Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In dit artikel wordt uitgelegd hoe u het systeemeigen hulpprogramma voor metrische rekengegevens in de Gebruikersinterface van Azure Databricks kunt gebruiken om belangrijke hardware- en Spark-metrische gegevens te verzamelen. De gebruikersinterface voor metrische gegevens is beschikbaar voor alle algemene toepassingen en takenberekeningen.
Metrische gegevens zijn bijna in realtime beschikbaar met een normale vertraging van minder dan één minuut. Metrische gegevens worden opgeslagen in door Azure Databricks beheerde opslag, niet in de opslag van de klant.
Serverloze berekening voor notebooks en taken maakt gebruik van query-inzichten in plaats van de gebruikersinterface voor metrische gegevens. Zie Query-inzichten weergeven voor meer informatie over serverloze rekengegevens.
Toegang tot de gebruikersinterface voor metrische rekengegevens
Om de gebruikersinterface voor compute-metrieken weer te geven:
- Klik op Compute in de zijbalk.
- Klik op de rekenresource waarvoor u metrische gegevens wilt weergeven.
- Klik op het tabblad Metrische gegevens .
Hardwaregegevens voor alle knooppunten worden standaard weergegeven. Als u metrische Spark-gegevens wilt weergeven, klikt u op de vervolgkeuzelijst met het label Hardware en selecteert u Spark. U kunt ook GPU selecteren als de instantie is ingeschakeld voor GPU.
Metrische gegevens filteren op tijdsperiode
U kunt historische metrische gegevens weergeven door een tijdsbereik te selecteren met behulp van het filter voor datumkiezer. Metrische gegevens worden elke minuut verzameld, zodat u kunt filteren op elk dag-, uur- of minuutbereik van de afgelopen 30 dagen. Klik op het agendapictogram om een keuze te maken uit vooraf gedefinieerde gegevensbereiken of klik in het tekstvak om aangepaste waarden te definiëren.
Notitie
De tijdsintervallen die in de grafieken worden weergegeven, worden aangepast op basis van de tijdsduur die u bekijkt. De meeste metrische gegevens zijn gemiddelden op basis van het tijdsinterval dat u momenteel bekijkt.
U kunt ook de meest recente metrische gegevens ophalen door op de knop Vernieuwen te klikken.
Metrische gegevens weergeven op knooppuntniveau
Op de pagina met metrische gegevens worden standaard metrische gegevens weergegeven voor alle knooppunten binnen een cluster (inclusief het stuurprogramma) die gemiddeld zijn gedurende de periode.
U kunt metrische gegevens voor afzonderlijke knooppunten weergeven door te klikken op het vervolgkeuzemenu Alle knooppunten en het knooppunt te selecteren waarvoor u metrische gegevens wilt weergeven. GPU-metrische gegevens zijn alleen beschikbaar op het niveau van afzonderlijke knooppunten. Metrische Spark-gegevens zijn niet beschikbaar voor afzonderlijke knooppunten.
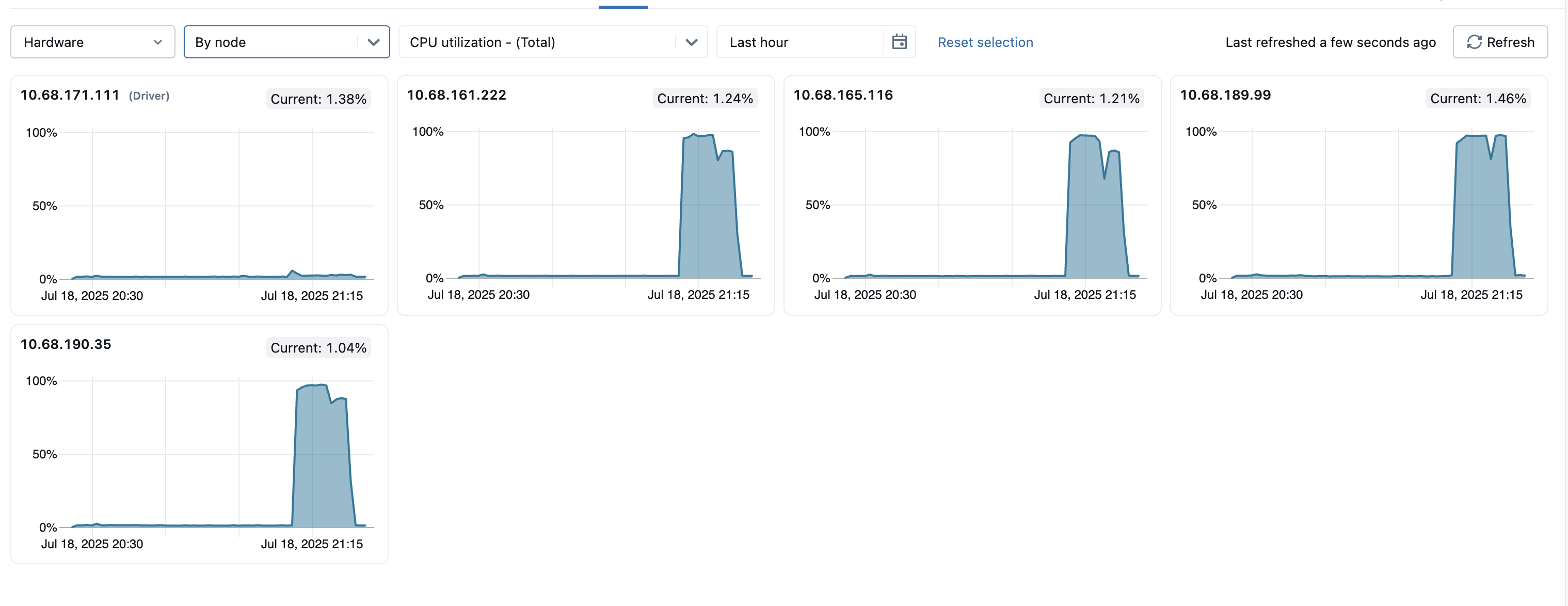
Om te helpen bij het identificeren van randgevallen binnen het cluster, kunt u ook de metrics voor alle afzonderlijke knooppunten op één pagina weergeven. Als u deze weergave wilt openen, klikt u op het vervolgkeuzemenu Alle knooppunten en selecteert u Op knooppunt en selecteert u vervolgens de subcategorie voor metrische gegevens die u wilt weergeven.
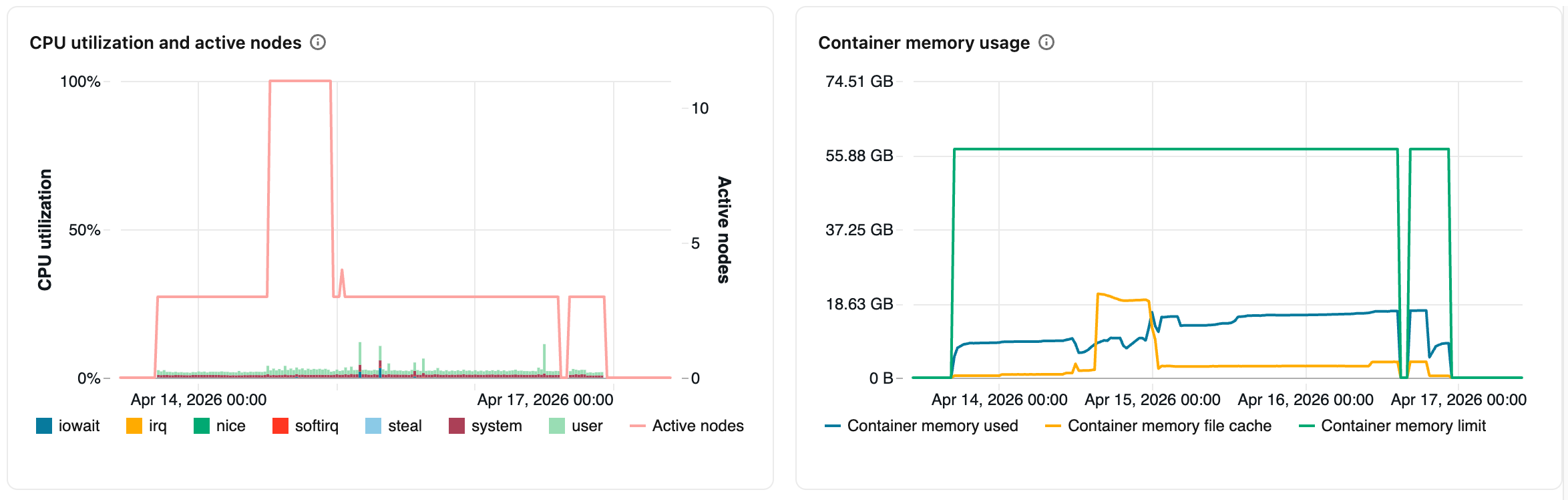
Grafieken met metrische hardwaregegevens
De volgende grafieken met metrische hardware zijn beschikbaar om weer te geven in de gebruikersinterface voor metrische rekengegevens:
-
CPU-gebruik en actieve knooppunten: in de lijngrafiek wordt het aantal actieve knooppunten weergegeven op elke tijdstempel voor de opgegeven rekenkracht. In het staafdiagram wordt het percentage tijd weergegeven dat de CPU in elke modus heeft besteed, op basis van de totale kosten voor CPU-seconden. Hier volgen de bijgehouden modi:
-
guest: Als u VM's uitvoert, is het de CPU die door die VM's wordt gebruikt. -
iowait: Tijd besteed aan wachten op I/O -
idle: Tijd dat de CPU niets te doen had -
irq: Tijd besteed aan onderbrekingsaanvragen -
nice: Tijd die wordt gebruikt door processen die positief zijn, wat een lagere prioriteit betekent dan andere taken -
softirq: Tijd besteed aan softwareonderbrekaanvragen -
steal: Als u een virtuele machine bent, hoeveel tijd andere VM's hebben 'gestolen' van uw CPU's -
system: De tijd die in de kernel is besteed -
user: De tijd die in gebruikersruimte is besteed
-
-
Geheugengebruik van containers: het geheugen dat wordt verbruikt door de Spark-container, gemiddeld op alle toepasselijke knooppunten. Bevat gemiddelden van niet-terugvorderbaar geheugen (
Container memory used), de cache van de bestandspagina van het besturingssysteem (Container memory file cache) en de geconfigureerde geheugenlimiet (Container memory limit). - JVM-heapgebruik: het geheugengebruik van de JVM heap, gemiddeld voor alle toepasselijke knooppunten. Omvat gemiddelden van het werkelijke heapgebruik, de heap-capaciteit en de geconfigureerde maximale heaplimiet.
- Netwerk ontvangen en verzonden: het aantal ontvangen en verzonden bytes via het netwerk door elk apparaat.
- Vrije bestandssysteemruimte: het totale gebruik van het bestandssysteem per koppelpunt, gemeten in bytes.
Klik op Knooppuntgeheugengebruik onder aan het tabblad Hardware om de volgende extra grafiek uit te vouwen:
-
Geheugengebruik en wissel: In de lijngrafiek ziet u het totale gebruik van geheugenwisseling per modus, gemeten in bytes. In het staafdiagram ziet u het totale geheugengebruik per modus, ook gemeten in bytes. De volgende gebruikstypen worden bijgehouden:
-
used: Totaal geheugen op besturingssysteemniveau dat wordt gebruikt, inclusief geheugen dat wordt gebruikt door achtergrondprocessen die worden uitgevoerd op een rekenproces. Omdat het stuurprogramma en de achtergrondprocessen geheugen gebruiken, kan het gebruik nog steeds worden weergegeven, zelfs wanneer er geen Spark-taken worden uitgevoerd. -
other: Geheugen in gebruik voor andere doeleinden danused,bufferofcached -
buffer: Geheugen gebruikt door kernelbuffers -
cached: Geheugen dat wordt gebruikt door de cache van het bestandssysteem op het niveau van het besturingssysteem -
free: Ongebruikt geheugen. Alles wat niet is toegeschreven aan een van de bovenstaande categorieën in de grafiek, is gratis.
-
Grafieken met metrische Spark-gegevens
De volgende grafieken met metrische Spark-gegevens zijn beschikbaar om weer te geven in de gebruikersinterface voor metrische rekengegevens:
- Distributie van serverbelasting: deze tegels tonen het CPU-gebruik in de afgelopen minuut voor elk knooppunt in de rekenresource. Elke tegel is een klikbare koppeling naar de pagina met metrische gegevens van het afzonderlijke knooppunt.
- Actieve taken: het totale aantal taken dat op een bepaald moment wordt uitgevoerd.
- Totaal aantal mislukte taken: het totale aantal taken dat is mislukt in uitvoerders.
- Totaal voltooide taken: het totale aantal taken dat is voltooid door uitvoerend componenten.
- Totaal aantal taken: het totale aantal taken (uitvoeren, mislukt en voltooid) in uitvoerders.
-
Totaal aantal leesbewerkingen in willekeurige volgorde: de totale grootte van leesgegevens in willekeurige volgorde, gemeten in bytes.
Shuffle readbetekent de som van geserialiseerde uitleesgegevens op alle executors aan het begin van een fase. -
Totale shuffle-schrijf bewerking: De totale grootte van shuffle-schrijfgegevens, gemeten in bytes.
Shuffle Writeis de som van alle geschreven geserialiseerde gegevens door alle uitvoerders voordat ze worden verzonden (meestal aan het einde van een fase). - Totale duur van de taak: de totale verstreken tijd die de JVM heeft besteed aan het uitvoeren van taken op uitvoerders, gemeten in seconden.
Metrische GPU-grafieken
Notitie
GPU-metrische gegevens zijn alleen beschikbaar op Databricks Runtime ML 13.3 en hoger.
De volgende metrische GPU-grafieken zijn beschikbaar om weer te geven in de gebruikersinterface voor metrische rekengegevens:
- Distributie van serverbelasting: in deze grafiek ziet u het CPU-gebruik in de afgelopen minuut voor elk knooppunt.
- Per-GPU decoder gebruik: Het percentage van GPU decodergebruik.
- Per-GPU encodergebruik: het percentage van de GPU-encoderbenutting.
- Geheugengebruik in bytes per-GPU voor de framebuffer: het geheugengebruik van de framebuffer, uitgedrukt in bytes.
- Per-GPU geheugengebruik: het percentage GPU-geheugengebruik.
- Per-GPU gebruik: het percentage GPU-gebruik.
Probleemoplossing
Als u onvolledige of ontbrekende metrische gegevens voor een periode ziet, kan dit een van de volgende problemen zijn:
- Een storing in de Databricks-service die verantwoordelijk is voor het opvragen en opslaan van metrische gegevens.
- Netwerkproblemen aan de kant van de klant.
- De computer is of was in een ongezonde toestand.