Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Dit artikel bevat de basisstappen voor het implementeren en opvragen van een aangepast model, dat een traditioneel ML-model is, met behulp van Mosaic AI Model Serving. Het model moet zijn geregistreerd in Unity Catalog of in het register van het werkruimtemodel.
Zie de volgende artikelen voor meer informatie over het leveren en implementeren van generatieve AI-modellen:
Stap 1: het model registreren
Er zijn verschillende manieren om uw model te registreren voor het leveren van modellen:
| Techniek voor logboekregistratie | Beschrijving |
|---|---|
| Automatisch loggen | Dit wordt automatisch ingeschakeld wanneer u Databricks Runtime gebruikt voor machine learning. Het is de eenvoudigste manier, maar geeft je minder controle. |
| Loggen met behulp van de ingebouwde functies van MLflow | U kunt het model handmatig registreren met de ingebouwde modellenopties van MLflow. |
Aangepaste logboekregistratie met pyfunc |
Gebruik dit als u een aangepast model hebt of als u extra stappen voor of na deductie nodig hebt. |
In het volgende voorbeeld ziet u hoe u uw MLflow-model kunt loggen met behulp van de transformer-flavor en parameters specificeert die u nodig hebt voor uw model.
with mlflow.start_run():
model_info = mlflow.transformers.log_model(
transformers_model=text_generation_pipeline,
artifact_path="my_sentence_generator",
inference_config=inference_config,
registered_model_name='gpt2',
input_example=input_example,
signature=signature
)
Nadat uw model is geregistreerd, controleert u of uw model is geregistreerd in Unity Catalog of het MLflow-modelregister.
Stap 2: Een eindpunt maken met behulp van de gebruikersinterface van de server
Nadat uw geregistreerde model is gelogd en u klaar bent om het in gebruik te nemen, kunt u een modelserveereindpunt maken met behulp van de Serving-UI.
Klik op Serveren in de zijbalk om de gebruikersinterface van de server weer te geven.
Klik op Een service-eindpunt maken.
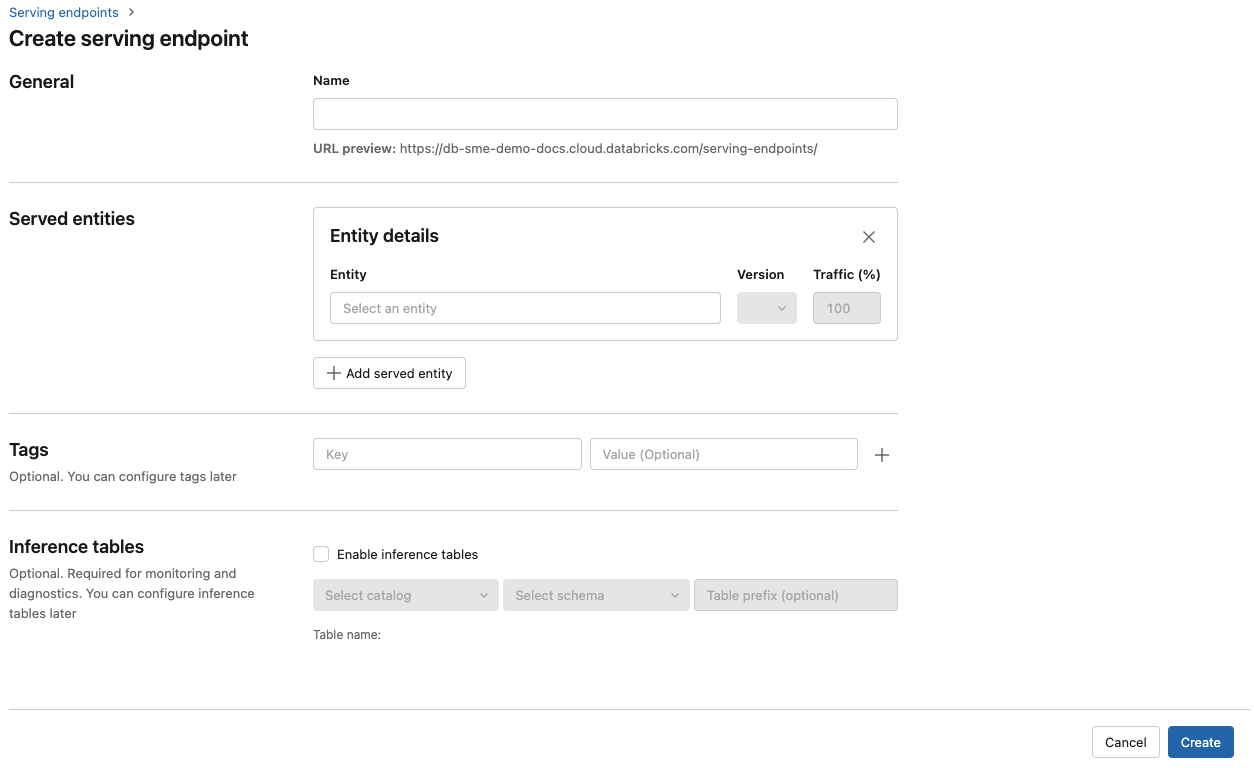
Geef in het veld Naam een naam op voor uw eindpunt.
In de sectie Geserveerde entiteiten
- Klik in het veld Entiteit om het formulier Genereerde entiteit selecteren te openen.
- Selecteer het type model dat u wilt serveren. Het formulier wordt dynamisch bijgewerkt op basis van uw selectie.
- Selecteer welk model en welke modelversie u wilt gebruiken.
- Selecteer het percentage verkeer dat u naar uw geleverd model wilt routeren.
- Selecteer welke grootte rekenkracht u wilt gebruiken.
- Selecteer onder Compute Scale-out de grootte van de rekenschaal die overeenkomt met het aantal aanvragen dat dit geleverd model tegelijkertijd kan verwerken. Dit getal moet ongeveer gelijk zijn aan de uitvoeringstijd van het QPS x-model.
- De beschikbare grootten zijn klein voor 0-4 aanvragen, gemiddeld 8-16 aanvragen en groot voor 16-64 aanvragen.
- Geef op of het eindpunt moet worden geschaald naar nul wanneer het niet in gebruik is.
Klik op Maken. De pagina Eindpunten voor het serveren wordt weergegeven met de status Van het servereindpunt die wordt weergegeven als Niet gereed.
Als u liever programmatisch een eindpunt maakt met de Databricks Serving-API, raadpleegt u Aangepast model maken voor eindpunten.
Stap 3: Het eindpunt opvragen
De eenvoudigste en snelste manier om scoreaanvragen te testen en te verzenden naar uw aangeboden model is door gebruik te maken van de gebruikersinterface van de server .
Ga op de pagina Servereindpunt naar Query-eindpunt.
Voeg de modelinvoergegevens in de JSON-indeling in en klik op Aanvraag verzenden. Als het model is geregistreerd met een invoervoorbeeld, klikt u op Voorbeeld weergeven om het invoervoorbeeld te laden.
{ "inputs" : ["Hello, I'm a language model,"], "params" : {"max_new_tokens": 10, "temperature": 1} }
Als u scoreaanvragen wilt verzenden, maakt u een JSON met een van de ondersteunde sleutels en een JSON-object dat overeenkomt met de invoerindeling. Zie Query-serveerpunten voor aangepaste modellen voor de ondersteunde indelingen en richtlijnen voor het verzenden van scoringverzoeken met behulp van de API.
Als u van plan bent om toegang te krijgen tot uw eindpunt buiten de gebruikersinterface van Azure Databricks Serving, hebt u een DATABRICKS_API_TOKEN.
Belangrijk
Als best practice voor beveiliging voor productiescenario's raadt Databricks u aan om OAuth-tokens voor machine-naar-machine te gebruiken voor verificatie tijdens de productie.
Voor testen en ontwikkelen raadt Databricks aan om een persoonlijk toegangstoken te gebruiken dat hoort bij service-principals in plaats van werkruimtegebruikers. Zie Tokens voor een service-principal beheren om tokens voor een service-principal te maken.
Voorbeeldnotebooks
Zie het volgende notebook voor het leveren van een MLflow-model transformers met Model Serving.
Een notebook voor een Hugging Face Transformers-model implementeren
Zie het volgende notebook voor het leveren van een MLflow-model pyfunc met Model Serving. Zie Python-code implementeren met Model Serving voor meer informatie over het aanpassen van uw modelimplementaties.