Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In deze zelfstudie wordt u begeleid bij het gebruik van een Azure Databricks-notebook om een query uit te voeren op voorbeeldgegevens die zijn opgeslagen in Unity Catalog met behulp van SQL, Python, Scala en R en vervolgens de queryresultaten in het notebook te visualiseren.
Tip
Laat Genie Code (agentmodus) dit voor u doen:
Create a new notebook that queries @samples.nyctaxi.trips and displays a bar chart showing the average fare amount by trip distance, grouped by the pickup zip code.
Vereisten
Als u de taken in dit artikel wilt uitvoeren, moet u voldoen aan de volgende vereisten:
- Uw werkruimte moet Unity Catalog ingeschakeld zijn. Zie Aan de slag met Unity Catalog voor meer informatie over hoe u aan de slag gaat met Unity Catalog.
- U moet gemachtigd zijn om een bestaande rekenresource te gebruiken of een nieuwe rekenresource te maken. Zie Compute of zie uw Databricks-beheerder.
Stap 1: Een nieuw notitieblok maken
Als u een notitieblok in uw werkruimte wilt maken, klikt u op ![]() Nieuw in de zijbalk en vervolgens op Notitieblok. Er wordt een leeg notitieblok geopend in de werkruimte.
Nieuw in de zijbalk en vervolgens op Notitieblok. Er wordt een leeg notitieblok geopend in de werkruimte.
Zie Databricks-notebooks beheren voor meer informatie over het maken en beheren van notebooks.
Stap 2: Een query uitvoeren op een tabel
Voer een query uit op de samples.nyctaxi.trips tabel in Unity Catalog met behulp van de taal van uw keuze. Deze tabel is een van de voorbeeldgegevenssets die zijn opgenomen in de samples catalogus.
Kopieer en plak de volgende code in de nieuwe lege notebookcel. Met deze code worden de resultaten weergegeven van het opvragen van de
samples.nyctaxi.tripstabel in Unity Catalog.SQL
SELECT * FROM samples.nyctaxi.tripsPython
display(spark.read.table("samples.nyctaxi.trips"))Scala
display(spark.read.table("samples.nyctaxi.trips"))R
library(SparkR) display(sql("SELECT * FROM samples.nyctaxi.trips"))Druk
Shift+Enterom de cel uit te voeren en naar de volgende cel te gaan.De queryresultaten worden weergegeven in het notebook.
Stap 3: de gegevens weergeven
Geef het gemiddelde tarief op reisafstand weer, gegroepeerd op de postcode voor ophalen.
Klik naast het tabblad Tabel op + en klik vervolgens op Visualisatie.
De visualisatie-editor wordt weergegeven.
Controleer in de vervolgkeuzelijst Visualisatietype of Balk is geselecteerd.
Selecteer
fare_amountvoor de X-kolom.Selecteer
trip_distancevoor de Y-kolom.Selecteer
Averagehet aggregatietype.Selecteer
pickup_zipals de Groeperen op kolom.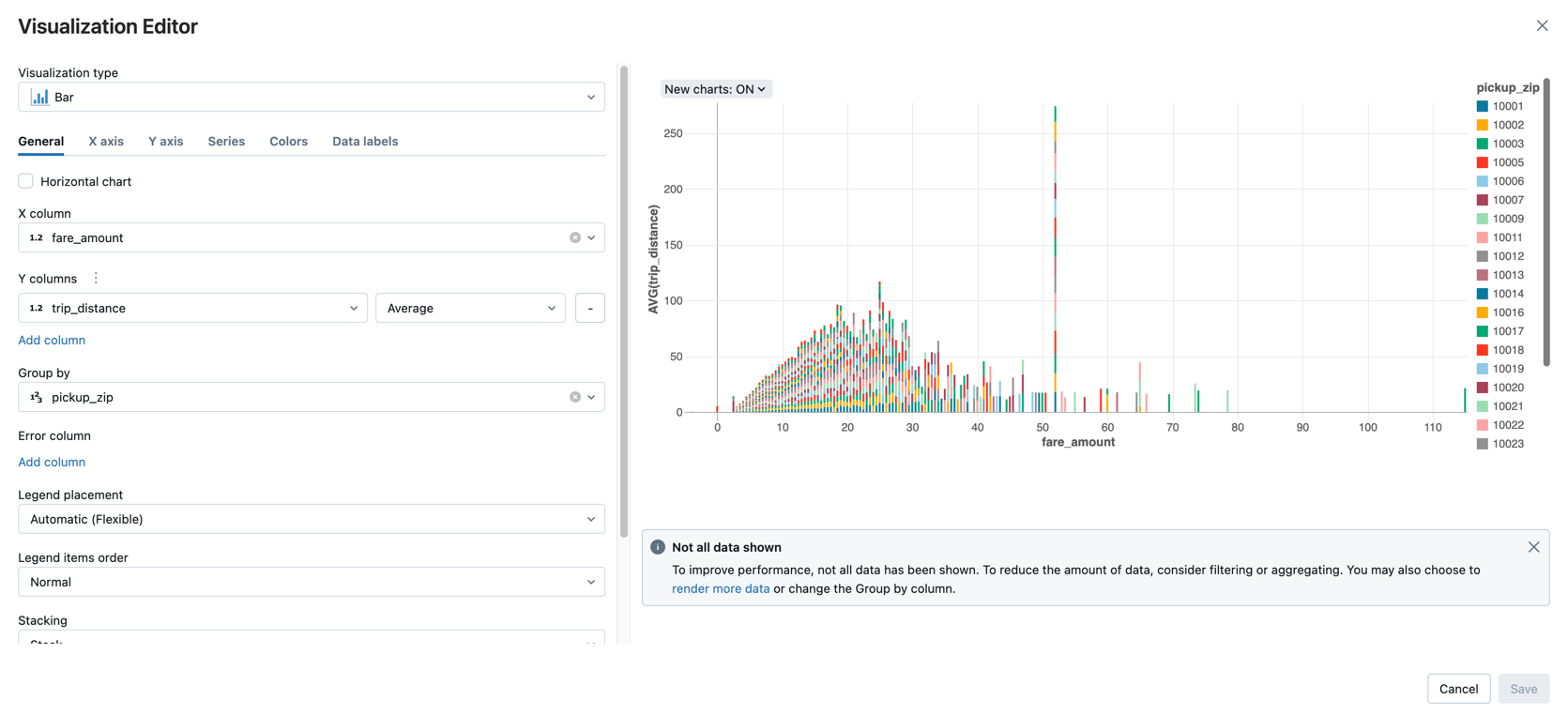
Klik op Opslaan.
Volgende stappen
- Zie zelfstudie: CSV-gegevens importeren en visualiseren vanuit een notebook voor meer informatie over het toevoegen van gegevens uit een CSV-bestand aan Unity Catalog en het visualiseren van gegevens.
- Voor meer informatie over het laden van gegevens in Databricks met behulp van Apache Spark, raadpleegt u zelfstudie: Gegevens laden en transformeren met Apache Spark DataFrames.
- Zie Standard connectors in Lakeflow Connect voor meer informatie over hoe u gegevens in Databricks kunt opnemen.
- Zie Querygegevens voor meer informatie over het uitvoeren van query's op gegevens met Databricks.
- Zie Visualisaties in Databricks-notebooks en SQL-editor voor meer informatie over visualisaties.
- Zie zelfstudie: EDA-technieken (EDA) voor meer informatie over experimentele gegevensanalysetechnieken: EDA-technieken met behulp van Databricks-notebooks.