Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Schemaontwikkeling verwijst naar de mogelijkheid van een systeem om zich aan te passen aan wijzigingen in de structuur van gegevens in de loop van de tijd. Deze wijzigingen zijn gebruikelijk bij het werken met semi-gestructureerde gegevens, gebeurtenisstromen of bronnen van derden waar nieuwe velden worden toegevoegd, gegevenstypen worden verplaatst of geneste structuren zich ontwikkelen.
Veelvoorkomende wijzigingen zijn:
- Nieuwe kolommen: Aanvullende velden die niet eerder zijn gedefinieerd, soms met een aangepaste backfillwaarde.
-
Kolomnaam wijzigen: een kolomnaam wijzigen, bijvoorbeeld van
namenaarfull_name. - Verwijderde kolommen: Kolommen verwijderen uit het tabelschema.
-
Type breder maken: het type van een kolom wijzigen in een breder type. Een bijvoorbeeld
INTveld wordtDOUBLE. -
Andere typewijzigingen: het type van een kolom wijzigen. Een bijvoorbeeld
INTveld wordtSTRING.
Het ondersteunen van de ontwikkeling van schema's is essentieel voor het bouwen van robuuste, langlopende pijplijnen die geschikt zijn voor het wijzigen van gegevens zonder regelmatige handmatige updates.
Components
De ontwikkeling van azure Databricks-schema's omvat vier hoofdonderdeelcategorieën, waarbij schemawijzigingen onafhankelijk worden verwerkt:
- Connectors: onderdelen die gegevens uit externe bronnen opnemen. Dit zijn onder andere Auto Loader, Kafka-, Kinesis- en Lakeflow-connectors.
-
Formaatparsers: Functies die onbewerkte indelingen decoderen, waaronder
from_json,from_avro,from_xml, enfrom_protobuf. - Engines: Verwerkingsengines die query's uitvoeren, waaronder Structured Streaming.
- Gegevenssets: Streamingtabellen, gematerialiseerde weergaven, Delta-tabellen en weergaven die gegevens opslaan en verwerken.
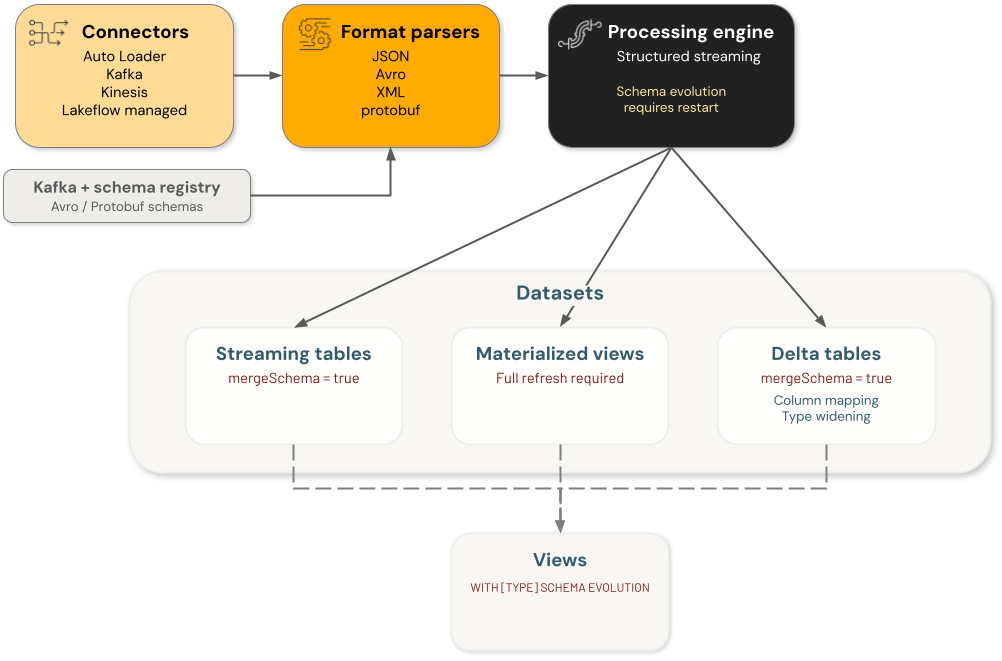
Elk onderdeel in de ontwikkeling van het schema van de data engineering-architectuur is onafhankelijk. U bent verantwoordelijk voor het configureren van de ontwikkeling van schema's in afzonderlijke onderdelen om het gewenste gedrag in uw gegevensverwerkingsstroom te bereiken.
Wanneer u bijvoorbeeld automatisch laden gebruikt om gegevens op te nemen in een Delta-tabel, zijn er twee persistente schema's: een wordt beheerd door Auto Loader op de schemalocatie en de andere is het schema van de delta-doeltabel. In een stabiele toestand zijn die twee hetzelfde. Wanneer automatisch laadprogramma het schema ontwikkelt, op basis van binnenkomende gegevens, moet de Delta-tabel ook het schema ontwikkelen of mislukt de query. In dat geval kunt u (a) het schema van de delta-doeltabel bijwerken door schemaontwikkeling in te schakelen of door een directe DDL-opdracht te gebruiken, of (b) de doel-Delta-tabel volledig herschrijven.
Ondersteuning voor schemaontwikkeling per connector
In de volgende secties wordt beschreven hoe elk Azure Databricks-onderdeel verschillende typen schemawijzigingen verwerkt.
Automatische lader
AutoLoader ondersteunt kolomwijzigingen en typebreiding. Configureer automatische ontwikkeling van schema's met cloudFiles.schemaEvolutionMode en rescuedDataColumn. U kunt handmatig schemaHints instellen of een onveranderbare schema instellen. Bij het automatisch ontwikkelen van het schema mislukt de stream in eerste instantie. Bij het opnieuw opstarten wordt het ontwikkelde schema gebruikt. Zie Hoe werkt de evolutie van het Auto Loader-schema?
-
Nieuwe kolommen: Ondersteund, afhankelijk van de
schemaEvolutionModegeselecteerde. Mislukt met handmatig opnieuw opstarten vereist om nieuwe kolommen toe te voegen aan het schema. -
Kolomnaam wijzigen: Ondersteund, afhankelijk van de
schemaEvolutionModegeselecteerde. De hernoemde kolom wordt behandeld als een nieuwe kolom die is toegevoegd, en de oude kolom wordt gevuld metNULLvoor nieuwe rijen. Er is een fout opgetreden en een handmatige herstart is vereist om het schema bij te werken. -
Verwijderde kolommen: ondersteund. Behandeld als 'soft deletes', waarbij voor de verwijderde kolom nieuwe rijen worden ingesteld op
NULL. -
Type widening: ondersteund in Databricks Runtime 16.4 en hoger met
schemaEvolutionModeingesteld opaddNewColumnsWithTypeWidening. Ondersteunde wijzigingen in gegevenstypen worden automatisch uitgebreid. Niet-ondersteunde typewijzigingen worden vastgelegd in derescuedDataColumn. Zie Automatische typeverbreding met Auto Loader. -
Andere typewijzigingen: niet ondersteund. Typewijzigingen worden vastgelegd in de
rescuedDataColumnalsrescueDataColumnis ingesteld enschemaEvolutionModeis ingesteld oprescue. Anders is een handmatige schemawijziging vereist.
Deltaconnector
De Delta-connector kan de ontwikkeling van schema's ondersteunen. Als het lezen vanuit een Delta-tabel met kolomtoewijzing en schemaTrackingLocation is ingeschakeld, ondersteunt deze de ontwikkeling van schema's voor kolomhernoeming en verwijderde kolommen. U moet de juiste Spark-configuratie instellen voor elk van deze respectieve wijzigingen om het schema te ontwikkelen zonder de stream te stoppen. Anders evolveert de stroom zijn bijgehouden schema wanneer er een wijziging wordt gedetecteerd en stopt vervolgens. Vervolgens moet u de streamingquery handmatig opnieuw starten om de verwerking te hervatten.
-
Nieuwe kolommen: ondersteund. Als
mergeSchemadeze optie is ingeschakeld, worden nieuwe kolommen automatisch toegevoegd. Anders mislukt de query en moet u de stream opnieuw starten om de nieuwe kolommen toe te voegen aan het schema, maar de Delta-tabel vereist geen herschrijfbewerking. -
Kolomnaam wijzigen: ondersteund. Wanneer
mergeSchemais ingeschakeld, wordt het hernoemen automatisch afgehandeld. Anders kunt u een schema ontwikkelen binnen een streamingquery met de Spark-configuratiespark.databricks.delta.streaming.allowSourceColumnRename. -
Verwijderde kolommen: ondersteund. Als
mergeSchemadeze optie is ingeschakeld, worden verwijderde kolommen automatisch verwerkt. Anders kunt u een schema ontwikkelen binnen een streamingquery met de Spark-configuratiespark.databricks.delta.streaming.allowSourceColumnDrop. -
Type widening: ondersteund in Databricks Runtime 16.4 LTS en hoger. Met
mergeSchemaingeschakeld en typeverbreding ingeschakeld op de doeltabel, worden typewijzigingen automatisch verwerkt. U kunt type widening inschakelen met de tabeleigenschaptype widening. - Andere typewijzigingen: niet ondersteund.
SaaS- en CDC-connectors
De SaaS- en CDC-connectors ontwikkelen het schema automatisch wanneer kolommen worden gewijzigd. Dit wordt afgehandeld via een automatische herstart wanneer een wijziging wordt gedetecteerd. Voor typewijzigingen is een volledige vernieuwing vereist.
- Nieuwe kolommen: ondersteund. De query wordt automatisch opnieuw opgestart om schemaovereenkomsten op te lossen.
- Kolomnaam wijzigen: ondersteund. De query wordt automatisch opnieuw opgestart om schemaovereenkomsten op te lossen. De hernoemde kolom wordt behandeld als een nieuwe kolom toegevoegd.
-
Verwijderde kolommen: ondersteund. Verwijderde kolommen worden behandeld als soft deletes, waarbij voor nieuwe rijen de verwijderde kolom is ingesteld op
NULL. - Type breder maken: niet ondersteund. Voor het bijwerken van het schema is een volledige vernieuwing vereist.
- Andere typewijzigingen: niet ondersteund. Voor het bijwerken van het schema is een volledige vernieuwing vereist.
Kinesis, Kafka, Pub/Sub en Pulsar connectors
Er wordt geen systeemeigen schemaontwikkeling ondersteund. Elk van de connectorfuncties retourneert een binaire blob. Schema-evolutie wordt verwerkt door de formaatparser.
- Nieuwe kolommen: verwerkt door de opmaakparser.
- Kolomnaam wijzigen: verwerkt door de notatieparser.
- Verwijderde kolommen: verwerkt door de opmaakparser.
- Type widening: Verwerkt door de formaatparser.
- Andere typewijzigingen: verwerkt door de notatieparser.
Ondersteuning voor schemaontwikkeling door opmaakparser
from_json Parser
De from_json parser biedt geen ondersteuning voor de ontwikkeling van schema's. U moet het schema handmatig bijwerken. Wanneer u declaratieve pijplijnen van Lakeflow Spark gebruikt from_json , kan automatische schemaontwikkeling worden ingeschakeld met schemaLocationKey en schemaEvolutionMode.
- Nieuwe kolommen: wanneer automatische schemaontwikkeling is ingeschakeld, gedraagt het zich als Automatisch laden.
- Kolomhernoeming: wanneer automatische schemaontwikkeling is ingeschakeld, gedraagt het zich als Auto Loader.
- Verwijderde kolommen: wanneer automatische schema-evolutie is ingeschakeld, gedraagt het zich als Auto Loader.
- Type widening: Wanneer automatische schemaontwikkeling is ingeschakeld, gedraagt het zich als Auto Loader.
- Andere typewijzigingen: wanneer automatische schemaontwikkeling is ingeschakeld, gedraagt het zich als Automatisch laden.
from_avro en from_protobuf parsers
De from_avro en from_protobuf parsers gedragen zich op dezelfde manier. Het schema kan worden opgehaald uit het Confluent-schemaregister of de gebruiker kan een schema opgeven en moet het schema handmatig bijwerken. Er is geen concept van schemaontwikkeling binnen de from_avro of from_protobuf functie; deze moet worden verwerkt door de uitvoeringsengine en het schemaregister.
- Nieuwe kolommen: Ondersteund met Confluent Schema Registry. Anders moet de gebruiker het schema handmatig bijwerken.
- Kolomnaam wijzigen: ondersteund met Confluent Schema Registry. Anders moet de gebruiker het schema handmatig bijwerken.
- Verwijderde kolommen: ondersteund met Confluent Schema Registry. Anders moet de gebruiker het schema handmatig bijwerken.
- Type widening: ondersteund met Confluent Schema Registry. Anders moet de gebruiker het schema handmatig bijwerken.
- Andere typewijzigingen: ondersteund met Confluent Schema Registry. Anders moet de gebruiker het schema handmatig bijwerken.
from_csv en from_xml parsers
De from_csv en from_xml parsers bieden geen ondersteuning voor schema-evolutie.
- Nieuwe kolommen: niet ondersteund
- Kolomnaam wijzigen: niet ondersteund
- Verwijderde kolommen: niet ondersteund
- Type breder maken: niet ondersteund
- Andere typewijzigingen: niet ondersteund
Ondersteuning voor schemaontwikkeling per engine
Gestructureerd streamen
Het schema van een streamingquery is vergrendeld tijdens de planningsfase en alle microbatches hergebruiken dat plan zonder opnieuw te plannen. Als het bronschema halverwege de uitvoering verandert, mislukt de query en moet de gebruiker de streamingquery opnieuw starten, zodat Spark het nieuwe schema opnieuw kan plannen.
De gegevensset waarnaar de stroom schrijft, moet ook ondersteuning bieden voor de ontwikkeling van schema's.
- Nieuwe kolommen: ondersteund. De query mislukt en u moet de stream opnieuw starten om het schema-mismatch op te lossen.
- Kolomnaam wijzigen: ondersteund. De query mislukt en u moet de stream opnieuw starten om het schema-mismatch op te lossen.
- Verwijderde kolommen: ondersteund. De query mislukt en u moet de stream opnieuw starten om het schema-mismatch op te lossen.
- Type breder maken: ondersteund. De query mislukt en u moet de stream opnieuw starten om het schema-mismatch op te lossen.
- Andere typewijzigingen: ondersteund. De query mislukt en u moet de stream opnieuw starten om het schema-mismatch op te lossen.
Ontwikkeling van schema's per gegevensset
Streamingtabellen
Streamingtabellen ondersteunen standaard samenvoegschema-evolutie gedrag. Het bijwerken van het schema vereist geen handmatig opnieuw opstarten, maar willekeurige schemawijzigingen vereisen een volledige vernieuwing.
- Nieuwe kolommen: ondersteund. De query wordt automatisch opnieuw opgestart om de schema mismatch op te lossen.
- Kolomnaam wijzigen: ondersteund. De query wordt opnieuw opgestart om de schemascheefstand op te lossen. De hernoemde kolom wordt behandeld als een nieuwe kolom toegevoegd.
- Verwijderde kolommen: ondersteund. Verwijderde kolommen worden behandeld als zachte verwijdering, waarbij nieuwe rijen in de verwijderde kolom worden ingesteld op NULL.
- Type breder maken: ondersteund. Typebreiding moet worden ingeschakeld op het niveau van de pipeline of direct op de tabel. Zie type-verbredding in Lakeflow Spark Declarative Pipelines.
- Andere typewijzigingen: niet ondersteund. Voor het bijwerken van het schema is een volledige vernieuwing vereist.
Gematerealiseerde weergaven
Elke update van het schema of de definitiequery activeert een volledige hercomputing van de gerealiseerde weergave.
- Nieuwe kolommen: Volledig opnieuw compileren geactiveerd.
- Kolom hernoemen: volledige herberekening geactiveerd.
- Verwijderde kolommen: volledig opnieuw compileren geactiveerd.
- Type-verbreding: Volledige herberekening geactiveerd.
- Andere typewijzigingen: volledig opnieuw compileren geactiveerd.
Delta-tabellen
Delta-tabellen ondersteunen verschillende configuraties om het tabelschema bij te werken, waaronder het wijzigen van de naam, het verwijderen en breder maken van het type kolommen zonder tabelgegevens opnieuw te schrijven. Ondersteunde configuraties zijn onder andere ontwikkeling van samenvoegschema's, kolomtoewijzing, type widening en overwriteSchema.
- Nieuwe kolommen: ondersteund. Wordt automatisch ontwikkeld wanneer de ontwikkeling van het samenvoegschema is ingeschakeld, zonder dat een Delta-tabel opnieuw hoeft te worden geschreven. Als de ontwikkeling van het samenvoegschema niet is ingeschakeld, mislukken updates.
-
Kolomnaam wijzigen: ondersteund. Kan de naam wijzigen via handmatige
ALTER TABLE DDLopdrachten waarvoor kolomtoewijzing is ingeschakeld. Er is geen herschrijf van een Delta-tabel vereist. -
Verwijderde kolommen: ondersteund. Je kunt kolommen verwijderen via manuele
ALTER TABLE DDLopdrachten met ingeschakelde kolomtoewijzing. Er is geen herschrijf van een Delta-tabel vereist. -
Type breder maken: ondersteund. De typewijziging wordt automatisch toegepast wanneer typevergroting en schema-evolutie voor samenvoegen zijn ingeschakeld. U kunt kolommen breder maken via handmatige
ALTER TABLE DDLopdrachten wanneer het type widening is ingeschakeld. Als geen van beide is geconfigureerd, mislukken de bewerkingen. Zie Widen-typen met automatische schemaontwikkeling. -
Andere typewijzigingen: ondersteund, maar vereist een volledig herschrijven van de Delta-tabel. U moet inschakelen
overwriteSchema, waardoor de Delta-tabel volledig kan worden herschreven. Anders mislukken bewerkingen.
Views
Als de weergave niet column_list overeenkomt met het nieuwe schema of als deze een query bevat die niet kan worden geparseerd, wordt de weergave ongeldig. Als dit niet het probleem is, kunt u de evolutie van het schema inschakelen voor typewijzigingen met SCHEMA TYPE EVOLUTION en voor typewijzigingen, evenals nieuwe, hernoemde en verwijderde kolommen met SCHEMA EVOLUTION (een superset van typeontwikkeling).
-
Nieuwe kolommen: ondersteund. Met
SCHEMA EVOLUTIONde modus verandert de weergave automatisch zonder handmatige tussenkomst als er geen explicietecolumn_listactie is. Anders kan de weergave ongeldig worden en kan de gebruiker er geen query's op uitvoeren. -
Kolommen hernoemen: ondersteund. Met
SCHEMA EVOLUTIONde modus verandert de weergave automatisch zonder handmatige tussenkomst als er geen explicietecolumn_listactie is. Anders kan de weergave ongeldig worden. -
Verwijderde kolommen: ondersteund. Met
SCHEMA EVOLUTIONde modus verandert de weergave automatisch zonder handmatige tussenkomst als er geen explicietecolumn_listactie is. Anders kan de weergave ongeldig worden. -
Type breder maken: ondersteund. Met
SCHEMA TYPE EVOLUTIONmodus evolueert de weergave automatisch voor elke typewijziging. MetSCHEMA EVOLUTIONde modus verandert de weergave automatisch zonder handmatige tussenkomst als er geen explicietecolumn_listactie is. Anders kan de weergave ongeldig worden. -
Andere typewijzigingen: ondersteund. Met
SCHEMA TYPE EVOLUTIONmodus evolueert de weergave automatisch voor elke typewijziging. MetSCHEMA EVOLUTIONde modus verandert de weergave automatisch zonder handmatige tussenkomst als er geen explicietecolumn_listactie is. Anders kan de weergave ongeldig worden.
Example
In het volgende voorbeeld ziet u hoe u een Kafka-onderwerp kunt opnemen met Avro-gecodeerde nettoladingen die zijn geregistreerd in Confluent Schema Registry en deze naar een beheerde Delta-tabel schrijft waarvoor schemaontwikkeling is ingeschakeld.
Belangrijke punten geïllustreerd:
- Integreer met de Kafka-connector.
- Avro-records decoderen met behulp van from_avro met een Kafka-schemaregister.
- De evolutie van het schema afhandelen door het instellen
avroSchemaEvolutionMode. - Schrijf naar een Delta-tabel met
mergeSchemaingeschakeld om additieve wijzigingen toe te staan.
In de code wordt ervan uitgegaan dat u een Kafka-onderwerp hebt met behulp van het Confluent-schemaregister, waarbij avro-gecodeerde gegevens worden uitgevoerd.
# ----- CONFIG: fill these in -----
# Catalog and schema:
CATALOG = "<catalog_name>"
SCHEMA = "<schema_name>"
# Schema Registry:
# (This is where the producer evolves the schema)
SCHEMA_REG = "<schema registry endpoint>"
SR_USER = "<api key>"
SR_PASS = "<api secret>"
# Confluent Cloud: SASL_SSL broker:
BOOTSTRAP = "<server:ip>"
# Kafka topic:
TOPIC = "<topic>"
# ----- end: config -----
BRONZE_TABLE = f"{CATALOG}.{SCHEMA}.bronze_users"
CHECKPOINT = f"/Volumes/{CATALOG}/{SCHEMA}/checkpoints/bronze_users"
# Kafka auth (example for Confluent Cloud SASL/PLAIN over SSL)
KAFKA_OPTS = {
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "PLAIN",
"kafka.sasl.jaas.config": f"kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username='{SR_USER}' password='{SR_PASS}';"
}
# ----- Evolution knobs -----
# spark.conf.set("spark.databricks.delta.schema.autoMerge.enabled", value = True)
from pyspark.sql.functions import col
from pyspark.sql.avro.functions import from_avro
# Build reader
reader = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", BOOTSTRAP)
.option("subscribe", TOPIC)
.option("startingOffsets", "earliest")
)
# Attach Kafka auth options
for k, v in KAFKA_OPTS.items():
reader = reader.option(k, v)
# --- No native schema evolution supported. Returns a binary blob. ---
raw_df = reader.load()
# Decode Avro with Schema Registry
# --- The format parser handles updating the schema using the schema registry ---
decoded = from_avro(
data=col("value"),
jsonFormatSchema=None, # using SR
subject=f"{TOPIC}-value",
schemaRegistryAddress=SCHEMA_REG,
options={
"confluent.schema.registry.basic.auth.credentials.source": "USER_INFO",
"confluent.schema.registry.basic.auth.user.info": f"{SR_USER}:{SR_PASS}",
# Behavior on schema changes:
"avroSchemaEvolutionMode": "restart", # fail-fast so you can restart and adopt new fields
"mode": "FAILFAST"
}
).alias("payload")
bronze_df = raw_df.select(decoded, "timestamp").select("payload.*", "timestamp")
# Write to a managed Delta table as a STREAM
# --- Need to enable schema evolution separately for streaming to a Delta separately with mergeSchema --
(bronze_df.writeStream
.format("delta")
.option("checkpointLocation", CHECKPOINT)
.option("ignoreChanges", "true")
.outputMode("append")
.option("mergeSchema", "true") # only supports adding new columns. Renaming, dropping, and type changes need to be handled separately.
.trigger(availableNow=True) # Use availableNow trigger for Databricks SQL/Unity Catalog
.toTable(BRONZE_TABLE)
)