Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Belangrijk
Deze functie is beschikbaar als openbare preview. Zie Serverloze rekenkracht inschakelen voor informatie over geschiktheid en inschakeling.
In dit artikel wordt uitgelegd hoe u serverloze berekeningen gebruikt voor notebooks. Zie Uw Azure Databricks-taak uitvoeren met serverloze berekeningen voor werkstromen voor informatie over het gebruik van serverloze berekeningen voor werkstromen.
Zie De prijzen van Databricks voor informatie over prijzen.
Vereisten
Uw werkruimte moet zijn ingeschakeld voor Unity Catalog.
Uw werkruimte moet zich in een ondersteunde regio bevinden. Zie Azure Databricks-regio's.
Uw account moet zijn ingeschakeld voor serverloze berekeningen. Zie Serverloze berekening inschakelen.
Een notebook koppelen aan serverloze berekeningen
Als uw werkruimte is ingeschakeld voor serverloze interactieve berekeningen, hebben alle gebruikers in de werkruimte toegang tot serverloze berekeningen voor notebooks. Er zijn geen extra machtigingen vereist.
Als u verbinding wilt maken met de serverloze berekening, klikt u op de vervolgkeuzelijst Verbinding maken in het notitieblok en selecteert u Serverloos. Voor nieuwe notebooks wordt de gekoppelde rekenkracht automatisch automatisch op serverloos ingesteld bij het uitvoeren van code als er geen andere resource is geselecteerd.
Notebookafhankelijkheden installeren
U kunt Python-afhankelijkheden voor serverloze notebooks installeren met behulp van het deelvenster Omgeving , dat één plek biedt voor het bewerken, weergeven en exporteren van de bibliotheekvereisten voor een notebook. Deze afhankelijkheden kunnen worden toegevoegd met behulp van een basisomgeving of afzonderlijk.
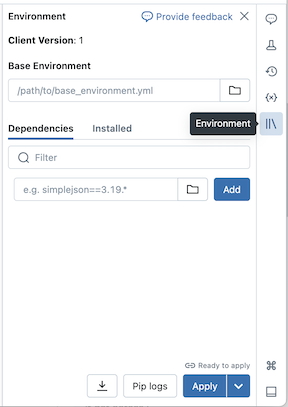
Een basisomgeving configureren
Een basisomgeving is een YAML-bestand dat is opgeslagen als een werkruimtebestand of op een Unity Catalog-volume dat aanvullende omgevingsafhankelijkheden aangeeft. Basisomgevingen kunnen worden gedeeld tussen notebooks. Een basisomgeving configureren:
Maak een YAML-bestand dat instellingen definieert voor een virtuele Python-omgeving. Het volgende voorbeeld van YAML, dat is gebaseerd op de omgevingsspecificatie van MLflow-projecten, definieert een basisomgeving met enkele bibliotheekafhankelijkheden:
client: "1" dependencies: - --index-url https://pypi.org/simple - -r "/Workspace/Shared/requirements.txt" - cowsay==6.1Upload het YAML-bestand als een werkruimtebestand of naar een Unity Catalog-volume. Zie Een bestand importeren of bestanden uploaden naar een Unity Catalog-volume.
Klik rechts van het notitieblok op de
 knop om het deelvenster Omgeving uit te vouwen. Deze knop wordt alleen weergegeven wanneer een notebook is verbonden met serverloze berekeningen.
knop om het deelvenster Omgeving uit te vouwen. Deze knop wordt alleen weergegeven wanneer een notebook is verbonden met serverloze berekeningen.Voer in het veld Basisomgeving het pad van het geüploade YAML-bestand in of navigeer ernaartoe en selecteer het.
Klik op Toepassen. Hiermee worden de afhankelijkheden in de virtuele notebookomgeving geïnstalleerd en wordt het Python-proces opnieuw gestart.
Gebruikers kunnen de afhankelijkheden die zijn opgegeven in de basisomgeving overschrijven door afhankelijkheden afzonderlijk te installeren.
Afhankelijkheden afzonderlijk toevoegen
U kunt ook afhankelijkheden installeren op een notebook dat is verbonden met serverloze berekeningen met behulp van het tabblad Afhankelijkheden van het deelvenster Omgeving :
- Klik rechts van het notitieblok op de knop om het deelvenster Omgeving uit te vouwen. Deze knop wordt alleen weergegeven wanneer een notebook is verbonden met serverloze berekeningen.
- Klik in de sectie Afhankelijkheden op Afhankelijkheid toevoegen en voer het pad in van de bibliotheekafhankelijkheid in het veld. U kunt een afhankelijkheid opgeven in elke indeling die geldig is in een requirements.txt-bestand .
- Klik op Toepassen. Hiermee worden de afhankelijkheden in de virtuele notebookomgeving geïnstalleerd en wordt het Python-proces opnieuw gestart.
Notitie
Een taak die gebruikmaakt van serverloze rekenkracht installeert de omgevingsspecificatie van het notebook voordat de notebookcode wordt uitgevoerd. Dit betekent dat u geen afhankelijkheden hoeft toe te voegen wanneer u notebooks als taken plant. Zie Notebook-omgevingen en afhankelijkheden configureren.
Geïnstalleerde afhankelijkheden en pip-logboeken weergeven
Als u geïnstalleerde afhankelijkheden wilt weergeven, klikt u op Geïnstalleerd in het deelvenster Omgevingen voor een notebook. Pip-installatielogboeken voor de notebookomgeving zijn ook beschikbaar door onderaan het deelvenster op Pip-logboeken te klikken.
De omgeving opnieuw instellen
Als uw notebook is verbonden met serverloze berekeningen, slaat Databricks automatisch de inhoud van de virtuele omgeving van het notebook in de cache op. Dit betekent dat u in het algemeen de Python-afhankelijkheden die zijn opgegeven in het deelvenster Omgeving niet opnieuw hoeft te installeren wanneer u een bestaand notebook opent, zelfs niet als de verbinding is verbroken vanwege inactiviteit.
Het opslaan van virtuele Python-omgevingen is ook van toepassing op taken. Dit betekent dat volgende uitvoeringen van taken sneller zijn, omdat vereiste afhankelijkheden al beschikbaar zijn.
Notitie
Als u de implementatie wijzigt van een aangepast Python-pakket dat wordt gebruikt in een taak zonder server, moet u ook het versienummer bijwerken voor taken om de meest recente implementatie op te halen.
Als u de omgevingscache wilt wissen en een nieuwe installatie wilt uitvoeren van de afhankelijkheden die zijn opgegeven in het deelvenster Omgeving van een notebook dat is gekoppeld aan serverloze berekening, klikt u op de pijl naast Toepassen en klikt u vervolgens op Omgeving opnieuw instellen.
Notitie
Stel de virtuele omgeving opnieuw in als u pakketten installeert die het kernnotitieblok of de Apache Spark-omgeving verbreken of wijzigen. Als u het notebook loskoppelt van serverloze rekenkracht en opnieuw koppelt, wordt de volledige omgevingscache niet per se gewist.
Queryinzichten weergeven
Serverloze rekenkracht voor notebooks en werkstromen maakt gebruik van query-inzichten om de prestaties van spark-uitvoering te beoordelen. Nadat u een cel in een notebook hebt uitgevoerd, kunt u inzichten weergeven die betrekking hebben op SQL- en Python-query's door te klikken op de koppeling Prestatie weergeven.
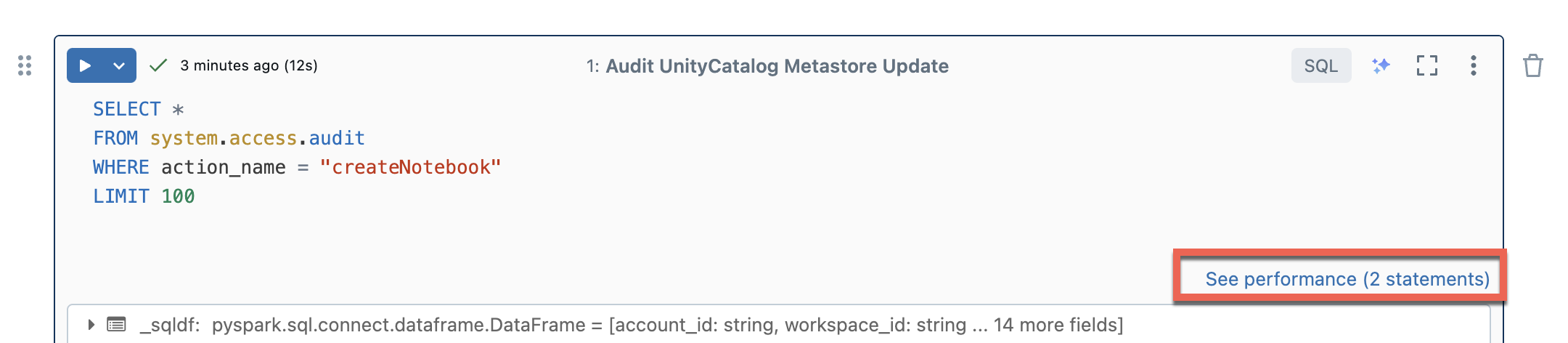
U kunt op een van de Spark-instructies klikken om de metrische querygegevens weer te geven. Hier kunt u op Queryprofiel weergeven klikken om een visualisatie van de queryuitvoering te bekijken. Zie Queryprofiel voor meer informatie over queryprofielen.
Notitie
Als u prestatie-inzichten voor uw taakuitvoeringen wilt weergeven, raadpleegt u Query-inzichten voor taakuitvoeringen weergeven.
Querygeschiedenis
Alle query's die worden uitgevoerd op serverloze berekeningen, worden ook vastgelegd op de pagina querygeschiedenis van uw werkruimte. Zie Querygeschiedenis voor meer informatie over de querygeschiedenis.
Beperkingen voor query-inzicht
- Het queryprofiel is alleen beschikbaar nadat de uitvoering van de query is beëindigd.
- Metrische gegevens worden live bijgewerkt, hoewel het queryprofiel niet wordt weergegeven tijdens de uitvoering.
- Alleen de volgende querystatussen worden behandeld: ACTIEF, GEANNULEERD, MISLUKT, VOLTOOID.
- Het uitvoeren van query's kan niet worden geannuleerd vanaf de pagina querygeschiedenis. Ze kunnen worden geannuleerd in notebooks of taken.
- Uitgebreide metrische gegevens zijn niet beschikbaar.
- Downloaden van queryprofiel is niet beschikbaar.
- Toegang tot de Spark-gebruikersinterface is niet beschikbaar.
- De instructietekst bevat alleen de laatste regel die is uitgevoerd. Er kunnen echter meerdere regels vóór deze regel staan die zijn uitgevoerd als onderdeel van dezelfde instructie.
Beperkingen
Zie Serverloze rekenbeperkingen voor een lijst met beperkingen.