Geavanceerde systemen voor ophalen-Augmented Generation bouwen
In het vorige artikel zijn twee opties besproken voor het bouwen van een 'chat over uw gegevens'-toepassing, een van de eerste gebruiksvoorbeelden voor generatieve AI in bedrijven:
- Ophalen van augmented generation (RAG) die een aanvulling vormt op de LLM-training (Large Language Model) met een database met doorzoekbare artikelen die kunnen worden opgehaald op basis van gelijkenis met de query's van de gebruikers en doorgegeven aan de LLM voor voltooiing.
- Afstemmen, waarmee de training van de LLM wordt uitgebreid om meer te weten te komen over het probleemdomein.
In het vorige artikel werd ook besproken wanneer u elke benadering, pro's en con's van elke benadering en verschillende andere overwegingen moet gebruiken.
In dit artikel wordt RAG uitgebreider besproken, met name al het werk dat nodig is voor het maken van een oplossing die gereed is voor productie.
In het vorige artikel ziet u de stappen of fasen van RAG met behulp van het volgende diagram.
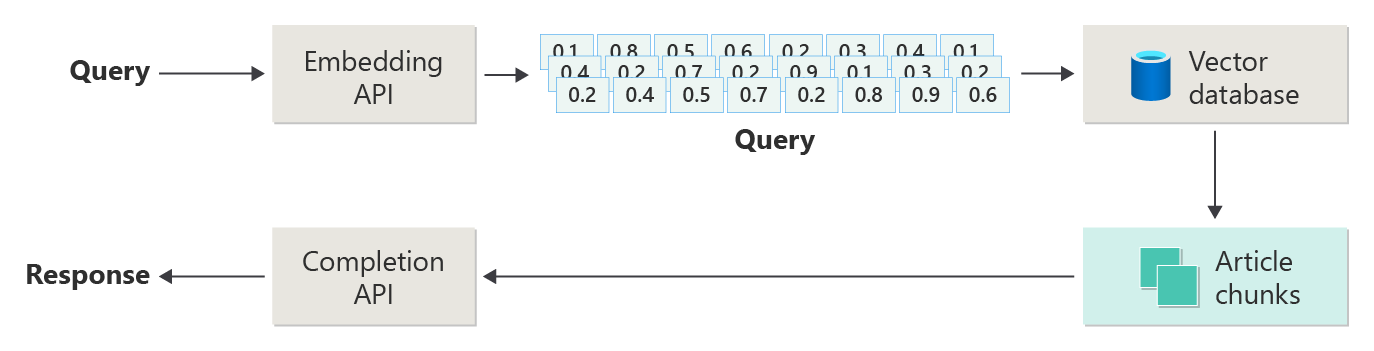
Deze voorstelling is 'naïef RAG' genoemd en is een handige manier om eerst de mechanismen, rollen en verantwoordelijkheden te begrijpen die nodig zijn voor het implementeren van een RAG-chatsysteem.
Een meer echte implementatie heeft echter nog veel meer pre- en postverwerkingsstappen om de artikelen, de query's en de antwoorden voor gebruik voor te bereiden. Het volgende diagram is een realistischer beeld van een RAG, ook wel 'geavanceerde RAG' genoemd.

Dit artikel biedt een conceptueel kader voor het begrijpen van de soorten problemen die vooraf en na verwerking zijn in een echt RAG-chatsysteem, georganiseerd als volgt:
- Opnamefase
- Deductiepijplijnfase
- Evaluatiefase
Als conceptueel overzicht worden de trefwoorden en ideeën aangeboden als context en een uitgangspunt voor verdere verkenning en onderzoek.
Opname
Opname houdt zich voornamelijk bezig met het opslaan van de documenten van uw organisatie op een zodanige manier dat ze eenvoudig kunnen worden opgehaald om de vraag van een gebruiker te beantwoorden. De uitdaging is ervoor te zorgen dat de gedeelten van de documenten die het beste overeenkomen met de query van de gebruiker zich bevinden en worden gebruikt tijdens deductie. Matching wordt voornamelijk bereikt door vectorized embeddings en een cosinus-gelijkeniszoekopdracht. Het wordt echter gefaciliteerd door inzicht te krijgen in de aard van de inhoud (patronen, vorm, enzovoort) en de strategie van de gegevensorganisatie (de structuur van de gegevens wanneer deze worden opgeslagen in de vectordatabase).
Hiervoor moeten ontwikkelaars rekening houden met het volgende:
- Inhoud vooraf verwerken en extraheren
- Segmenteringsstrategie
- Segmenteringsorganisatie
- Strategie bijwerken
Inhoud vooraf verwerken en extraheren
Schone en nauwkeurige inhoud is een van de beste manieren om de algehele kwaliteit van een RAG-chatsysteem te verbeteren. Hiervoor moeten ontwikkelaars beginnen met het analyseren van de vorm en vorm van de documenten die moeten worden geïndexeerd. Voldoen de documenten aan de opgegeven inhoudspatronen, zoals documentatie? Zo niet, welke typen vragen kunnen de documenten beantwoorden?
Ontwikkelaars moeten minimaal stappen maken in de opnamepijplijn om:
- Tekstopmaak standaardiseren
- Speciale tekens verwerken
- Niet-gerelateerde, verouderde inhoud verwijderen
- Account voor versieversies van inhoud
- Account voor inhoudservaring (tabbladen, afbeeldingen, tabellen)
- Metagegevens extraheren
Sommige van deze informatie (zoals bijvoorbeeld metagegevens) kunnen nuttig zijn om bij het document in de vectordatabase te worden bewaard voor gebruik tijdens het ophalen en evalueren in de deductiepijplijn, of in combinatie met het tekstsegment om de vectoring van het segment te overtuigen.
Segmenteringsstrategie
Ontwikkelaars moeten beslissen hoe ze een langer document opsplitsen in kleinere segmenten. Dit kan de relevantie van de aanvullende inhoud die naar de LLM wordt verzonden verbeteren om de query van de gebruiker nauwkeurig te beantwoorden. Bovendien moeten ontwikkelaars nadenken over het gebruik van de segmenten bij het ophalen. Dit is een gebied waar systeemontwerpers wat onderzoek moeten doen naar technieken die in de industrie worden gebruikt, en wat experimenten uitvoeren, zelfs testen in een beperkte capaciteit in hun organisatie.
Ontwikkelaars moeten rekening houden met:
- Optimalisatie van segmentgrootte - Bepaal wat de ideale grootte van het segment is en hoe u een segment aanwijst. Per sectie? Per alinea? Op zin?
- Overlappende en glijdende venstersegmenten - Bepalen hoe de inhoud moet worden verdeeld in afzonderlijke segmenten. Of overlappen de segmenten elkaar? Of beide (schuifvenster)?
- Small2Big : bij het segmenteren op een gedetailleerd niveau als één zin, wordt de inhoud zodanig ingedeeld dat de aangrenzende zinnen of alinea's gemakkelijk kunnen worden gevonden? (Zie 'Segmenteringsorganisatie'.) Als u deze aanvullende informatie opvraagt en aan de LLM levert, kan deze meer context bieden bij het beantwoorden van de query van de gebruiker.
Segmenteringsorganisatie
In een RAG-systeem is de organisatie van gegevens in de vectordatabase cruciaal voor het efficiënt ophalen van relevante informatie om het generatieproces te verbeteren. Hier volgen de typen indexerings- en ophaalstrategieën die ontwikkelaars kunnen overwegen:
- Hiërarchische indexen : deze benadering omvat het maken van meerdere lagen van indexen, waarbij een index op het hoogste niveau (samenvattingsindex) de zoekruimte snel beperkt tot een subset van mogelijk relevante segmenten en een index op het tweede niveau (segmentenindex) meer gedetailleerde aanwijzingen biedt voor de werkelijke gegevens. Deze methode kan het ophaalproces aanzienlijk versnellen, omdat het aantal vermeldingen dat in de gedetailleerde index moet worden gescand, vermindert door eerst de samenvattingsindex te filteren.
- Gespecialiseerde indexen: gespecialiseerde indexen , zoals op grafieken of relationele databases, kunnen worden gebruikt, afhankelijk van de aard van de gegevens en de relaties tussen segmenten. Bijvoorbeeld:
- Indexen op basis van grafieken zijn handig wanneer de segmenten onderling verbonden informatie of relaties hebben die het ophalen kunnen verbeteren, zoals bronvermeldingsnetwerken of kennisgrafieken.
- Relationele databases kunnen effectief zijn als de segmenten in tabelvorm zijn gestructureerd, waarbij SQL-query's kunnen worden gebruikt om gegevens te filteren en op te halen op basis van specifieke kenmerken of relaties.
- Hybride indexen : een hybride benadering combineert meerdere indexeringsstrategieën om de sterke punten van elk van beide te benutten. Ontwikkelaars kunnen bijvoorbeeld een hiërarchische index gebruiken voor het initiële filteren en een index op basis van grafieken om relaties tussen segmenten dynamisch te verkennen tijdens het ophalen.
Optimalisatie van uitlijning
Om de relevantie en nauwkeurigheid van de opgehaalde segmenten te verbeteren, kan het handig zijn om ze nauwkeuriger af te stemmen op de typen vragen of query's die ze moeten beantwoorden. Eén strategie om dit te bereiken is het genereren en invoegen van een hypothetische vraag voor elk segment dat aangeeft welke vraag het segment het meest geschikt is om te beantwoorden. Dit helpt op verschillende manieren:
- Verbeterde afstemming: tijdens het ophalen kan het systeem de binnenkomende query vergelijken met deze hypothetische vragen om de beste overeenkomst te vinden, waardoor de relevantie van de opgehaalde segmenten wordt verbeterd.
- Trainingsgegevens voor Machine Learning-modellen: deze combinaties van vragen en segmenten kunnen dienen als trainingsgegevens om de machine learning-modellen die onder het RAG-systeem liggen te verbeteren, zodat u kunt leren welke typen vragen het beste worden beantwoord door welke segmenten.
- Direct Query Handling: Als een echte gebruikersquery nauw overeenkomt met een hypothetische vraag, kan het systeem snel het bijbehorende segment ophalen en gebruiken, waardoor de reactietijd wordt versneld.
De hypothetische vraag van elk segment fungeert als een soort 'label' dat het ophaalalgoritme begeleidt, waardoor het beter gericht en contextbewuster wordt. Dit is handig in scenario's waarin de segmenten betrekking hebben op een breed scala aan onderwerpen of soorten informatie.
Strategieën bijwerken
Als uw organisatie documenten moet indexeren die regelmatig worden bijgewerkt, is het essentieel om een bijgewerkte verzameling te onderhouden om ervoor te zorgen dat het ophalende onderdeel (de logica in het systeem dat verantwoordelijk is voor het uitvoeren van de query op de vectordatabase en het retourneren van de resultaten) toegang heeft tot de meest recente informatie. Hier volgen enkele strategieën voor het bijwerken van de vectordatabase in dergelijke systemen:
- Incrementele updates:
- Regelmatige intervallen: updates plannen met regelmatige tussenpozen (bijvoorbeeld dagelijks, wekelijks) afhankelijk van de frequentie van documentwijzigingen. Deze methode zorgt ervoor dat de database periodiek wordt vernieuwd.
- Updates op basis van triggers: implementeer een systeem waarin het opnieuw indexeren van updates wordt geactiveerd. Zo kan elke wijziging of toevoeging van een document automatisch een herindexering van de betreffende secties initiëren.
- Gedeeltelijke updates:
- Selectief opnieuw indexeren: in plaats van de hele database opnieuw te indexeren, moet u alleen de delen van het corpus die zijn gewijzigd selectief bijwerken. Dit kan efficiënter zijn dan volledig opnieuw indexeren, met name voor grote gegevenssets.
- Delta-codering: Sla alleen de verschillen op tussen de bestaande documenten en de bijgewerkte versies. Deze aanpak vermindert de belasting van gegevensverwerking door te voorkomen dat ongewijzigde gegevens moeten worden verwerkt.
- Versiebeheer:
- Momentopnamen: versies van het document op verschillende tijdstippen onderhouden. Hierdoor kan het systeem indien nodig terugkeren of verwijzen naar eerdere versies en een back-upmechanisme bieden.
- Documentversiebeheer: gebruik een versiebeheersysteem om wijzigingen in documenten systematisch bij te houden. Dit helpt bij het bijhouden van de geschiedenis van wijzigingen en kan het updateproces vereenvoudigen.
- Realtime updates:
- Stroomverwerking: gebruik technologieën voor stroomverwerking om de vectordatabase in realtime bij te werken wanneer er wijzigingen worden aangebracht in de documenten. Dit kan essentieel zijn voor toepassingen waarbij de tijdigheid van informatie essentieel is.
- Live query's uitvoeren: in plaats van alleen te vertrouwen op vooraf geïndexeerde vectoren, implementeert u een mechanisme om livegegevens op te vragen voor de meest recente antwoorden, mogelijk gecombineerd met resultaten in de cache voor efficiëntie.
- Optimalisatietechnieken:
- Batchverwerking: verzamel wijzigingen en verwerkt deze in batches om het gebruik van resources te optimaliseren en de overhead te verminderen die wordt veroorzaakt door frequente updates.
- Hybride benaderingen: combineer verschillende strategieën, zoals het gebruik van incrementele updates voor kleine wijzigingen en volledige herindexering voor grote updates of structurele wijzigingen in het documentlichaam.
Het kiezen van de juiste updatestrategie of combinatie van strategieën is afhankelijk van specifieke vereisten, zoals de grootte van het document, de frequentie van updates, de behoefte aan realtime gegevens en beschikbaarheid van resources. Elke benadering heeft zijn afwegingen in termen van complexiteit, kosten en updatelatentie, dus het is essentieel om deze factoren te evalueren op basis van de specifieke behoeften van de toepassing.
Deductiepijplijn
Nu de artikelen zijn gesegmenteerd, gevectoriseerd en opgeslagen in een vectordatabase, wordt de focus verplaatst naar uitdagingen bij voltooiing.
- Is de query van de gebruiker zodanig geschreven dat de resultaten worden opgehaald uit het systeem waarnaar de gebruiker op zoek is?
- Schendt de query van de gebruiker een van onze beleidsregels?
- Hoe herschrijven we de query van de gebruiker om de kans op het vinden van dichtstbijzijnde overeenkomsten in de vectordatabase te verbeteren?
- Hoe evalueren we de queryresultaten om ervoor te zorgen dat de artikelsegmenten zijn uitgelijnd op de query?
- Hoe evalueren en wijzigen we de queryresultaten voordat ze worden doorgegeven aan de LLM om ervoor te zorgen dat de meest relevante details worden opgenomen in de voltooiing van de LLM?
- Hoe evalueren we het antwoord van de LLM om ervoor te zorgen dat de voltooiing van de LLM de oorspronkelijke query van de gebruiker beantwoordt?
- Hoe zorgen we ervoor dat het antwoord van de LLM voldoet aan ons beleid?
Zoals u kunt zien, zijn er veel taken waarmee ontwikkelaars rekening moeten houden, meestal in de vorm van:
- Invoer vooraf verwerken om de kans op het verkrijgen van de gewenste resultaten te optimaliseren
- Uitvoer na verwerking om de gewenste resultaten te garanderen
Houd er rekening mee dat de volledige deductiepijplijn in realtime wordt uitgevoerd. Hoewel er geen goede manier is om de logica te ontwerpen die de stappen vóór en na de verwerking uitvoert, is het waarschijnlijk een combinatie van programmeerlogica en aanvullende aanroepen naar een LLM. Een van de belangrijkste overwegingen is dan de afweging tussen het bouwen van de meest nauwkeurige en compatibele pijplijn en de kosten en latentie die nodig zijn om dit te laten gebeuren.
Laten we eens kijken naar elke fase om specifieke strategieën te identificeren.
Stappen voor het vooraf verwerken van query's
De voorverwerking van query's vindt direct plaats nadat uw gebruiker de query heeft verzonden, zoals wordt weergegeven in dit diagram:

Het doel van deze stappen is om ervoor te zorgen dat de gebruiker vragen stelt binnen het bereik van ons systeem (en niet probeert om het systeem te "jailbreaken" om het iets onbedoelds te laten doen) en de query van de gebruiker voorbereidt om de kans te vergroten dat het de best mogelijke artikelsegmenten vindt met behulp van de cosinus-gelijkenis / "dichtstbijzijnde buur" zoekopdracht.
Beleidscontrole : deze stap kan logica omvatten die bepaalde inhoud identificeert, verwijdert, markeert of afwijst. Enkele voorbeelden zijn het verwijderen van persoonsgegevens, het verwijderen van expletives en het identificeren van 'jailbreak'-pogingen. Jailbreaking verwijst naar de methoden die gebruikers kunnen gebruiken om de ingebouwde veiligheids-, ethische of operationele richtlijnen van het model te omzeilen of te manipuleren.
Query's opnieuw schrijven : dit kan alles zijn van het uitvouwen van acroniemen en het verwijderen van een taal om de vraag opnieuw te formuleren om deze abstracter te stellen om concepten en principes op hoog niveau te extraheren ('step-back prompting').
Een variatie op het terugvragen van stappen is hypothetische documentinsluitingen (HyDE) die gebruikmaakt van de LLM om de vraag van de gebruiker te beantwoorden, een insluiting voor dat antwoord maakt (het hypothetische document insluiten) en dat insluiten wordt gebruikt om een zoekopdracht uit te voeren op de vectordatabase.
Subquery's
Deze verwerkingsstap betreft de oorspronkelijke query. Als de oorspronkelijke query lang en complex is, kan het handig zijn om deze programmatisch op te splitsen in verschillende kleinere query's en vervolgens alle antwoorden te combineren.
Denk bijvoorbeeld aan een vraag met betrekking tot wetenschappelijke ontdekkingen, met name op het gebied van natuurkunde. De query van de gebruiker kan zijn: 'Wie heeft er meer significante bijdragen geleverd aan moderne natuurkunde, Albert Einstein of Niels Bohr?'
Deze query kan rechtstreeks worden verwerkt omdat 'significante bijdragen' subjectief en multifaceted kunnen zijn. Als u deze opsplitst in subquery's, kunt u deze beter beheren:
- Subquery 1: "Wat zijn de belangrijkste bijdragen van Albert Einstein aan moderne natuurkunde?"
- Subquery 2: "Wat zijn de belangrijkste bijdragen van Niels Bohr aan moderne natuurkunde?"
De resultaten van deze subquery's zouden de belangrijkste theorieën en ontdekkingen van elke fysicus beschrijven. Voorbeeld:
- Voor Einstein kunnen bijdragen de theorie van relativiteit, het foto-elektrische effect en E=mc^2 omvatten.
- Voor Bohr kunnen bijdragen zijn model van het waterstofatomen, zijn werk aan kwantummechanica en zijn principe van complementariteit omvatten.
Zodra deze bijdragen zijn beschreven, kunnen ze worden beoordeeld om het volgende te bepalen:
- Subquery 3: "Hoe hebben de theorieën van Einstein invloed op de ontwikkeling van moderne natuurkunde?"
- Subquery 4: "Hoe hebben Bohr's theorieën invloed op de ontwikkeling van moderne natuurkunde?"
Deze subquery's zouden de invloed van het werk van elke wetenschapper op het veld onderzoeken, zoals hoe de theorieën van Newton leidden tot verbeteringen in cosmologie en kwantumtheorie, en hoe bohr's werk heeft bijgedragen aan het begrip van atomische structuur en kwantummechanica.
Door de resultaten van deze subquery's te combineren, kan het taalmodel een uitgebreider antwoord vormen met betrekking tot wie aanzienlijke bijdragen heeft geleverd aan moderne natuurkunde, op basis van de omvang en impact van hun theoretische ontwikkelingen. Deze methode vereenvoudigt de oorspronkelijke complexe query door te werken met specifiekere, beantwoordbare onderdelen en deze bevindingen vervolgens samen te stellen in een coherent antwoord.
Queryrouter
Het is mogelijk dat uw organisatie besluit om het inhoudsbestand te verdelen in meerdere vectorarchieven of volledige ophaalsystemen. In dat geval kunnen ontwikkelaars een queryrouter gebruiken. Dit is een mechanisme dat op intelligente wijze bepaalt welke indexen of ophaalengines moeten worden gebruikt op basis van de opgegeven query. De primaire functie van een queryrouter is het optimaliseren van het ophalen van gegevens door de meest geschikte database of index te selecteren die de beste antwoorden op een specifieke query kan bieden.
De queryrouter werkt meestal op een punt nadat de query is geformuleerd door de gebruiker, maar voordat deze naar alle ophaalsystemen wordt verzonden. Hier volgt een vereenvoudigde werkstroom:
- Queryanalyse: De LLM of een ander onderdeel analyseert de binnenkomende query om inzicht te krijgen in de inhoud, context en het type informatie dat waarschijnlijk nodig is.
- Indexselectie: Op basis van de analyse selecteert de queryrouter een of meer van mogelijk verschillende beschikbare indexen. Elke index kan worden geoptimaliseerd voor verschillende typen gegevens of query's. Sommige kunnen bijvoorbeeld geschikter zijn voor feitelijke query's, terwijl anderen excelleren in het leveren van meningen of subjectieve inhoud.
- Query verzenden: de query wordt vervolgens verzonden naar de geselecteerde index.
- Resultatenaggregatie: antwoorden van de geselecteerde indexen worden opgehaald en mogelijk geaggregeerd of verder verwerkt om een uitgebreid antwoord te vormen.
- Antwoordgeneratie: de laatste stap omvat het genereren van een coherent antwoord op basis van de opgehaalde informatie, waarbij mogelijk inhoud uit meerdere bronnen wordt geïntegreerd of gesynthetaliseerd.
Uw organisatie kan meerdere ophaalengines of indexen gebruiken voor de volgende gebruiksscenario's:
- Specialisatie van gegevenstypen: sommige indexen zijn mogelijk gespecialiseerd in nieuwsartikelen, andere in academische documenten en nog andere in algemene webinhoud of specifieke databases, zoals die voor medische of juridische informatie.
- Optimalisatie van querytypen: bepaalde indexen kunnen worden geoptimaliseerd voor snelle feitelijke zoekacties (bijvoorbeeld datums, gebeurtenissen), terwijl andere mogelijk beter zijn voor complexe redeneringstaken of query's waarvoor grondige domeinkennis is vereist.
- Algoritmen verschillen: verschillende algoritmen voor ophalen kunnen worden gebruikt in verschillende engines, zoals op vector gebaseerde overeenkomsten, traditionele zoekopdrachten op basis van trefwoorden of geavanceerdere semantische begripsmodellen.
Stel dat een RAG-systeem wordt gebruikt in een medische adviescontext. Het systeem heeft toegang tot meerdere indexen:
- Een medische onderzoeksdocumentindex die is geoptimaliseerd voor gedetailleerde en technische uitleg.
- Een klinische casestudy-index die praktijkvoorbeelden van symptomen en behandelingen biedt.
- Een algemene index voor gezondheidsinformatie voor basisquery's en informatie over de volksgezondheid.
Als een gebruiker een technische vraag stelt over de chemische effecten van een nieuw medicijn, kan de queryrouter prioriteit geven aan de medische onderzoekspapierindex vanwege de diepte en technische focus. Voor een vraag over typische symptomen van een veelvoorkomende ziekte, kan de algemene gezondheidsindex echter worden gekozen voor zijn brede en gemakkelijk begrijpelijke inhoud.
Verwerkingsstappen na het ophalen
Na het ophalen vindt de verwerking plaats nadat het retriever-onderdeel relevante inhoudssegmenten ophaalt uit de vectordatabase, zoals wordt weergegeven in het diagram:

Wanneer de chunks voor kandidaat-inhoud zijn opgehaald, moeten de volgende stappen worden uitgevoerd om te controleren of de artikelsegmenten nuttig zijn bij het uitbreiden van de LLM-prompt en vervolgens beginnen met het voorbereiden van de prompt die moet worden gepresenteerd aan de LLM.
Ontwikkelaars moeten rekening houden met verschillende aspecten van de prompt. Een prompt die te veel aanvullende informatie bevat en sommige (mogelijk de belangrijkste informatie) kan worden genegeerd. Op dezelfde manier kan een prompt die irrelevante informatie bevat, onbedoeld van invloed zijn op het antwoord.
Een andere overweging is de naald in een hooistackprobleem , een term die verwijst naar een bekende quirk van sommige LLM's waarbij de inhoud aan het begin en einde van een prompt meer gewicht heeft voor de LLM dan de inhoud in het midden.
Ten slotte moet de maximale contextvensterlengte van de LLM en het aantal tokens dat nodig is om buitengewoon lange prompts te voltooien (vooral bij het omgaan met query's op schaal) worden overwogen.
Om deze problemen op te lossen, kan een pijplijn voor het ophalen van de verwerkingspijplijn de volgende stappen bevatten:
- Resultaten filteren: in deze stap zorgen ontwikkelaars ervoor dat de artikelsegmenten die door de vectordatabase worden geretourneerd, relevant zijn voor de query. Als dit niet het resultaat is, wordt het resultaat genegeerd bij het opstellen van de prompt voor de LLM.
- Opnieuw rangschikken- Rangschikking van de artikelsegmenten die zijn opgehaald uit het vectorarchief om ervoor te zorgen dat relevante details zich in de buurt van de randen (begin en einde) van de prompt bevinden.
- Promptcompressie : gebruik van een klein, goedkoop model dat is ontworpen om meerdere artikelsegmenten te combineren en samen te vatten in één, gecomprimeerde prompt voordat deze naar de LLM wordt verzonden.
Verwerkingsstappen na voltooiing
Verwerking na voltooiing vindt plaats nadat de query van de gebruiker en alle inhoudssegmenten naar de LLM zijn verzonden, zoals wordt weergegeven in het volgende diagram:

Zodra de prompt is voltooid door de LLM, is het tijd om de voltooiing te valideren om ervoor te zorgen dat het antwoord juist is. Een verwerkingspijplijn na voltooiing kan de volgende stappen bevatten:
- Feitencontrole - Dit kan veel vormen aannemen, maar de bedoeling is om specifieke claims te identificeren die in het artikel worden gepresenteerd als feiten en vervolgens om die feiten op nauwkeurigheid te controleren. Als de stap voor het controleren van feiten mislukt, kan het handig zijn om de LLM opnieuw op te vragen in de hoop een beter antwoord te krijgen of een foutbericht te retourneren aan de gebruiker.
- Beleidscontrole : dit is de laatste verdedigingslinie om ervoor te zorgen dat antwoorden geen schadelijke inhoud bevatten, of het nu gaat om de gebruiker of de organisatie.
Beoordeling
Het evalueren van de resultaten van een niet-deterministisch systeem is niet zo eenvoudig als eenheids- of integratietests waarmee de meeste ontwikkelaars bekend zijn. Er zijn verschillende factoren om rekening mee te houden:
- Zijn gebruikers tevreden over de resultaten die ze krijgen?
- Krijgen gebruikers nauwkeurige antwoorden op hun vragen?
- Hoe leggen we feedback van gebruikers vast? Zijn er beleidsregels die bepalen welke gegevens we kunnen verzamelen over gebruikersgegevens?
- Voor diagnose over onbevredigende reacties hebben we inzicht in al het werk dat is uitgevoerd om de vraag te beantwoorden? Houden we een logboek bij van elke fase in de deductiepijplijn van invoer en uitvoer, zodat we hoofdoorzaakanalyse kunnen uitvoeren?
- Hoe kunnen we wijzigingen aanbrengen in het systeem zonder regressie of afname van de resultaten?
Feedback van gebruikers vastleggen en erop reageren
Zoals eerder vermeld, moeten ontwikkelaars mogelijk samenwerken met het privacyteam van hun organisatie om feedback vast te leggen mechanismen en telemetrie, logboekregistratie, enzovoort, om forensische en hoofdoorzaakanalyse in te schakelen voor een bepaalde querysessie.
De volgende stap is het ontwikkelen van een evaluatiepijplijn. De behoefte aan een evaluatiepijplijn komt voort uit de complexiteit en de tijdintensieve aard van het analyseren van exacte feedback en de hoofdoorzaken van de antwoorden van een AI-systeem. Deze analyse is van cruciaal belang omdat het elke reactie onderzoekt om te begrijpen hoe de AI-query de resultaten heeft geproduceerd, de geschiktheid van de inhoudssegmenten controleert die worden gebruikt uit documentatie en de strategieën die worden gebruikt bij het opdelen van deze documenten.
Daarnaast moet er rekening worden gehouden met eventuele extra pre- of naverwerkingsstappen die de resultaten kunnen verbeteren. Met dit gedetailleerde onderzoek worden vaak hiaten in de inhoud ontdekt, met name wanneer er geen geschikte documentatie bestaat als reactie op de query van een gebruiker.
Het bouwen van een evaluatiepijplijn wordt daarom essentieel om de schaal van deze taken effectief te beheren. Een efficiënte pijplijn maakt gebruik van aangepaste hulpprogramma's om metrische gegevens te evalueren die de kwaliteit van de antwoorden van de AI benaderen. Dit systeem zou het proces stroomlijnen om te bepalen waarom een specifiek antwoord werd gegeven op de vraag van een gebruiker, welke documenten werden gebruikt om dat antwoord te genereren en de effectiviteit van de deductiepijplijn die de query's verwerkt.
Gouden gegevensset
Een strategie voor het evalueren van de resultaten van een niet-deterministisch systeem zoals een RAG-chatsysteem is het implementeren van een 'gouden gegevensset'. Een gouden gegevensset is een gecureerde set vragen met goedgekeurde antwoorden, metagegevens (zoals onderwerp en type vraag), verwijzingen naar brondocumenten die kunnen dienen als grondwaar voor antwoorden en zelfs variaties (verschillende formuleringen om de diversiteit vast te leggen van hoe gebruikers dezelfde vragen kunnen stellen).
De 'gouden gegevensset' vertegenwoordigt het 'beste scenario' en stelt ontwikkelaars in staat om het systeem te evalueren om te zien hoe goed het presteert en regressietests uit te voeren bij het implementeren van nieuwe functies of updates.
Schade beoordelen
Schademodellering is een methodologie die is gericht op het voorzien van potentiële schade, het opsporen van tekortkomingen in een product dat risico's kan vormen voor individuen en het ontwikkelen van proactieve strategieën om dergelijke risico's te beperken.
Het hulpprogramma dat is ontworpen voor het beoordelen van de impact van technologie, met name AI-systemen, zou verschillende belangrijke onderdelen bevatten op basis van de principes van schademodellering, zoals beschreven in de verstrekte resources.
Belangrijke functies van een hulpprogramma voor evaluatie van schadelijke effecten kunnen zijn:
Identificatie van belanghebbenden: Het hulpprogramma helpt gebruikers bij het identificeren en categoriseren van verschillende belanghebbenden die worden beïnvloed door de technologie, waaronder directe gebruikers, indirect betrokken partijen en andere entiteiten, zoals toekomstige generaties of niet-menselijke factoren zoals milieukwesties (.
Schadecategorieën en beschrijvingen: het zou een uitgebreide lijst met mogelijke schade omvatten, zoals privacyverlies, emotionele nood of economische exploitatie. Het hulpprogramma kan de gebruiker begeleiden door verschillende scenario's die illustreren hoe de technologie deze schade kan veroorzaken, waardoor zowel beoogde als onbedoelde gevolgen kunnen worden geëvalueerd.
Ernst- en waarschijnlijkheidsevaluaties: met het hulpprogramma kunnen gebruikers de ernst en waarschijnlijkheid van elke geïdentificeerde schade beoordelen, zodat ze prioriteit kunnen geven aan welke problemen eerst moeten worden opgelost. Dit kan bestaan uit kwalitatieve evaluaties en kan worden ondersteund door gegevens waar beschikbaar.
Risicobeperkingsstrategieën: bij het identificeren en evalueren van schade zou het hulpprogramma potentiële risicobeperkingsstrategieën voorstellen. Dit kan wijzigingen in het systeemontwerp, meer waarborgen of alternatieve technologische oplossingen omvatten die geïdentificeerde risico's minimaliseren.
Feedbackmechanismen: het hulpprogramma moet mechanismen bevatten voor het verzamelen van feedback van belanghebbenden, zodat het evaluatieproces voor schadelijke effecten dynamisch en responsief is op nieuwe informatie en perspectieven.
Documentatie en rapportage: Om te helpen bij transparantie en verantwoording, zou het hulpprogramma het maken van gedetailleerde rapporten vergemakkelijken waarin het evaluatieproces, bevindingen en acties worden beschreven die worden ondernomen om potentiële risico's te beperken.
Deze functies zouden niet alleen helpen bij het identificeren en beperken van risico's, maar ook bij het ontwerpen van meer ethische en verantwoorde AI-systemen door vanaf het begin een breed scala aan effecten te overwegen.
Zie voor meer informatie:
De beveiliging testen en controleren
In dit artikel worden verschillende processen beschreven die zijn gericht op het beperken van de mogelijkheid dat het RAG-chatsysteem kan worden misbruikt of gecompromitteerd. Red-teaming speelt een cruciale rol om ervoor te zorgen dat de oplossingen effectief zijn. Red-teaming omvat het simuleren van de acties van een kwaadwillende persoon die gericht is op de toepassing om potentiële zwakke plekken of beveiligingsproblemen te ontdekken. Deze aanpak is vooral essentieel bij het aanpakken van het aanzienlijke risico op jailbreaking.
Om de beveiliging van een RAG-chatsysteem effectief te testen en te controleren, moeten ontwikkelaars deze systemen grondig beoordelen in verschillende scenario's waarin deze richtlijnen kunnen worden getest. Dit zorgt niet alleen voor robuustheid, maar helpt ook bij het verfijnen van de reacties van het systeem om strikt te voldoen aan gedefinieerde ethische normen en operationele procedures.
Laatste overwegingen die van invloed kunnen zijn op uw ontwerpbeslissingen voor toepassingen
Hier volgt een korte lijst met zaken die u kunt overwegen en andere punten uit dit artikel die van invloed zijn op uw beslissingen over het ontwerp van uw toepassing:
- Bevestig de niet-deterministische aard van generatieve AI in uw ontwerp, planning voor variabiliteit in uitvoer en het instellen van mechanismen om consistentie en relevantie in reacties te garanderen.
- Beoordeel de voordelen van het vooraf verwerken van gebruikersprompts tegen de mogelijke toename van latentie en kosten. Het vereenvoudigen of wijzigen van prompts voordat het indienen de reactiekwaliteit kan verbeteren, maar kan complexiteit en tijd toevoegen aan de reactiecyclus.
- Onderzoek strategieën voor het parallelliseren van LLM-aanvragen om de prestaties te verbeteren. Deze aanpak kan latentie verminderen, maar vereist zorgvuldig beheer om verhoogde complexiteit en mogelijke gevolgen voor de kosten te voorkomen.
Als u direct wilt experimenteren met het bouwen van een generatieve AI-oplossing, raden we u aan om aan de slag te gaan met de chat met behulp van uw eigen gegevensvoorbeeld voor Python. Er zijn ook versies van de zelfstudie beschikbaar in .NET, Java en JavaScript.