Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In Azure Databricks kunt u broncodebeheer uitvoeren voor een pijplijn en alle code die eraan is gekoppeld. Door alle bestanden die aan uw pijplijn zijn gekoppeld onder versiebeheer in Git te plaatsen, kunnen wijzigingen in uw transformatiecode, verkenningscode en pijplijnconfiguratie worden getest in de ontwikkelingsfase en met vertrouwen in productie worden geïmplementeerd.
Een brongestuurde pijplijn biedt de volgende voordelen:
- Traceerbaarheid: leg elke wijziging in de Git-geschiedenis vast.
- Testen: Pijplijnwijzigingen valideren in een ontwikkelwerkruimte voordat u promoveert naar een gedeelde productiewerkruimte. Elke ontwikkelaar heeft een eigen ontwikkelingspijplijn in hun eigen codebranch in een Git-map en in hun eigen schema.
- Samenwerking: wanneer afzonderlijke ontwikkeling en testen zijn voltooid, worden codewijzigingen naar de belangrijkste productiepijplijn gepusht.
- Governance: afgestemd op bedrijfs-CI/CD- en implementatiestandaarden.
Met Azure Databricks kunnen pijplijnen en hun bronbestanden samen worden beheerd met behulp van declaratieve Automation-bundels. Met bundels wordt de pijplijnconfiguratie beheerd door bronbeheer in de vorm van YAML-configuratiebestanden naast de Python- of SQL-bronbestanden van een pijplijn. Een bundel kan één of meerdere pijplijnen hebben, evenals andere brontypen, zoals jobs.
Op deze pagina ziet u hoe u een onder broncontrole beheer pijplijn instelt met behulp van declaratieve automatiseringsbundels, zoals dat vroeger Databricks Asset Bundles werden genoemd. Zie Wat zijn declaratieve automation-bundels? voor meer informatie over bundels.
Requirements
Als u een door bron beheerde pijplijn wilt maken, moet u het volgende al hebben:
- Een Git-map die in uw werkruimte is gemaakt en geconfigureerd. Met een Git-map kunnen afzonderlijke gebruikers wijzigingen ontwerpen en testen voordat ze worden doorgevoerd in een Git-opslagplaats. Zie Git-mappen van Azure Databricks.
- De Lakeflow Pipelines-editor. Zie ETL-pijplijnen ontwikkelen en fouten opsporen met de Lakeflow Pipelines Editor voor meer informatie.
- Zie Identiteiten, machtigingen en rechten voor pijplijnen beheren voor de volledige set rechten die vereist zijn om pijplijnen en de uitvoer ervan te maken, uit te voeren, te vernieuwen en weer te geven.
Een nieuwe pijplijn maken in een bundel
Opmerking
Databricks raadt aan om een pijplijn te maken die vanaf het begin door de bron wordt beheerd. U kunt ook een bestaande pijplijn toevoegen aan een bundel die al door de bron wordt beheerd. Zie Migreer bestaande resources naar een bundel.
Ga als volgt te werk om een nieuwe, door bron beheerde pijplijn te maken:
Klik boven aan de zijbalk op
 Nieuw en selecteer vervolgens
Nieuw en selecteer vervolgens  ETL-pijplijn.
ETL-pijplijn.Breng de gewenste wijzigingen aan in de naam of het schema van de pijplijn. Zie Een nieuwe ETL-pijplijn maken.
Klik op het
 -menu (rechts van de knop
-menu (rechts van de knop  Voorbeeldcode gebruiken) en selecteer
Voorbeeldcode gebruiken) en selecteer  Instellen als broncodebeheer.
Instellen als broncodebeheer.Klik op Nieuw project maken en selecteer vervolgens een Git-map waarin u de code en configuratie wilt plaatsen:
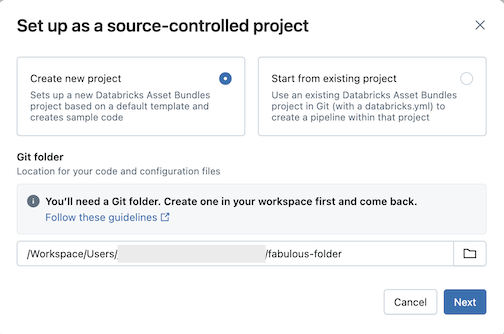
Klik op Volgende.
Voer het volgende in het dialoogvenster Een assetbundel maken in:
- Bundelnaam: de naam van de bundel.
- Initiële catalogus: de naam van de catalogus die het schema bevat dat moet worden gebruikt.
- Gebruik een persoonlijk schema: laat dit selectievakje ingeschakeld als u bewerkingen wilt isoleren in een persoonlijk schema, zodat wanneer gebruikers in uw organisatie samenwerken aan hetzelfde project dat u elkaars wijzigingen niet overschrijft in dev.
- Initiële taal: de initiële taal die moet worden gebruikt voor de voorbeeldpijplijnbestanden van het project, Python of SQL.
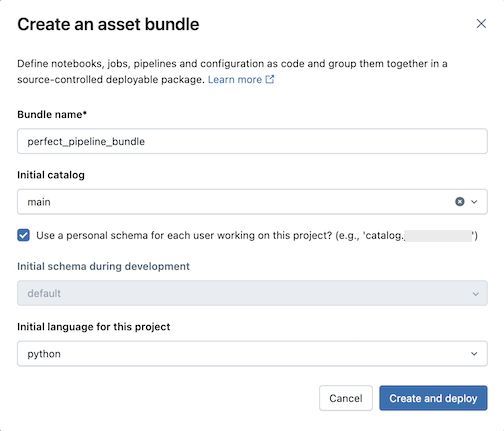
Klik op Maken en implementeren. Er wordt een bundel met een pijplijn gemaakt in de Git-map.
De pijplijnbundel verkennen
Verken vervolgens de pijplijnbundel die is gemaakt.
De bundel, die zich in de Git-map bevindt, bevat bundel systeembestanden en het databricks.yml bestand, waarmee variabelen, url's en machtigingen voor de doelwerkruimte worden gedefinieerd, en andere instellingen voor de bundel. Omdat databricks.yml zich in de hoofdmap van de bundel bevindt (de bovenliggende map van de pijplijnhoofdmap), gaat u naar het tabblad Alle bestanden in de assetbrowser van de pijplijn om het te zien. De resources map van een bundel is de locatie waar definities voor resources, zoals pijplijnen en taken, zijn opgenomen.
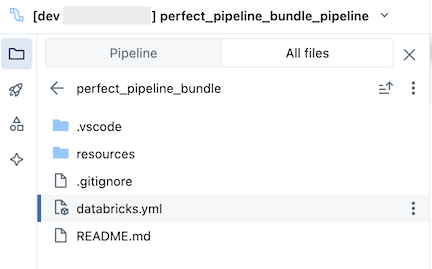
Open de resources map en klik vervolgens op de knop Pijplijneditor om de brongestuurde pijplijn weer te geven:
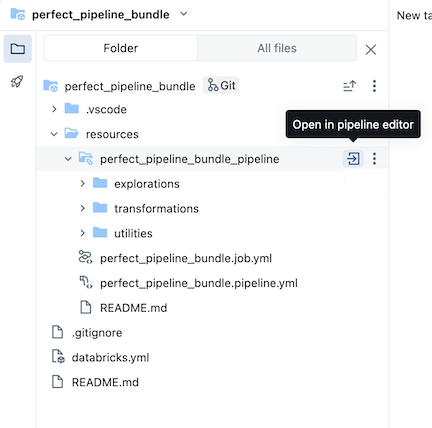
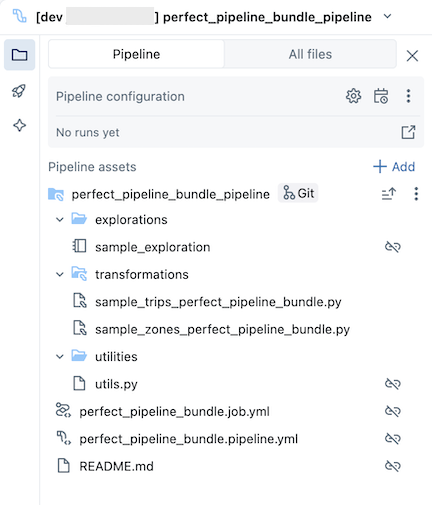
De voorbeeldpijplijnbundel bevat de volgende bestanden:
Een voorbeeld van een verkenningsnotitieblok
Twee voorbeeldcodebestanden die transformaties uitvoeren op tabellen
Een voorbeeldcodebestand dat een hulpprogrammafunctie bevat
Een YAML-bestand voor taakconfiguratie waarmee de taak in de bundel wordt gedefinieerd waarmee de pijplijn wordt uitgevoerd
Een YAML-bestand voor pijplijnconfiguratie dat de pijplijn definieert
Belangrijk
U moet dit bestand bewerken om configuratiewijzigingen in de pijplijn permanent vast te leggen, inclusief wijzigingen die zijn aangebracht via de gebruikersinterface, anders worden wijzigingen in de gebruikersinterface overschreven wanneer de bundel opnieuw wordt geïmplementeerd. Als u bijvoorbeeld een andere standaardcatalogus voor de pijplijn wilt instellen, bewerkt u het
catalogveld in dit configuratiebestand.Een README-bestand met aanvullende informatie over de voorbeeldpijplijnbundel en instructies voor het uitvoeren van de pijplijn
Raadpleeg de Assetbrowser voor pijplijnen voor informatie over pijplijnbestanden.
Zie Auteursbundels in de werkruimte maken en implementeren en werkstromen uitvoeren vanuit de werkruimte voor meer informatie over het ontwerpen en implementeren van wijzigingen in de pijplijnbundel.
De pijplijn uitvoeren
U kunt afzonderlijke transformaties of de volledige door de bron beheerde pijplijn uitvoeren:
- Als u één transformatie in de pijplijn wilt uitvoeren en bekijken, selecteert u het transformatiebestand in de browserstructuur van de werkruimte om het te openen in de bestandseditor. Klik bovenaan het bestand in de editor op de knop Run file om het bestand uit te voeren.
- Als u alle transformaties in de pijplijn wilt uitvoeren, klikt u op de knop Pijplijn uitvoeren in de rechterbovenhoek van de Databricks-werkruimte.
Zie Pijplijncode uitvoeren voor meer informatie over het uitvoeren van pijplijnen.
De pijplijn bijwerken
U kunt artefacten in uw pijplijn bijwerken of aanvullende verkenningen en transformaties toevoegen, maar u wilt deze wijzigingen naar GitHub pushen. Klik op het ![]() of het Git-pictogram dat is gekoppeld aan de pijplijnbundel, of klik op het kebab-menu voor de map en vervolgens op Git... om te selecteren welke wijzigingen u wilt pushen. Zie Wijzigingen doorvoeren en pushen.
of het Git-pictogram dat is gekoppeld aan de pijplijnbundel, of klik op het kebab-menu voor de map en vervolgens op Git... om te selecteren welke wijzigingen u wilt pushen. Zie Wijzigingen doorvoeren en pushen.
Wanneer u pijplijnconfiguratiebestanden bijwerkt of bestanden toevoegt aan of verwijdert uit de bundel, worden deze wijzigingen niet doorgegeven aan de doelwerkruimte totdat u de bundel expliciet implementeert. Zie Bundels implementeren en werkstromen uitvoeren vanuit de werkruimte.
Opmerking
Databricks raadt u aan de standaardinstelling voor door bron beheerde pijplijnen te behouden. De standaardinstelling is zo geconfigureerd dat u de YAML-configuratie van de pijplijnbundel niet hoeft te bewerken wanneer er extra bestanden worden toegevoegd via de gebruikersinterface.
Een bestaande pijplijn toevoegen aan een bundel
Als u een bestaande pijplijn wilt toevoegen aan een bundel, maakt u eerst een bundel in de werkruimte en voegt u vervolgens de YAML-definitie van de pijplijn toe aan de bundel, zoals wordt beschreven op de volgende pagina's:
- Zelfstudie: Een bundel maken en implementeren in de werkruimte
- Een bestaande resource toevoegen aan een bundel
Zie Bestaande resources migreren naar een bundel met behulp van de Databricks CLI voor informatie over het migreren van resources naar een bundel.
Aanvullende bronnen
Zie Spark Declarative Pipelines voor meer tutorials en referentiemateriaal over pijplijnen.