Toegang tot Azure Data Lake Storage met Microsoft Enterprise ID (voorheen bekend als Azure Active Directory of AAD) referentie-passthrough (verouderd).
Belangrijk
Deze documentatie is buiten gebruik gesteld en wordt mogelijk niet bijgewerkt.
Referentie-passthrough is een verouderd gegevensbeheermodel. Databricks raadt u aan om een upgrade uit te voeren naar Unity Catalog. Unity Catalog vereenvoudigt de beveiliging en governance van uw gegevens door een centrale plaats te bieden voor het beheren en controleren van toegang tot gegevens in meerdere werkruimten in uw account. Bekijk Wat is Unity Catalog?
Neem voor een verhoogde beveiligings- en governancepostuur contact op met uw Azure Databricks-accountteam om referentiepassthrough uit te schakelen in uw Azure Databricks-account.
Notitie
Dit artikel bevat verwijzingen naar de lijst met toegestane termen, een term die azure Databricks niet gebruikt. Zodra de term uit de software wordt verwijderd, verwijderen we deze uit dit artikel.
U kunt automatisch verifiëren voor toegang tot Azure Data Lake Storage Gen1 vanuit Azure Databricks (ADLS Gen1) en ADLS Gen2 vanuit Azure Databricks-clusters met behulp van dezelfde Microsoft Entra-id (voorheen Azure Active Directory) identiteit die u gebruikt om u aan te melden bij Azure Databricks. Wanneer u Azure Data Lake Storage-referentiepassthrough inschakelt voor uw cluster, kunnen opdrachten die u op dat cluster uitvoert, gegevens lezen en schrijven in Azure Data Lake Storage zonder dat u referenties van de service-principal hoeft te configureren voor toegang tot opslag.
Azure Data Lake Storage referentiepassthrough wordt slechts ondersteund met Azure Data Lake Storage Gen1 en Gen2. Azure Blob Storage biedt geen ondersteuning voor referentiepassthrough.
Dit artikel behandelt:
- Referentiepassthrough inschakelen voor standaardclusters en clusters met hoge gelijktijdigheid.
- Referentiepassthrough configureren en opslagbronnen initialiseren in ADLS-accounts.
- Toegang tot ADLS-resources rechtstreeks wanneer referentiepassthrough is ingeschakeld.
- Toegang tot ADLS-resources via een koppelpunt wanneer referentiepassthrough is ingeschakeld.
- Ondersteunde functies en beperkingen bij het gebruik van referentiepassthrough.
Notebooks zijn opgenomen om voorbeelden te bieden van het gebruik van referentiepassthrough met ADLS Gen1- en ADLS Gen2-opslagaccounts.
Eisen
- Premium-abonnement. Zie Een Azure Databricks-werkruimte upgraden of downgraden voor meer info over het upgraden van een standard-abonnement naar een Premium-abonnement.
- Een Azure Data Lake Storage Gen1- of Gen2-opslagaccount. Azure Data Lake Storage Gen2-opslagaccounts moeten de hiërarchische naamruimte gebruiken om te werken met Azure Data Lake Storage referentiepassthrough. Zie Een opslagaccount maken voor instructies over het maken van een nieuw ADLS Gen2-account, inclusief het inschakelen van deze hiërarchische naamruimte.
- Juist geconfigureerde gebruikersmachtigingen voor Azure Data Lake Storage. Een Azure Databricks-beheerder moet ervoor zorgen dat gebruikers de juiste rollen hebben, bijvoorbeeld Inzender voor opslagblobgegevens, om gegevens te lezen en schrijven die zijn opgeslagen in Azure Data Lake Storage. Zie Use the Azure portal to assign an Azure role for access to blob and queue data (De Azure-portal gebruiken om een Azure-rol toe te wijzen voor toegang tot blob- en wachtrijgegevens).
- Meer informatie over de bevoegdheden van werkruimtebeheerders in werkruimten die zijn ingeschakeld voor passthrough en controleer uw bestaande toewijzingen van werkruimtebeheerders. Werkruimtebeheerders kunnen bewerkingen voor hun werkruimte beheren, waaronder het toevoegen van gebruikers en service-principals, het maken van clusters en het delegeren van andere gebruikers als werkruimtebeheerders. Werkruimtebeheertaken, zoals het beheren van het eigendom van taken en het weergeven van notebooks, kunnen indirecte toegang geven tot gegevens die zijn geregistreerd in Azure Data Lake Storage. Werkruimtebeheerder is een bevoorrechte rol die u zorgvuldig moet distribueren.
- U kunt geen cluster gebruiken dat is geconfigureerd met ADLS-referenties, bijvoorbeeld referenties van de service-principal, met referentiepassthrough.
Belangrijk
U kunt niet verifiëren bij Azure Data Lake Storage met uw Microsoft Entra ID-referenties als u zich achter een firewall bevindt die niet is geconfigureerd om verkeer naar Microsoft Entra-id toe te staan. Azure Firewall blokkeert standaard Active Directory-toegang. Als u toegang wilt toestaan, configureert u de servicetag AzureActiveDirectory. U vindt gelijkwaardige info voor virtuele netwerkapparaten onder de tag AzureActiveDirectory in het JSON-bestand Azure IP Ranges en Service Tags. Zie Azure Firewall servicetags en Azure IP-adressen voor openbare cloud voor meer info.
Aanbevelingen voor logboekregistratie
U kunt identiteiten registreren die worden doorgegeven aan ADLS-opslag in de diagnostische logboeken van Azure Storage. Met logboekregistratie-identiteiten kunnen ADLS-aanvragen worden gekoppeld aan afzonderlijke gebruikers vanuit Azure Databricks-clusters. Schakel diagnostische logboekregistratie in voor uw opslagaccount om deze logboeken te ontvangen:
- Azure Data Lake Storage Gen1: volg de instructies in Diagnostische logboekregistratie inschakelen voor uw Data Lake Storage Gen1-account.
- Azure Data Lake Storage Gen2: Configureren met behulp van PowerShell met de
Set-AzStorageServiceLoggingPropertyopdracht. Geef 2.0 op als versie, omdat logboekvermeldingsindeling 2.0 de principal-naam van de gebruiker in de aanvraag bevat.
Passthrough voor Azure Data Lake Storage-referenties inschakelen voor een cluster met hoge gelijktijdigheid
Clusters met hoge gelijktijdigheid kunnen door meerdere gebruikers worden gedeeld. Ze ondersteunen alleen Python en SQL met Azure Data Lake Storage-referentiepassthrough.
Belangrijk
Als u Azure Data Lake Storage-referentiepassthrough inschakelt voor een cluster met hoge gelijktijdigheid, worden alle poorten in het cluster geblokkeerd, met uitzondering van poorten 44, 53 en 80.
- Wanneer u een cluster maakt, stelt u de clustermodus in op Hoge gelijktijdigheid.
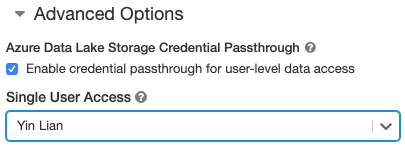
- Selecteer onder Geavanceerde opties referentiepassthrough inschakelen voor gegevenstoegang op gebruikersniveau en sta alleen Python- en SQL-opdrachten toe.

Passthrough voor Azure Data Lake Storage-referenties inschakelen voor een Standard-cluster
Standaardclusters met referentiepassthrough zijn beperkt tot één gebruiker. Standard-clusters ondersteunen Python, SQL, Scala en R. In Databricks Runtime 10.4 LTS en hoger wordt sparklyr ondersteund.
U moet een gebruiker toewijzen bij het maken van een cluster, maar het cluster kan op elk gewenst moment worden bewerkt door een gebruiker met CAN MANAGE-machtigingen om de oorspronkelijke gebruiker te vervangen.
Belangrijk
De gebruiker die aan het cluster is toegewezen, moet ten minste DE MACHTIGING KOPPELEN AAN voor het cluster hebben om opdrachten op het cluster uit te voeren. Werkruimtebeheerders en de maker van het cluster hebben CAN MANAGE-machtigingen, maar kunnen geen opdrachten uitvoeren op het cluster, tenzij ze de aangewezen clustergebruiker zijn.
- Wanneer u een cluster maakt, stelt u de clustermodus in op Standard.
- Selecteer onder Geavanceerde opties referentiepassthrough inschakelen voor gegevenstoegang op gebruikersniveau en selecteer de gebruikersnaam in de vervolgkeuzelijst Toegang voor één gebruiker.
Een container maken
Containers bieden een manier om objecten in een Azure-opslagaccount te organiseren.
Rechtstreeks toegang krijgen tot Azure Data Lake Storage met behulp van referentiepassthrough
Nadat u azure Data Lake Storage-referentiepassthrough hebt geconfigureerd en opslagcontainers hebt gemaakt, hebt u rechtstreeks toegang tot gegevens in Azure Data Lake Storage Gen1 met behulp van een adl:// pad en Azure Data Lake Storage Gen2 met behulp van een abfss:// pad.
Azure Data Lake Storage Gen1
Python
spark.read.format("csv").load("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv") %>% sdf_collect()
- Vervang door
<storage-account-name>de naam van het ADLS Gen1-opslagaccount.
Azure Data Lake Storage Gen2
Python
spark.read.format("csv").load("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv") %>% sdf_collect()
- Vervang door
<container-name>de naam van een container in het ADLS Gen2-opslagaccount. - Vervang door
<storage-account-name>de naam van het ADLS Gen2-opslagaccount.
Azure Data Lake Storage koppelen aan DBFS met behulp van referentiepassthrough
U kunt een Azure Data Lake Storage-account of een map erin koppelen aan Wat is het Databricks File System (DBFS)?. De mount is een aanwijzer naar een data lake store, zodat de gegevens nooit lokaal worden gesynchroniseerd.
Wanneer u gegevens koppelt met behulp van een cluster dat is ingeschakeld met azure Data Lake Storage-referentiepassthrough, gebruikt elke lees- of schrijfbewerking naar het koppelpunt uw Microsoft Entra ID-referenties. Dit koppelpunt is zichtbaar voor andere gebruikers, maar de enige gebruikers met lees- en schrijftoegang zijn degenen die:
- Toegang hebben tot het onderliggende Azure Data Lake Storage-opslagaccount
- Een cluster gebruiken dat is ingeschakeld voor passthrough van Azure Data Lake Storage-referenties
Azure Data Lake Storage Gen1
Gebruik de volgende opdrachten om een Azure Data Lake Storage Gen1-resource of map erin te koppelen:
Python
configs = {
"fs.adl.oauth2.access.token.provider.type": "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider": spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.adl.oauth2.access.token.provider.type" -> "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider" -> spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- Vervang door
<storage-account-name>de naam van het ADLS Gen2-opslagaccount. - Vervang
<mount-name>door de naam van het beoogde koppelpunt in DBFS.
Azure Data Lake Storage Gen2
Als u een Azure Data Lake Storage Gen2-bestandssysteem of een map erin wilt koppelen, gebruikt u de volgende opdrachten:
Python
configs = {
"fs.azure.account.auth.type": "CustomAccessToken",
"fs.azure.account.custom.token.provider.class": spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.azure.account.auth.type" -> "CustomAccessToken",
"fs.azure.account.custom.token.provider.class" -> spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- Vervang door
<container-name>de naam van een container in het ADLS Gen2-opslagaccount. - Vervang door
<storage-account-name>de naam van het ADLS Gen2-opslagaccount. - Vervang
<mount-name>door de naam van het beoogde koppelpunt in DBFS.
Waarschuwing
Geef geen toegangssleutels voor uw opslagaccount of referenties van de service-principal op om te verifiëren bij het koppelpunt. Hierdoor hebben andere gebruikers toegang tot het bestandssysteem met behulp van deze referenties. Het doel van passthrough voor Azure Data Lake Storage-referenties is om te voorkomen dat u deze referenties moet gebruiken en ervoor te zorgen dat de toegang tot het bestandssysteem wordt beperkt tot gebruikers die toegang hebben tot het onderliggende Azure Data Lake Storage-account.
Veiligheid
Het is veilig om Azure Data Lake Storage-referentiepassthrough-clusters te delen met andere gebruikers. U wordt geïsoleerd van elkaar en kunt elkaars referenties niet lezen of gebruiken.
Ondersteunde functies
| Functie | Minimale Databricks Runtime-versie | Opmerkingen |
|---|---|---|
| Python en SQL | 5.5 | |
| Azure Data Lake Storage Gen1 | 5.5 | |
%run |
5.5 | |
| DBFS | 5.5 | Referenties worden alleen doorgegeven als het DBFS-pad wordt omgezet in een locatie in Azure Data Lake Storage Gen1 of Gen2. Voor DBFS-paden die worden omgezet naar andere opslagsystemen, gebruikt u een andere methode om uw referenties op te geven. |
| Azure Data Lake Storage Gen2 | 5.5 | |
| schijfcache | 5.5 | |
| PySpark ML-API | 5.5 | De volgende ML-klassen worden niet ondersteund: * org/apache/spark/ml/classification/RandomForestClassifier* org/apache/spark/ml/clustering/BisectingKMeans* org/apache/spark/ml/clustering/GaussianMixture* org/spark/ml/clustering/KMeans* org/spark/ml/clustering/LDA* org/spark/ml/evaluation/ClusteringEvaluator* org/spark/ml/feature/HashingTF* org/spark/ml/feature/OneHotEncoder* org/spark/ml/feature/StopWordsRemover* org/spark/ml/feature/VectorIndexer* org/spark/ml/feature/VectorSizeHint* org/spark/ml/regression/IsotonicRegression* org/spark/ml/regression/RandomForestRegressor* org/spark/ml/util/DatasetUtils |
| Broadcast-variabelen | 5.5 | In PySpark is er een limiet voor de grootte van de Python UDF's die u kunt maken, omdat grote UDF's worden verzonden als broadcastvariabelen. |
| Notebook-scoped bibliotheken | 5.5 | |
| Scala | 5.5 | |
| SparkR | 6,0 | |
| sparklyr | 10.1 | |
| Een Databricks-notebook uitvoeren vanuit een ander notebook | 6.1 | |
| PySpark ML-API | 6.1 | Alle Ondersteunde PySpark ML-klassen. |
| Metrische clustergegevens | 6.1 | |
| Databricks Connect | 7.3 | Passthrough wordt ondersteund op Standard-clusters. |
Beperkingen
De volgende functies worden niet ondersteund met Azure Data Lake Storage-referentiepassthrough:
%fs(gebruik in plaats daarvan de equivalente dbutils.fs-opdracht ).- Databricks-werkstromen.
- De Naslaginformatie over de Databricks REST API.
- Unity Catalog.
- Toegangsbeheer voor tabellen. De machtigingen die zijn verleend door Azure Data Lake Storage-referentiepassthrough, kunnen worden gebruikt om de fijnmazige machtigingen van tabel-ACL's te omzeilen, terwijl de extra beperkingen van tabel-ACL's enkele van de voordelen beperken die u krijgt van referentiepassthrough. Met name:
- Als u microsoft Entra ID-machtigingen hebt om toegang te krijgen tot de gegevensbestanden die ten grondslag liggen aan een bepaalde tabel, hebt u volledige machtigingen voor die tabel via de RDD-API, ongeacht de beperkingen die hiervoor via tabel-ACL's zijn ingesteld.
- U wordt alleen beperkt door tabel-ACL-machtigingen wanneer u de DataFrame-API gebruikt. U ziet waarschuwingen over het niet hebben van machtigingen
SELECTvoor een bestand als u bestanden rechtstreeks probeert te lezen met de DataFrame-API, ook al kunt u deze bestanden rechtstreeks lezen via de RDD-API. - U kunt niet lezen uit tabellen die worden ondersteund door andere bestandssysteem dan Azure Data Lake Storage, zelfs niet als u een tabel-ACL-machtiging hebt om de tabellen te lezen.
- De volgende methoden voor SparkContext (
sc) en SparkSession(spark)-objecten:- Afgeschafte methoden.
- Methoden zoals
addFile()enaddJar()waarmee niet-beheerders Scala-code kunnen aanroepen. - Elke methode die toegang heeft tot een ander bestandssysteem dan Azure Data Lake Storage Gen1 of Gen2 (voor toegang tot andere bestandssysteemen op een cluster waarvoor Passthrough voor Azure Data Lake Storage-referentie is ingeschakeld, gebruikt u een andere methode om uw referenties op te geven en raadpleegt u de sectie over vertrouwde bestandssysteemen onder Probleemoplossing).
- De oude Hadoop-API's (
hadoopFile()enhadoopRDD()). - Streaming-API's, omdat de doorgegeven referenties verlopen terwijl de stream nog steeds wordt uitgevoerd.
- DBFS-koppelingen (
/dbfs) zijn alleen beschikbaar in Databricks Runtime 7.3 LTS en hoger. Koppelpunten waarvoor referentiepassthrough is geconfigureerd, worden niet ondersteund via dit pad. - Azure Data Factory.
- MLflow op clusters met hoge gelijktijdigheid.
- Python-pakket azureml-sdk op clusters met hoge gelijktijdigheid.
- U kunt de levensduur van passthrough-tokens voor Microsoft Entra-id's niet verlengen met behulp van het beleid voor de levensduur van het Microsoft Entra ID-token. Als u een opdracht verzendt naar het cluster dat langer dan een uur duurt, mislukt dit als een Azure Data Lake Storage-resource na de markering van 1 uur wordt geopend.
- Wanneer u Hive 2.3 en hoger gebruikt, kunt u geen partitie toevoegen aan een cluster waarvoor referentiepassthrough is ingeschakeld. Zie de relevante sectie voor probleemoplossing voor meer informatie.
Voorbeeldnotitieblokken
De volgende notebooks demonstreren azure Data Lake Storage-referentiepassthrough voor Azure Data Lake Storage Gen1 en Gen2.
Passthrough-notebook voor Azure Data Lake Storage Gen1
Passthrough-notebook voor Azure Data Lake Storage Gen2
Problemen oplossen
py4j.security.Py4JSecurityException: ... is niet opgenomen in de whitelist
Deze uitzondering wordt gegenereerd wanneer u een methode hebt geopend die Azure Databricks niet expliciet als veilig heeft gemarkeerd voor clusters met referentiepassthrough van Azure Data Lake Storage. In de meeste gevallen betekent dit dat de methode kan toestaan dat een gebruiker op een cluster met referentiepassthrough van Azure Data Lake Storage toegang krijgt tot de referenties van een andere gebruiker.
org.apache.spark.api.python.PythonSecurityException: Pad ... maakt gebruik van een niet-vertrouwd bestandssysteem
Deze uitzondering wordt gegenereerd als u hebt geprobeerd toegang te krijgen tot een bestandssysteem dat niet bekend is door het Azure Data Lake Storage referentiepassthrough-cluster om veilig te zijn. Als u een niet-vertrouwd bestandssysteem gebruikt, kan het zijn dat een gebruiker in een Referentiepassthrough-cluster van Azure Data Lake Storage toegang krijgt tot de referenties van een andere gebruiker, zodat we niet toestaan dat alle bestandssysteemen die we niet vertrouwen veilig worden gebruikt.
Als u de set vertrouwde bestandssystemen op een Azure Data Lake Storage-referentiepassthrough-cluster wilt configureren, stelt u de Spark-configuratiesleutel spark.databricks.pyspark.trustedFilesystems op dat cluster in als een door komma's gescheiden lijst met de klassenamen die vertrouwde implementaties van org.apache.hadoop.fs.FileSystem zijn.
Het toevoegen van een partitie mislukt wanneer AzureCredentialNotFoundException referentiepassthrough is ingeschakeld
Wanneer u Hive 2.3-3.1 gebruikt en u probeert een partitie toe te voegen aan een cluster waarvoor referentiepassthrough is ingeschakeld, treedt deze volgende uitzondering op:
org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:com.databricks.backend.daemon.data.client.adl.AzureCredentialNotFoundException: Could not find ADLS Gen2 Token
U kunt dit probleem omzeilen door partities toe te voegen aan een cluster zonder referentiepassthrough ingeschakeld.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor