Overzicht van bedrijfscontinuïteit en herstel na noodgevallen
Bedrijfscontinuïteit en herstel na noodgevallen in Azure Data Explorer stelt uw bedrijf in staat om te blijven werken in het geval van een onderbreking. In dit artikel worden beschikbaarheid (binnen regio's) en herstel na noodgevallen besproken. Hierin worden systeemeigen mogelijkheden en overwegingen met betrekking tot de architectuur beschreven voor een robuuste Implementatie van Azure Data Explorer. Het bevat informatie over herstel na menselijke fouten, hoge beschikbaarheid, gevolgd door meerdere configuraties voor herstel na noodgevallen. Deze configuraties zijn afhankelijk van tolerantievereisten zoals Recovery Point Objective (RPO) en Recovery Time Objective (RTO), benodigde inspanningen en kosten.
Verstorende gebeurtenissen beperken
- Menselijke fout
- Hoge beschikbaarheid van Azure Data Explorer
- Storing van een Azure-beschikbaarheidszone
- Storing van een Azure-datacenter
- Storing van een Azure-regio
Menselijke fout
Menselijke fouten zijn onvermijdelijk. Gebruikers kunnen per ongeluk een cluster, database of tabel verwijderen.
Onbedoeld verwijderen van cluster of database
Onbedoeld verwijderen van een cluster of database is een onherstelbare actie. Als azure Data Explorer resource-eigenaar kunt u gegevensverlies voorkomen door de mogelijkheid voor verwijderen van vergrendeling in te schakelen, die beschikbaar is op azure-resourceniveau.
Tabel per ongeluk verwijderen
Gebruikers met of meer machtigingen voor tabelbeheerders mogen tabellen verwijderen. Als een van deze gebruikers per ongeluk een tabel verwijdert, kunt u deze herstellen met de .undo drop table opdracht . Voor deze opdracht moet u eerst de eigenschap herstelbaarheid inschakelen in het bewaarbeleid.
Onbedoeld verwijderen van externe tabel
Externe tabellen zijn Kusto-queryschema-entiteiten die verwijzen naar gegevens die buiten de database zijn opgeslagen. Als u een externe tabel verwijdert, worden alleen de metagegevens van de tabel verwijderd. U kunt deze herstellen door de opdracht voor het maken van tabellen opnieuw uit te voeren. Gebruik de mogelijkheid voor voorlopig verwijderen ter bescherming tegen onbedoeld verwijderen of overschrijven van een bestand/blob gedurende een door de gebruiker geconfigureerde tijdsduur.
Hoge beschikbaarheid van Azure Data Explorer
Hoge beschikbaarheid verwijst naar de fouttolerantie van Azure Data Explorer, de bijbehorende onderdelen en onderliggende afhankelijkheden binnen een Azure-regio. Deze fouttolerantie voorkomt SPOF (Single Point of Failure) in de implementatie. In Azure Data Explorer omvat hoge beschikbaarheid de persistentielaag, de rekenlaag en een leidervolgerconfiguratie.
Persistentielaag
Azure Data Explorer maakt gebruik van Azure Storage als duurzame persistentielaag. Azure Storage biedt automatisch fouttolerantie, met de standaardinstelling lokaal redundante opslag (LRS) in een datacenter. Er worden drie replica's bewaard. Als een replica verloren gaat tijdens gebruik, wordt een andere zonder onderbreking geïmplementeerd. Verdere tolerantie is mogelijk met Zone Redundant Storage (ZRS) die replica's intelligent plaatst in regionale beschikbaarheidszones van Azure voor maximale fouttolerantie tegen extra kosten. Opslag met ZRS wordt automatisch geconfigureerd wanneer het Azure Data Explorer-cluster wordt geïmplementeerd in Beschikbaarheidszones.
Rekenlaag
Azure Data Explorer is een gedistribueerd computingplatform en kan twee tot veel knooppunten hebben, afhankelijk van de schaal en het type knooppuntrol. Selecteer tijdens het inrichten beschikbaarheidszones om de knooppuntimplementatie over zones te verdelen voor maximale tolerantie binnen regio's. Een fout in de beschikbaarheidszone leidt niet tot een volledige storing, maar tot prestatievermindering totdat de zone is hersteld.
Configuratie van Leader-volgercluster
Azure Data Explorer biedt een optionele volgermogelijkheid voor een leadercluster die kan worden gevolgd door andere volgclusters voor alleen-lezentoegang tot de gegevens en metagegevens van de leider. Wijzigingen in de leider, zoals create, appenden, worden drop automatisch gesynchroniseerd met de volger. Hoewel de leiders Azure-regio's kunnen omvatten, moeten de volgclusters worden gehost in dezelfde regio('s) als de leider. Als het leadercluster niet beschikbaar is of databases of tabellen per ongeluk worden verwijderd, verliezen de volgclusters de toegang totdat de toegang in de leider is hersteld.
Storing van een Azure-beschikbaarheidszone
Azure-beschikbaarheidszones zijn unieke fysieke locaties binnen dezelfde Azure-regio. Ze kunnen de reken- en gegevens van een Azure Data Explorer-cluster beveiligen tegen gedeeltelijke regiofouten. Zonefout is een beschikbaarheidsscenario omdat het een regio binnen de regio is.
Maak een Azure Data Explorer-cluster vast aan dezelfde zone als andere verbonden Azure-resources. Zie Een cluster maken voor meer informatie over het inschakelen van beschikbaarheidszones.
Notitie
Implementatie naar beschikbaarheidszones is mogelijk bij het maken van een cluster of kan later worden gemigreerd.
Storing van een Azure-datacenter
Azure-beschikbaarheidszones gaan gepaard met kosten en sommige klanten kiezen ervoor om te implementeren zonder zoneredundantie. Met een dergelijke implementatie van Azure Data Explorer leidt een storing in het Azure-datacenter tot clusterstoring. Het verwerken van een storing in een Azure-datacenter is daarom identiek aan die van een storing in een Azure-regio.
Storing van een Azure-regio
Azure Data Explorer biedt geen automatische beveiliging tegen storingen in een hele Azure-regio. Om de bedrijfsimpact te minimaliseren als er een dergelijke storing is, Data Explorer meerdere Azure-clusters in gekoppelde Azure-regio's. Op basis van uw beoogde hersteltijd (RTO), het beoogde herstelpunt (RPO) en uw inspanningen en kostenoverwegingen zijn er meerdere configuraties voor herstel na noodgevallen. Kosten- en prestatieoptimalisaties zijn mogelijk met azure Advisor-aanbevelingen en configuratie voor automatische schaalaanpassing .
Configuraties voor herstel na noodgevallen
In deze sectie worden meerdere configuraties voor herstel na noodgevallen beschreven, afhankelijk van de tolerantievereisten (RPO en RTO), de benodigde inspanning en de kosten.
Beoogde hersteltijd (RTO) verwijst naar de tijd die moet worden hersteld van een onderbreking. Een RTO van 2 uur betekent bijvoorbeeld dat de toepassing binnen twee uur na een onderbreking actief en actief moet zijn. Recovery Point Objective (RPO) verwijst naar het tijdsinterval dat kan verstrijken tijdens een onderbreking voordat de hoeveelheid gegevens die verloren gaat tijdens die periode groter is dan de toegestane drempelwaarde. Als de RPO bijvoorbeeld 24 uur is en een toepassing gegevens heeft die beginnen vanaf 15 jaar geleden, vallen ze nog steeds binnen de parameters van de overeengekomen RPO.
Opname-, verwerkings- en curatieprocessen moeten vooraf zorgvuldig worden ontworpen bij het plannen van herstel na noodgevallen. Opname verwijst naar gegevens die vanuit verschillende bronnen zijn geïntegreerd in Azure Data Explorer; verwerking verwijst naar transformaties en vergelijkbare activiteiten; curatie verwijst naar gerealiseerde weergaven, exports naar de data lake, enzovoort.
Hieronder vindt u populaire configuraties voor herstel na noodgevallen. Elk van deze configuraties wordt hieronder in detail beschreven.
- Configuratie actief-actief-actief (altijd ingeschakeld)
- Configuratie actief-actief
- Stand-byconfiguratie actief/dynamisch
- Clusterconfiguratie voor gegevensherstel op aanvraag
Configuratie actief-actief-actief
Deze configuratie wordt ook wel 'always-on' genoemd. Voor kritieke toepassingsimplementaties zonder tolerantie voor storingen moet u meerdere Azure Data Explorer-clusters gebruiken in gekoppelde Azure-regio's. Opname, verwerking en curatie parallel met alle clusters instellen. De cluster-SKU moet in alle regio's hetzelfde zijn. Azure zorgt ervoor dat updates worden geïmplementeerd en verspreid over gekoppelde Azure-regio's. Een storing in een Azure-regio veroorzaakt geen toepassingsstoring. Mogelijk ondervindt u enige latentie of prestatievermindering.

| Configuratie | RPO | RTO | Inspanning | Kosten |
|---|---|---|---|---|
| Actief-actief-actief-actief-n | 0 uur | 0 uur | Lager | Hoogste |
Active-Active configuratie
Deze configuratie is identiek aan de configuratie actief-actief-actief, maar omvat slechts twee gekoppelde Azure-regio's. Configureer dubbele opname, verwerking en curatie. Gebruikers worden doorgestuurd naar de dichtstbijzijnde regio. De cluster-SKU moet in alle regio's hetzelfde zijn.

| Configuratie | RPO | RTO | Inspanning | Kosten |
|---|---|---|---|---|
| Actief-actief | 0 uur | 0 uur | Lager | Hoog |
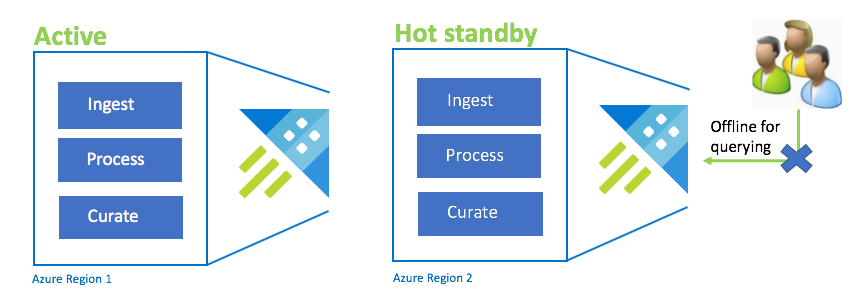
Active-Hot stand-byconfiguratie
De configuratie Active-Hot is vergelijkbaar met de configuratie Actief-Actief in dubbele opname, verwerking en curatie. Hoewel het stand-bycluster online is voor opname, proces en curatie, is het niet beschikbaar voor query's. Het stand-bycluster hoeft zich niet in dezelfde SKU te bevinden als het primaire cluster. Het kan een kleinere SKU en schaal hebben, waardoor deze mogelijk minder goed presteert. In een noodgeval worden gebruikers omgeleid naar het stand-bycluster, dat optioneel kan worden opgeschaald om de prestaties te verbeteren.
| Configuratie | RPO | RTO | Inspanning | Kosten |
|---|---|---|---|---|
| Actief-hot stand-by | 0 uur | Beperkt | Gemiddeld | Gemiddeld |
Configuratie voor gegevensherstel op aanvraag
Deze oplossing biedt de minste tolerantie (hoogste RPO en RTO), is de laagste in kosten en de hoogste inspanning. In deze configuratie is er geen cluster voor gegevensherstel. Continue export van gecureerde gegevens configureren (tenzij ook onbewerkte en tussenliggende gegevens vereist zijn) naar een opslagaccount dat is geconfigureerd grs (geografisch redundante opslag). Er wordt een cluster voor gegevensherstel gemaakt als er een noodherstelscenario is. Op dat moment worden DDLs, configuratie, beleid en processen toegepast. Gegevens worden opgenomen uit de opslag met de opnameeigenschap kustoCreationTime om de opnametijd te overrijden die standaard is ingesteld op de systeemtijd.

| Configuratie | RPO | RTO | Inspanning | Kosten |
|---|---|---|---|---|
| Cluster voor gegevensherstel op aanvraag | Hoogste | Hoogste | Hoogste | Laagste |
Overzicht van configuratieopties voor herstel na noodgevallen
| Configuratie | Flexibiliteit | RPO | RTO | Inspanning | Kosten |
|---|---|---|---|---|---|
| Actief-actief-actief-actief-n | Hoogste | 0 uur | 0 uur | Lager | Hoogste |
| Actief-actief | Hoog | 0 uur | 0 uur | Lager | Hoog |
| Actief-hot stand-by | Normaal | 0 uur | Beperkt | Gemiddeld | Gemiddeld |
| Cluster voor gegevensherstel op aanvraag | Laagste | Hoogste | Hoogste | Hoogste | Laagste |
Aanbevolen procedures
Volg deze aanbevolen procedures, ongeacht welke configuratie voor herstel na noodgevallen wordt gekozen:
- Alle databaseobjecten, beleidsregels en configuraties moeten worden bewaard in broncodebeheer, zodat ze kunnen worden vrijgegeven aan het cluster vanuit het hulpprogramma voor releaseautomatisering. Zie Azure DevOps-ondersteuning voor Azure Data Explorer voor meer informatie.
- Ontwerp, ontwikkel en implementeer validatieroutines om ervoor te zorgen dat alle clusters vanuit een gegevensperspectief zijn gesynchroniseerd. Azure Data Explorer ondersteunt clusteroverschrijdende joins. Een eenvoudige telling of rijen in tabellen kan helpen bij het valideren.
- Releaseprocedures moeten governancecontroles en -balansen omvatten die ervoor zorgen dat de clusters worden gespiegeld.
- Wees volledig op de hoogte van wat er nodig is om een volledig nieuw cluster te bouwen.
- Maak een controlelijst met implementatie-eenheden. Uw lijst is uniek voor uw behoeften, maar moet implementatiescripts, opnameverbindingen, BI-hulpprogramma's en andere belangrijke configuraties bevatten.