Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
U kunt gedistribueerde werkbelasting starten over meerdere GPU's ( binnen één knooppunt of op meerdere knooppunten), met behulp van de Serverloze GPU Python-API. De API biedt een eenvoudige, geïntegreerde interface waarmee de details van GPU-inrichting, omgevingsinstallatie en workloaddistributie worden weggenomen. Met minimale codewijzigingen kunt u naadloos overstappen van training met één GPU naar gedistribueerde uitvoering via externe GPU's vanuit hetzelfde notebook.
Snel aan de slag
De serverloze GPU-API voor gedistribueerde training is vooraf geïnstalleerd in serverloze GPU-rekenomgevingen voor Databricks-notebooks. We raden GPU-omgeving 4 en hoger aan. Als u deze wilt gebruiken voor gedistribueerde training, importeert en gebruikt u de distributed decorator om uw trainingsfunctie te distribueren.
In het onderstaande codefragment ziet u het basisgebruik van @distributed:
# Import the distributed decorator
from serverless_gpu import distributed
# Decorate your training function with @distributed and specify the number of GPUs, the GPU type,
# and whether or not the GPUs are remote
@distributed(gpus=8, gpu_type='A10', remote=True)
def run_train():
...
Hieronder ziet u een volledig voorbeeld dat een MLP-model (multilayer perceptron) traint op 8 A10 GPU-knooppunten vanuit een notebook:
Stel uw model in en definieer hulpprogrammafuncties.
# Define the model import os import torch import torch.distributed as dist import torch.nn as nn def setup(): dist.init_process_group("nccl") torch.cuda.set_device(int(os.environ["LOCAL_RANK"])) def cleanup(): dist.destroy_process_group() class SimpleMLP(nn.Module): def __init__(self, input_dim=10, hidden_dim=64, output_dim=1): super().__init__() self.net = nn.Sequential( nn.Linear(input_dim, hidden_dim), nn.ReLU(), nn.Dropout(0.2), nn.Linear(hidden_dim, hidden_dim), nn.ReLU(), nn.Dropout(0.2), nn.Linear(hidden_dim, output_dim) ) def forward(self, x): return self.net(x)Importeer de serverless_gpu-bibliotheek en de gedistribueerde module.
import serverless_gpu from serverless_gpu import distributedVerpakt de modeltrainingscode in een functie en verfraaid de functie met de
@distributeddecorator.@distributed(gpus=8, gpu_type='A10', remote=True) def run_train(num_epochs: int, batch_size: int) -> None: import mlflow import torch.optim as optim from torch.nn.parallel import DistributedDataParallel as DDP from torch.utils.data import DataLoader, DistributedSampler, TensorDataset # 1. Set up multi node environment setup() device = torch.device(f"cuda:{int(os.environ['LOCAL_RANK'])}") # 2. Apply the Torch distributed data parallel (DDP) library for data-parellel training. model = SimpleMLP().to(device) model = DDP(model, device_ids=[device]) # 3. Create and load dataset. x = torch.randn(5000, 10) y = torch.randn(5000, 1) dataset = TensorDataset(x, y) sampler = DistributedSampler(dataset) dataloader = DataLoader(dataset, sampler=sampler, batch_size=batch_size) # 4. Define the training loop. optimizer = optim.Adam(model.parameters(), lr=0.001) loss_fn = nn.MSELoss() for epoch in range(num_epochs): sampler.set_epoch(epoch) model.train() total_loss = 0.0 for step, (xb, yb) in enumerate(dataloader): xb, yb = xb.to(device), yb.to(device) optimizer.zero_grad() loss = loss_fn(model(xb), yb) # Log loss to MLflow metric mlflow.log_metric("loss", loss.item(), step=step) loss.backward() optimizer.step() total_loss += loss.item() * xb.size(0) mlflow.log_metric("total_loss", total_loss) print(f"Total loss for epoch {epoch}: {total_loss}") cleanup()Voer de gedistribueerde training uit door de gedistribueerde functie aan te roepen met door de gebruiker gedefinieerde argumenten.
run_train.distributed(num_epochs=3, batch_size=1)Wanneer deze wordt uitgevoerd, wordt er een MLflow-uitvoeringskoppeling gegenereerd in de uitvoer van de notebookcel. Klik op de koppeling voor de MLflow-uitvoering of zoek deze in het deelvenster Experiment om de uitvoeringsresultaten te bekijken.
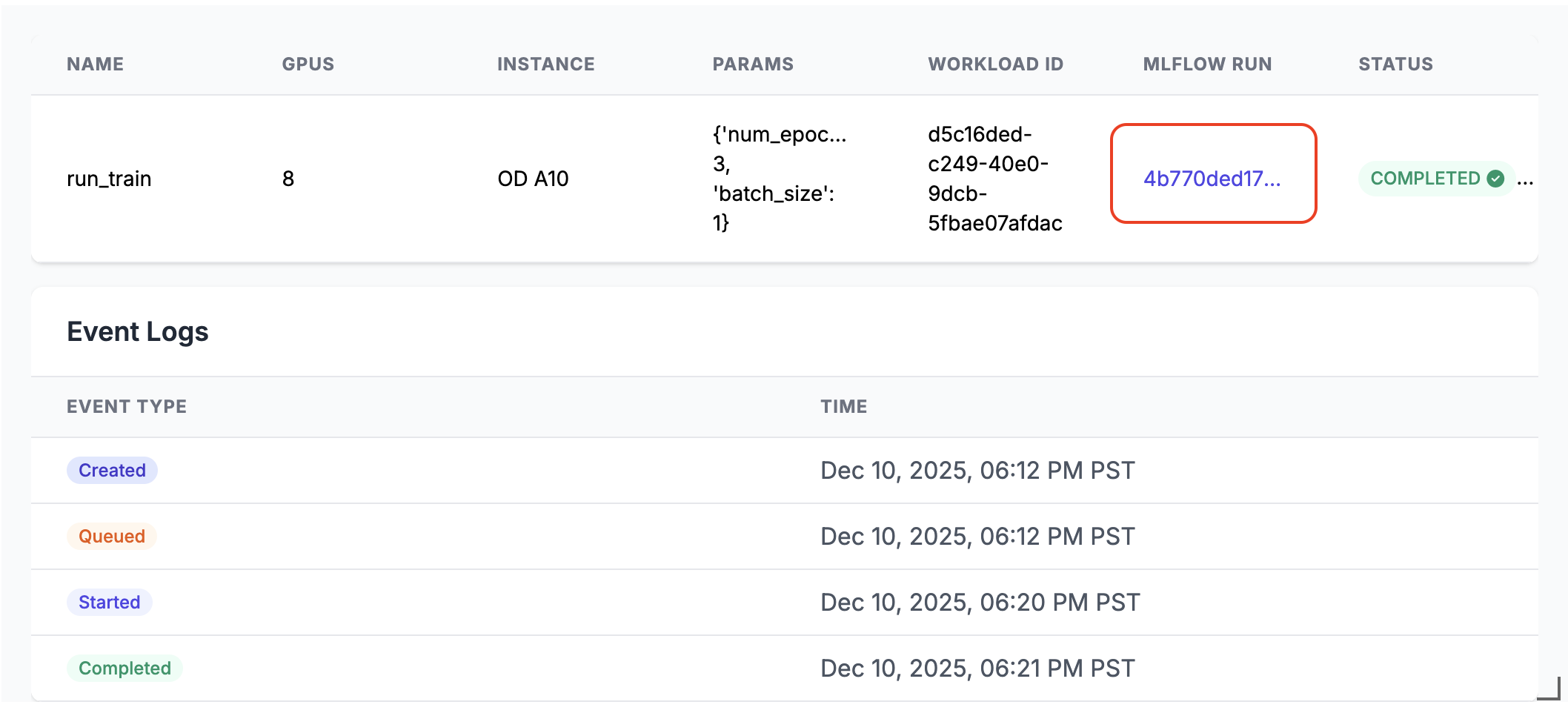
Details van gedistribueerde uitvoering
Serverloze GPU-API bestaat uit verschillende belangrijke onderdelen:
- Compute Manager: verwerkt resourcetoewijzing en -beheer
- Runtime-omgeving: Beheert Python-omgevingen en -afhankelijkheden
- Startprogramma: uitvoering en bewaking van taken organiseren
Wanneer deze wordt uitgevoerd in de gedistribueerde modus:
- De functie wordt geserialiseerd en verdeeld over het opgegeven aantal GPU's
- Elke GPU voert een kopie van de functie uit met dezelfde parameters
- De omgeving wordt gesynchroniseerd op alle knooppunten
- Resultaten worden verzameld en geretourneerd door alle GPU's
Als remote op True is ingesteld, wordt de workload op de externe GPU's verdeeld. Als remote is ingesteld op False, wordt de workload uitgevoerd op het GPU-knooppunt dat is verbonden met het huidige notebook. Als het knooppunt meerdere GPU-chips heeft, worden ze allemaal gebruikt.
De API ondersteunt populaire parallelle trainingsbibliotheken zoals Distributed Data Parallel (DDP), Fully Sharded Data Parallel (FSDP), DeepSpeed en Ray.
U vindt meer echte gedistribueerde trainingsscenario's met behulp van de verschillende bibliotheken in notebookvoorbeelden.
Starten met Ray
De serverloze GPU-API biedt ook ondersteuning voor het starten van gedistribueerde training met behulp van Ray, waarbij gebruik wordt gemaakt van de @ray_launch decorator, die boven op @distributed is gelaagd.
Elke ray_launch taak bootstrapt eerst een torch-gedistribueerde rendezvous om de Ray-hoofdwerker te bepalen en IP-adressen te verzamelen. Rang-nul start ray start --head (met de export van metrische gegevens indien ingeschakeld), stelt RAY_ADDRESS in en voert je gedecoreerde functie uit als de Ray-driver. Andere knooppunten worden samengevoegd via ray start --address en wachten totdat het stuurprogramma een voltooiingsmarkering schrijft.
Aanvullende configuratiedetails:
- Als u het verzamelen van metrische gegevens van het Ray-systeem op elk knooppunt wilt inschakelen, gebruikt u
RayMetricsMonitormetremote=True. - Definieer Ray-runtime-opties (actors, datasets, plaatsingsgroepen en planning) binnen uw gedecoreerde functie met standaard Ray-API's.
- Beheer clusterbrede besturingselementen (GPU-aantal en type, externe versus lokale modus, asynchroon gedrag en Databricks-poolomgevingsvariabelen) buiten de functie in de decoratorargumenten of notebookomgeving.
In het onderstaande voorbeeld ziet u hoe u @ray_launch gebruikt:
from serverless_gpu.ray import ray_launch
@ray_launch(gpus=16, remote=True, gpu_type='A10')
def foo():
import os
import ray
print(ray.state.available_resources_per_node())
return 1
foo.distributed()
Zie dit notebook voor een volledig voorbeeld, waarmee Ray een Resnet18-neuraal netwerk traint op meerdere A10 GPU's.
U kunt deze API ook gebruiken om Ray Data, een schaalbare gegevensverwerkingsbibliotheek voor AI-workloads, aan te roepen om gedistribueerde batchdeductie uit te voeren op LLM's. Zie voorbeelden van vllm en sglang .
FAQs
Waar moet de code voor het laden van gegevens worden geplaatst?
Wanneer u de serverloze GPU-API gebruikt voor gedistribueerde training, verplaatst u de code voor het laden van gegevens binnen de @distributed decorator. De datasetgrootte kan groter zijn dan de maximale grootte die is toegestaan door de module pickle, dus het wordt aanbevolen om de dataset in de decorator te genereren, zoals hieronder getoond.
from serverless_gpu import distributed
# this may cause pickle error
dataset = get_dataset(file_path)
@distributed(gpus=8, remote=True)
def run_train():
# good practice
dataset = get_dataset(file_path)
....
Kan ik gereserveerde GPU-pools gebruiken?
Als de gereserveerde GPU-pool beschikbaar is (controleer dit bij uw beheerder) in uw werkruimte en u opgeeft remote in True de @distributed-decorator, wordt de workload standaard gestart op de gereserveerde GPU-pool. Als u de GPU-pool op aanvraag wilt gebruiken, stelt u de omgevingsvariabele DATABRICKS_USE_RESERVED_GPU_POOLFalse in op voordat u de gedistribueerde functie aanroept, zoals hieronder wordt weergegeven:
import os
os.environ['DATABRICKS_USE_RESERVED_GPU_POOL'] = 'False'
@distributed(gpus=8, remote=True)
def run_train():
...
Meer informatie
Raadpleeg de documentatie van de Serverloze GPU Python-API voor de API-referentie.