Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Aanbeveling
Data Factory in Microsoft Fabric is de volgende generatie van Azure Data Factory, met een eenvoudigere architectuur, ingebouwde AI en nieuwe functies. Als u nieuw bent in gegevensintegratie, begint u met Fabric Data Factory. Bestaande ADF-workloads kunnen upgraden naar Fabric om toegang te krijgen tot nieuwe mogelijkheden voor gegevenswetenschap, realtime analyses en rapportage.
In deze zelfstudie gebruikt u de gebruikersinterface (UX) van Azure Data Factory om een pijplijn te maken die gegevens van een Azure Data Lake Storage (ADLS) Gen2-bron kopieert en transformeert naar een ADLS Gen2-opslagplaats met behulp van een toewijzingsgegevensstroom. Het configuratiepatroon in deze handleiding kan worden uitgebreid wanneer gegevens worden getransformeerd met behulp van de gegevensverwerkingsstroom.
Deze zelfstudie is bedoeld voor het in kaart brengen van gegevensstromen algemeen. Gegevensstromen zijn beschikbaar in Azure Data Factory en Synapse Pipelines. Als u nieuw bent met gegevensstromen in Azure Synapse Pipelines, volgt u Gegevensstroom met behulp van Azure Synapse Pipelines.
In deze zelfstudie voert u de volgende stappen uit:
- Een data factory maken.
- Maak een pijplijn met een Gegevensstroom-activiteit.
- Bouw een gegevensstroom voor mapping met vier transformaties.
- Voer een test van de pijplijn uit.
- Een Gegevensstroom activiteit bewaken
Vereisten
- Azure-abonnement. Als u geen Azure abonnement hebt, maakt u een vrij Azure account voordat u begint.
- Azure Data Lake Storage Gen2 account. U gebruikt ADLS-opslag als bron- en sinkgegevensopslag. Als u geen opslagaccount hebt, raadpleegt u Maak een Azure-opslagaccount voor stappen om er een te maken.
- Download MoviesDB.csv hier. Als u het bestand wilt ophalen uit GitHub, kopieert u de inhoud naar een teksteditor van uw keuze om lokaal op te slaan als een .csv bestand. Upload het bestand naar uw opslagaccount in een container met de naam sample-data.
Een data factory maken
In deze stap maakt u een data factory en opent u de Data Factory UX om een pijplijn in de data factory te maken.
Open Microsoft Edge of Google Chrome. Momenteel wordt de Data Factory-gebruikersinterface alleen ondersteund in de webbrowsers Microsoft Edge en Google Chrome.
Selecteer in het bovenste menu Create a resource>Analytics>Data Factory:
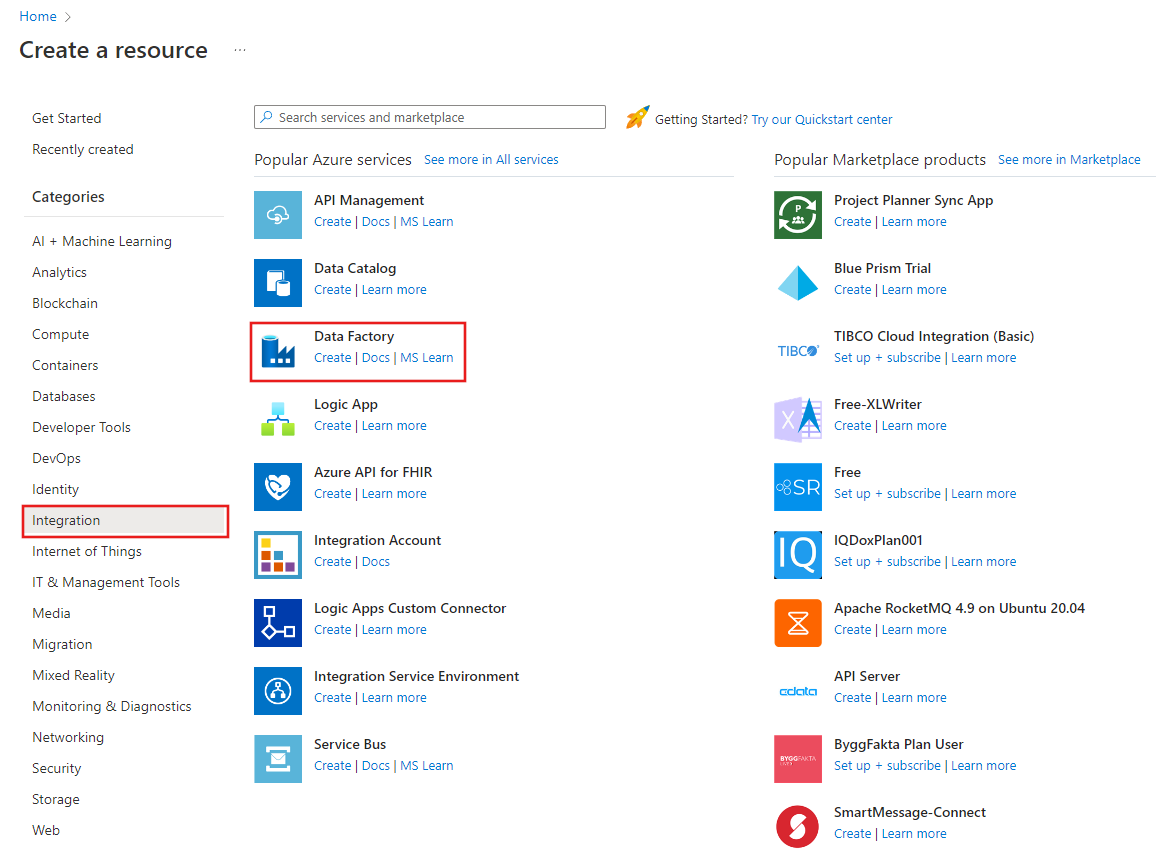
Voer op de pagina Nieuwe data factory onder NaamADFTutorialDataFactory in.
De naam van de Azure data factory moet globally uniek zijn. Als u een foutbericht ontvangt dat betrekking heeft op de waarde die bij de naam is ingevuld, voert u een andere naam in voor de data factory. (bijvoorbeeld uwnaamADFTutorialDataFactory). Zie Data Factory naming rules (Naamgevingsregels Data Factory) voor meer informatie over naamgevingsregels voor Data Factory-artefacten.
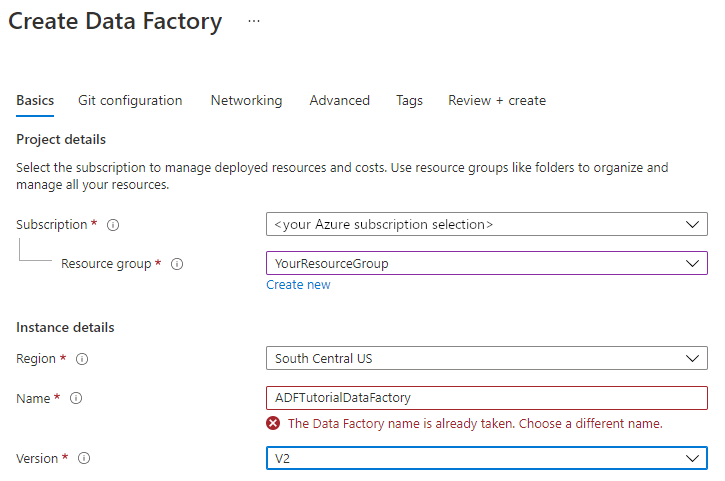
Selecteer de Azure subscription waarin u de data factory wilt maken.
Voer een van de volgende stappen uit voor Resourcegroep:
Selecteer Bestaande gebruiken en selecteer een bestaande resourcegroep in de vervolgkeuzelijst.
Selecteer Nieuwe maken en voer de naam van een resourcegroep in.
Zie Resourcegroepen gebruiken om uw Azure resources te beheren voor meer informatie over resourcegroepen.
Selecteer V2 onder Versie.
Selecteer onder Regio een locatie voor de data factory. In de vervolgkeuzelijst worden alleen ondersteunde locaties weergegeven. Gegevensarchieven (bijvoorbeeld Azure Storage en SQL Database) en berekeningen (bijvoorbeeld Azure HDInsight) die door de data factory worden gebruikt, kunnen zich in andere regio's bevinden.
Selecteer Beoordelen en maken en selecteer vervolgens Maken.
Als het maken is voltooid, ziet u de melding in het meldingencentrum. Selecteer Naar resource gaan om naar de pagina Data factory te gaan.
Selecteer Start studio om de Data Factory-studio op een afzonderlijk tabblad te starten.
Een pijplijn maken met een Gegevensstroom-activiteit
In deze stap maakt u een pijplijn die een Gegevensstroom-activiteit bevat.
Selecteer op de startpagina van Azure Data Factory Orchestrate.
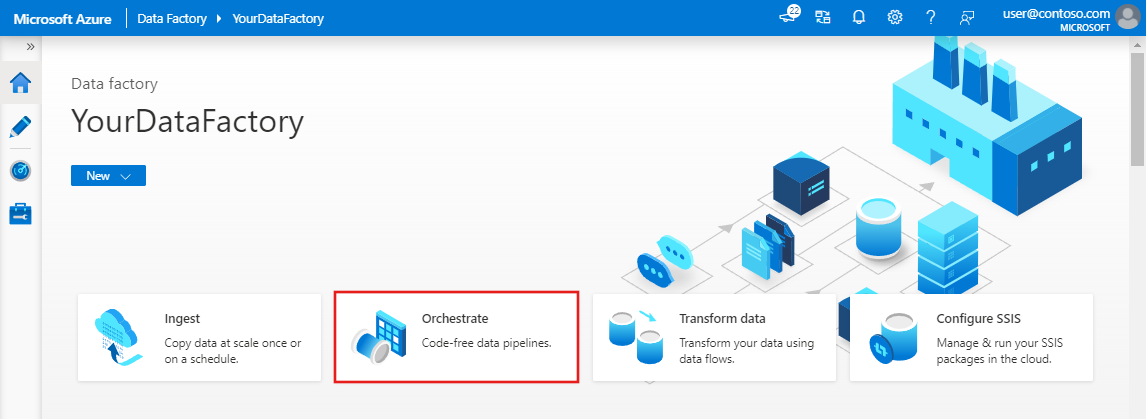
Er is nu een venster geopend voor een nieuwe pijplijn. Voer op het tabblad Algemeen voor de pijplijneigenschappen TransformMovies in als naam van de pijplijn.
Vouw in het deelvenster Activiteiten de accordeon Verplaatsen en Transformeren uit. Sleep de activiteit Gegevensstroom van het deelvenster naar het pijplijncanvas.

Geef uw gegevensstroomactiviteit de naam Gegevensstroom1.
Zet in de bovenbalk van het pijplijncanvas de schuifregelaar Gegevensstroom foutopsporing aan. Met de foutopsporingsmodus kunt u interactieve transformatielogica testen op een live Spark-cluster. Gegevensstroom-clusters nemen 5-7 minuten in beslag om op te starten en gebruikers wordt aangeraden eerst debug in te schakelen als ze van plan zijn om Gegevensstroom-ontwikkeling uit te voeren. Zie De foutopsporingsmodus voor meer informatie.

Transformatielogica bouwen in het gegevensstroomcanvas
In deze stap bouwt u een gegevensstroom die de moviesDB.csv in ADLS-opslag gebruikt en de gemiddelde classificatie van komedies van 1910 tot 2000 samenvoegt. Vervolgens schrijft u dit bestand terug naar de ADLS-opslag.
Ga in het deelvenster onder het canvas naar de instellingen van uw gegevensstroomactiviteit en selecteer Nieuw, naast het gegevensstroomveld. Hiermee opent u het gegevensstroomcanvas.
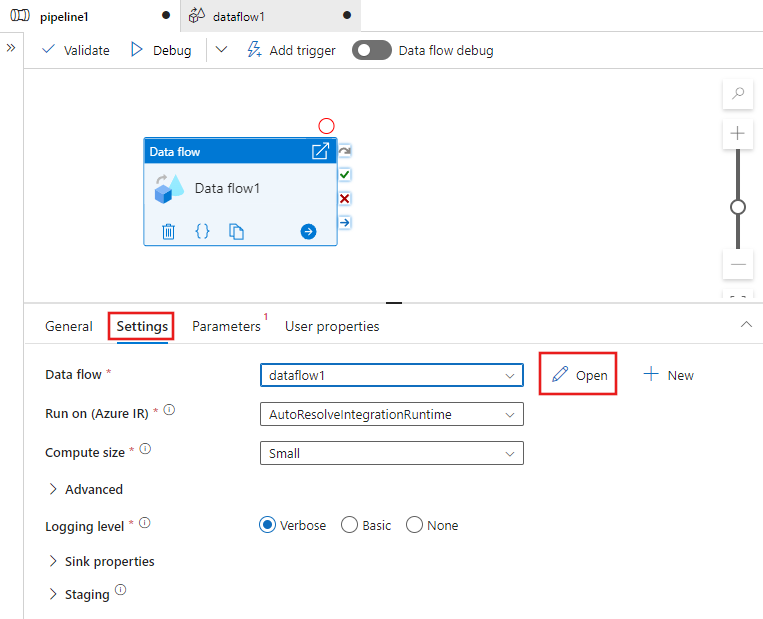
Geef in het deelvenster Eigenschappen onder Algemeen de naam van uw gegevensstroom: TransformMovies.
Voeg in het gegevensstroomcanvas een bron toe door het vak Bron toevoegen te selecteren.

Noem uw bron MoviesDB. Selecteer Nieuw om een nieuwe brongegevensset te maken.

Kies Azure Data Lake Storage Gen2. Selecteer Doorgaan.

Kies DelimitedText. Selecteer Doorgaan.

Noem uw gegevensset MoviesDB. Kies Nieuw in de vervolgkeuzelijst voor gekoppelde services.

Geef in het scherm voor het maken van de gekoppelde service uw ADLS Gen2-gekoppelde service de naam ADLSGen2 en geef uw verificatiemethode op. Voer vervolgens uw verbindingsreferenties in. In deze tutorial gebruiken we een accountsleutel om verbinding te maken met ons opslagaccount. U kunt testverbinding selecteren om te controleren of uw referenties correct zijn ingevoerd. Selecteer Maken wanneer u klaar bent.

Wanneer u terug bent op het scherm voor het maken van de gegevensset, voert u in waar het bestand zich bevindt onder het veld Bestandspad . In deze handleiding bevindt het bestand moviesDB.csv zich in de container sample-data. Als het bestand kopteksten bevat, controleert u de eerste rij als koptekst. Selecteer Uit verbinding/archief om het headerschema rechtstreeks vanuit het bestand in de opslag te importeren. Selecteer OK wanneer u klaar bent.

Als uw foutopsporingscluster is gestart, gaat u naar het tabblad Gegevensvoorbeeld van de brontransformatie en selecteert u Vernieuwen om een momentopname van de gegevens op te halen. U kunt de voorbeeldweergave van gegevens gebruiken om te controleren of uw transformatie juist is geconfigureerd.

Selecteer naast het bronknooppunt op het canvas van de gegevensstroom het pluspictogram om een nieuwe transformatie toe te voegen. De eerste transformatie die u toevoegt, is een filter.

Geef de filtertransformatie de naam FilterYears. Selecteer het expressievak naast Filteren op en open de opbouwfunctie voor expressies. Hier geeft u uw filtervoorwaarde op.

Met de opbouwfunctie voor expressies voor gegevensstromen kunt u interactief expressies bouwen die u in verschillende transformaties kunt gebruiken. Expressies kunnen ingebouwde functies, kolommen uit het invoerschema en door de gebruiker gedefinieerde parameters bevatten. Zie Gegevensstroom opbouwfunctie voor expressies voor meer informatie over het bouwen van expressies.
In deze zelfstudie wilt u films filteren van genrekomedie die tussen de jaren 1910 en 2000 uitkwam. Naarmate het jaar momenteel een tekenreeks is, moet u deze converteren naar een geheel getal met behulp van de
toInteger()functie. Gebruik de operatoren groter dan of gelijk aan (>=) en kleiner dan of gelijk aan (<=) om te vergelijken met letterlijke jaarwaarden 1910 en 2000. Deze expressies samenvoegen met de operator (&&). De uitdrukking komt neer op:toInteger(year) >= 1910 && toInteger(year) <= 2000Als u wilt zoeken welke films komedies zijn, kunt u de
rlike()functie gebruiken om patroon 'Komedie' te vinden in de kolomgenres.rlikeDe expressie samenvoegen met de jaarvergelijking om het volgende te verkrijgen:toInteger(year) >= 1910 && toInteger(year) <= 2000 && rlike(genres, 'Comedy')Als u een foutopsporingscluster actief hebt, kunt u uw logica controleren door Vernieuwen te selecteren om expressie-uitvoer te zien in vergelijking met de gebruikte invoer. Er is meer dan één juist antwoord op hoe u deze logica kunt uitvoeren met behulp van de expressietaal voor gegevensstromen.

Selecteer Opslaan en Voltooien zodra u klaar bent met uw expressie.
Haal een voorbeeld van gegevens op om te controleren of het filter correct werkt.

De volgende transformatie die u toevoegt, is een statistische transformatie onder Schema-modifier.

Geef uw statistische transformatie de naam AggregateComedyRatings. Op het tabblad Groeperen, selecteer jaar in de vervolgkeuzelijst om de aggregaties te groeperen op het jaar dat de film uitkwam.

Ga naar het tabblad Aggregaties . Geef in het linkertekstvak de statistische kolom AverageComedyRating een naam. Selecteer het juiste expressievak om de statistische expressie in te voeren via de opbouwfunctie voor expressies.

Om het gemiddelde van kolom Rating op te halen, gebruik de
avg(). Omdat Waardering een tekenreeks is enavg()een numerieke invoer inneemt, moeten we de waarde via detoInteger()functie converteren naar een getal. Dit is een expressie die er als volgt uitziet:avg(toInteger(Rating))Selecteer Opslaan en Voltooien wanneer u klaar bent.

Ga naar het tabblad Gegevensvoorbeeld om de transformatie-uitvoer weer te geven. U ziet dat er slechts twee kolommen zijn, jaar en AverageComedyRating.

Vervolgens wilt u een Sink-transformatie toevoegen onder Bestemming.

Geef uw spoelbak spoelbak een naam. Selecteer Nieuw om uw sinkgegevensset te maken.

Kies Azure Data Lake Storage Gen2. Selecteer Doorgaan.
Kies DelimitedText. Selecteer Doorgaan.
Geef de naam aan uw sink-dataset MoviesSink. Kies voor gekoppelde service de gekoppelde ADLS Gen2-service die u in stap 6 hebt gemaakt. Voer een uitvoermap in waarnaar u uw gegevens wilt schrijven. In deze zelfstudie schrijven we naar de map 'output' in container 'sample-data'. De map hoeft niet van tevoren te bestaan en kan dynamisch worden gemaakt. Stel eerste rij in als kop en als waar en selecteer Geen voor Importschema. Klik op Voltooien.

Nu u klaar bent met het opzetten van uw gegevensstroom. U bent klaar om deze uit te voeren in uw pijplijn.
De Gegevensstroom uitvoeren en bewaken
U kunt fouten in een pijplijn opsporen voordat u deze publiceert. In deze stap gaat u een foutopsporingsuitvoering van de gegevensstroompijplijn activeren. Hoewel gegevensvoorbeeld geen gegevens schrijft, schrijft een foutopsporingsuitvoering gegevens naar uw sinkbestemming.
Ga naar het pijplijncanvas. Selecteer Foutopsporing om een foutopsporingsuitvoering te activeren.

Pijplijnopsporing van Gegevensstroom-activiteiten maakt gebruik van het actieve foutopsporingscluster, maar duurt nog steeds ten minste een minuut om te initialiseren. U kunt de voortgang bijhouden via het tabblad Uitvoer . Zodra de uitvoering is voltooid, beweegt u de muisaanwijzer over de run en selecteert u het brilpictogram om het bewakingsvenster te openen.

Selecteer in het bewakingsvenster de knop Fasen om het aantal rijen en tijd te zien dat in elke transformatiestap is besteed.


Selecteer een transformatie om gedetailleerde informatie over de kolommen en partitionering van de gegevens op te halen.

Als u deze zelfstudie correct hebt gevolgd, moet u 83 rijen en 2 kolommen in uw sinkmap hebben geschreven. U kunt controleren of de gegevens juist zijn door uw blobopslag te controleren.
Gerelateerde inhoud
De pijplijn in deze zelfstudie voert een gegevensstroom uit waarmee de gemiddelde classificatie van komedies tussen 1910 en 2000 wordt samengevoegd en de gegevens naar ADLS worden geschreven. U hebt geleerd hoe u:
- Een data factory maken.
- Maak een pijplijn met een Gegevensstroom-activiteit.
- Bouw een gegevensstroom voor mapping met vier transformaties.
- Voer een test van de pijplijn uit.
- Een Gegevensstroom activiteit bewaken
Meer informatie over de expressietaal voor gegevensstromen.