we een voorbeeld bekijken:
df_vcore.createOrReplaceTempView("T_VCORE")
df_v = spark.sql(" SELECT * FROM T_VCORE WHERE birth_year == 1970 and gender == 2 ")
display(df_v)
Uitvoer: 
Gegevens schrijven naar Azure Cosmos DB voor MongoDB vCore
De algemene syntaxis ziet er als volgt uit:
df.write.format("mongo").option("spark.mongodb.output.uri", connectionString).option("database",database).option("collection","<collection_name>").mode("append").save()
Laten we een voorbeeld bekijken:
df_vcore.write.format("mongo").option("spark.mongodb.output.uri", connectionString_vcore).option("database",database).option("collection","CitiBike2019").mode("append").save()
Deze opdracht heeft geen uitvoer omdat deze rechtstreeks naar de verzameling schrijft. U kunt kruislings controleren of de record is bijgewerkt met behulp van een leesopdracht.
Gegevens lezen uit azure Cosmos DB voor MongoDB vCore-verzameling met een aggregatiepijplijn
[! Opmerking] Aggregatiepijplijn is een krachtige mogelijkheid waarmee gegevens in Azure Cosmos DB voor MongoDB vooraf kunnen worden verwerkt en getransformeerd. Het is een uitstekende match voor realtime analyses, dashboards, het genereren van rapporten met roll-ups, sommen, en gemiddelden met data post-processing op de serverzijde. (Opmerking: er is een heel boek over geschreven).
Azure Cosmos DB voor MongoDB ondersteunt zelfs uitgebreide secundaire/samengestelde indexen voor het extraheren, filteren en verwerken van alleen de gegevens die nodig zijn.
Als u bijvoorbeeld alle klanten in een specifieke geografie rechtstreeks in de database analyseert zonder eerst de volledige gegevensset te hoeven laden, waardoor gegevensverplaatsing wordt geminimaliseerd en de latentie wordt verminderd.
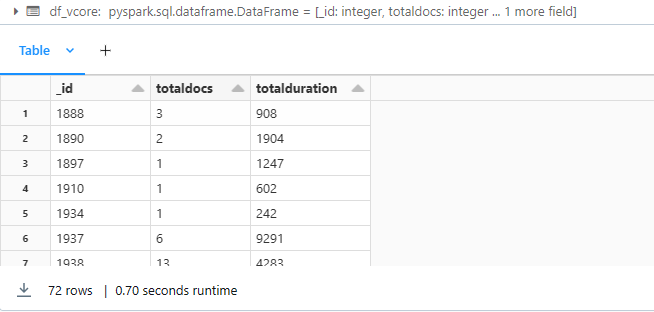
Hier volgt een voorbeeld van het gebruik van de statistische functie:
pipeline = "[{ $group : { _id : '$birth_year', totaldocs : { $count : 1 }, totalduration: {$sum: '$tripduration'}} }]"
df_vcore = spark.read.format("mongo").option("database", database).option("spark.mongodb.input.uri", connectionString_vcore).option("collection",collection).option("pipeline", pipeline).load()
display(df_vcore)
Uitvoer:
Verwante inhoud
De volgende artikelen laten zien hoe u aggregatiepijplijnen gebruikt in Azure Cosmos DB voor MongoDB vCore:
- Maven Central is de locatie waar u Spark Connector kunt vinden.
- Aggregatiepijplijn