Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In deze zelfstudie leert u hoe u een Azure Databricks-notebook gebruikt om gegevens te importeren uit een CSV-bestand met babynaamgegevens uit health.data.ny.gov in uw Unity Catalog-volume met behulp van Python, Scala en R. U leert ook hoe u een kolomnaam wijzigt, de gegevens visualiseert en opslaat in een tabel.
Opmerking
Als u Databricks Free Edition gebruikt, selecteert u het tabblad Python voor alle codevoorbeelden in deze zelfstudie. Free Edition biedt geen ondersteuning voor R of Scala. Bovendien beperkt Free Edition uitgaande internettoegang, dus moet u het CSV-bestand uploaden met behulp van de gebruikersinterface van de werkruimte in plaats van het te downloaden met code. Zie stap 3 voor gedetailleerde instructies.
Vereisten
Als u de taken in dit artikel wilt uitvoeren, moet u voldoen aan de volgende vereisten:
- Uw werkruimte moet Unity Catalog ingeschakeld. Zie Aan de slag met Unity Catalog voor meer informatie over hoe u aan de slag gaat met Unity Catalog. Voor Azure Databricks Free Edition en werkruimten voor gratis proefversies is Unity Catalog standaard ingeschakeld.
- U moet de bevoegdheid
WRITE VOLUMEhebben op een volume, de bevoegdheidUSE SCHEMAop het bovenliggende schema, en de bevoegdheidUSE CATALOGop de bovenliggende catalogus. Gebruikers van de Free Edition hebben deze bevoegdheden standaard voor de werkruimtecatalogus endefaulthet schema. - U moet gemachtigd zijn om een bestaande rekenresource te gebruiken of een nieuwe rekenresource te maken. Zie Compute of bekijk uw Azure Databricks-beheerder.
Aanbeveling
Zie Gegevensnotitieblokken importeren en visualiseren voor een voltooid notitieblok voor dit artikel.
Stap 1: Een nieuw notitieblok maken
Als u een notitieblok in uw werkruimte wilt maken, klikt u op ![]() Nieuw in de zijbalk en vervolgens op Notitieblok. Er wordt een leeg notitieblok geopend in de werkruimte.
Nieuw in de zijbalk en vervolgens op Notitieblok. Er wordt een leeg notitieblok geopend in de werkruimte.
Zie Databricks-notebooks beheren voor meer informatie over het maken en beheren van notebooks.
Stap 2: Variabelen definiëren
In deze stap definieert u variabelen voor gebruik in het voorbeeldnotitieblok dat u in dit artikel maakt. U hebt de namen van een Unity Catalog-catalogus, -schema en -volume nodig.
Aanbeveling
Als u de catalogus- en schemanamen niet weet, klikt u op ![]() Catalogus in de zijbalk. De werkruimtecatalogus deelt een naam met uw werkruimte en wordt weergegeven in het catalogusvenster. Vouw het uit om beschikbare schema's weer te geven. Gebruikers van de gratis editie en gratis proefversie kunnen de werkruimtecatalogus en het
Catalogus in de zijbalk. De werkruimtecatalogus deelt een naam met uw werkruimte en wordt weergegeven in het catalogusvenster. Vouw het uit om beschikbare schema's weer te geven. Gebruikers van de gratis editie en gratis proefversie kunnen de werkruimtecatalogus en het default schema gebruiken.
Als u geen volume hebt, maakt u er een door de volgende opdracht uit te voeren in een notebookcel (vervang <catalog_name> en <schema_name> door uw waarden):
CREATE VOLUME IF NOT EXISTS <catalog_name>.<schema_name>.my_volume
Kopieer en plak de volgende code in de nieuwe lege notebookcel. Vervang
<catalog-name>,<schema-name>en<volume-name>door de catalogus-, schema- en volumenamen voor een Unity Catalog-volume. Vervang eventueel detable_namewaarde door een tabelnaam van uw keuze. U slaat de gegevens van de babynaam verderop in dit artikel op in deze tabel.Druk
Shift+Enterom de cel uit te voeren en een nieuwe lege cel te maken.Python
catalog = "<catalog_name>" schema = "<schema_name>" volume = "<volume_name>" download_url = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name = "baby_names.csv" table_name = "baby_names" path_volume = "/Volumes/" + catalog + "/" + schema + "/" + volume path_table = catalog + "." + schema print(path_table) # Show the complete path print(path_volume) # Show the complete pathScala
val catalog = "<catalog_name>" val schema = "<schema_name>" val volume = "<volume_name>" val downloadUrl = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" val fileName = "baby_names.csv" val tableName = "baby_names" val pathVolume = s"/Volumes/${catalog}/${schema}/${volume}" val pathTable = s"${catalog}.${schema}" print(pathVolume) // Show the complete path print(pathTable) // Show the complete pathR
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" download_url <- "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name <- "baby_names.csv" table_name <- "baby_names" path_volume <- paste("/Volumes/", catalog, "/", schema, "/", volume, sep = "") path_table <- paste(catalog, ".", schema, sep = "") print(path_volume) # Show the complete path print(path_table) # Show the complete path
Stap 3: CSV-bestand importeren
In deze stap importeert u een CSV-bestand met babynaamgegevens uit health.data.ny.gov in uw Unity Catalog-volume. Kies één van de volgende methoden:
- Uploaden met behulp van de gebruikersinterface van de werkruimte : gebruik deze methode als u databricks Free Edition gebruikt of als het downloaden van de code in optie B mislukt met een netwerkfout. Free Edition en andere serverloze rekenomgevingen beperken uitgaande internettoegang, dus u moet het bestand uploaden vanaf uw lokale computer.
- Downloaden met behulp van code : gebruik deze methode als uw rekenomgeving uitgaande internettoegang heeft.
Optie A: Uploaden met behulp van de gebruikersinterface van de werkruimte
- Open health.data.ny.gov/api/views/jxy9-yhdk/rows.csv op uw lokale computer in uw browser. Het bestand wordt gedownload naar uw computer als
rows.csv. - Zoek het gedownloade bestand op uw computer en wijzig de naam van het bestand in
rows.csvbaby_names.csv. Dit komt overeen met defile_namevariabele die u in stap 2 hebt gedefinieerd. - Ga terug naar uw Azure Databricks-werkruimte. Klik in de zijbalk op
 Nieuw > toevoegen of gegevens uploaden.
Nieuw > toevoegen of gegevens uploaden. - Klik op Bestanden uploaden naar een volume.
- Klik op bladeren en selecteer het
baby_names.csvbestand of sleep het naar het uploadgebied. - Selecteer onder Doelvolume het volume dat u hebt opgegeven in stap 2.
- Nadat het uploaden is voltooid, gaat u terug naar uw notitieblok en gaat u verder met stap 4.
Zie Werken met bestanden in Unity Catalog-volumes voor meer informatie over het uploaden van bestanden.
Optie B: Downloaden met behulp van code
Kopieer en plak de volgende code in de nieuwe lege notebookcel. Met deze code wordt het
rows.csvbestand van health.data.ny.gov naar uw Unity Catalog-volume gekopieerd met behulp van de databricks dbutils-opdracht .Druk
Shift+Enterom de cel uit te voeren en naar de volgende cel te gaan.Python
dbutils.fs.cp(f"{download_url}", f"{path_volume}" + "/" + f"{file_name}")Scala
dbutils.fs.cp(downloadUrl, s"${pathVolume}/${fileName}")R
dbutils.fs.cp(download_url, paste(path_volume, "/", file_name, sep = ""))
Stap 4: CSV-gegevens laden in een DataFrame
In deze stap maakt u een DataFrame met de naam df van het CSV-bestand dat u eerder in uw Unity Catalog-volume hebt geladen met behulp van de methode spark.read.csv.
Kopieer en plak de volgende code in de nieuwe lege notebookcel. Met deze code worden babynaamgegevens vanuit het CSV-bestand in DataFrame
dfgeladen.Druk
Shift+Enterom de cel uit te voeren en naar de volgende cel te gaan.Python
df = spark.read.csv(f"{path_volume}/{file_name}", header=True, inferSchema=True, sep=",")Scala
val df = spark.read .option("header", "true") .option("inferSchema", "true") .option("delimiter", ",") .csv(s"${pathVolume}/${fileName}")R
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df <- read.df(paste(path_volume, "/", file_name, sep=""), source="csv", header = TRUE, inferSchema = TRUE, delimiter = ",")
U kunt gegevens laden uit een groot aantal ondersteunde bestandsindelingen.
Stap 5: Gegevens uit notebook visualiseren
In deze stap gebruikt u de methode display() om de inhoud van het DataFrame weer te geven in een tabel in het notebook en visualiseert u vervolgens de gegevens in een woordwolkdiagram in het notebook.
Kopieer en plak de volgende code in de nieuwe lege notebookcel en klik vervolgens op Cel uitvoeren om de gegevens in een tabel weer te geven.
Python
display(df)Scala
display(df)R
display(df)Bekijk de resultaten in de tabel.
Klik naast het tabblad Tabel op + en klik vervolgens op Visualisatie.
Klik in de visualisatie-editor op Visualisatietype en controleer of word-cloud is geselecteerd.
Controleer of is geselecteerd in de kolom Woorden
First Name.Klik in frequentielimietop
35.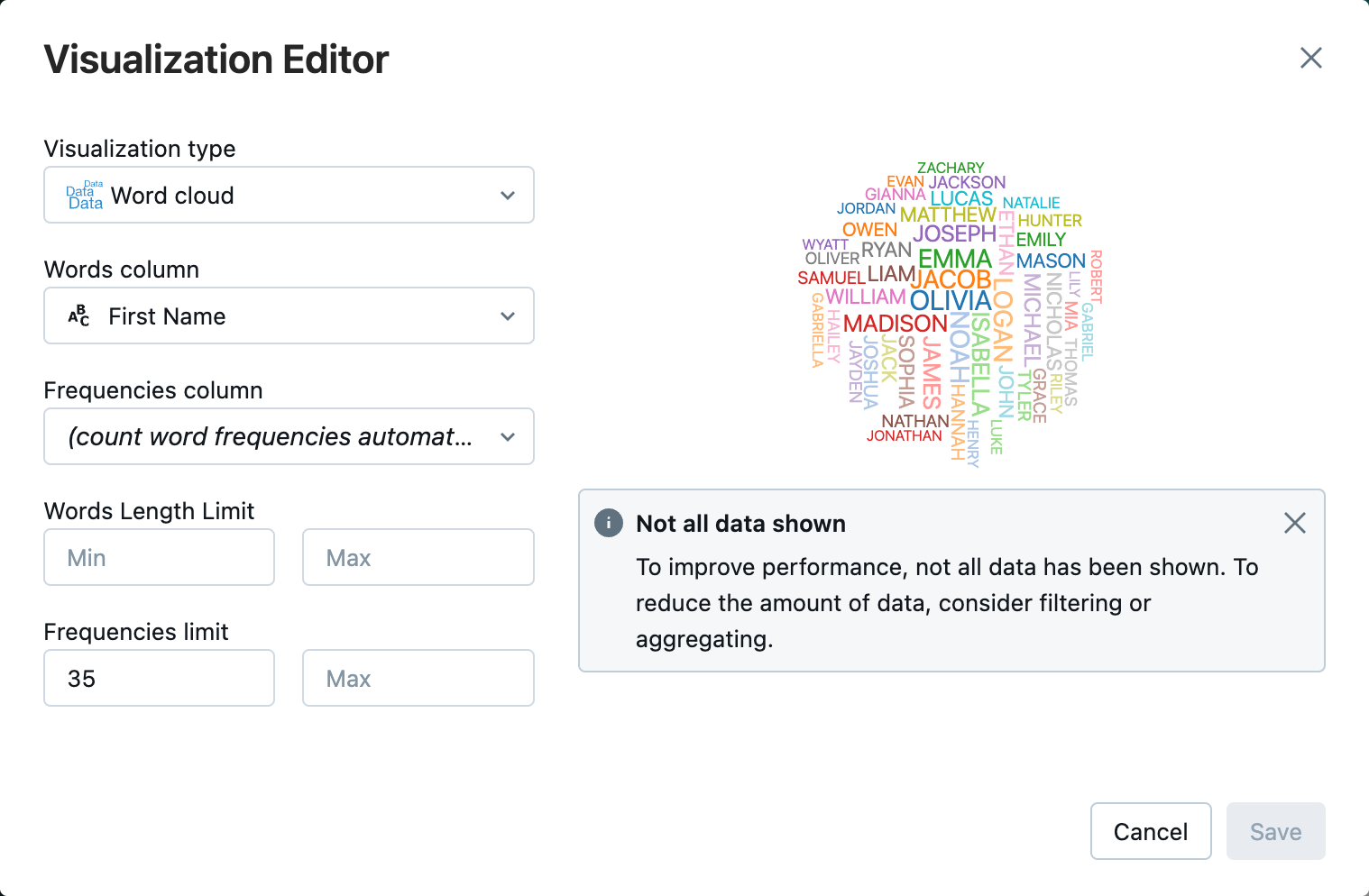
Klik op Opslaan.
Stap 6: Het DataFrame opslaan in een tabel
Belangrijk
Als u uw DataFrame in Unity Catalog wilt opslaan, moet u CREATE tabelbevoegdheden hebben voor de catalogus en het schema. Zie Bevoegdheden en beveiligbare objecten in Unity Catalog en Bevoegdheden beheren in Unity Catalogvoor meer informatie over machtigingen in Unity Catalog.
Kopieer en plak de volgende code in een lege notebookcel. Deze code vervangt een spatie in de kolomnaam. Speciale tekens, zoals spaties, zijn niet toegestaan in kolomnamen. Deze code maakt gebruik van de Apache Spark-methode
withColumnRenamed().Python
df = df.withColumnRenamed("First Name", "First_Name") df.printSchemaScala
val dfRenamedColumn = df.withColumnRenamed("First Name", "First_Name") // when modifying a DataFrame in Scala, you must assign it to a new variable dfRenamedColumn.printSchema()R
df <- withColumnRenamed(df, "First Name", "First_Name") printSchema(df)Kopieer en plak de volgende code in een lege notebookcel. Met deze code wordt de inhoud van het DataFrame opgeslagen in een tabel in Unity Catalog met behulp van de tabelnaamvariabele die u aan het begin van dit artikel hebt gedefinieerd.
Python
df.write.mode("overwrite").saveAsTable(f"{path_table}" + "." + f"{table_name}")Scala
dfRenamedColumn.write.mode("overwrite").saveAsTable(s"${pathTable}.${tableName}")R
saveAsTable(df, paste(path_table, ".", table_name), mode = "overwrite")Als u wilt controleren of de tabel is opgeslagen, klikt u op Catalogus in de linkerzijbalk om de gebruikersinterface van Catalog Explorer te openen. Open uw catalogus en vervolgens uw schema om te controleren of de tabel wordt weergegeven.
Klik op de tabel om het tabelschema weer te geven op het tabblad Overzicht.
Klik op voorbeeldgegevens om 100 rijen met gegevens uit de tabel weer te geven.
Gegevensnotitieblokken importeren en visualiseren
Gebruik een van de volgende notebooks om de stappen in dit artikel uit te voeren. Vervang <catalog-name>, <schema-name>en <volume-name> door de catalogus-, schema- en volumenamen voor een Unity Catalog-volume. Vervang eventueel de table_name waarde door een tabelnaam van uw keuze.
Python
Gegevens importeren uit CSV met behulp van Python
Scala
Gegevens importeren uit CSV met behulp van Scala
R
Gegevens importeren uit CSV met R
Volgende stappen
- Zie Handleiding: Exploratieve gegevensanalysetechnieken met Databricks-notebooks.
- Zie Zelfstudie: Een ETL-pijplijn bouwen met Lakeflow pipelines en Zelfstudie: Een ETL-pijplijn bouwen met Apache Spark op het Databricks-platform voor informatie over het bouwen van een ETL-pijplijn (extract, transform, and load)