Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is de volgende generatie van Azure Data Factory, met een eenvoudigere architectuur, ingebouwde AI en nieuwe functies. Als u nieuw bent in gegevensintegratie, begint u met Fabric Data Factory. Bestaande ADF-workloads kunnen upgraden naar Fabric om toegang te krijgen tot nieuwe mogelijkheden voor gegevenswetenschap, realtime analyses en rapportage.
De Azure Databricks Jar-activiteit in een pipeline voert een Spark Jar uit in uw Azure Databricks-cluster. Dit artikel is gebaseerd op het artikel over activiteiten voor gegevenstransformatie , waarin een algemeen overzicht wordt weergegeven van de gegevenstransformatie en de ondersteunde transformatieactiviteiten. Azure Databricks is een beheerd platform voor het uitvoeren van Apache Spark.
Bekijk de volgende video voor een inleiding en demonstratie van deze functie van 11 minuten:
Een Jar-activiteit voor Azure Databricks toevoegen aan een pijplijn met UI
Voer de volgende stappen uit om een Jar-activiteit te gebruiken voor Azure Databricks in een pijplijn:
Zoek naar Jar in het deelvenster Activiteiten van de pijplijn en sleep een Jar-activiteit naar het pijplijncanvas.
Selecteer de nieuwe Jar-activiteit op het canvas als deze nog niet is geselecteerd.
Selecteer het tabblad Azure Databricks om een nieuwe Azure Databricks gekoppelde service te selecteren of te maken waarmee de Jar-activiteit wordt uitgevoerd.
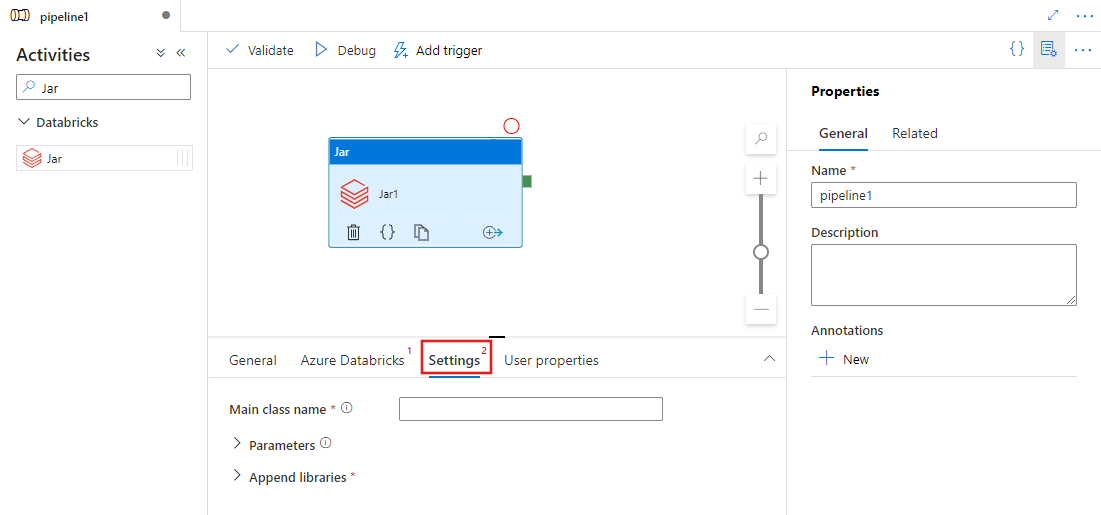
Selecteer het tabblad Settings en geef een klassenaam op die moet worden uitgevoerd op Azure Databricks, optionele parameters die moeten worden doorgegeven aan het Jar-bestand en bibliotheken die op het cluster moeten worden geïnstalleerd om de taak uit te voeren.
Databricks Jar-activiteitsdefinitie
Hier volgt de JSON-voorbeelddefinitie van een Databricks Jar-activiteit:
{
"name": "SparkJarActivity",
"type": "DatabricksSparkJar",
"linkedServiceName": {
"referenceName": "AzureDatabricks",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mainClassName": "org.apache.spark.examples.SparkPi",
"parameters": [ "10" ],
"libraries": [
{
"jar": "dbfs:/docs/sparkpi.jar"
}
]
}
}
Activiteitseigenschappen van Databricks Jar
In de volgende tabel worden de JSON-eigenschappen beschreven die worden gebruikt in de JSON-definitie:
| Eigenschap | Beschrijving | Vereist |
|---|---|---|
| naam | Naam van de activiteit in de pijplijn. | Ja |
| beschrijving | Tekst die beschrijft wat de activiteit doet. | Nee |
| type | Voor Databricks Jar-activiteit is het activiteitstype DatabricksSparkJar. | Ja |
| naam van de gekoppelde service | Naam van de gekoppelde Databricks-service waarop de Jar-activiteit wordt uitgevoerd. Zie het artikel Compute als Gekoppelde Services voor meer informatie over deze gekoppelde service. | Ja |
| mainClassName | De volledige naam van de klasse die de hoofdmethode bevat die moet worden uitgevoerd. Deze klasse moet opgenomen worden in een JAR die als bibliotheek geleverd wordt. Een JAR-bestand kan meerdere klassen bevatten. Elk van de klassen kan een hoofdmethode bevatten. | Ja |
| parameters | Parameters die worden doorgegeven aan de hoofdmethode. Deze eigenschap is een matrix met tekenreeksen. | Nee |
| bibliotheken | Een lijst met bibliotheken die moeten worden geïnstalleerd op het cluster waarmee de taak wordt uitgevoerd. Het kan een matrix van <tekenreeks, object zijn> | Ja (ten minste één met de mainClassName-methode) |
Notitie
Bekend probleem : wanneer u hetzelfde interactieve cluster gebruikt voor het uitvoeren van gelijktijdige Databricks Jar-activiteiten (zonder opnieuw opstarten van het cluster), is er een bekend probleem in Databricks waarbij in parameters van de 1e activiteit ook door de volgende activiteiten worden gebruikt. Hierdoor worden onjuiste parameters doorgegeven aan de volgende taken. Als u dit wilt beperken, gebruikt u in plaats daarvan een taakcluster .
Ondersteunde bibliotheken voor Databricks-activiteiten
In de vorige Databricks-activiteitsdefinitie hebt u deze bibliotheektypen opgegeven: jar, egg, maven, pypi, . cran
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Zie de Databricks-documentatie voor bibliotheektypen voor meer informatie.
Een bibliotheek uploaden in Databricks
U kunt de gebruikersinterface van de werkruimte gebruiken:
De gebruikersinterface van de Databricks-werkruimte gebruiken
Als u het dbfs-pad van de bibliotheek wilt ophalen die is toegevoegd met behulp van de gebruikersinterface, kunt u Databricks CLI gebruiken.
Normaal gesproken worden de Jar-bibliotheken opgeslagen onder dbfs:/FileStore/jars tijdens het gebruik van de gebruikersinterface. U kunt alles weergeven via de CLI: databricks fs ls dbfs:/FileStore/job-jars
U kunt ook de Databricks CLI gebruiken:
De bibliotheek kopiëren volgen met behulp van Databricks CLI
Databricks CLI gebruiken (installatiestappen)
Als u bijvoorbeeld een JAR naar dbfs wilt kopiëren:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar
Gerelateerde inhoud
Bekijk de video voor een inleiding en demonstratie van deze functie van elf minuten.