Rijen ontdubbelen en null-waarden zoeken met behulp van gegevensstroomfragmenten
VAN TOEPASSING OP: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Met behulp van codefragmenten in toewijzingsgegevensstromen kunt u eenvoudig algemene taken uitvoeren, zoals gegevensontdubbeling en null-filtering. In dit artikel wordt uitgelegd hoe u deze functies eenvoudig kunt toevoegen aan uw pijplijnen met behulp van scriptfragmenten voor gegevensstromen.
Een pipeline maken
Selecteer Nieuwe pijplijn.
Voeg een gegevensstroomactiviteit toe.
Selecteer het tabblad Broninstellingen , voeg een brontransformatie toe en verbind deze vervolgens met een van uw gegevenssets.
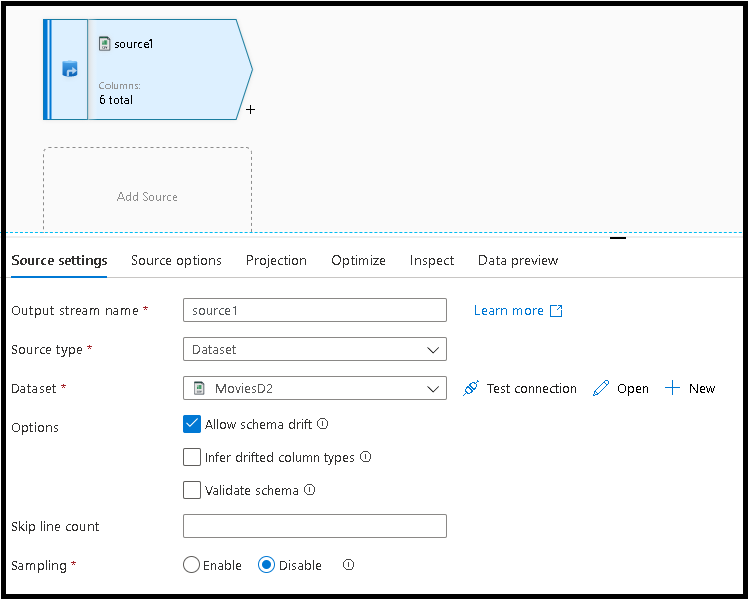
De ontdubbelings- en null-controlefragmenten maken gebruik van algemene patronen die profiteren van schemadrift van gegevensstromen. De fragmenten werken met een schema uit uw gegevensset of met gegevenssets die geen vooraf gedefinieerd schema hebben.
Kopieer in de sectie Distinct row using all columns (Distinct row using all columns) van het Gegevensstroomscript (DFS) het codefragment voor DistinctRows.
-
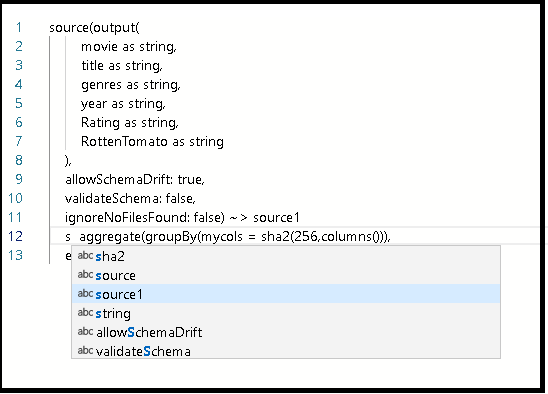
Druk in het script na de definitie op
source1Enter en plak het codefragment.Voer een van de volgende bewerkingen uit:
Verbinding maken dit geplakte codefragment naar de brontransformatie die u eerder in de grafiek hebt gemaakt door bron1 vóór de geplakte code te typen.
U kunt ook de nieuwe transformatie in de ontwerpfunctie verbinden door de binnenkomende stroom te selecteren vanuit het nieuwe transformatieknooppunt in de grafiek.
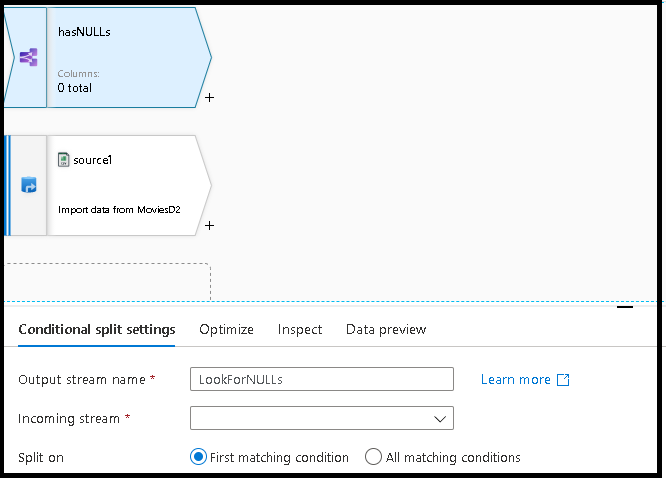
Nu verwijdert uw gegevensstroom dubbele rijen uit uw bron met behulp van de statistische transformatie, die door alle rijen wordt gegroepeerd met behulp van een algemene hash voor alle kolomwaarden.
Voeg een codefragment toe voor het splitsen van uw gegevens in één stroom die rijen bevat met nulls en een andere stream zonder nulls. Hiervoor doet u het volgende:
Ga terug naar de bibliotheek fragmenten en kopieer deze keer de code voor de NULL-controles.
b. Selecteer nogmaals Script in de ontwerpfunctie voor gegevensstromen en plak deze nieuwe transformatiecode onderaan. Met deze actie wordt het script verbonden met uw vorige transformatie door de naam van die transformatie vóór het geplakte fragment te plaatsen.
Uw gegevensstroomgrafiek moet er nu ongeveer als volgt uitzien:
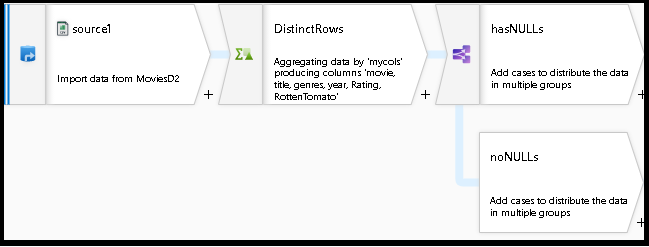
U hebt nu een werkende gegevensstroom gemaakt met algemene ontdubbelings- en null-controles door bestaande codefragmenten uit de Gegevensstroom Script-bibliotheek te nemen en toe te voegen aan uw bestaande ontwerp.
Gerelateerde inhoud
- Bouw de rest van uw gegevensstroomlogica met behulp van transformaties van toewijzingsgegevensstromen.