Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Azure DevOps Services biedt ontwikkelhulpprogramma's voor samenwerking, zoals krachtige pijplijnen, gratis privé-Git-opslagplaatsen, configureerbare Kanbanborden en uitgebreide geautomatiseerde en continue testmogelijkheden. Azure Pipelines is een Azure DevOps-functie waarmee u CI/CD kunt beheren om uw code te implementeren met krachtige pijplijnen die werken met elke taal, platform en cloud. Azure Data Explorer - Pijplijnhulpprogramma's is de Azure Pipelines-taak waarmee u release-pijplijnen kunt maken en uw databasewijzigingen kunt implementeren in uw Azure Data Explorer-databases. Het is gratis beschikbaar in Visual Studio Marketplace. De extensie bevat de volgende basistaken:
Azure Data Explorer-opdracht - Beheerdersopdrachten uitvoeren op een Azure Data Explorer-cluster
Azure Data Explorer-query - Query's uitvoeren op een Azure Data Explorer-cluster en de resultaten parseren
Poort van de Azure Data Explorer-queryserver: een taak zonder agent om releases te beheersen afhankelijk van het resultaat van de query.
In dit document wordt een eenvoudig voorbeeld beschreven van het gebruik van de taak Azure Data Explorer - Pijplijnhulpprogramma's om schemawijzigingen in uw database te implementeren. Raadpleeg de Documentatie van Azure DevOps voor volledige CI/CD-pijplijnen.
Vereiste voorwaarden
- Een Azure-abonnement. Maak een gratis Azure-account.
- Een Azure Data Explorer-cluster en -database. Een cluster en database maken.
- Azure Data Explorer-cluster instellen:
- Maak een Microsoft Entra-app door een Microsoft Entra-toepassing in te richten.
- Verken toegang tot uw Microsoft Entra-app in uw Azure Data Explorer-database door machtigingen voor azure Data Explorer-databases te beheren.
- Azure DevOps instellen:
- Installatie van extensie:
Als u de eigenaar van het Azure DevOps-exemplaar bent, installeert u de extensie vanuit Marketplace, neemt u anders contact op met de eigenaar van uw Azure DevOps-exemplaar en vraagt u deze te installeren.

Uw inhoud voorbereiden voor release
U kunt de volgende methoden gebruiken om beheerdersopdrachten uit te voeren op een cluster binnen een taak:
Gebruik een zoekpatroon om meerdere opdrachtbestanden op te halen uit een lokale agentmap (bouw bronnen of releaseartefacten). De optie met één regel ondersteunt meerdere bestanden met één opdracht per bestand.

Schrijf opdrachten inline.
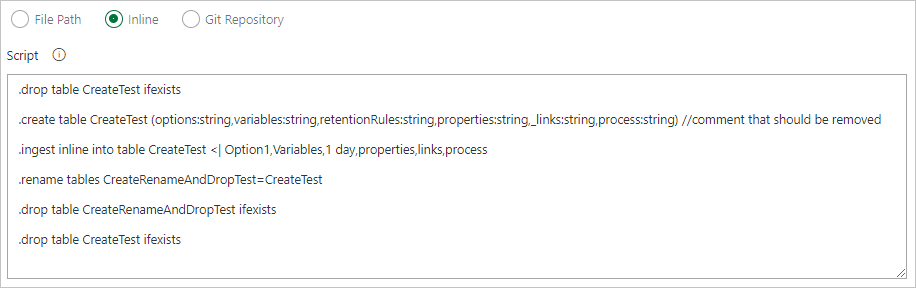
Geef een bestandspad op om opdrachtbestanden rechtstreeks vanuit Git-broncodebeheer op te halen (aanbevolen).
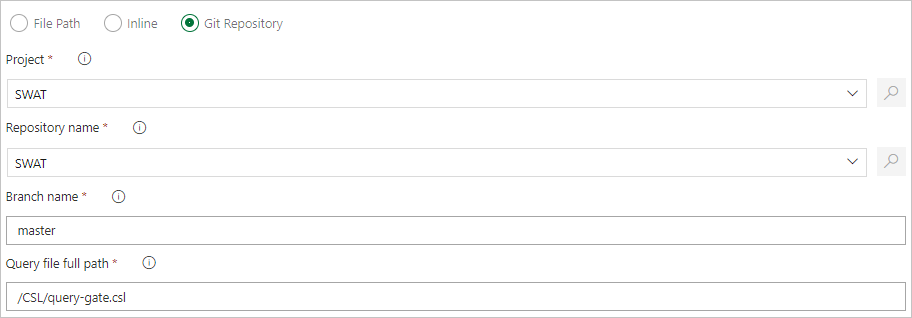
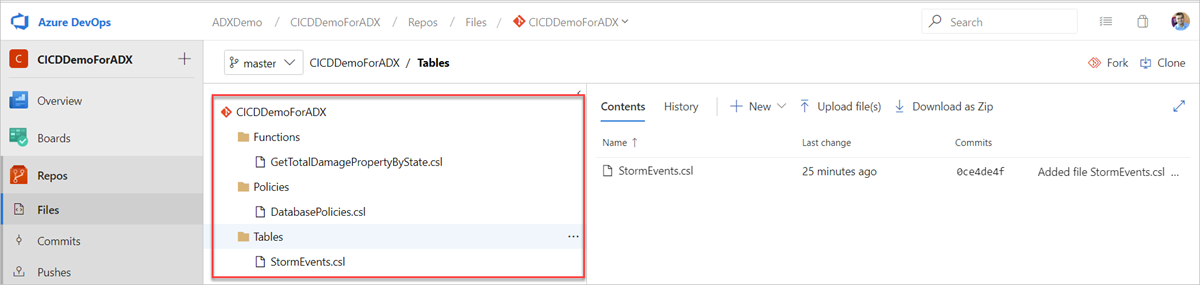
Maak de volgende voorbeeldmappen (Functies, Beleid, Tabellen) in uw Git-opslagplaats. Kopieer de bestanden uit de opslagplaats met voorbeelden naar de respectieve mappen en voer de wijzigingen door. De voorbeeldbestanden worden geleverd om de volgende werkstroom uit te voeren.
Aanbeveling
Wanneer u uw eigen werkstroom maakt, wordt u aangeraden uw code idempotent te maken. Gebruik bijvoorbeeld
.create-merge tablein plaats van.create table, en gebruik de.create-or-alterfunctie in plaats van de.createfunctie.
Een release-pijplijn maken
Meld u aan bij uw Azure DevOps-organisatie.
Selecteer Pijplijnreleases> in het menu aan de linkerkant en selecteer vervolgens Nieuwe pijplijn.
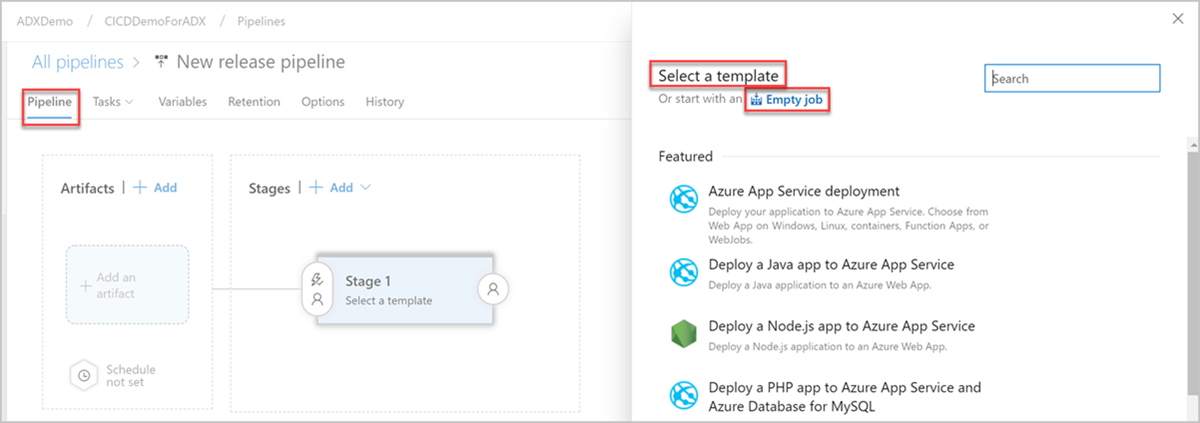
Het venster Nieuwe releasepijplijn wordt geopend. Selecteer op het tabblad Pijplijnen in het deelvenster Sjabloon selecteren de optie Lege taak.
Klik op de knop Fase. Voeg in het deelvenster Fase de fasenaam toe en selecteer Opslaan om uw pijplijn op te slaan.
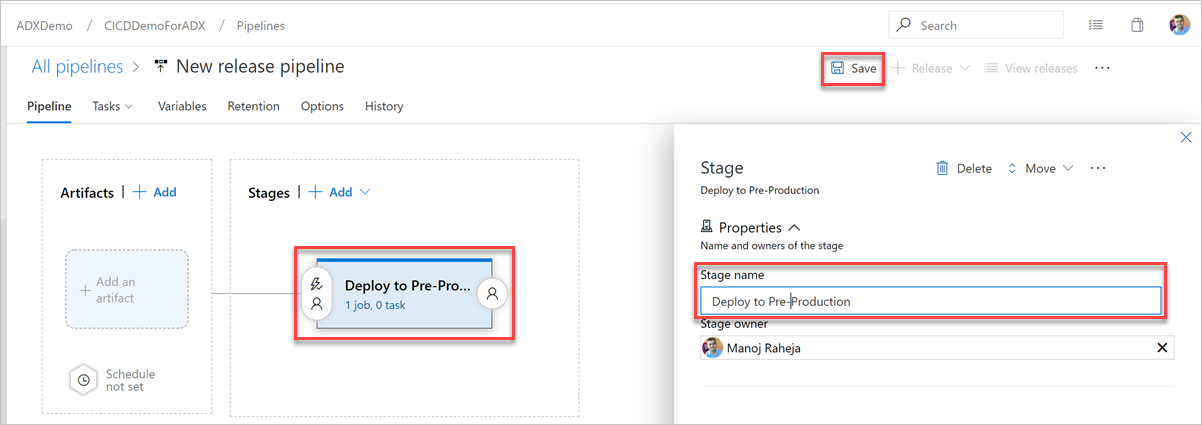
Selecteer De knop Een artefact toevoegen . Selecteer in het deelvenster Een artefact toevoegen de opslagplaats waar uw code zich bevindt, vul relevante informatie in en selecteer Toevoegen. Selecteer Opslaan om uw pijplijn op te slaan.
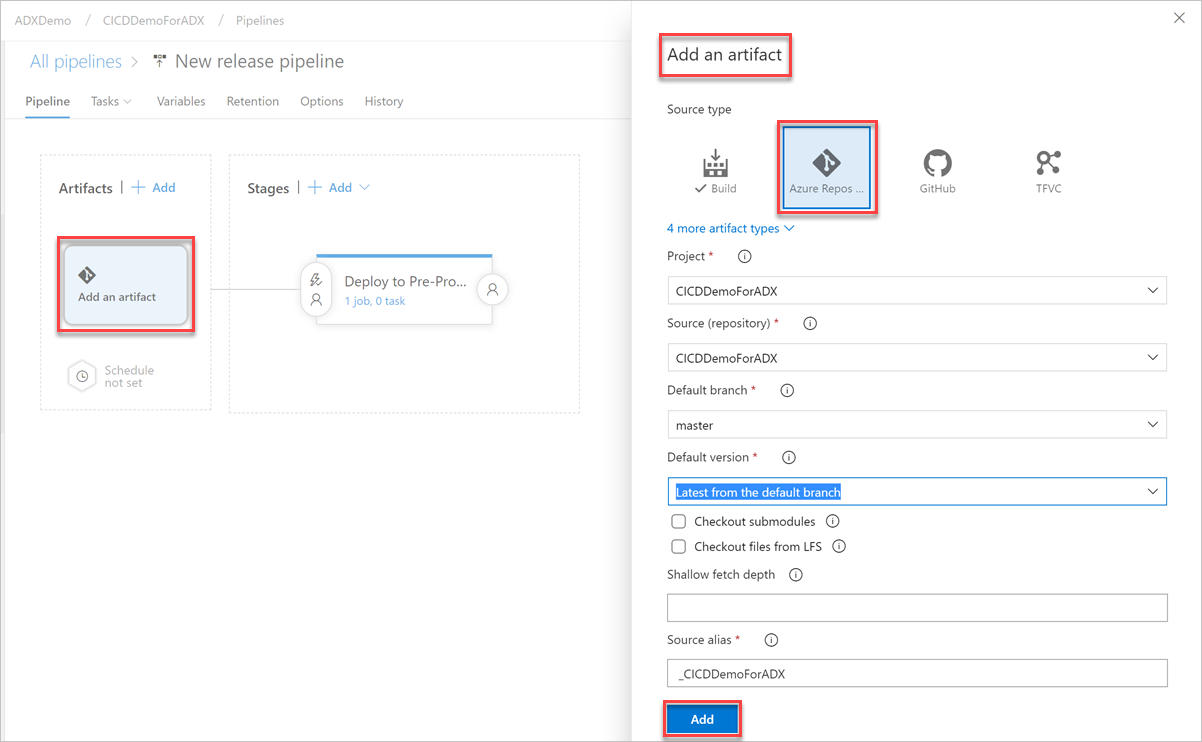
Selecteer + Toevoegen op het tabblad Variabelen om een variabele te maken voor eindpunt-URL die in de taak wordt gebruikt. Voer de naam en waarde van het eindpunt in en selecteer Opslaan om uw pijplijn op te slaan.
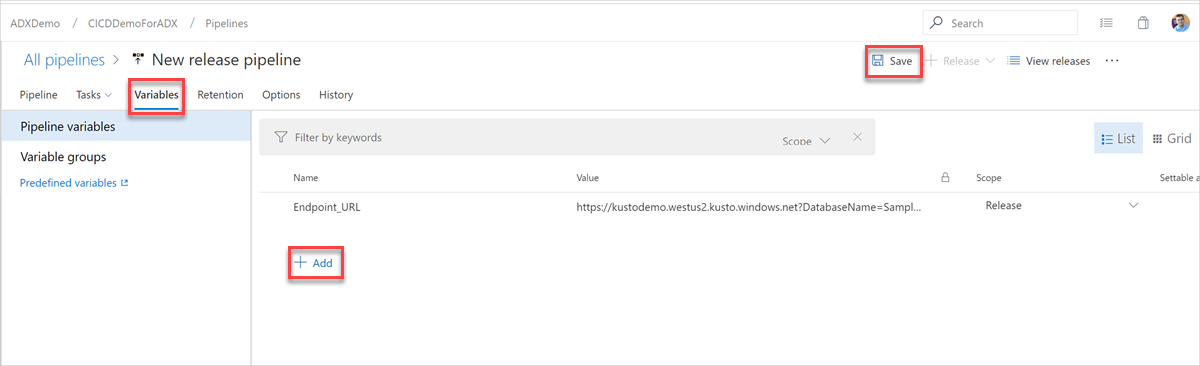
Als u de eindpunt-URL wilt vinden, gaat u naar de overzichtspagina van uw Azure Data Explorer-cluster in Azure Portal en kopieert u de cluster-URI. Maak de variabele-URI in de volgende indeling
https://<ClusterURI>?DatabaseName=<DBName>. Bijvoorbeeld https://kustodocs.westus.kusto.windows.net?DatabaseName=SampleDB
Een taak maken, de mappen implementeren
Selecteer op het tabblad Pijplijn1 taak, 0 taak om taken toe te voegen.
Herhaal de volgende stappen om opdrachttaken te maken om bestanden te implementeren vanuit de mappen Tabellen, Functies en Beleid :
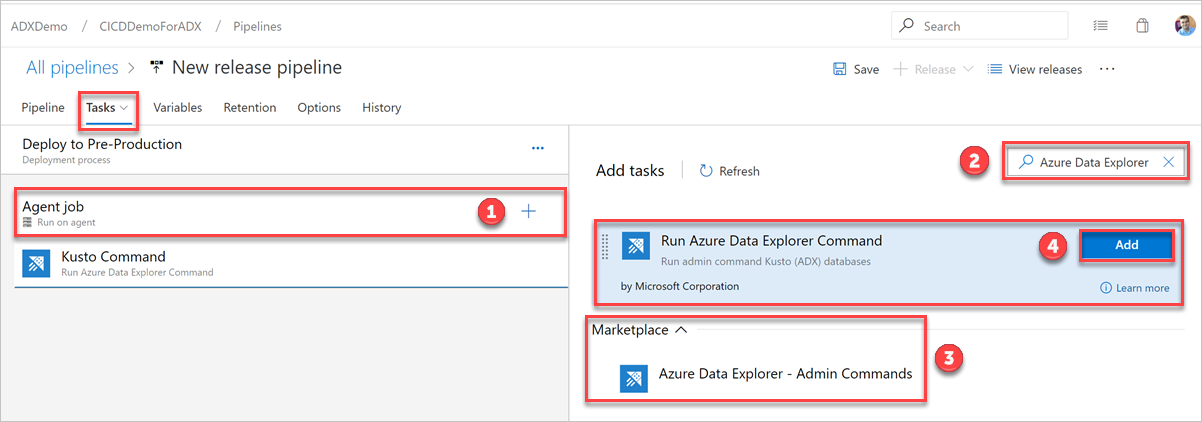
Selecteer op het tabblad + op agenttaak en zoek naar Azure Data Explorer.
Selecteer Toevoegen onder Opdracht Azure Data Explorer uitvoeren.
Selecteer Kusto Command en werk de taak bij met de volgende informatie:
Weergavenaam: Naam van de taak. Bijvoorbeeld,
Deploy <FOLDER>waarbij<FOLDER>de naam is van de map voor de implementatietaak die u creëert.Bestandspad: Geef voor elke map het pad op zoals
*/<FOLDER>/*.cslwaar<FOLDER>de relevante map voor de taak is.Eindpunt-URL: Geef de
EndPoint URLvariabele op die u in de vorige stap hebt gemaakt.Service-eindpunt gebruiken: selecteer deze optie.
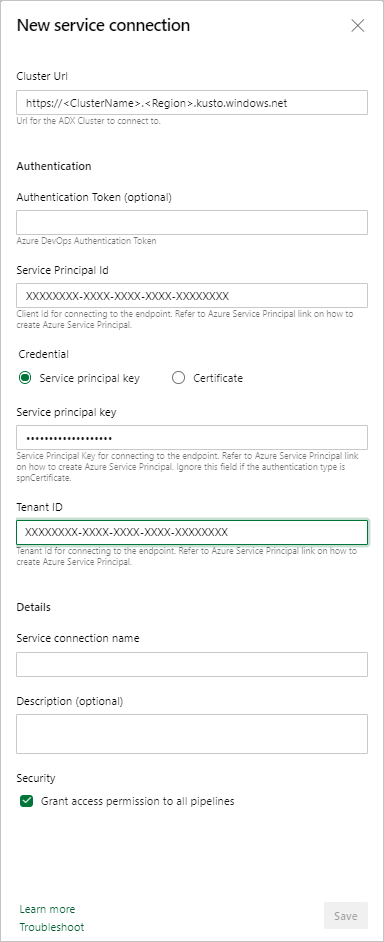
Service-eindpunt: selecteer een bestaand service-eindpunt of maak een nieuw service-eindpunt (+ Nieuw) met de volgende informatie in het venster Azure Data Explorer-serviceverbinding toevoegen :
Configuratie Voorgestelde waarde Verificatiemethode Stel Federatieve identiteitsreferenties (FIC) in (aanbevolen) of selecteer Service Principal-authenticatie (SPA). Verbindingsnaam Voer een naam in om dit service-eindpunt te identificeren Cluster-URL De waarde vindt u in de overzichtssectie van uw Azure Data Explorer-cluster in Azure Portal Service-principal-id Voer de Microsoft Entra-app-id in (gemaakt als vereiste) App-sleutel voor service-principal Voer de Microsoft Entra-applicatiesleutel in (gemaakt als vereiste vooraf) Microsoft Entra tenant-ID Voer uw Microsoft Entra-tenant in (bijvoorbeeld microsoft.com of contoso.com)
Schakel het selectievakje Alle pijplijnen toestaan om deze verbinding te gebruiken in en selecteer vervolgens OK.
Als uw beheeropdrachten langlopende asynchrone bewerkingen zijn, schakelt u het selectievakje Wachten op voltooien van lange asynchrone beheeropdrachten in. Wanneer deze functie is ingeschakeld, wordt de status van de bewerking opgevraagd met behulp van
.show operationstotdat de bewerking is voltooid.
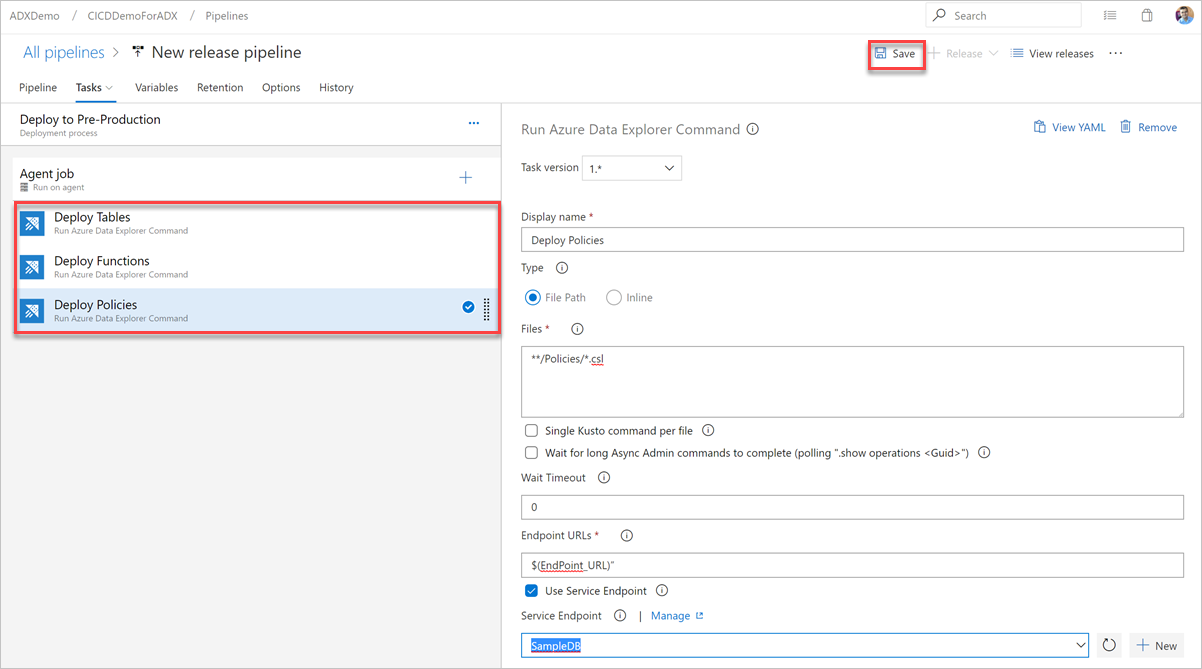
Selecteer Opslaan en controleer vervolgens op het tabblad Taken of er drie taken zijn: Tabellen implementeren, Functies implementeren en Beleid implementeren.
Een querytaak maken
Maak indien nodig een taak om een query uit te voeren op het cluster. Het uitvoeren van query's in een build- of release-pijplijn kan worden gebruikt om een gegevensset te valideren en een stap te laten slagen of mislukken op basis van de queryresultaten. De criteria voor het slagen van taken kunnen zijn gebaseerd op een drempelwaarde voor het aantal rijen of één waarde, afhankelijk van wat de query retourneert.
Selecteer op het tabblad + op agenttaak en zoek naar Azure Data Explorer.
Selecteer Toevoegen onder Azure Data Explorer-query uitvoeren.
Selecteer Kusto-query en werk de taak bij met de volgende informatie:
- Weergavenaam: Naam van de taak. Bijvoorbeeld : Querycluster.
- Type: Selecteer Inline.
- Query: Voer de query in die u wilt uitvoeren.
-
Eindpunt-URL: Geef de
EndPoint URLvariabele op die u eerder hebt gemaakt. - Service-eindpunt gebruiken: selecteer deze optie.
- Service-eindpunt: selecteer een service-eindpunt.
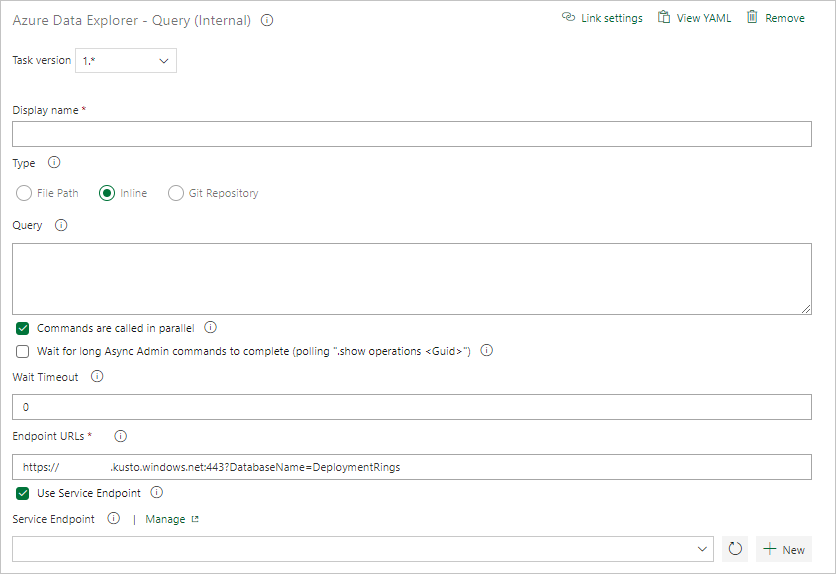
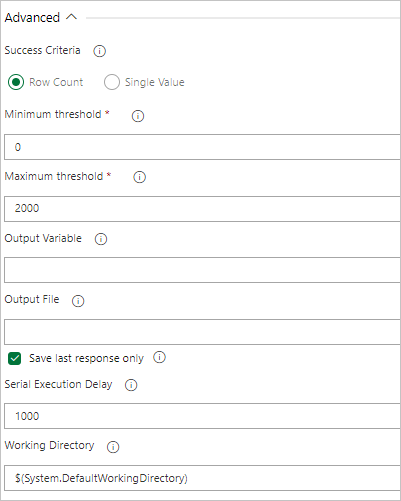
Selecteer onder Taakresultaten de succescriteria van de taak op basis van de resultaten van uw query, als volgt:
Als uw query rijen retourneert, selecteert u Aantal rijen en geeft u de criteria op die u nodig hebt.
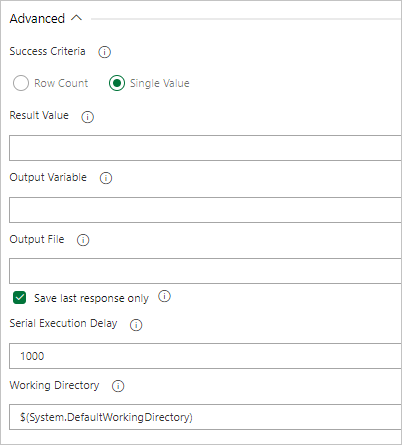
Als uw query een waarde retourneert, selecteert u Enkele waarde en geeft u het verwachte resultaat op.
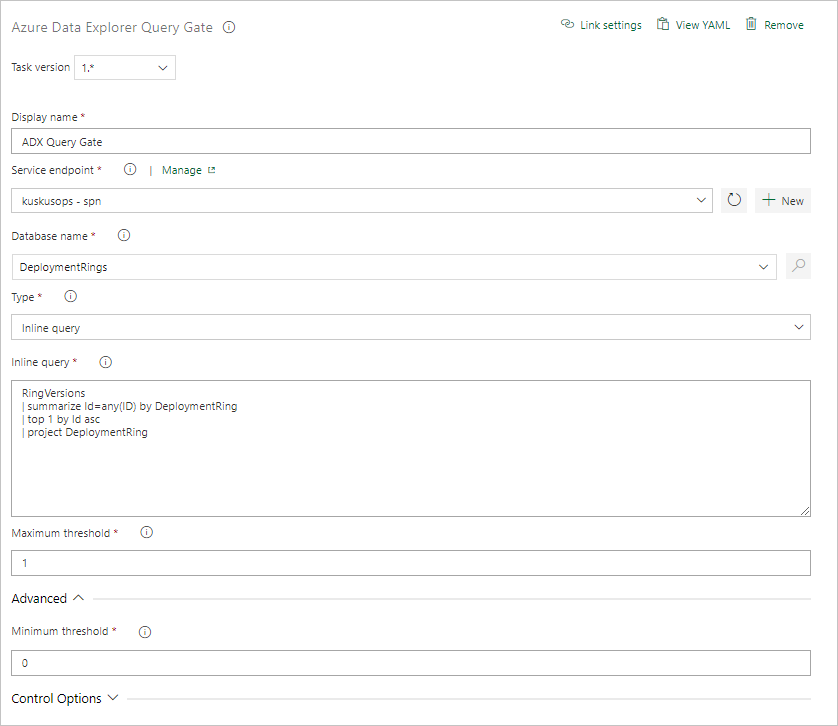
Een Query Server Gate-taak maken
Maak zo nodig een taak om een query uit te voeren op een cluster en beheers de releasevoortgang afhankelijk van het aantal rijen in de queryresultaten. De serverquerypoorttaak is een taak zonder agent, wat betekent dat de query rechtstreeks op de Azure DevOps-server wordt uitgevoerd.
Selecteer op het tabblad Taken een + en zoek naar Azure Data Explorer.
Onder de optie Voer Azure Data Explorer-queryserverpoort uit, selecteer Toevoegen.
Selecteer Kusto Query Server Gate en selecteer vervolgens Server Gate Test.
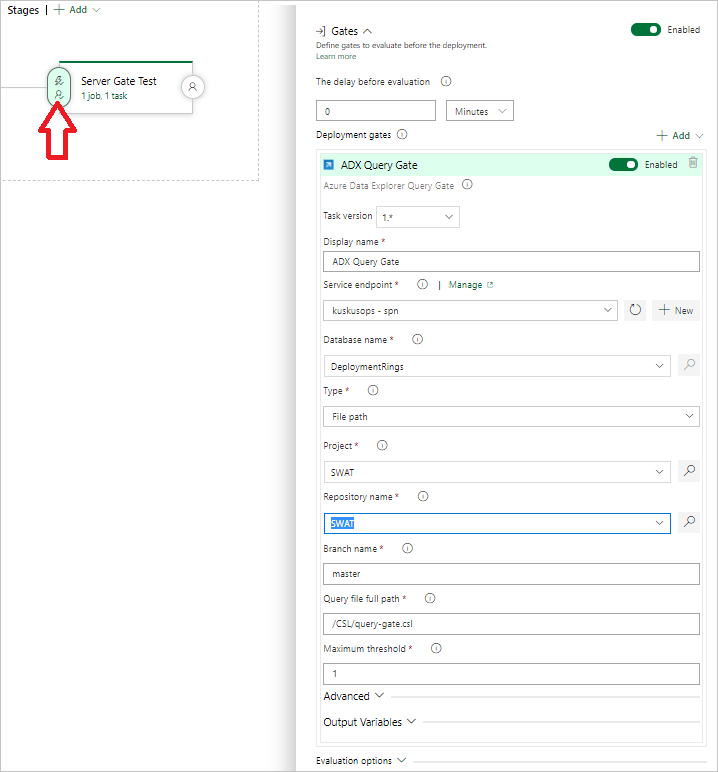
Configureer de taak met de volgende informatie:
- Weergavenaam: Naam van de poort.
- Service-eindpunt: selecteer een service-eindpunt.
- Databasenaam: Geef de databasenaam op.
- Type: Selecteer inlinequery.
- Query: Voer de query in die u wilt uitvoeren.
- Maximumdrempelwaarde: geef het maximumaantal rijen op voor de succescriteria van de query.
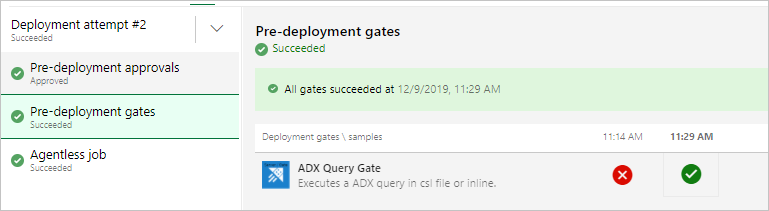
Opmerking
U zou resultaten zoals de onderstaande moeten zien wanneer u de release uitvoert.
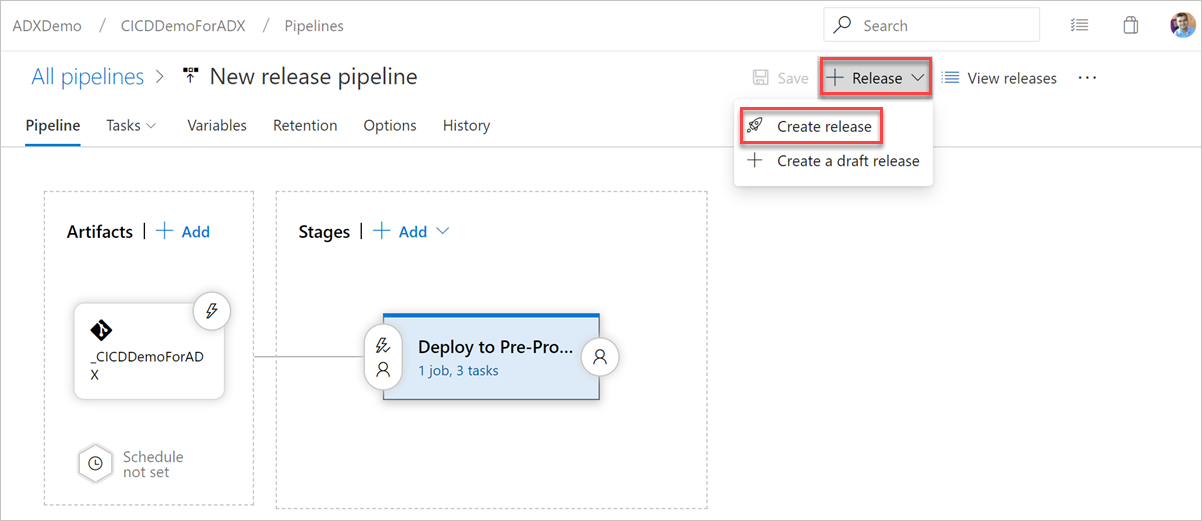
De release uitvoeren
Selecteer + Release>maken om een release te starten.
Controleer op het tabblad Logboeken of de implementatiestatus is geslaagd.
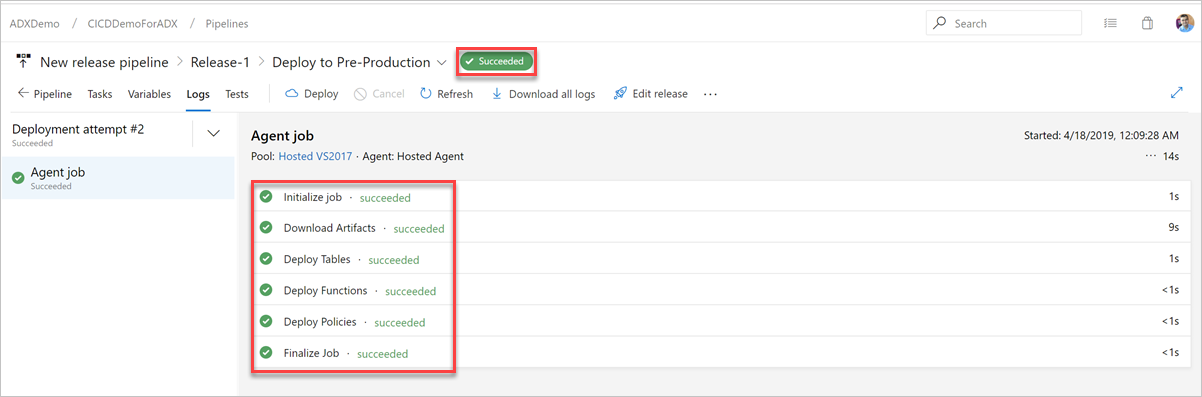
Nu is het maken van een release-pijplijn voor implementatie naar preproductie voltooid.
Ondersteuning voor sleutelloze verificatie voor Azure Data Explorer DevOps-taken
De extensie ondersteunt sleutelloze verificatie voor Azure Data Explorer-clusters. Met sleutelloze verificatie kunt u verifiëren bij Azure Data Explorer-clusters zonder een sleutel te gebruiken. Het is veiliger en eenvoudiger te beheren.
Opmerking
Kusto Fabric-cluster-URL's worden niet ondersteund voor WIF-verificatie (Workload Identity Federation) en Beheerde identiteit.
FIC-verificatie (Federated Identity Credentials) gebruiken in een Azure Data Explorer-serviceverbinding
Opmerking
Vanaf extensieversie 4.0.x biedt het Azure Data Explorer-service-eindpunt ondersteuning voor WIF-verificatie (Workload Identity Federation) naast Service Principal Authentication.
Ga in uw DevOps-exemplaar naar Project Settings>Service-verbindingen>Nieuwe serviceverbinding>met Azure Data Explorer.
Selecteer Federatieve identiteitsreferenties en voer de cluster-URL, service-principal-id, tenant-id, naam van een serviceverbinding in en selecteer Opslaan.
Open in Azure Portal de Microsoft Entra-app voor de opgegeven service-principal.
Selecteer onder Certificaten en geheimenfederatieve referenties.
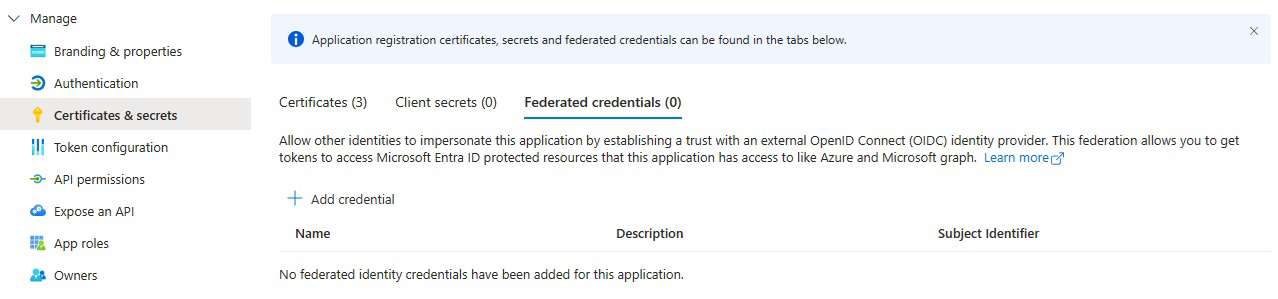
Selecteer Referentie toevoegen en selecteer vervolgens voor het scenario met federatieve referenties de optie Andere verlener en vul de instellingen in met behulp van de volgende informatie:
Uitgever:
<https://vstoken.dev.azure.com/{System.CollectionId}>waarbij{System.CollectionId}de verzameling-ID is van uw Azure DevOps-organisatie. U vindt de verzamelings-id op de volgende manieren:- Selecteer in de klassieke Release-pijplijn van Azure DevOps de optie Initialize-taak. De verzamelings-id wordt weergegeven in de logboeken.
Onderwerp-id:
<sc://{DevOps_Org_name}/{Project_Name}/{Service_Connection_Name}>waar{DevOps_Org_name}is de naam van de Azure DevOps-organisatie,{Project_Name}de projectnaam en{Service_Connection_Name}is de serviceverbindingsnaam die u eerder hebt gemaakt.Opmerking
Als er ruimte in de naam van de serviceverbinding staat, kunt u deze gebruiken met de ruimte in het veld. Voorbeeld:
sc://MyOrg/MyProject/My Service Connection.Naam: Voer een naam in voor de referentie.
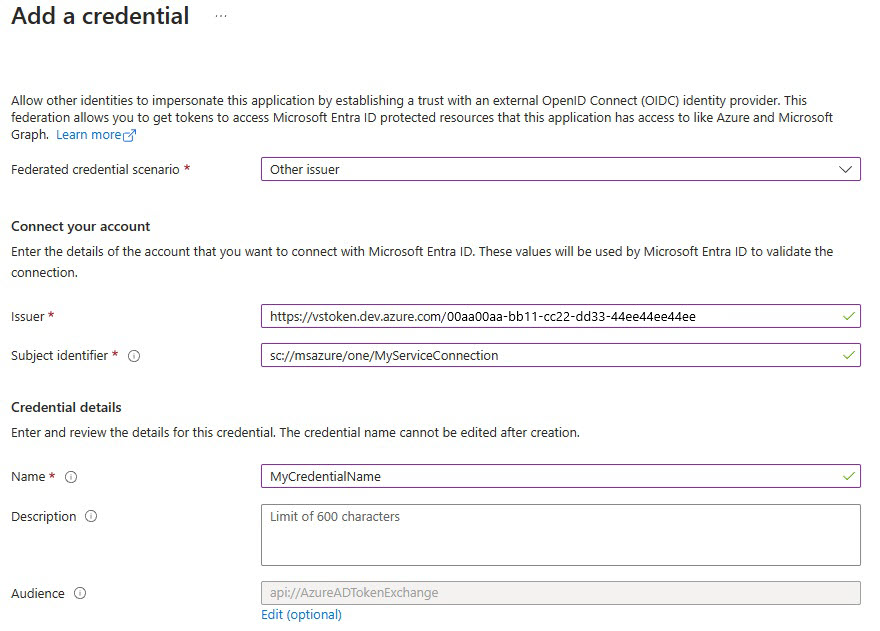
Selecteer Toevoegen.
Federatieve identiteitsreferenties of beheerde identiteit gebruiken in een AZURE Resource Manager-serviceverbinding (ARM)
Ga in uw DevOps-exemplaar naar Project Settings>Service-verbindingen>nieuwe serviceverbinding>met Azure Resource Manager.
Selecteer onder de Verificatiemethode, Workload Identiteitsfederatie (automatisch) om door te gaan. U kunt ook de handmatige optie Workload Identity Federation (handmatig) gebruiken om de details van de workloadidentiteitsfederatie en de optie Beheerde identiteit op te geven. Meer informatie over het instellen van een beheerde identiteit met behulp van Azure Resource Management in Azure Resource Manager -serviceverbindingen (ARM).
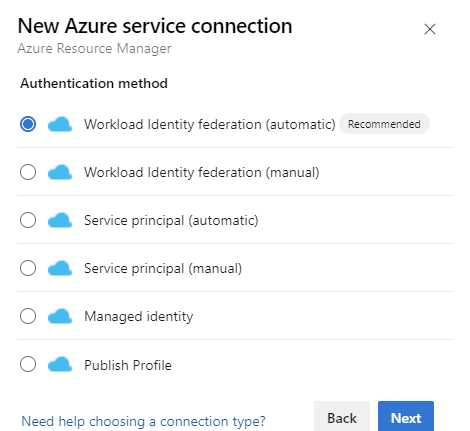
Vul de vereiste gegevens in, selecteer Verifiëren en selecteer Opslaan.
YAML-pijplijnconfiguratie
U kunt taken configureren met behulp van de Azure DevOps-webgebruikersinterface of YAML-code in het pijplijnschema.
De extensie biedt drie pijplijntaken die allemaal toegankelijk zijn via YAML:
-
Azure Data Explorer-opdracht (
ADXAdminCommand@5) - Beheer-/beheeropdrachten uitvoeren op een ADX-cluster - Azure Data Explorer-query : query's uitvoeren op een ADX-cluster en de resultaten parseren
- Azure Data Explorer-queryserverpoort — agentloze taak om releases te beheersen, afhankelijk van het queryresultaat
Aanbeveling
Voor verbeterde beveiliging kunt u Workload Identity Federation of Managed Identity authenticatie gebruiken via een Azure Resource Manager-serviceverbinding in plaats van inloggegevens direct in de pipeline op te slaan. Deze sleutelloze verificatiemethoden zijn de aanbevolen best practice.
Voorbeeld van beheerderopdracht — inline-opdrachten
In het volgende voorbeeld wordt een inlinebeheerdersopdracht uitgevoerd met behulp van een Azure Resource Manager-serviceverbinding (ARM), die ondersteuning biedt voor WIF-verificatie (Workload Identity Federation) en Managed Identity:
steps:
- task: Azure-Kusto.ADXAdminCommands.PublishToADX.ADXAdminCommand@5
displayName: 'Run inline ADX admin command'
inputs:
clusterUri: 'https://<ClusterName>.<Region>.kusto.windows.net'
databaseName: '<DatabaseName>'
commandsSource: 'inline'
inlineCommands: |
.create-merge table MyTable (Id:int, Name:string, Timestamp:datetime)
.create-or-alter function MyFunction() { MyTable | take 10 }
azureSubscription: '<ARM Service Connection Name>'
continueOnError: true
Voorbeeld van beheeropdracht - opdrachten op basis van bestanden
In het volgende voorbeeld worden beheerdersopdrachten uitgevoerd van bestanden die overeenkomen met een glob-patroon, met behulp van AAD-app-registratieverificatie:
steps:
- task: Azure-Kusto.ADXAdminCommands.PublishToADX.ADXAdminCommand@5
displayName: 'Deploy schema from files'
inputs:
clusterUri: 'https://<ClusterName>.<Region>.kusto.windows.net'
databaseName: '<DatabaseName>'
commandsSource: 'files'
commandFilesPattern: '**/*.csl'
aadAppId: '$(AAD_APP_ID)'
aadAppKey: '$(AAD_APP_KEY)'
aadTenantId: '$(AAD_TENANT_ID)'
continueOnError: true
U kunt ook als het glob-patroon gebruiken **/*.kql , afhankelijk van de naamgevingsconventie van uw bestand.
Voorbeeld van beheeropdracht - Azure Resource Manager-serviceverbinding
In het volgende voorbeeld wordt een Azure Resource Manager-serviceverbinding gebruikt, die ondersteuning biedt voor WIF (Workload Identity Federation) en Managed Identity voor sleutelloze verificatie:
steps:
- task: Azure-Kusto.ADXAdminCommands.PublishToADX.ADXAdminCommand@5
displayName: 'Deploy schema via ARM service connection'
inputs:
clusterUri: 'https://<ClusterName>.<Region>.kusto.windows.net'
databaseName: '<DatabaseName>'
commandsSource: 'files'
commandFilesPattern: '**/*.csl'
azureSubscription: '<ARM Service Connection Name>'
continueOnError: true
condition: ne(variables['ProductVersion'], '')
Taakinvoerparameters
In de volgende tabel worden de belangrijkste invoerparameters voor de ADXAdminCommand@5 taak beschreven:
| Kenmerk | Beschrijving |
|---|---|
clusterUri |
De basis-URI voor het Kusto-cluster (bijvoorbeeld https://<ClusterName>.<Region>.kusto.windows.net) |
databaseName |
De naam van de doeldatabase |
commandsSource |
De bron van opdrachten: inline voor inline KQL-opdrachten of files voor op bestanden gebaseerde opdrachten |
inlineCommands |
Inline KQL-opdrachten die moeten worden uitgevoerd (gebruikt wanneer commandsSource is inline) |
commandFilesPattern |
Glob-patroon voor scriptbestanden (gebruikt wanneer commandsSource is files), bijvoorbeeld **/*.csl of **/*.kql |
aadAppId |
De ID van de Microsoft Entra-app (service-principal) voor AAD-applicatie-authenticatie |
aadAppKey |
De Microsoft Entra-app-sleutel/-geheim voor AAD-app-verificatie |
aadTenantId |
De Microsoft Entra-tenant-id voor AAD-app-verificatie |
azureSubscription |
De naam van de Azure Resource Manager-serviceverbinding voor OP ARM gebaseerde verificatie (ondersteunt WIF en Managed Identity) |
Verificatiemethoden
De extensie ondersteunt de volgende verificatiemethoden:
- nl-NL: AAD-app-registratie (Azure Active Directory): gebruik
aadAppId,aadAppKey, enaadTenantIdom te verifiëren met een service-principal. Sla referenties op als beveiligde pijplijnvariabelen. - Verificatie op basis van certificaten : gebruik een certificaat in plaats van een app-sleutel voor service-principal-verificatie. Sla de certificaatgegevens op als beveiligde pijplijnvariabelen.
-
Beheerde identiteit : gebruik een Azure Resource Manager-serviceverbinding die is geconfigureerd met beheerde identiteit. Stel de
azureSubscriptioninvoer in op de naam van de serviceverbinding. -
WIF (Workload Identity Federation): gebruik een Azure Resource Manager-serviceverbinding met workloadidentiteitsfederatie (automatisch of handmatig). Dit is de aanbevolen sleutelloze benadering. Stel de
azureSubscriptioninvoer in op de naam van de serviceverbinding.
Opmerking
WIF (Workload Identity Federation) is een nieuwere toevoeging aan de extensie. Het maakt geheimloze verificatie mogelijk en is de aanbevolen benadering voor nieuwe pijplijnen. Zie Federatieve identiteitsreferenties of beheerde identiteit gebruiken in een Azure Resource Manager-serviceverbinding (ARM) voor installatie-instructies.
Queryvoorbeeld
steps:
- task: Azure-Kusto.PublishToADX.ADXQuery.ADXQuery@5
displayName: '<Task Display Name>'
inputs:
targetType: 'inline'
script: |
let badVer=
RunnersLogs | where Timestamp > ago(30m)
| where EventText startswith "$$runnerresult" and Source has "ShowDiagnostics"
| extend State = extract(@"Status='(.*)', Duration.*",1, EventText)
| where State == "Unhealthy"
| extend Reason = extract(@'"NotHealthyReason":"(.*)","IsAttentionRequired.*',1, EventText)
| extend Cluster = extract(@'Kusto.(Engine|DM|CM|ArmResourceProvider).(.*).ShowDiagnostics',2, Source)
| where Reason != "Merge success rate past 60min is < 90%"
| where Reason != "Ingestion success rate past 5min is < 90%"
| where Reason != "Ingestion success rate past 5min is < 90%, Merge success rate past 60min is < 90%"
| where isnotempty(Cluster)
| summarize max(Timestamp) by Cluster,Reason
| order by max_Timestamp desc
| where Reason startswith "Differe"
| summarize by Cluster
;
DimClusters | where Cluster in (badVer)
| summarize by Cluster , CmConnectionString , ServiceConnectionString ,DeploymentRing
| extend ServiceConnectionString = strcat("#connect ", ServiceConnectionString)
| where DeploymentRing == "$(DeploymentRing)"
kustoUrls: 'https://<ClusterName>.kusto.windows.net?DatabaseName=<DatabaseName>'
authType: 'kustoserviceconn'
connectedServiceName: '<connection service name>'
minThreshold: '0'
maxThreshold: '10'
continueOnError: true