Transformatie bevestigen in toewijzingsgegevensstroom
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Gegevensstromen zijn beschikbaar in Zowel Azure Data Factory als Azure Synapse Pipelines. Dit artikel is van toepassing op toewijzingsgegevensstromen. Als u geen ervaring hebt met transformaties, raadpleegt u het inleidende artikel Gegevens transformeren met behulp van een toewijzingsgegevensstroom.
Met de asserttransformatie kunt u aangepaste regels maken binnen uw toewijzingsgegevensstromen voor gegevenskwaliteit en gegevensvalidatie. U kunt regels bouwen waarmee wordt bepaald of waarden voldoen aan een verwacht waardedomein. Daarnaast kunt u regels bouwen die controleren op uniekheid van rijen. Met de asserttransformatie kunt u bepalen of elke rij in uw gegevens voldoet aan een set criteria. Met de asserttransformatie kunt u ook aangepaste foutberichten instellen wanneer niet aan de regels voor gegevensvalidatie wordt voldaan.
Configuratie
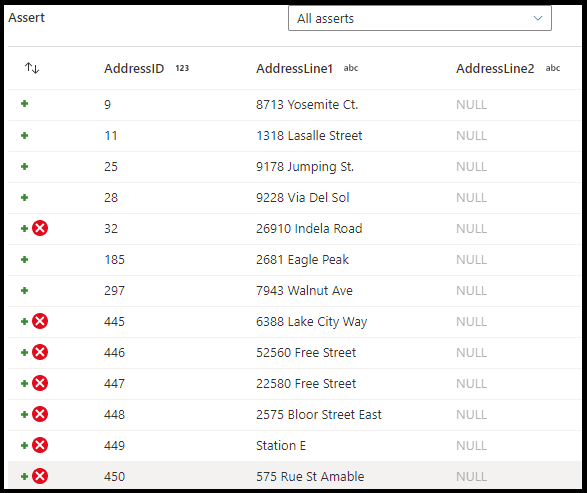
In het configuratievenster voor asserttransformatie kiest u het type assert, geeft u een unieke naam op voor de assertie, optionele beschrijving en definieert u de expressie en het optionele filter. In het deelvenster Gegevensvoorbeeld wordt aangegeven welke rijen uw asserties hebben mislukt. Daarnaast kunt u elke rijtag downstream testen met behulp van isError() en hasError() voor rijen die mislukte asserties hebben.
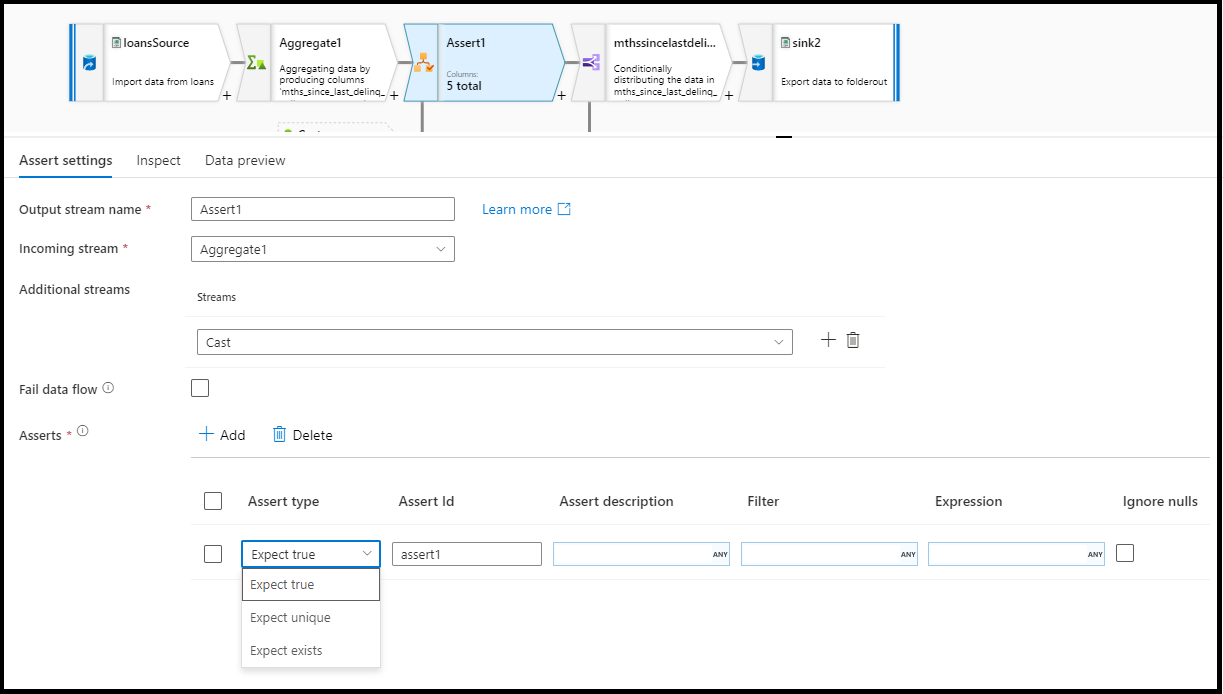
Asserttype
- Waar verwachten: het resultaat van uw expressie moet resulteren in een booleaanse waar resultaat. Gebruik deze optie om waardebereiken voor domeinen in uw gegevens te valideren.
- Verwacht uniek: Stel een kolom of expressie in als een uniekheidsregel in uw gegevens. Gebruik deze optie om dubbele rijen te taggen.
- Verwacht bestaat: deze optie is alleen beschikbaar wanneer u een tweede binnenkomende stream hebt geselecteerd. Er wordt naar beide streams gekeken en wordt bepaald of de rijen in beide streams aanwezig zijn op basis van de kolommen of de expressies die u hebt opgegeven. Als u de tweede stroom wilt toevoegen, selecteert u
Additional streams.
Gegevensstroom mislukt
Selecteer fail data flow deze optie als u uw gegevensstroomactiviteit onmiddellijk wilt laten mislukken zodra de assertieregel mislukt.
Assert-id
Assert-id is een eigenschap waarin u een (tekenreeks)naam voor uw assertie invoert. U kunt de id later downstream in uw gegevensstroom gebruiken met behulp van hasError() of om de foutcode van de assertie uit te voeren. Assert-id's moeten uniek zijn binnen elke gegevensstroom.
Assertbeschrijving
Voer hier een tekenreeksbeschrijving in voor uw assertie. U kunt hier ook expressies en kolomwaarden voor rijcontext gebruiken.
Filter
Filter is een optionele eigenschap waarin u de assertie kunt filteren op slechts een subset van rijen op basis van uw expressiewaarde.
Expression
Voer een expressie in voor evaluatie voor elk van uw asserties. U kunt meerdere asserties hebben voor elke assertietransformatie. Elk type assertie vereist een expressie die ADF moet evalueren om te testen of de assertie is geslaagd.
NULL's negeren
Standaard bevat de assertietransformatie NULL's in de rijverklaringsevaluatie. U kunt ervoor kiezen NULL's met deze eigenschap te negeren.
Fouten in direct assertierij
Wanneer een assertie mislukt, kunt u deze foutrijen desgewenst doorsturen naar een bestand in Azure met behulp van het tabblad Fouten in de sinktransformatie. U hebt ook een optie voor de sinktransformatie om rijen met assertiefouten helemaal niet uit te voeren door foutrijen te negeren.
Voorbeelden
source(output(
AddressID as integer,
AddressLine1 as string,
AddressLine2 as string,
City as string,
StateProvince as string,
CountryRegion as string,
PostalCode as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source(output(
CustomerID as integer,
AddressID as integer,
AddressType as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source2
source1, source2 assert(expectExists(AddressLine1 == AddressLine1, false, 'nonUS', true(), 'only valid for U.S. addresses')) ~> Assert1
Script voor gegevensstroom
Voorbeelden
source1, source2 assert(expectTrue(CountryRegion == 'United States', false, 'nonUS', null, 'only valid for U.S. addresses'),
expectExists(source1@AddressID == source2@AddressID, false, 'assertExist', StateProvince == 'Washington', toString(source1@AddressID) + ' already exists in Washington'),
expectUnique(source1@AddressID, false, 'uniqueness', null, toString(source1@AddressID) + ' is not unqiue')) ~> Assert1
Gerelateerde inhoud
- Gebruik de transformatie Selecteren om kolommen te selecteren en te valideren.
- Gebruik de transformatie van afgeleide kolommen om kolomwaarden te transformeren.