Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
VAN TOEPASSING OP: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is de volgende generatie van Azure Data Factory, met een eenvoudigere architectuur, ingebouwde AI en nieuwe functies. Als u nieuw bent met gegevensintegratie, begin dan met Fabric Data Factory. Bestaande ADF-workloads kunnen upgraden naar Fabric om toegang te krijgen tot nieuwe mogelijkheden voor gegevenswetenschap, realtime analyses en rapportage.
Integration Runtime (IR) is de rekeninfrastructuur die wordt gebruikt door Azure Data Factory- en Azure Synapse-pijplijnen om de volgende mogelijkheden voor gegevensintegratie in verschillende netwerkomgevingen te bieden:
- Gegevensstroom: Voer een Gegevensstroom uit in een beheerde Azure-rekenomgeving.
- Gegevensverplaatsing: Gegevens kopiëren tussen gegevensarchieven in een openbaar of particulier netwerk (voor zowel on-premises als virtuele particuliere netwerken). De service biedt ondersteuning voor ingebouwde connectors, indelingsconversie, kolomtoewijzing en effectieve en schaalbare gegevensoverdracht.
- Activiteitsverzending: verzend en bewaak transformatieactiviteiten die worden uitgevoerd op verschillende rekenservices, zoals Azure Databricks, Azure HDInsight, ML Studio (klassiek), Azure SQL Database, SQL Server en meer.
- SSIS-pakketuitvoering: systeemeigen SSIS-pakketten (SQL Server Integration Services) uitvoeren in een beheerde Azure-rekenomgeving.
In Data Factory- en Synapse-pijplijnen definieert een activiteit de actie die moet worden uitgevoerd. Een gekoppelde service definieert een doelgegevensarchief of een rekenservice. Een integratieruntime biedt de brug tussen activiteiten en gekoppelde services. De gekoppelde service of activiteit verwijst naar en biedt de rekenomgeving waarin de activiteit rechtstreeks wordt uitgevoerd of verzonden. Met deze koppeling kan de activiteit worden uitgevoerd in de dichtstbijzijnde mogelijke regio naar het doelgegevensarchief of de rekenservice om de prestaties te maximaliseren en tegelijkertijd flexibiliteit te bieden om te voldoen aan beveiligings- en nalevingsvereisten.
Integratieruntimes kunnen rechtstreeks worden gemaakt in de Azure Data Factory en Azure Synapse UI via de beheerhub, en vanuit activiteiten, gegevenssets of gegevensstromen die ernaar verwijzen.
Integration Runtime-typen
Data Factory biedt drie typen Integration Runtime (IR) en u moet het type kiezen dat het beste past bij uw mogelijkheden voor gegevensintegratie en netwerkomgevingsvereisten. De drie typen IR zijn:
- Azure
- Zelfgehost
- Azure-SSIS
Notitie
Synapse pijplijnen ondersteunen momenteel alleen Azure- of zelfgehoste integratie runtimes.
De volgende tabel beschrijft de mogelijkheden en de netwerkondersteuning voor de drie typen Integration Runtime:
| IR-type | Ondersteuning voor openbare netwerken | Ondersteuning voor Private Link |
|---|---|---|
| Azure | Gegevensstroom Gegevensverplaatsing Verzending van de activiteit |
Gegevensstroom Gegevensverplaatsing Verzending van de activiteit |
| Zelfgehost | Gegevensverplaatsing Verzending van de activiteit |
Gegevensverplaatsing Verzending van de activiteit |
| Azure-SSIS | Uitvoering van SSIS-pakket | Uitvoering van SSIS-pakket |
Notitie
Uitgaande regels variëren afhankelijk van de service voor Azure IR. In Synapse hebben werkruimten opties om uitgaand verkeer van het beheerde virtuele netwerk te beperken bij gebruik van Azure IR. In Data Factory worden alle poorten geopend voor uitgaande communicatie bij gebruik van Azure IR. Azure-SSIS IR kan worden geïntegreerd met uw virtuele netwerk om uitgaande communicatiebesturingselementen te bieden.
Azure-integratieruntime
Een Azure Integration Runtime kan het volgende doen:
- Gegevensstromen uitvoeren in Azure
- Kopieeractiviteiten uitvoeren tussen cloudgegevensarchieven
- Verzend de volgende transformatieactiviteiten in een openbaar netwerk:
- .NET aangepaste activiteit
- Azure Function-activiteit
- Databricks Notebook/Jar/Python-activiteit
- Data Lake Analytics U-SQL-activiteit
- Metagegevens ophalen-activiteit
- HDInsight Hive-activiteit
- HDInsight Pig-activiteit
- HDInsight MapReduce-activiteit
- HDInsight Spark-activiteit
- HDInsight Streaming-activiteit
- Opzoekactiviteit
- Machine Learning Studio (klassiek) Batch Execution-activiteit
- Machine Learning Studio (klassiek) Resource-activiteit bijwerken
- Activiteit voor opgeslagen procedures
- Validatieactiviteit
- Webactiviteit
Azure IR-netwerkomgeving
Azure Integration Runtime biedt ondersteuning voor het maken van verbinding met gegevensarchieven en het berekenen van services met openbare toegankelijke eindpunten. Wanneer u Beheerd virtueel netwerk inschakelt, ondersteunt Azure Integration Runtime het maken van verbinding met gegevensarchieven met behulp van de Private Link-service in een privénetwerkomgeving. In Synapse hebben werkruimten opties om uitgaand verkeer van het beheerde virtuele netwerk met IR te beperken. In Data Factory worden alle poorten geopend voor uitgaande communicatie. De Azure-SSIS IR kan worden geïntegreerd met uw virtuele netwerk om uitgaande communicatiebesturingselementen te bieden.
Azure IR-rekenresource en -schalen
Azure Integration Runtime biedt een volledig beheerde, serverloze rekenresource in Azure. U hoeft zich geen zorgen te maken over het inrichten van infrastructuur, software-installatie, patches of het schalen van capaciteit. Daarnaast betaalt u alleen tijdens het werkelijke gebruik.
Azure Integration Runtime biedt de systeemeigen rekenkracht om gegevens te verplaatsen tussen gegevensarchieven in de cloud op een veilige, betrouwbare en krachtige manier. U kunt instellen hoeveel gegevensintegratie-eenheden moeten worden gebruikt voor de kopieeractiviteit en de rekenkracht van de Azure IR wordt elastisch omhoog geschaald zonder dat u expliciet de grootte van de Azure Integration Runtime hoeft aan te passen.
Activiteitsverzending is een lichtgewicht bewerking om de activiteit naar de doel-rekenservice te routeren, dus u hoeft de rekengrootte voor dit scenario niet omhoog te schalen.
Zie Azure Integration Runtime maken en configureren voor meer informatie over het maken en configureren van een Azure IR.
Notitie
Azure Integration Runtime heeft eigenschappen met betrekking tot Gegevensstroom runtime, waarmee de onderliggende rekeninfrastructuur wordt gedefinieerd die wordt gebruikt om de gegevensstromen uit te voeren.
Zelf-gehoste Integration Runtime
Een zelf-gehoste IR is in staat tot:
- Het uitvoeren van kopieeractiviteit tussen een gegevensarchief in de cloud en een gegevensarchief in een privénetwerk.
- Voer de volgende transformatieactiviteiten uit op rekenbronnen in on-premises omgevingen of het Azure Virtual Network.
- Azure Function-activiteit
- Aangepaste activiteit (wordt uitgevoerd op Azure Batch)
- Data Lake Analytics U-SQL-activiteit
- Metagegevens ophalen-activiteit
- HDInsight Hive-activiteit (BYOC - Bring Your Own Cluster)
- HDInsight Pig-activiteit (BYOC)
- HDInsight MapReduce-activiteit (BYOC)
- HDInsight Spark-activiteit (BYOC)
- HDInsight Streaming-activiteit (BYOC)
- Opzoekactiviteit
- Machine Learning Studio (klassiek) Batch Execution-activiteit
- Machine Learning Studio (klassiek) Resource-activiteit bijwerken
- Machine Learning-pijplijnactiviteit uitvoeren
- Activiteit voor opgeslagen procedures
- Validatieactiviteit
- Webactiviteit
Notitie
Gebruik zelf-gehoste Integration Runtime ter ondersteuning van gegevensopslag waarvoor "bring-your-own driver" is vereist, zoals SAP Hana, MySQL, enzovoort. Zie ondersteunde gegevensopslag voor meer informatie.
Notitie
De Java Runtime Environment (JRE) is een vereiste voor de Self Hosted IR. Zorg ervoor dat de JRE op dezelfde host is geïnstalleerd.
Zelf-hostende IR-netwerkomgeving
Als u gegevensintegratie veilig wilt uitvoeren in een privénetwerkomgeving die geen directe line-of-sight heeft van de openbare cloudomgeving, kunt u een zelf-hostende IR installeren in uw on-premises omgeving achter een firewall of in een virtueel particulier netwerk. De zelf-gehoste integratieruntime maakt alleen uitgaande verbindingen op basis van HTTP met internet.
Zelf-gehoste IR-rekenkracht en schaalbaarheid
Installeer een zelf-hostende IR op een on-premises machine of een virtuele machine in een particulier netwerk. Momenteel wordt de zelf-hostende IR alleen ondersteund op een Windows-besturingssysteem. Voor hoge beschikbaarheid en schaalbaarheid kunt u de zelf-hostende IR uitbreiden door het logische exemplaar te koppelen aan meerdere on-premises computers in de modus actief-actief. Zie het artikel over het maken en configureren van een zelf-gehoste IR voor meer informatie.
Azure-SSIS Integration Runtime
Als u de bestaande SSIS-werkbelasting wilt opheffen of verplaatsen, kunt u een Azure-SSIS IR maken voor het uitvoeren van systeemeigen SSIS-pakketten.
Azure-SSIS IR-netwerkomgeving
De Azure-SSIS IR kan worden ingericht in een openbaar netwerk of een particulier netwerk. On-premises gegevenstoegang wordt ondersteund door Azure-SSIS IR te koppelen aan een virtueel netwerk dat is verbonden met uw on-premises netwerk.
Azure-SSIS-IR-rekenfaciliteit en schaalopties
De Azure-SSIS IR is een volledig beheerd cluster van Virtuele Azure-machines die zijn toegewezen om uw SSIS-pakketten uit te voeren. U kunt uw eigen Azure SQL Database of SQL Managed Instance gebruiken voor de catalogus met SSIS-projecten/pakketten (SSISDB). U kunt de rekenkracht vergroten door de grootte van het knooppunt op te geven en uitbreiden door het aantal knooppunten in het cluster aan te geven. U kunt de kosten voor het verrichten van uw Azure-SSIS Integration Runtime beheren door deze te stoppen en te starten zoals uw behoeften vereisen.
Zie De Azure-SSIS IR maken en configureren voor meer informatie. Zodra u deze hebt gemaakt, kunt u uw bestaande SSIS-pakketten implementeren en beheren met weinig tot geen wijzigingen met behulp van vertrouwde hulpprogramma's zoals SQL Server Data Tools (SSDT) en SQL Server Management Studio (SSMS), net zoals bij het gebruik van SSIS on-premises.
Zie de volgende artikelen voor meer informatie over de Azure-SSIS-runtime:
- Zelfstudie: SSIS-pakketten implementeren in Azure. In dit artikel vindt u stapsgewijze instructies voor het maken van een Azure-SSIS IR en het gebruik van een Azure SQL Database voor het hosten van de SSIS-catalogus.
- Procedure: Een Azure SSIS Integration Runtime maken. Dit artikel breidt de zelfstudie uit en bevat instructies voor het gebruik van SQL Managed Instance en het toevoegen van de IR aan een virtueel netwerk.
- Een Azure-SSIS IR monitoren. In dit artikel leest u hoe u informatie over een Azure-SSIS IR ophaalt en beschrijvingen geeft van statussen in de geretourneerde informatie.
- Een Azure-SSIS IR beheren. In dit artikel leest u hoe u een Azure-SSIS IR stopt, start of verwijdert. Er wordt ook uitgelegd hoe u een Azure-SSIS IR kunt uitschalen door meer knooppunten toe te voegen aan de IR.
- Een Azure-SSIS-IR toevoegen aan een virtueel netwerk. Dit artikel bevat algemene informatie over het toevoegen van een Azure-SSIS IR aan een virtueel netwerk van Azure. Het biedt ook stappen voor het gebruik van Azure Portal om een virtueel netwerk te configureren en een Azure-SSIS IR eraan toe te voegen.
Locatie van Integration Runtime
Relatie tussen fabriekslocatie en IR-locatie
Wanneer u een exemplaar van Data Factory of een Synapse-werkruimte maakt, moet u de locatie opgeven. De metagegevens voor het exemplaar worden hier opgeslagen en het activeren van de pijplijn wordt hier gestart. Metagegevens worden alleen opgeslagen in de gekozen regio en worden niet opgeslagen in andere regio's.
Ondertussen heeft een pijplijn toegang tot gegevensarchieven en rekenservices in andere Azure-regio's om gegevens te verplaatsen tussen gegevensarchieven of gegevens te verwerken met behulp van rekenservices. Dit gedrag wordt gerealiseerd via de IR die algemeen beschikbaar is om de gegevensnaleving, efficiëntie en verminderde kosten voor uitgaand netwerkverkeer te realiseren.
De IR-locatie definieert de locatie van de back-end-berekening en waar de gegevensverplaatsing, activiteitsverzending en uitvoering van SSIS-pakketten worden uitgevoerd. De IR-locatie kan afwijken van de locatie van de Data Factory waartoe deze behoort.
Locatie van Azure IR
U kunt de locatieregio van een Azure IR instellen. In dat geval vindt de uitvoering of verzending van de activiteit plaats in de geselecteerde regio.
De standaardinstelling is om de Azure IR in het openbare netwerk automatisch te herstellen. Met deze optie:
Voor de kopieeractiviteit wordt er een maximale inspanning geleverd om automatisch de locatie van uw doeldatastore te detecteren en vervolgens de IR in dezelfde regio te gebruiken, indien beschikbaar, of anders de dichtstbijzijnde in dezelfde geografie; als de regio van het doeldatastore niet kan worden gedetecteerd, wordt de IR in de regio van het exemplaar gebruikt.
Er is bijvoorbeeld een Data Factory- of Synapse-werkruimte gemaakt in VS - oost,
- Wanneer u gegevens kopieert naar een Azure Blob in VS - west, als de blob wordt gedetecteerd in de regio VS - west, wordt de kopieeractiviteit uitgevoerd op de IR in VS - west; als de regiodetectie mislukt, wordt de kopieeractiviteit uitgevoerd op de IR in VS - oost.
- Wanneer u gegevens kopieert naar Salesforce, waarvoor de regio niet kan worden gedetecteerd, wordt de kopieeractiviteit uitgevoerd op de IR in VS - oost.
Tip
Als u strikte vereisten voor gegevensnaleving hebt en ervoor moet zorgen dat gegevens geen bepaalde geografie verlaten, kunt u expliciet een Azure IR maken in een bepaalde regio en de gekoppelde service naar deze IR laten wijzen met behulp van de eigenschap ConnectVia. Als u bijvoorbeeld gegevens wilt kopiëren van een blob in VK - zuid naar een Azure Synapse-werkruimte in VK - zuid en ervoor wilt zorgen dat gegevens het VERENIGD Koninkrijk niet verlaten, maakt u een Azure IR in HET VK - zuid en koppelt u beide gekoppelde services aan deze IR.
Voor de uitvoering van lookup-/GetMetadata/Delete-activiteiten (pijplijnactiviteiten), verzending van transformatieactiviteiten (externe activiteiten) en ontwerpbewerkingen (testverbinding, bladeren in mappenlijst en tabellijst en voorbeeldgegevens), wordt de IR in dezelfde regio gebruikt als de Data Factory of Synapse-werkruimte.
Voor Gegevensstroom wordt de IR in de regio Data Factory of Synapse Workspace gebruikt.
Tip
Een best practice is om ervoor te zorgen dat gegevensstromen worden uitgevoerd in dezelfde regio als uw bijbehorende gegevensarchieven, indien mogelijk. U kunt dit bereiken met automatisch herstellen voor de Azure IR (als de locatie van het gegevensarchief hetzelfde is als de locatie van de Data Factory- of Synapse-werkruimte), of door een nieuw Azure IR-exemplaar te maken in dezelfde regio als uw gegevensarchieven en vervolgens de gegevensstromen erop uit te voeren.
Als u Managed Virtual Network inschakelt met automatisch oplossen voor de Azure IR, wordt de IR in de Data Factory- of Synapse Workspace-regio gebruikt.
U kunt controleren welke IR-locatie wordt gebruikt tijdens de uitvoering van de activiteit in de bewakingsweergave van pijplijnactiviteiten in Data Factory Studio of Synapse Studio, of in de bewakingspayload.
Locatie van zelfgehoste IR
De zelfgehoste IR wordt logisch geregistreerd bij de Data Factory of Synapse-werkruimte en de rekenkracht die wordt gebruikt om de functionaliteit ervan te ondersteunen, wordt door u geleverd. Daarom is er geen expliciete locatie-eigenschap voor zelf-hostende IR.
Wanneer de zelf-gehoste IR wordt gebruikt om gegevensverplaatsing uit te voeren, haalt deze gegevens uit de bron en schrijft deze naar de bestemming.
Locatie Azure-SSIS IR
Notitie
Azure-SSIS Integration Runtimes worden momenteel niet ondersteund in Synapse-pijplijnen.
Het selecteren van de juiste locatie voor uw Azure-SSIS IR is essentieel voor het bereiken van hoge prestaties in uw ETL-werkstromen (extract-transform-load).
- De locatie van uw Azure-SSIS IR hoeft niet hetzelfde te zijn als de locatie van uw Data Factory, maar moet hetzelfde zijn als de locatie van uw eigen Azure SQL Database of SQL Managed Instance waar SSISDB zich bevindt. Op deze manier heeft uw Azure-SSIS Integration Runtime eenvoudig toegang tot de SSISDB zonder overmatig verkeer tussen verschillende locaties.
- Als u geen bestaande SQL Database of SQL Managed Instance hebt, maar on-premises gegevensbronnen/bestemmingen hebt, moet u een nieuwe Azure SQL Database of SQL Managed Instance maken op dezelfde locatie als een virtueel netwerk dat is verbonden met uw on-premises netwerk. Op deze manier kunt u uw Azure-SSIS IR maken met behulp van de nieuwe Azure SQL Database of SQL Managed Instance en dat virtuele netwerk koppelen. Alles bevindt zich op dezelfde locatie, waardoor gegevensverplaatsing en bijbehorende kosten worden geminimaliseerd, terwijl de prestaties worden gemaximaliseerd.
- Als de locatie van uw bestaande Azure SQL Database of SQL Managed Instance niet hetzelfde is als de locatie van een virtueel netwerk dat is verbonden met uw on-premises netwerk, maakt u eerst uw Azure-SSIS IR met behulp van een bestaande Azure SQL Database of SQL Managed Instance en voegt u een ander virtueel netwerk toe op dezelfde locatie. Configureer vervolgens een virtueel netwerk naar een virtuele netwerkverbinding tussen de verschillende locaties.
Het volgende diagram toont de locatie-instellingen voor Data Factory en de integratieruntimes ervan.
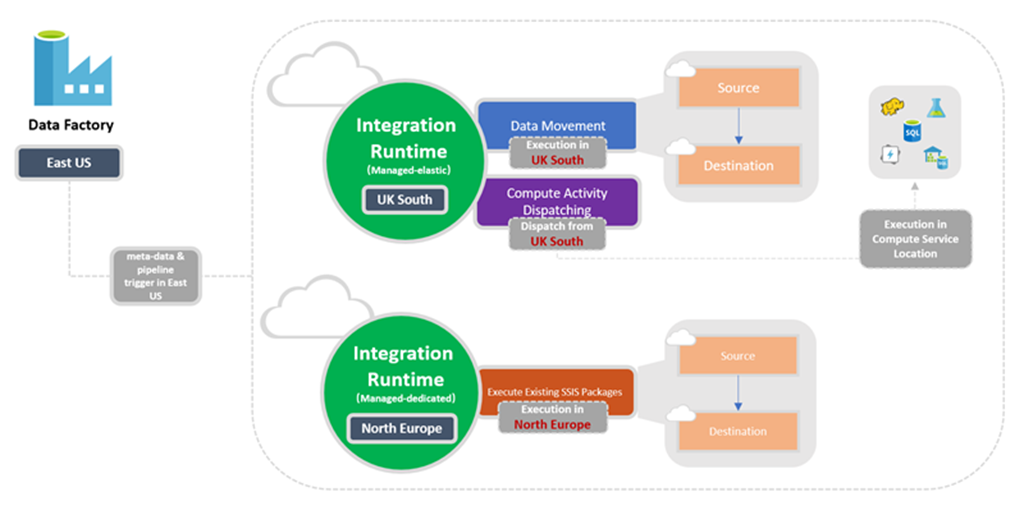
Bepalen welke IR u moet gebruiken
Als een activiteit wordt gekoppeld aan meer dan één type Integration Runtime, wordt deze omgezet in een van deze. De zelfgehoste Integration Runtime heeft voorrang op de Azure Integration Runtime in exemplaren van Azure Data Factory of Synapse Workspace die gebruikmaken van een beheerd virtueel netwerk. En de laatste heeft voorrang op de globale Azure Integration Runtime.
Er wordt bijvoorbeeld één kopieeractiviteit gebruikt om gegevens van de bron naar de sink te kopiëren. De globale Azure Integration Runtime is gekoppeld aan de gekoppelde service voor de bron, en een Azure Integration Runtime in een beheerd virtueel netwerk van Azure Data Factory is gekoppeld aan de gekoppelde service voor de sink. Het resultaat is dat zowel de gekoppelde bron- als de gekoppelde sinkservices de Azure Integration Runtime in het beheerde virtuele netwerk van Azure Data Factory gebruiken. Maar als een zelf-hostende Integration Runtime is gekoppeld aan de gekoppelde service voor de bron, gebruiken zowel de bron- als sink-gekoppelde service de zelf-hostende Integration Runtime.
Kopieeractiviteit
Voor de Copy-activiteit zijn gekoppelde bron- en sinkservices vereist om de richting van de gegevensstroom te definiëren. De volgende logica wordt gebruikt om te bepalen welk exemplaar van Integration Runtime wordt gebruikt voor het uitvoeren van de kopieeractiviteit:
- Kopiëren tussen twee cloudgegevensbronnen: als zowel gekoppelde bron- als sinkservices Gebruikmaken van Azure IR, wordt de regionale Azure IR gebruikt als deze is opgegeven of wordt de locatie van de Azure IR automatisch bepaald als de optie voor automatisch opnieuw verlaten IR (standaard) is gekozen, zoals beschreven in de sectie Integration Runtime-locatie .
- Kopiëren tussen een cloudgegevensbron en een gegevensbron in een privénetwerk: als de gekoppelde bron- of sinkservice verwijst naar een zelf-hostende IR, wordt de kopieeractiviteit uitgevoerd op de zelf-hostende IR.
- Kopiëren tussen twee gegevensbronnen in een particulier netwerk: zowel de gekoppelde bron- als sinkservice moet verwijzen naar hetzelfde exemplaar van de integratieruntime en die IR wordt gebruikt om de kopieeractiviteit uit te voeren.
Lookup- en GetMetadata-activiteit
De activiteiten Lookup en GetMetadata worden uitgevoerd op de integratieruntime die is geassocieerd met de service die aan de gegevensopslag is gekoppeld.
Externe transformatieactiviteit
Elke externe transformatieactiviteit die gebruikmaakt van een externe berekeningsengine heeft een gekoppelde doelservice voor rekenkracht, die verwijst naar een integration runtime. Dit IR-exemplaar bepaalt de locatie vanaf waar die externe met de hand gecodeerde transformatieactiviteit wordt uitgevoerd.
Gegevensstroom activiteit
Gegevensstroom activiteiten worden uitgevoerd op de bijbehorende Azure Integration Runtime. De eigenschappen van de gegevensstroom in uw Azure IR bepalen welke Spark-berekening wordt gebruikt en worden volledig beheerd door de service.
Integratie-omgeving in CI/CD
Integratieruntimes veranderen niet vaak en zijn vergelijkbaar in alle fasen in uw CI/CD. Voor Data Factory moet u dezelfde naam en hetzelfde type integratie-runtime hebben in alle fasen van CI/CD. Als u integratieruntimes in alle fasen wilt delen, kunt u overwegen om een specifieke fabriek te gebruiken met als doel alleen de gedeelde integratieruntimes te bevatten. U kunt vervolgens deze gedeelde voorziening in al uw omgevingen gebruiken als een gekoppelde Integration Runtime.
Gerelateerde inhoud
Zie de volgende artikelen:
- Azure Integration Runtime maken
- Zelf-gehoste integratie-runtime maken
- Een Azure-SSIS Integration Runtime maken. Dit artikel breidt de zelfstudie uit en bevat instructies voor het gebruik van SQL Managed Instance en het toevoegen van de IR aan een virtueel netwerk.