Gegevensstromen bewaken
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Nadat u klaar bent met het bouwen en opsporen van fouten in uw gegevensstroom, wilt u de gegevensstroom plannen om uit te voeren volgens een planning binnen de context van een pijplijn. U kunt de pijplijn plannen met triggers. Voor het testen en opsporen van fouten in uw gegevensstroom vanuit een pijplijn, kunt u de knop Foutopsporing gebruiken op het werkbalklint of de optie Nu activeren vanuit de opbouwfunctie voor pijplijnen om een uitvoering met één uitvoering uit te voeren om uw gegevensstroom binnen de pijplijncontext te testen.
Wanneer u uw pijplijn uitvoert, kunt u de pijplijn en alle activiteiten in de pijplijn bewaken, inclusief de Gegevensstroom activiteit. Selecteer het monitorpictogram in het linkerdeelvenster van de gebruikersinterface. U kunt een scherm zien dat lijkt op het scherm dat volgt. Met de gemarkeerde pictogrammen kunt u inzoomen op de activiteiten in de pijplijn, inclusief de Gegevensstroom activiteit.
U ziet statistieken op dit niveau, inclusief de uitvoeringstijden en status. De run-id op het activiteitsniveau verschilt van de run-id op pijplijnniveau. De run-id op het vorige niveau is voor de pijplijn. Als u de bril selecteert, krijgt u gedetailleerde informatie over de uitvoering van uw gegevensstroom.

Wanneer u zich in de grafische knooppuntbewakingsweergave bevindt, ziet u een vereenvoudigde versie van uw gegevensstroomgrafiek. Als u de detailweergave wilt zien met grotere grafiekknooppunten met labels voor transformatiefasen, gebruikt u de zoomschuifregelaar aan de rechterkant van het canvas. U kunt ook de zoekknop aan de rechterkant gebruiken om onderdelen van uw gegevensstroomlogica in de grafiek te vinden.
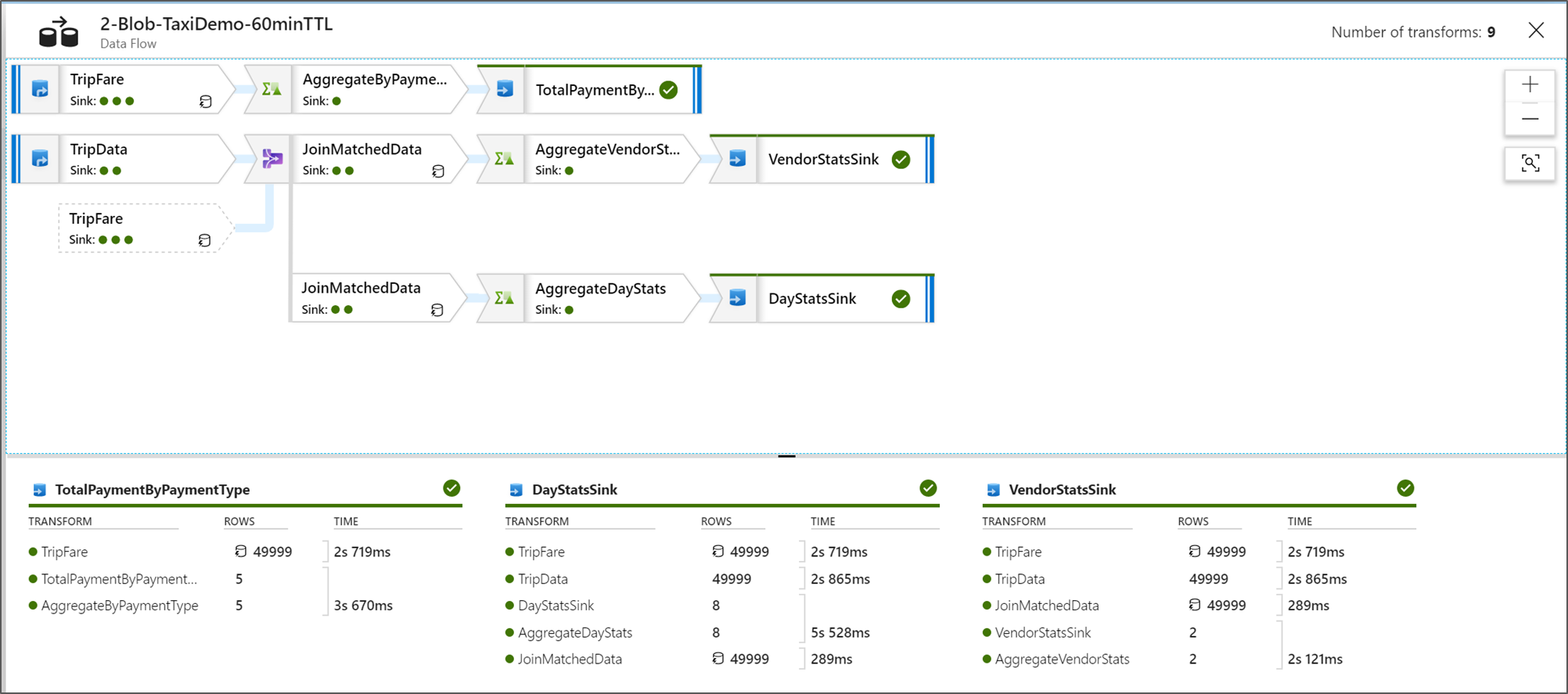
Uitvoeringsplannen voor Gegevensstroom weergeven
Wanneer uw Gegevensstroom wordt uitgevoerd in Spark, bepaalt de service optimale codepaden op basis van de gehele gegevensstroom. Daarnaast kunnen de uitvoeringspaden plaatsvinden op verschillende scale-outknooppunten en gegevenspartities. Daarom vertegenwoordigt de bewakingsgrafiek het ontwerp van uw stroom, rekening houdend met het uitvoeringspad van uw transformaties. Wanneer u afzonderlijke knooppunten selecteert, ziet u fasen die code vertegenwoordigen die samen in het cluster is uitgevoerd. De tijdsinstellingen en aantallen die u ziet, vertegenwoordigen deze groepen of fasen in plaats van de afzonderlijke stappen in uw ontwerp.
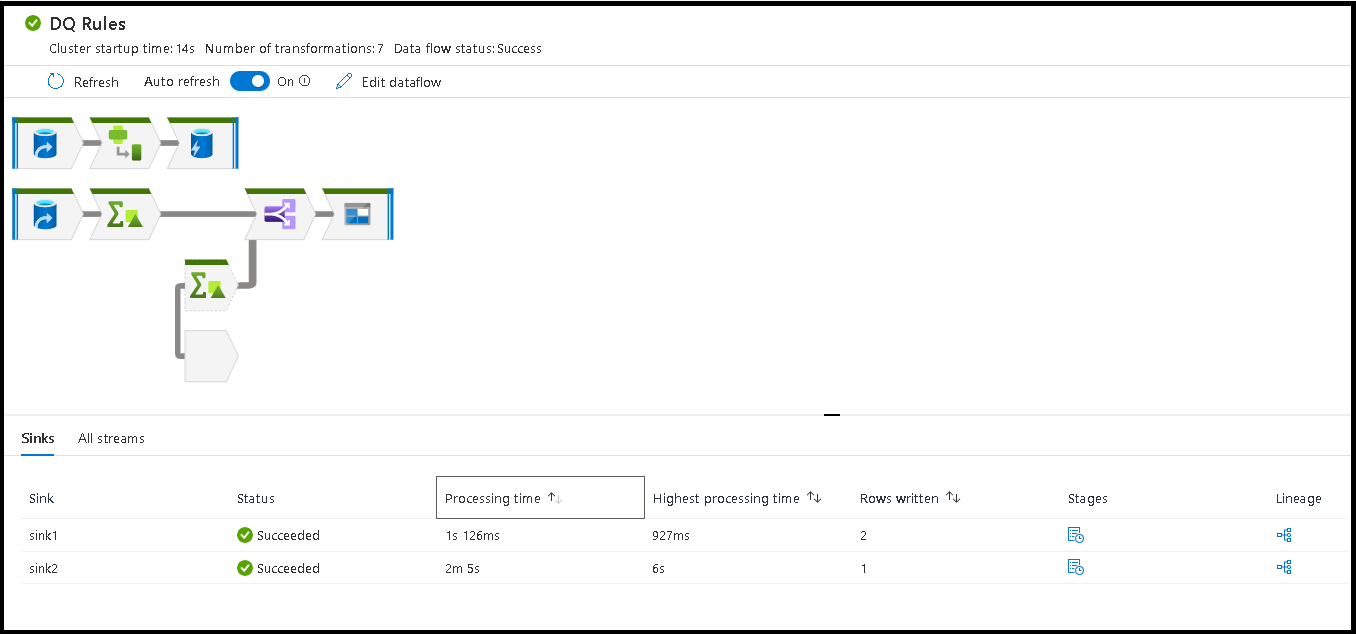
Wanneer u de open ruimte in het bewakingsvenster selecteert, worden in de statistieken in het onderste deelvenster tijdsinstellingen en rijen geteld voor elke Sink en de transformaties die hebben geleid tot de sinkgegevens voor transformatieherkomst.
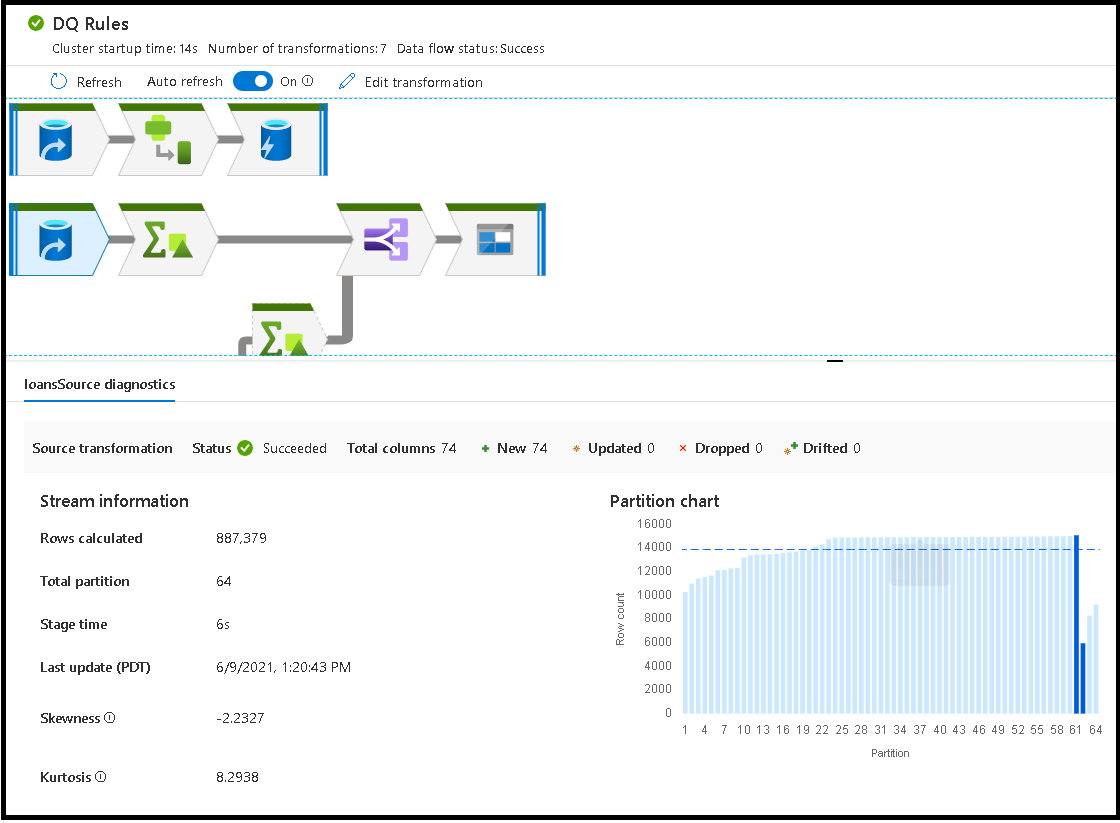
Wanneer u afzonderlijke transformaties selecteert, ontvangt u extra feedback over het rechterdeelvenster met partitiestatistieken, kolomaantallen, scheefheid (hoe gelijkmatig zijn de gegevens verdeeld over partities) en kurtosis (hoe stekelig de gegevens zijn).
Door te sorteren op verwerkingstijd kunt u bepalen welke fasen in uw gegevensstroom de meeste tijd hebben geduurd.
Als u wilt bepalen welke transformaties in elke fase de meeste tijd hebben geduurd, sorteert u op de hoogste verwerkingstijd.
De *rijen die zijn geschreven, kunnen ook worden gesorteerd als een manier om te bepalen welke stromen in uw gegevensstroom de meeste gegevens schrijven.
Wanneer u de sink selecteert in de knooppuntweergave, kunt u kolomherkomst zien. Er zijn drie verschillende methoden waarmee kolommen worden verzameld in uw gegevensstroom om in de Sink te terechtkomen. Dit zijn:
- Berekend: U gebruikt de kolom voor voorwaardelijke verwerking of binnen een expressie in uw gegevensstroom, maar niet in de sink
- Afgeleid: De kolom is een nieuwe kolom die u in uw stroom hebt gegenereerd. De kolom is dus niet aanwezig in de bron
- Toegewezen: De kolom is afkomstig van de bron en u wijst deze toe aan een sinkveld
- Status van gegevensstroom: de huidige status van uw uitvoering
- Opstarttijd van het cluster: De hoeveelheid tijd die nodig is om de JIT Spark-rekenomgeving te verkrijgen voor de uitvoering van uw gegevensstroom
- Aantal transformaties: hoeveel transformatiestappen worden uitgevoerd in uw stroom

Totale verwerkingstijd voor sinks versus de verwerkingstijd voor transformaties
Elke transformatiefase bevat een totale tijd voor die fase die moet worden voltooid met elke totale uitvoeringstijd van de partitie. Wanneer u de sink selecteert, ziet u 'Sink verwerkingstijd'. Deze tijd omvat het totaal van de transformatietijd plus de I/O-tijd die nodig was om uw gegevens naar uw doelarchief te schrijven. Het verschil tussen de sinkverwerkingstijd en het totaal van de transformatie is de I/O-tijd voor het schrijven van de gegevens.
U kunt ook gedetailleerde tijdsinstellingen zien voor elke stap voor partitietransformatie als u de JSON-uitvoer van uw gegevensstroomactiviteit opent in de weergave pijplijnbewaking. De JSON bevat milliseconden voor elke partitie, terwijl de UX-bewakingsweergave een cumulatieve tijdsinstelling is van partities die samen worden toegevoegd:
{
"stage": 4,
"partitionTimes": [
14353,
14914,
14246,
14912,
...
]
}
Verwerkingstijd sink
Wanneer u een sinktransformatiepictogram in uw kaart selecteert, ziet u in het deelvenster aan de rechterkant een extra gegevenspunt met de naam 'naverwerkingstijd' onderaan. Dit is de hoeveelheid tijd die nodig is om uw taak uit te voeren op het Spark-cluster nadat uw gegevens zijn geladen, getransformeerd en geschreven. Deze tijd kan bestaan uit het sluiten van verbindingsgroepen, afsluiten van stuurprogramma's, het verwijderen van bestanden, het samenvoegen van bestanden, enzovoort. Wanneer u acties uitvoert in uw stroom, zoals 'bestanden verplaatsen' en 'uitvoer naar één bestand', ziet u waarschijnlijk een toename van de waarde voor de naverwerkingstijd.
- Duur van schrijffase: de tijd voor het schrijven van de gegevens naar een faseringslocatie voor Synapse SQL
- SQL-duur van tabelbewerking: de tijd die is besteed aan het verplaatsen van gegevens van tijdelijke tabellen naar doeltabel
- Pre SQL-duur & Post SQL-duur: de tijd die is besteed aan het uitvoeren van pre/post SQL-opdrachten
- Duur van opdrachten vooraf en duur van postopdrachten: de tijd die is besteed aan het uitvoeren van eventuele pre-/postbewerkingen voor bron/sinks op basis van bestanden. Bijvoorbeeld bestanden verplaatsen of verwijderen na verwerking.
- Duur van samenvoegen: de tijd die nodig is om het bestand samen te voegen, bestanden worden gebruikt voor sinks op basis van bestanden bij het schrijven naar één bestand of wanneer 'Bestandsnaam als kolomgegevens' wordt gebruikt. Als er aanzienlijke tijd wordt besteed aan deze metrische gegevens, moet u voorkomen dat u deze opties gebruikt.
- Fasetijd: Totale hoeveelheid tijd die in Spark is besteed om de bewerking als fase te voltooien.
- Tijdelijke fasering stabiel: naam van de tijdelijke tabel die door gegevensstromen wordt gebruikt om gegevens in de database te faseren.
Foutrijen
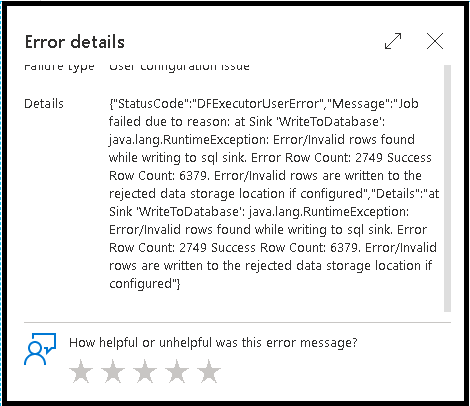
Het inschakelen van de verwerking van foutrijen in uw gegevensstroomsink wordt weerspiegeld in de bewakingsuitvoer. Wanneer u de sink instelt op geslaagde fouten, wordt in de bewakingsuitvoer het aantal geslaagde en mislukte rijen weergegeven wanneer u het knooppunt voor sinkbewaking selecteert.
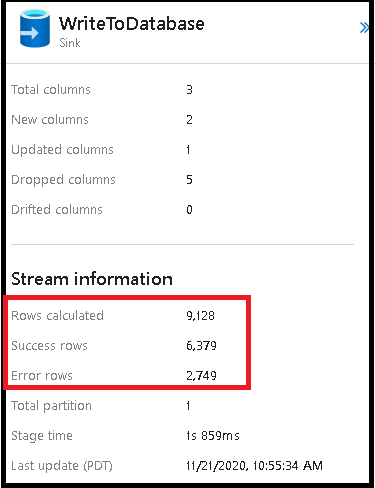
Wanneer u 'Fout melden bij fout' selecteert, wordt dezelfde uitvoer alleen weergegeven in de uitvoertekst van de activiteitscontrole. Dit komt doordat de gegevensstroomactiviteit een fout retourneert voor de uitvoering en de gedetailleerde bewakingsweergave niet beschikbaar is.
Pictogrammen bewaken
Dit pictogram betekent dat de transformatiegegevens al in de cache van het cluster zijn opgeslagen, zodat rekening is gehouden met de tijdsinstellingen en het uitvoeringspad:
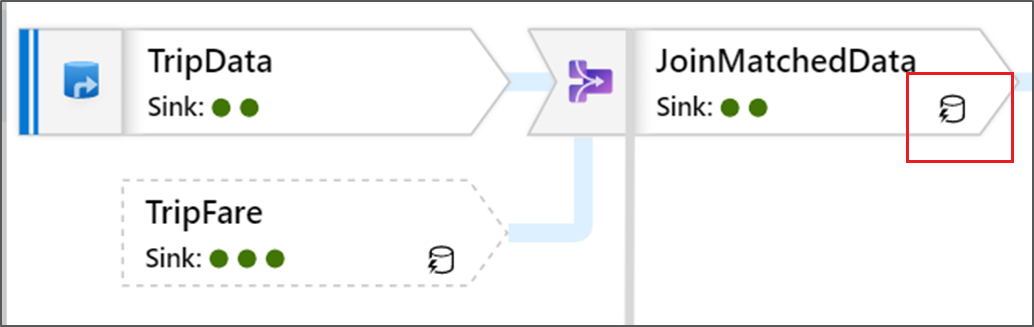
U ziet ook groene cirkelpictogrammen in de transformatie. Ze vertegenwoordigen een telling van het aantal sinks waarnaar gegevens stromen.