Rekenproces configureren (verouderd)
Notitie
Dit zijn instructies voor de verouderde gebruikersinterface voor het maken van clusters en zijn alleen opgenomen voor historische nauwkeurigheid. Alle klanten moeten de bijgewerkte gebruikersinterface voor het maken van clusters gebruiken.
In dit artikel worden de configuratieopties uitgelegd die beschikbaar zijn wanneer u Azure Databricks-clusters maakt en bewerkt. Het richt zich op het maken en bewerken van clusters met behulp van de gebruikersinterface. Zie de Databricks CLI, de Clusters-API en de Terraform-provider van Databricks voor andere methoden.
Zie aanbevolen procedures voor clusterconfiguratie voor hulp bij het bepalen welke combinatie van configuratieopties het beste bij uw behoeften past.
Clusterbeleid
Een clusterbeleid beperkt de mogelijkheid om clusters te configureren op basis van een set regels. De beleidsregels beperken de kenmerken of kenmerkwaarden die beschikbaar zijn voor het maken van clusters. Clusterbeleid heeft ACL's die het gebruik beperken tot specifieke gebruikers en groepen en dus beperken welke beleidsregels u kunt selecteren wanneer u een cluster maakt.
Als u een clusterbeleid wilt configureren, selecteert u het clusterbeleid in de vervolgkeuzelijst Beleid .
Notitie
Als er geen beleidsregels zijn gemaakt in de werkruimte, wordt de vervolgkeuzelijst Beleid niet weergegeven.
Als u het volgende hebt:
- Machtiging voor cluster maken, kunt u het onbeperkte beleid selecteren en volledig configureerbare clusters maken. Het onbeperkte beleid beperkt geen clusterkenmerken of kenmerkwaarden.
- Zowel clustermachtigingen als toegang tot clusterbeleid maken, kunt u het onbeperkte beleid en het beleid selecteren dat u toegang hebt.
- Alleen toegang tot clusterbeleid, kunt u de beleidsregels selecteren waarvoor u toegang hebt.
Clustermodus
Notitie
In dit artikel worden de gebruikersinterface van verouderde clusters beschreven. Zie de referentie voor compute-configuratie voor informatie over de gebruikersinterface van nieuwe clusters (in preview). Dit omvat enkele terminologiewijzigingen voor clustertoegangstypen en -modi. Zie Clusters UI-wijzigingen en clustertoegangsmodi voor een vergelijking van de nieuwe en verouderde clustertypen. In de preview-gebruikersinterface:
- Clusters in de standaardmodus worden nu clusters met gedeelde toegangsmodus geen isolatie genoemd.
- Hoge gelijktijdigheid met tabellen-ACL's worden nu clusters met de modus Gedeelde toegang genoemd.
Azure Databricks ondersteunt drie clustermodi: Standard, High Concurrency en Single Node. De standaardclustermodus is Standard.
Belangrijk
- Als uw werkruimte is toegewezen aan een Unity Catalog-metastore , zijn clusters met hoge gelijktijdigheid niet beschikbaar. In plaats daarvan gebruikt u de toegangsmodus om de integriteit van toegangsbeheer te garanderen en sterke isolatiegaranties af te dwingen. Zie ook Access-modi.
- U kunt de clustermodus niet wijzigen nadat een cluster is gemaakt. Als u een andere clustermodus wilt, moet u een nieuw cluster maken.
De clusterconfiguratie bevat een instelling voor automatisch beëindigen waarvan de standaardwaarde afhankelijk is van de clustermodus:
- Standaardclusters en clusters met één knooppunt worden standaard na 120 minuten automatisch beëindigd.
- Clusters met hoge gelijktijdigheid worden niet standaard automatisch beëindigd.
Standaardclusters
Waarschuwing
Clusters in de standaardmodus (ook wel Gedeelde clusters zonder isolatie genoemd) kunnen worden gedeeld door meerdere gebruikers, zonder isolatie tussen gebruikers. Als u de clustermodus Hoge gelijktijdigheid gebruikt zonder extra beveiligingsinstellingen zoals Tabel-ACL's of Referentiepassthrough, worden dezelfde instellingen gebruikt als clusters in de standaardmodus. Accountbeheerders kunnen voorkomen dat interne referenties automatisch worden gegenereerd voor Databricks-werkruimtebeheerders op dit type cluster. Voor veiligere opties raadt Databricks alternatieven aan, zoals clusters met hoge gelijktijdigheid met tabel-ACL's.
Een Standard-cluster wordt alleen aanbevolen voor individuele gebruikers. Standaardclusters kunnen workloads uitvoeren die zijn ontwikkeld in Python, SQL, R en Scala.
Clusters met hoge gelijktijdigheid
Een cluster met hoge gelijktijdigheid is een beheerde cloudresource. De belangrijkste voordelen van clusters met hoge gelijktijdigheid zijn dat ze gedetailleerd delen bieden voor maximaal resourcegebruik en minimale querylatenties.
Clusters met hoge gelijktijdigheid kunnen workloads uitvoeren die zijn ontwikkeld in SQL, Python en R. De prestaties en beveiliging van clusters met hoge gelijktijdigheid worden geleverd door gebruikerscode uit te voeren in afzonderlijke processen, wat niet mogelijk is in Scala.
Daarnaast bieden alleen clusters met hoge gelijktijdigheid ondersteuning voor toegangsbeheer voor tabellen.
Als u een cluster met hoge gelijktijdigheid wilt maken, stelt u de clustermodus in op Hoge gelijktijdigheid.
Clusters met één knooppunt
Een cluster met één knooppunt heeft geen werkrollen en voert Spark-taken uit op het stuurprogrammaknooppunt.
Een Standard-cluster vereist daarentegen ten minste één Spark-werkknooppunt naast het stuurprogrammaknooppunt om Spark-taken uit te voeren.
Als u een cluster met één knooppunt wilt maken, stelt u de clustermodus in op één knooppunt.
Zie Rekenkracht met één knooppunt of meerdere knooppunten voor meer informatie over het werken met clusters met één knooppunt.
Zwembaden
Als u de begintijd van het cluster wilt verminderen, kunt u een cluster koppelen aan een vooraf gedefinieerde groep niet-actieve exemplaren, voor het stuurprogramma en werkknooppunten. Het cluster wordt gemaakt met behulp van exemplaren in de pools. Als een pool onvoldoende niet-actieve resources heeft om het aangevraagde stuurprogramma of werkknooppunt te maken, wordt de pool uitgebreid door nieuwe exemplaren toe te wijzen van de instantieprovider. Wanneer een gekoppeld cluster wordt beëindigd, worden de gebruikte exemplaren geretourneerd naar de pools en kunnen ze opnieuw worden gebruikt door een ander cluster.
Als u een pool selecteert voor werkknooppunten, maar niet voor het stuurprogrammaknooppunt, neemt het stuurprogrammaknooppunt de pool over van de configuratie van het werkknooppunt.
Belangrijk
Als u probeert een pool te selecteren voor het stuurprogrammaknooppunt, maar niet voor werkknooppunten, treedt er een fout op en wordt uw cluster niet gemaakt. Deze vereiste voorkomt een situatie waarin het stuurprogrammaknooppunt moet wachten tot werkknooppunten zijn gemaakt, of omgekeerd.
Zie Naslaginformatie over poolconfiguratie voor meer informatie over het werken met pools in Azure Databricks.
Databricks Runtime
Databricks-runtimes zijn de set kernonderdelen die op uw clusters worden uitgevoerd. Alle Databricks-runtimes bevatten Apache Spark en voegen onderdelen en updates toe die de bruikbaarheid, prestaties en beveiliging verbeteren. Zie de releaseversies en compatibiliteit van Databricks Runtime voor meer informatie.
Azure Databricks biedt verschillende typen runtimes en verschillende versies van deze runtimetypen in de vervolgkeuzelijst Databricks Runtime-versie wanneer u een cluster maakt of bewerkt.
Fotonversnelling
Photon is beschikbaar voor clusters met Databricks Runtime 9.1 LTS en hoger.
Als u Photon-versnelling wilt inschakelen, schakelt u het selectievakje Fotonversnelling gebruiken in.
Desgewenst kunt u het exemplaartype opgeven in de vervolgkeuzelijst Werkroltype en Stuurprogrammatype.
Databricks raadt de volgende exemplaartypen aan voor optimale prijs en prestaties:
- Standard_E4ds_v4
- Standard_E8ds_v4
- Standard_E16ds_v4
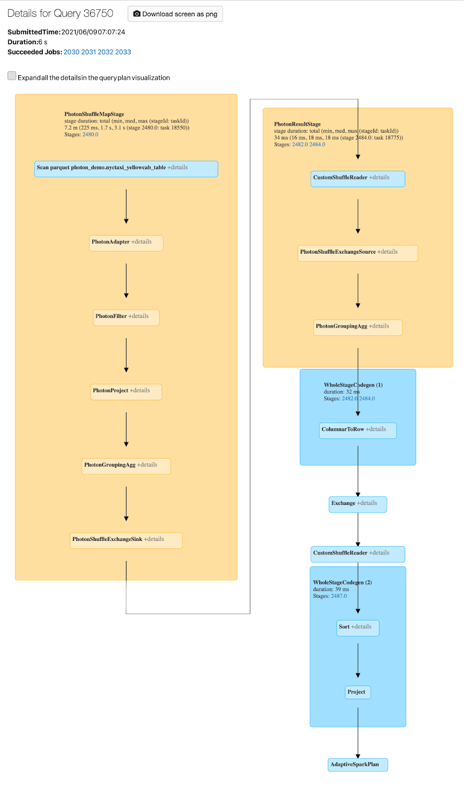
U kunt Photon-activiteit bekijken in de Spark-gebruikersinterface. In de volgende schermopname ziet u de querydetails DAG. Er zijn twee indicaties van Photon in de DAG. Eerst beginnen Photon-operators met 'Photon', bijvoorbeeld PhotonGroupingAgg. Ten tweede zijn fotonen operatoren en stadia gekleurde perzik, terwijl de niet-Photon degenen blauw zijn.
Docker-installatiekopieën
Voor sommige Databricks Runtime-versies kunt u een Docker-installatiekopieën opgeven wanneer u een cluster maakt. Voorbeelden van gebruiksvoorbeelden zijn bibliotheekaanpassing, een gouden containeromgeving die niet verandert en Docker CI/CD-integratie.
U kunt docker-installatiekopieën ook gebruiken om aangepaste Deep Learning-omgevingen te maken op clusters met GPU-apparaten.
Zie Containers aanpassen met Databricks Container Service en Databricks Container Services op GPU-rekenkracht voor instructies.
Clusterknooppunttype
Een cluster bestaat uit één stuurprogrammaknooppunt en nul of meer werkknooppunten.
U kunt afzonderlijke typen cloudproviderexemplaren kiezen voor het stuurprogramma- en werkknooppunt, hoewel het stuurprogrammaknooppunt standaard hetzelfde exemplaartype gebruikt als het werkknooppunt. Verschillende typen exemplaren passen bij verschillende gebruiksvoorbeelden, zoals geheugenintensieve of rekenintensieve workloads.
Notitie
Als uw beveiligingsvereisten rekenisolatie bevatten, selecteert u een Standard_F72s_V2 exemplaar als uw werkroltype. Deze exemplaartypen vertegenwoordigen geïsoleerde virtuele machines die de volledige fysieke host gebruiken en het benodigde isolatieniveau bieden dat nodig is ter ondersteuning van bijvoorbeeld IL5-workloads (Department of Defense Impact Level 5).
Stuurprogrammaknooppunt
Het stuurprogrammaknooppunt houdt statusinformatie bij van alle notebooks die aan het cluster zijn gekoppeld. Het stuurprogrammaknooppunt onderhoudt ook de SparkContext en interpreteert alle opdrachten die u vanuit een notebook of een bibliotheek in het cluster uitvoert en voert de Apache Spark-master uit die wordt gecoördineerd met de Spark-uitvoerders.
De standaardwaarde van het type stuurprogrammaknooppunt is hetzelfde als het type werkknooppunt. U kunt een groter type stuurprogrammaknooppunt met meer geheugen kiezen als u van plan bent om veel gegevens van Spark-werkrollen te collect() gebruiken en deze te analyseren in het notebook.
Tip
Omdat het stuurprogrammaknooppunt alle statusgegevens van de gekoppelde notitieblokken onderhoudt, moet u ongebruikte notitieblokken loskoppelen van het stuurprogrammaknooppunt.
Werkknooppunt
Azure Databricks-werkknooppunten voeren de Spark-uitvoerders en andere services uit die nodig zijn voor de juiste werking van de clusters. Wanneer u uw workload distribueert met Spark, vindt alle gedistribueerde verwerking plaats op werkknooppunten. Azure Databricks voert één uitvoerder per werkknooppunt uit; daarom worden de termenuitvoerders en werkrollen door elkaar gebruikt in de context van de Azure Databricks-architectuur.
Tip
Als u een Spark-taak wilt uitvoeren, hebt u ten minste één werkknooppunt nodig. Als een cluster nul werkrollen heeft, kunt u andere dan Apache Spark-opdrachten uitvoeren op het stuurprogrammaknooppunt, maar zullen Apache Spark-opdrachten mislukken.
GPU-exemplaartypen
Azure Databricks biedt ondersteuning voor clusters die zijn versneld met GPU's (Graphics Processing Units). Zie rekenkracht met GPU voor meer informatie.
Spot-exemplaren
Als u kosten wilt besparen, kunt u ervoor kiezen om spot-exemplaren te gebruiken , ook wel Azure Spot-VM's genoemd door het selectievakje Spot-exemplaren in te schakelen.

Het eerste exemplaar is altijd on-demand (het stuurprogrammaknooppunt is altijd on-demand) en volgende exemplaren zijn spot-exemplaren. Als spot-exemplaren worden verwijderd vanwege niet-beschikbaarheid, worden on-demand exemplaren geïmplementeerd om verwijderde exemplaren te vervangen.
Clustergrootte en automatische schaalaanpassing
Wanneer u een Azure Databricks-cluster maakt, kunt u een vast aantal werkrollen voor het cluster opgeven of een minimum- en maximum aantal werkrollen voor het cluster opgeven.
Wanneer u een cluster met een vaste grootte opgeeft, zorgt Azure Databricks ervoor dat uw cluster het opgegeven aantal werkrollen heeft. Wanneer u een bereik opgeeft voor het aantal werknemers, kiest Databricks het juiste aantal werkrollen dat nodig is om uw taak uit te voeren. Dit wordt automatisch schalen genoemd.
Met automatisch schalen worden werknemers in Azure Databricks dynamisch verplaatst om rekening te houden met de kenmerken van uw taak. Bepaalde onderdelen van uw pijplijn kunnen meer rekenkracht vereisen dan andere, en Databricks voegt automatisch extra werkrollen toe tijdens deze fasen van uw taak (en verwijdert ze wanneer ze niet meer nodig zijn).
Automatische schaalaanpassing maakt het eenvoudiger om een hoog clustergebruik te bereiken, omdat u het cluster niet hoeft in te richten om aan een workload te voldoen. Dit geldt met name voor workloads waarvan de vereisten na verloop van tijd veranderen (zoals het verkennen van een gegevensset tijdens de loop van een dag), maar deze kan ook van toepassing zijn op een eenmalige kortere workload waarvan de inrichtingsvereisten onbekend zijn. Automatische schaalaanpassing biedt dus twee voordelen:
- Workloads kunnen sneller worden uitgevoerd in vergelijking met een cluster met een constante grootte die niet is ingericht.
- Automatische schaalaanpassing van clusters kan de totale kosten verlagen in vergelijking met een statisch cluster.
Afhankelijk van de constante grootte van het cluster en de workload biedt automatische schaalaanpassing u een of beide voordelen tegelijk. De clustergrootte kan lager zijn dan het minimale aantal werknemers dat is geselecteerd wanneer de cloudprovider exemplaren beëindigt. In dit geval probeert Azure Databricks voortdurend instanties opnieuw in te richten om het minimale aantal werknemers te behouden.
Notitie
Automatisch schalen is niet beschikbaar voor spark-submit-taken.
De werking van automatisch schalen
- Schaalt omhoog van min tot max in 2 stappen.
- Kan omlaag schalen, zelfs als het cluster niet inactief is door de status van het willekeurige bestand te bekijken.
- Schaalt omlaag op basis van een percentage van de huidige knooppunten.
- Schaalt op taakclusters omlaag als het cluster de afgelopen 40 seconden te weinig wordt gebruikt.
- Bij clusters met alle doeleinden schaalt u omlaag als het cluster in de afgelopen 150 seconden te weinig wordt gebruikt.
- De
spark.databricks.aggressiveWindowDownSspark-configuratie-eigenschap geeft in seconden op hoe vaak een cluster beslissingen neemt over omlaag schalen. Als u de waarde verhoogt, wordt een cluster langzamer omlaag geschaald. De maximumwaarde is 600.
Automatisch schalen inschakelen en configureren
Als u wilt toestaan dat Azure Databricks het formaat van uw cluster automatisch wijzigt, schakelt u automatisch schalen voor het cluster in en geeft u het minimale en maximale bereik van werkrollen op.
Schakel automatisch schalen in.
Cluster met alle doeleinden: schakel op de pagina Cluster maken het selectievakje Automatisch schalen inschakelen in het vak Autopilot-opties in:

Taakcluster: schakel op de pagina Cluster configureren het selectievakje Automatisch schalen inschakelen in het vak Autopilot-opties in:

Configureer de minimale en maximale werkrollen.

Wanneer het cluster wordt uitgevoerd, wordt op de detailpagina van het cluster het aantal toegewezen werkrollen weergegeven. U kunt het aantal toegewezen werknemers vergelijken met de werkrolconfiguratie en zo nodig aanpassingen aanbrengen.
Belangrijk
Als u een exemplaargroep gebruikt:
- Zorg ervoor dat de aangevraagde clustergrootte kleiner is dan of gelijk is aan het minimale aantal niet-actieve exemplaren in de pool. Als deze groter is, is de opstarttijd van het cluster gelijk aan een cluster dat geen pool gebruikt.
- Zorg ervoor dat de maximale clustergrootte kleiner is dan of gelijk is aan de maximale capaciteit van de pool. Als deze groter is, mislukt het maken van het cluster.
Voorbeeld van automatisch schalen
Als u een statisch cluster opnieuw configureert als een automatisch schalend cluster, wijzigt Azure Databricks het cluster onmiddellijk binnen de minimum- en maximumgrenzen en wordt automatisch schalen gestart. In de volgende tabel ziet u bijvoorbeeld wat er gebeurt met clusters met een bepaalde initiële grootte als u een cluster opnieuw configureert voor automatische schaalaanpassing tussen 5 en 10 knooppunten.
| Oorspronkelijke grootte | Grootte na herconfiguratie |
|---|---|
| 6 | 6 |
| 12 | 10 |
| 3 | 5 |
Lokale opslag automatisch schalen
Het kan vaak lastig zijn om te schatten hoeveel schijfruimte een bepaalde taak nodig heeft. Als u wilt besparen hoeveel gigabytes beheerde schijf u tijdens het maken aan uw cluster moet koppelen, schakelt Azure Databricks automatisch het automatisch schalen van lokale opslag in op alle Azure Databricks-clusters.
Met automatische schaalaanpassing van lokale opslag bewaakt Azure Databricks de hoeveelheid vrije schijfruimte die beschikbaar is voor spark-werkrollen van uw cluster. Als een werkrol te laag op schijf begint te worden uitgevoerd, koppelt Databricks automatisch een nieuwe beheerde schijf aan de werkrol voordat er onvoldoende schijfruimte beschikbaar is. Schijven zijn gekoppeld aan een limiet van 5 TB aan totale schijfruimte per virtuele machine (inclusief de initiële lokale opslag van de virtuele machine).
De beheerde schijven die aan een virtuele machine zijn gekoppeld, worden alleen losgekoppeld wanneer de virtuele machine wordt geretourneerd naar Azure. Beheerde schijven worden dus nooit losgekoppeld van een virtuele machine zolang deze deel uitmaakt van een actief cluster. Als u het gebruik van beheerde schijven omlaag wilt schalen, raadt Azure Databricks aan om deze functie te gebruiken in een cluster dat is geconfigureerd met clustergrootte en automatische schaalaanpassing of onverwachte beëindiging.
Lokale schijfversleuteling
Belangrijk
Deze functie is beschikbaar als openbare preview.
Sommige exemplaartypen die u gebruikt om clusters uit te voeren, hebben mogelijk lokaal gekoppelde schijven. Azure Databricks kan willekeurige gegevens of tijdelijke gegevens opslaan op deze lokaal gekoppelde schijven. Om ervoor te zorgen dat alle data-at-rest is versleuteld voor alle opslagtypen, inclusief willekeurige gegevens die tijdelijk worden opgeslagen op de lokale schijven van uw cluster, kunt u versleuteling van lokale schijven inschakelen.
Belangrijk
Uw workloads kunnen langzamer worden uitgevoerd vanwege de invloed van de prestaties van het lezen en schrijven van versleutelde gegevens naar en van lokale volumes.
Wanneer lokale schijfversleuteling is ingeschakeld, genereert Azure Databricks lokaal een versleutelingssleutel die uniek is voor elk clusterknooppunt en wordt gebruikt voor het versleutelen van alle gegevens die zijn opgeslagen op lokale schijven. Het bereik van de sleutel is lokaal voor elk clusterknooppunt en wordt samen met het clusterknooppunt zelf vernietigd. Tijdens de levensduur bevindt de sleutel zich in het geheugen voor versleuteling en ontsleuteling en wordt deze versleuteld op de schijf opgeslagen.
Als u lokale schijfversleuteling wilt inschakelen, moet u de Clusters-API gebruiken. Stel tijdens het maken of bewerken van het cluster het volgende in:
{
"enable_local_disk_encryption": true
}
Zie de Clusters-API voor voorbeelden van het aanroepen van deze API's.
Hier volgt een voorbeeld van een aanroep voor het maken van een cluster waarmee lokale schijfversleuteling wordt ingeschakeld:
{
"cluster_name": "my-cluster",
"spark_version": "7.3.x-scala2.12",
"node_type_id": "Standard_D3_v2",
"enable_local_disk_encryption": true,
"spark_conf": {
"spark.speculation": true
},
"num_workers": 25
}
Beveiligingsmodus
Als uw werkruimte is toegewezen aan een Unity Catalog-metastore , gebruikt u de beveiligingsmodus in plaats van de clustermodus Hoge gelijktijdigheid om de integriteit van toegangsbeheer te waarborgen en sterke isolatiegaranties af te dwingen. De clustermodus Voor hoge gelijktijdigheid is niet beschikbaar met Unity Catalog.
Selecteer onder Geavanceerde opties de volgende clusterbeveiligingsmodi:
- Geen: geen isolatie. Dwingt geen toegangsbeheer voor werkruimten of referentiepassthrough af. Geen toegang tot Unity Catalog-gegevens.
- Eén gebruiker: kan alleen door één gebruiker worden gebruikt (standaard de gebruiker die het cluster heeft gemaakt). Andere gebruikers kunnen niet aan het cluster koppelen. Wanneer u een weergave opent vanuit een cluster met de beveiligingsmodus voor één gebruiker , wordt de weergave uitgevoerd met de machtigingen van de gebruiker. Clusters met één gebruiker ondersteunen workloads met behulp van Python, Scala en R. Init-scripts, bibliotheekinstallatie en DBFS-koppelingen worden ondersteund op clusters met één gebruiker. Geautomatiseerde taken moeten clusters met één gebruiker gebruiken.
- Gebruikersisolatie: kan worden gedeeld door meerdere gebruikers. Alleen SQL-workloads worden ondersteund. Bibliotheekinstallatie, init-scripts en DBFS-koppelingen zijn uitgeschakeld om strikte isolatie af te dwingen tussen de clustergebruikers.
- Alleen tabel-ACL (verouderd): dwingt toegangsbeheer voor werkruimten af, maar heeft geen toegang tot Unity Catalog-gegevens.
- Alleen passthrough (verouderd): dwingt passthrough van werkruimten af, maar heeft geen toegang tot Unity Catalog-gegevens.
De enige beveiligingsmodi die worden ondersteund voor Unity Catalog-workloads, zijn individuele gebruikers - en gebruikersisolatie.
Zie Access-modi voor meer informatie.
Spark-configuratie
Als u Spark-taken wilt verfijnen, kunt u aangepaste Spark-configuratie-eigenschappen opgeven in een clusterconfiguratie.
Klik op de pagina clusterconfiguratie op de wisselknop Geavanceerde opties .
Klik op het tabblad Spark .
Voer in Spark-configuratie de configuratie-eigenschappen in als één sleutel-waardepaar per regel.
Wanneer u een cluster configureert met behulp van de Cluster-API, stelt u Spark-eigenschappen in het spark_conf veld in de cluster-API maken of clusterconfiguratie-API bijwerken.
Databricks raadt het gebruik van globale init-scripts niet aan.
Als u Spark-eigenschappen voor alle clusters wilt instellen, maakt u een globaal init-script:
dbutils.fs.put("dbfs:/databricks/init/set_spark_params.sh","""
|#!/bin/bash
|
|cat << 'EOF' > /databricks/driver/conf/00-custom-spark-driver-defaults.conf
|[driver] {
| "spark.sql.sources.partitionOverwriteMode" = "DYNAMIC"
|}
|EOF
""".stripMargin, true)
Een Spark-configuratie-eigenschap ophalen uit een geheim
Databricks raadt aan gevoelige informatie, zoals wachtwoorden, op te slaan in een geheim in plaats van tekst zonder opmaak. Gebruik de volgende syntaxis om te verwijzen naar een geheim in de Spark-configuratie:
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
Als u bijvoorbeeld een Spark-configuratie-eigenschap wilt instellen die wordt aangeroepen password naar de waarde van het geheim dat is opgeslagen in secrets/acme_app/password:
spark.password {{secrets/acme-app/password}}
Zie Syntaxis voor het verwijzen naar geheimen in een Spark-configuratie-eigenschap of omgevingsvariabele voor meer informatie.
Omgevingsvariabelen
U kunt aangepaste omgevingsvariabelen configureren die u kunt openen vanuit init-scripts die worden uitgevoerd op een cluster. Databricks biedt ook vooraf gedefinieerde omgevingsvariabelen die u kunt gebruiken in init-scripts. U kunt deze vooraf gedefinieerde omgevingsvariabelen niet overschrijven.
Klik op de pagina clusterconfiguratie op de wisselknop Geavanceerde opties .
Klik op het tabblad Spark .
Stel de omgevingsvariabelen in het veld Omgevingsvariabelen in.
U kunt ook omgevingsvariabelen instellen met behulp van het spark_env_vars veld in de cluster-API maken of de clusterconfiguratie-API bijwerken.
Clustertags
Met clustertags kunt u eenvoudig de kosten bewaken van cloudresources die door verschillende groepen in uw organisatie worden gebruikt. U kunt tags opgeven als sleutel-waardeparen wanneer u een cluster maakt en Azure Databricks past deze tags toe op cloudresources, zoals VM's en schijfvolumes, evenals DBU-gebruiksrapporten.
Voor clusters die worden gestart vanuit pools, worden de aangepaste clustertags alleen toegepast op DBU-gebruiksrapporten en worden ze niet doorgegeven aan cloudresources.
Zie Gebruik bewaken met behulp van tags voor gedetailleerde informatie over hoe pool- en clustertagtypen samenwerken.
Voor het gemak past Azure Databricks vier standaardtags toe op elk cluster: Vendor, Creator, ClusterNameen ClusterId.
Bovendien past Azure Databricks op taakclusters twee standaardtags toe: RunName en JobId.
Op resources die worden gebruikt door Databricks SQL, past Azure Databricks ook de standaardtag SqlWarehouseIdtoe.
Waarschuwing
Wijs geen aangepaste tag met de sleutel Name toe aan een cluster. Elk cluster heeft een tag Name waarvan de waarde is ingesteld door Azure Databricks. Als u de waarde wijzigt die is gekoppeld aan de sleutel Name, kan het cluster niet meer worden bijgehouden door Azure Databricks. Als gevolg hiervan wordt het cluster mogelijk niet beëindigd nadat het inactief is geworden en blijven er gebruikskosten in rekening worden gebracht.
U kunt aangepaste tags toevoegen wanneer u een cluster maakt. Clustertags configureren:
Klik op de pagina clusterconfiguratie op de wisselknop Geavanceerde opties .
Klik onder aan de pagina op het tabblad Tags .
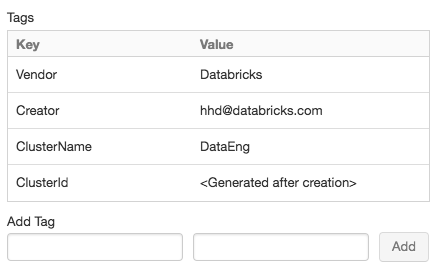
Voeg een sleutel-waardepaar toe voor elke aangepaste tag. U kunt maximaal 43 aangepaste tags toevoegen.
SSH-toegang tot clusters
Om veiligheidsredenen wordt de SSH-poort in Azure Databricks standaard gesloten. Als u SSH-toegang tot uw Spark-clusters wilt inschakelen, neemt u contact op met de ondersteuning van Azure Databricks.
Notitie
SSH kan alleen worden ingeschakeld als uw werkruimte is geïmplementeerd in uw eigen virtuele Azure-netwerk.
Levering clusterlogboek
Wanneer u een cluster maakt, kunt u een locatie opgeven voor het leveren van de logboeken voor het Spark-stuurprogrammaknooppunt, werkknooppunten en gebeurtenissen. Logboeken worden elke vijf minuten geleverd op de door u gekozen bestemming. Wanneer een cluster wordt beëindigd, garandeert Azure Databricks dat alle logboeken worden geleverd die zijn gegenereerd totdat het cluster is beëindigd.
Het doel van de logboeken is afhankelijk van de cluster-id. Als de opgegeven bestemming is dbfs:/cluster-log-delivery, worden clusterlogboeken 0630-191345-leap375 geleverd aan dbfs:/cluster-log-delivery/0630-191345-leap375.
Ga als volgende te werk om de locatie voor de levering van logboeken te configureren:
Klik op de pagina clusterconfiguratie op de wisselknop Geavanceerde opties .
Klik op het tabblad Logboekregistratie .
Selecteer een doeltype.
Voer het pad naar het clusterlogboek in.
Notitie
Deze functie is ook beschikbaar in de REST API. Zie de Clusters-API.
Init-scripts
Een initialisatie van een clusterknooppunt (of init) is een shellscript dat wordt uitgevoerd tijdens het opstarten voor elk clusterknooppunt voordat het Spark-stuurprogramma of de werkrol-JVM wordt gestart. U kunt init-scripts gebruiken om pakketten en bibliotheken te installeren die niet zijn opgenomen in de Databricks-runtime, het JVM-systeemklassepad te wijzigen, systeemeigenschappen en omgevingsvariabelen in te stellen die door de JVM worden gebruikt, of spark-configuratieparameters te wijzigen, onder andere configuratietaken.
U kunt init-scripts aan een cluster koppelen door de sectie Geavanceerde opties uit te vouwen en op het tabblad Init-scripts te klikken.
Zie Wat zijn init-scripts? voor gedetailleerde instructies.