Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is de volgende generatie van Azure Data Factory, met een eenvoudigere architectuur, ingebouwde AI en nieuwe functies. Als u nieuw bent in gegevensintegratie, begint u met Fabric Data Factory. Bestaande ADF-workloads kunnen upgraden naar Fabric om toegang te krijgen tot nieuwe mogelijkheden voor gegevenswetenschap, realtime analyses en rapportage.
Gegevensstromen zijn beschikbaar in zowel Azure Data Factory pijplijnen als Azure Synapse Analytics pijplijnen. Dit artikel is van toepassing op gegevensstromen. Als u nieuw bent met transformaties, raadpleegt u het inleidende artikel Gegevens transformeren met behulp van mapping-dataflows.
Gebruik de transformatie Parseren om tekstkolommen in uw gegevens te parseren die tekenreeksen in documentvorm zijn. De huidige ondersteunde typen ingesloten documenten die kunnen worden geparseerd, zijn JSON, XML en tekst met scheidingstekens.
Configuratie
In het configuratiepaneel voor parseringstransformatie kiest u eerst het type gegevens in de kolommen die u inline wilt parseren. De parseringstransformatie bevat ook de volgende configuratie-instellingen.

Kolom
Net als bij afgeleide kolommen en aggregaties kunt u met de eigenschap Kolom een bestaande kolom wijzigen door deze te selecteren in de vervolgkeuzelijst. U kunt ook hier de naam van een nieuwe kolom typen. In ADF worden de geparseerde brongegevens in deze kolom opgeslagen. In de meeste gevallen wilt u een nieuwe kolom definiëren waarmee het inkomende ingesloten documenttekenreeksveld wordt geparseerd.
Expressie
Gebruik de opbouwfunctie voor expressies om de bron in te stellen voor het parseren. Het instellen van de bron kan net zo eenvoudig zijn als het selecteren van de bronkolom met de zelf-ingesloten gegevens die u wilt parseren, of u kunt complexe expressies maken om te parseren.
Voorbeelden van expressies
Brontekenreeksgegevens:
chrome|steel|plastic- Uitdrukking:
(desc1 as string, desc2 as string, desc3 as string)
- Uitdrukking:
JSON-brongegevens:
{"ts":1409318650332,"userId":"309","sessionId":1879,"page":"NextSong","auth":"Logged In","method":"PUT","status":200,"level":"free","itemInSession":2,"registration":1384448}- Uitdrukking:
(level as string, registration as long)
- Uitdrukking:
Geneste JSON-brongegevens:
{"car" : {"model" : "camaro", "year" : 1989}, "color" : "white", "transmission" : "v8"}- Uitdrukking:
(car as (model as string, year as integer), color as string, transmission as string)
- Uitdrukking:
XML-brongegevens:
<Customers><Customer>122</Customer><CompanyName>Great Lakes Food Market</CompanyName></Customers>- Uitdrukking:
(Customers as (Customer as integer, CompanyName as string))
- Uitdrukking:
Bron-XML met kenmerkgegevens:
<cars><car model="camaro"><year>1989</year></car></cars>- Uitdrukking:
(cars as (car as ({@model} as string, year as integer)))
- Uitdrukking:
Expressies met gereserveerde tekens:
{ "best-score": { "section 1": 1234 } }- De bovenstaande expressie werkt niet omdat het teken '-'
best-scorewordt geïnterpreteerd als een aftrekkingsbewerking. Gebruik in deze gevallen een variabele met haakjes-notatie om de JSON-engine de tekst letterlijk te interpreteren:var bestScore = data["best-score"]; { bestScore : { "section 1": 1234 } }
- De bovenstaande expressie werkt niet omdat het teken '-'
Opmerking: als er fouten optreden bij het extraheren van kenmerken (met name @model) van een complex type, is een tijdelijke oplossing om het complexe type te converteren naar een tekenreeks, verwijdert u het @-symbool (met name replace(toString(your_xml_string_parsed_column_name.cars.car),'@',') en gebruikt u vervolgens de activiteit JSON-transformatie parseren.
Type uitvoerkolom
Hier configureert u het doeluitvoerschema van de parsering die in één kolom is geschreven. De eenvoudigste manier om een schema in te stellen voor uw uitvoer van parseren is door de knop 'Type detecteren' in de rechterbovenhoek van de expressiebouwer te selecteren. ADF probeert het schema automatisch te detecteren vanuit het tekenreeksveld, dat u parseert en voor u instelt in de uitvoerexpressie.
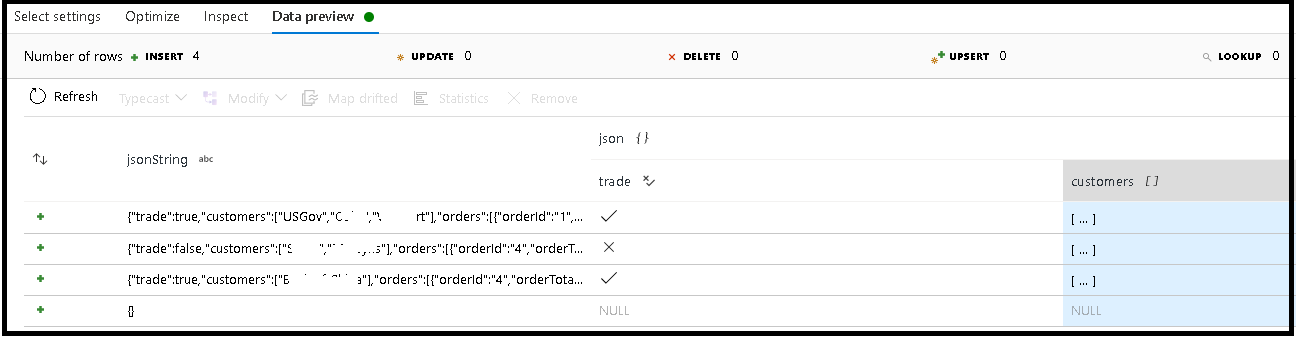
In dit voorbeeld hebben we het parseren van het inkomende veld 'jsonString' gedefinieerd. Dit is tekst zonder opmaak, maar opgemaakt als een JSON-structuur. We gaan de geparseerde resultaten opslaan als JSON in een nieuwe kolom met de naam json met dit schema:
(trade as boolean, customers as string[])
Raadpleeg het tabblad Inspecteren en het voorbeeld van gegevens om te controleren of uw uitvoer correct is toegewezen.
Gebruik de activiteit Afgeleide kolom om hiërarchische gegevens te extraheren (dat wil gezegd your_complex_column_name.car.model in het expressieveld)
Voorbeelden
source(output(
name as string,
location as string,
satellites as string[],
goods as (trade as boolean, customers as string[], orders as (orderId as string, orderTotal as double, shipped as (orderItems as (itemName as string, itemQty as string)[]))[])
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
documentForm: 'documentPerLine') ~> JsonSource
source(output(
movieId as string,
title as string,
genres as string
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false) ~> CsvSource
JsonSource derive(jsonString = toString(goods)) ~> StringifyJson
StringifyJson parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json',
documentForm: 'arrayOfDocuments') ~> ParseJson
CsvSource derive(csvString = 'Id|name|year\n\'1\'|\'test1\'|\'1999\'') ~> CsvString
CsvString parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
ParseJson select(mapColumn(
jsonString,
json
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedJson
ParseCsv select(mapColumn(
csvString,
csv
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedCsv
Script voor gegevensstroom
Syntaxis
Voorbeelden
parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json|XML|delimited',
documentForm: 'singleDocument') ~> ParseJson
parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
Gerelateerde inhoud
- Gebruik de Flatten-transformatie om rijen naar kolommen te transformeren.
- Gebruik de transformatie van afgeleide kolommen om rijen te transformeren.