Dbt-transformaties gebruiken in een Azure Databricks-taak
U kunt uw dbt Core-projecten uitvoeren als een taak in een Azure Databricks-taak. Door uw dbt Core-project uit te voeren als taaktaak, kunt u profiteren van de volgende functies van Azure Databricks-taken:
- Automatiseer uw dbt-taken en plan werkstromen die dbt-taken bevatten.
- Bewaak uw dbt-transformaties en verzend meldingen over de status van de transformaties.
- Neem uw dbt-project op in een werkstroom met andere taken. Uw werkstroom kan bijvoorbeeld gegevens opnemen met automatisch laden, de gegevens transformeren met dbt en de gegevens analyseren met een notebooktaak.
- Automatische archivering van de artefacten van taakuitvoeringen, waaronder logboeken, resultaten, manifesten en configuratie.
Raadpleeg de dbt-documentatie voor meer informatie over dbt Core.
Ontwikkelings- en productiewerkstroom
Databricks raadt u aan uw dbt-projecten te ontwikkelen op basis van een Databricks SQL Warehouse. Met behulp van een Databricks SQL Warehouse kunt u de SQL testen die is gegenereerd door dbt en de SQL Warehouse-querygeschiedenis gebruiken om fouten op te sporen in de query's die door dbt zijn gegenereerd.
Als u uw dbt-transformaties in productie wilt uitvoeren, raadt Databricks aan om de dbt-taak in een Databricks-taak te gebruiken. De dbt-taak voert standaard het dbt Python-proces uit met behulp van Azure Databricks Compute en de dbt gegenereerde SQL op basis van het geselecteerde SQL-warehouse.
U kunt dbt-transformaties uitvoeren op een serverloze SQL Warehouse of pro SQL Warehouse, Azure Databricks Compute of een ander dbt-ondersteund warehouse. In dit artikel worden de eerste twee opties besproken met voorbeelden.
Als uw werkruimte is ingeschakeld voor Unity Catalog en serverloze werkstromen is ingeschakeld, wordt de taak standaard uitgevoerd op serverloze berekeningen.
Notitie
Het ontwikkelen van dbt-modellen op basis van een SQL-warehouse en het uitvoeren ervan in productie op Azure Databricks Compute kan leiden tot subtiele verschillen in prestaties en ondersteuning voor SQL-talen. Databricks raadt aan om dezelfde Databricks Runtime-versie te gebruiken voor de berekening en het SQL-warehouse.
Vereisten
Zie Verbinding maken met dbt Core voor meer informatie over het gebruik van dbt Core en het pakket voor het
dbt-databricksmaken en uitvoeren van dbt-projecten in uw ontwikkelomgeving.Databricks raadt het dbt-databricks-pakket aan, niet het dbt-spark-pakket. Het dbt-databricks-pakket is een fork van dbt-spark die is geoptimaliseerd voor Databricks.
Als u dbt-projecten in een Azure Databricks-taak wilt gebruiken, moet u Git-integratie met Databricks Git-mappen instellen. U kunt geen dbt-project uitvoeren vanuit DBFS.
U moet serverloze of pro SQL-warehouses hebben ingeschakeld.
U moet over het Sql-recht van Databricks beschikken.
Uw eerste dbt-taak maken en uitvoeren
In het volgende voorbeeld wordt het jaffle_shop project gebruikt, een voorbeeldproject dat de belangrijkste dbt-concepten demonstreert. Voer de volgende stappen uit om een taak te maken waarmee het jaffle shop-project wordt uitgevoerd.
Ga naar de landingspagina van Azure Databricks en voer een van de volgende handelingen uit:
- Klik op
 Werkstromen in de zijbalk en klik op .
Werkstromen in de zijbalk en klik op .
- Klik in de zijbalk op
 Nieuw en selecteer Taak.
Nieuw en selecteer Taak.
- Klik op
Vervang in het taaktekstvak op het tabblad Taken een naam voor uw taak toevoegen... door uw taaknaam.
Voer in taaknaam een naam in voor de taak.
Selecteer in Type het dbt-taaktype .
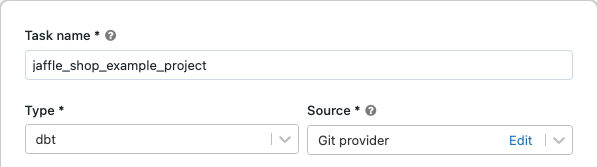
In de vervolgkeuzelijst Bron kunt u Werkruimte selecteren om een dbt-project te gebruiken in een Azure Databricks-werkruimtemap of Git-provider voor een project dat zich in een externe Git-opslagplaats bevindt. Omdat in dit voorbeeld het jaffle shop-project wordt gebruikt dat zich in een Git-opslagplaats bevindt, selecteert u Git-provider, klikt u op Bewerken en voert u de details in voor de GitHub-opslagplaats van de Jaffle-winkel.
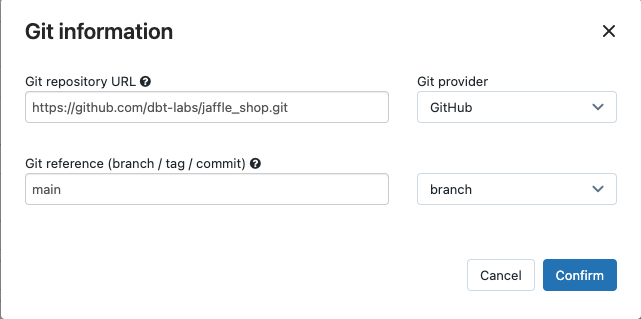
- Voer in de URL van de Git-opslagplaats de URL in voor het jaffle-winkelproject.
- Voer in Git-verwijzing (vertakking/tag/doorvoer) in
main. U kunt ook een tag of SHA gebruiken.
Klik op Bevestigen.
Geef in de tekstvakken dbt-opdrachten de dbt-opdrachten op die moeten worden uitgevoerd (deps, seed en run). U moet voor elke opdracht een voorvoegsel geven.
dbtOpdrachten worden uitgevoerd in de opgegeven volgorde.
Selecteer in SQL Warehouse een SQL Warehouse om de SQL uit te voeren die is gegenereerd door dbt. In het vervolgkeuzemenu van SQL Warehouse worden alleen serverloze en pro SQL-warehouses weergegeven.
(Optioneel) U kunt een schema opgeven voor de taakuitvoer. Standaard wordt het schema
defaultgebruikt.(Optioneel) Als u de rekenconfiguratie wilt wijzigen waarop dbt Core wordt uitgevoerd, klikt u op dbt CLI-berekening.
(Optioneel) U kunt een dbt-databricks-versie voor de taak opgeven. Als u uw dbt-taak bijvoorbeeld wilt vastmaken aan een specifieke versie voor ontwikkeling en productie:
- Klik onder Afhankelijke bibliotheken naast
 de huidige dbt-databricks-versie.
de huidige dbt-databricks-versie. - Klik op Toevoegen.
- Selecteer PyPI in het dialoogvenster Afhankelijke bibliotheek toevoegen en voer de dbt-package-versie in het tekstvak Pakket in (bijvoorbeeld
dbt-databricks==1.6.0). - Klik op Toevoegen.

Notitie
Databricks raadt u aan uw dbt-taken vast te maken aan een specifieke versie van het dbt-databricks-pakket om ervoor te zorgen dat dezelfde versie wordt gebruikt voor ontwikkelings- en productieuitvoeringen. Databricks raadt versie 1.6.0 of hoger aan van het dbt-databricks-pakket.
- Klik onder Afhankelijke bibliotheken naast
Klik op Create.
Als u de taak nu wilt uitvoeren, klikt u op
 .
.
De resultaten van uw dbt-taak weergeven
Wanneer de taak is voltooid, kunt u de resultaten testen door SQL-query's uit te voeren vanuit een notebook of door query's uit te voeren in uw Databricks-warehouse. Zie bijvoorbeeld de volgende voorbeeldquery's:
SHOW tables IN <schema>;
SELECT * from <schema>.customers LIMIT 10;
Vervang door <schema> de schemanaam die is geconfigureerd in de taakconfiguratie.
API-voorbeeld
U kunt ook de Taken-API gebruiken om taken te maken en beheren die dbt-taken bevatten. In het volgende voorbeeld wordt een taak met één dbt-taak gemaakt:
{
"name": "jaffle_shop dbt job",
"max_concurrent_runs": 1,
"git_source": {
"git_url": "https://github.com/dbt-labs/jaffle_shop",
"git_provider": "gitHub",
"git_branch": "main"
},
"job_clusters": [
{
"job_cluster_key": "dbt_CLI",
"new_cluster": {
"spark_version": "10.4.x-photon-scala2.12",
"node_type_id": "Standard_DS3_v2",
"num_workers": 0,
"spark_conf": {
"spark.master": "local[*, 4]",
"spark.databricks.cluster.profile": "singleNode"
},
"custom_tags": {
"ResourceClass": "SingleNode"
}
}
}
],
"tasks": [
{
"task_key": "transform",
"job_cluster_key": "dbt_CLI",
"dbt_task": {
"commands": [
"dbt deps",
"dbt seed",
"dbt run"
],
"warehouse_id": "1a234b567c8de912"
},
"libraries": [
{
"pypi": {
"package": "dbt-databricks>=1.0.0,<2.0.0"
}
}
]
}
]
}
(Geavanceerd) Dbt uitvoeren met een aangepast profiel
Als u uw dbt-taak wilt uitvoeren met een SQL Warehouse (aanbevolen) of rekenproces voor alle doeleinden, gebruikt u een aangepaste profiles.yml definitie van het magazijn of Azure Databricks-rekenproces om verbinding te maken. Voer de volgende stappen uit om een taak te maken waarmee het jaffle-winkelproject wordt uitgevoerd met een magazijn of een rekenproces voor alle doeleinden.
Notitie
Alleen een SQL-warehouse of rekenproces voor alle doeleinden kan worden gebruikt als doel voor een dbt-taak. U kunt taak berekenen niet gebruiken als doel voor dbt.
Maak een fork van de jaffle_shop opslagplaats.
Kloon de geforkte opslagplaats naar uw bureaublad. U kunt bijvoorbeeld een opdracht als volgt uitvoeren:
git clone https://github.com/<username>/jaffle_shop.gitVervang door
<username>uw GitHub-ingang.Maak een nieuw bestand met de naam
profiles.ymlin dejaffle_shopmap met de volgende inhoud:jaffle_shop: target: databricks_job outputs: databricks_job: type: databricks method: http schema: "<schema>" host: "<http-host>" http_path: "<http-path>" token: "{{ env_var('DBT_ACCESS_TOKEN') }}"- Vervang door
<schema>een schemanaam voor de projecttabellen. - Als u uw dbt-taak wilt uitvoeren met een SQL-warehouse, vervangt u
<http-host>de serverhostnaamwaarde op het tabblad Verbindingsgegevens voor uw SQL-warehouse. Als u uw dbt-taak wilt uitvoeren met alle doeleinden, vervangt<http-host>u de serverhostnaamwaarde op het tabblad Geavanceerde opties, JDBC/ODBC voor uw Azure Databricks-rekenproces. - Als u uw dbt-taak wilt uitvoeren met een SQL-warehouse, vervangt u
<http-path>de waarde van het HTTP-pad op het tabblad Verbindingsgegevens voor uw SQL-warehouse. Als u uw dbt-taak wilt uitvoeren met berekeningen voor alle doeleinden, vervangt u deze door<http-path>de HTTP-padwaarde van het tabblad Geavanceerde opties, JDBC/ODBC voor uw Azure Databricks-rekenproces.
U geeft geen geheimen op, zoals toegangstokens, in het bestand, omdat u dit bestand in broncodebeheer gaat controleren. In plaats daarvan gebruikt dit bestand de dbt-sjabloonfunctionaliteit om referenties dynamisch in te voegen tijdens runtime.
Notitie
De gegenereerde referenties zijn geldig voor de duur van de uitvoering, maximaal 30 dagen en worden automatisch ingetrokken na voltooiing.
- Vervang door
Controleer dit bestand in Git en push het naar uw geforkte opslagplaats. U kunt bijvoorbeeld opdrachten als de volgende uitvoeren:
git add profiles.yml git commit -m "adding profiles.yml for my Databricks job" git pushKlik op
Werkstromen in de zijbalk van de Databricks-gebruikersinterface.Selecteer de dbt-taak en klik op het tabblad Taken .
Klik in Bron op Bewerken en voer de details van de GitHub-opslagplaats van uw forked jaffle-winkel in.
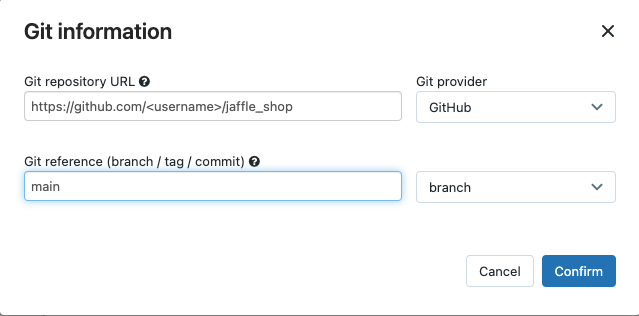
Selecteer geen (handmatig) in SQL Warehouse.
Voer in de map Profielen het relatieve pad in naar de map die het
profiles.ymlbestand bevat. Laat de padwaarde leeg om de standaardmap van de opslagplaats te gebruiken.
(Geavanceerd) Dbt Python-modellen gebruiken in een werkstroom
Notitie
dbt-ondersteuning voor Python-modellen is bèta en vereist dbt 1.3 of hoger.
dbt ondersteunt nu Python-modellen voor specifieke datawarehouses, waaronder Databricks. Met dbt Python-modellen kunt u hulpprogramma's uit het Python-ecosysteem gebruiken om transformaties te implementeren die moeilijk te implementeren zijn met SQL. U kunt een Azure Databricks-taak maken om één taak uit te voeren met uw Dbt Python-model, of u kunt de dbt-taak opnemen als onderdeel van een werkstroom die meerdere taken bevat.
U kunt Geen Python-modellen uitvoeren in een dbt-taak met behulp van een SQL Warehouse. Zie Specifieke datawarehouses in de dbt-documentatie voor meer informatie over het gebruik van dbt Python-modellen met Azure Databricks.
Fouten en probleemoplossing
Er bestaat geen fout in het profielbestand
Foutbericht:
dbt looked for a profiles.yml file in /tmp/.../profiles.yml but did not find one.
Mogelijke oorzaken:
Het profiles.yml bestand is niet gevonden in de opgegeven $PATH. Zorg ervoor dat de hoofdmap van uw dbt-project het bestand profiles.yml bevat.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor