Federatie in meerdere sites en regio's
Voor veel geavanceerde oplossingen moeten dezelfde gebeurtenisstromen beschikbaar worden gesteld voor gebruik op meerdere locaties of moeten gebeurtenisstromen worden verzameld op meerdere locaties en vervolgens worden samengevoegd tot een specifieke locatie voor verbruik. Er is ook vaak behoefte aan het verrijken of verminderen van gebeurtenisstromen of het uitvoeren van conversies van gebeurtenisindelingen, ook voor binnen één regio en oplossing.
Praktisch betekent dit dat uw oplossing meerdere Event Hubs onderhoudt, vaak in verschillende regio's en Event Hubs-naamruimten en vervolgens gebeurtenissen tussen deze regio's repliceert. U kunt ook gebeurtenissen uitwisselen met bronnen en doelen zoals Azure Service Bus, Azure IoT Hub of Apache Kafka.
Door meerdere actieve Event Hubs in verschillende regio's te onderhouden, kunnen clients er ook tussen kiezen en schakelen als hun inhoud wordt samengevoegd, waardoor het algehele systeem toleranter wordt tegen regionale beschikbaarheidsproblemen.
In dit hoofdstuk 'Federatie' worden federatiepatronen uitgelegd en wordt uitgelegd hoe u deze patronen kunt realiseren met behulp van serverloze Azure Stream Analytics of de Azure Functions-runtimes , met de mogelijkheid om uw eigen transformatie- of verrijkingscode rechtstreeks in het gebeurtenisstroompad te hebben.
Federatiepatronen
Er zijn veel mogelijke redenen waarom u gebeurtenissen tussen verschillende Event Hubs of andere bronnen en doelen wilt verplaatsen, en we inventariseren de belangrijkste patronen in deze sectie en verwijzen ook naar gedetailleerdere richtlijnen voor het respectieve patroon.
- Tolerantie voor regionale beschikbaarheidsgebeurtenissen
- Optimalisatie van latentie
- Validatie, reductie en verrijking
- Integratie met analyseservices
- Consolidatie en normalisatie van gebeurtenisstromen
- Het splitsen en routeren van gebeurtenisstromen
- Logboekprojecties
Tolerantie voor regionale beschikbaarheidsgebeurtenissen
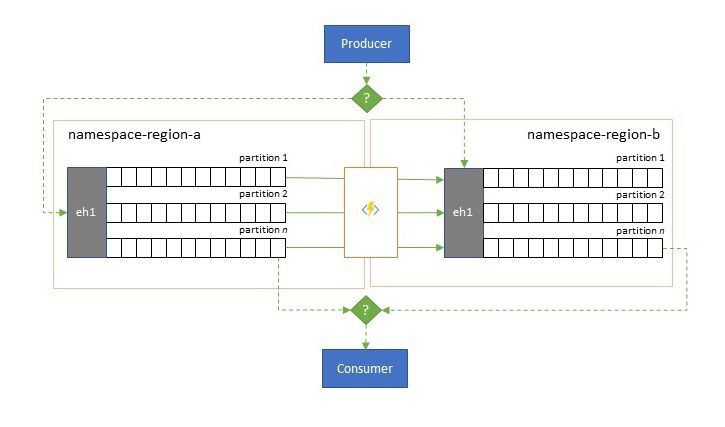
Hoewel maximale beschikbaarheid en betrouwbaarheid de belangrijkste operationele prioriteiten zijn voor Event Hubs, zijn er echter veel manieren waarop een producent of consument kan worden verhinderd om te praten met de toegewezen 'primaire' Event Hubs vanwege netwerk- of naamomzettingsproblemen, of waarbij een Event Hubs inderdaad tijdelijk niet reageert of fouten retourneert.
Dergelijke omstandigheden zijn niet 'rampzalig' zodat u de regionale implementatie helemaal wilt afbreken, zoals u in een noodherstelsituatie zou kunnen doen, maar het bedrijfsscenario van sommige toepassingen kan al worden beïnvloed door beschikbaarheidsgebeurtenissen die niet langer dan een paar minuten of zelfs seconden duren.
Er zijn twee fundamentele patronen om dergelijke scenario's aan te pakken:
- Het replicatiepatroon gaat over het repliceren van de inhoud van een primaire Event Hubs naar een secundaire Event Hubs, waarbij de primaire Event Hubs doorgaans door de toepassing wordt gebruikt voor zowel het produceren als gebruiken van gebeurtenissen en het secundaire als een terugvaloptie voor het geval de primaire Event Hubs niet meer beschikbaar is. Omdat replicatie unidirectioneel is, zorgt een overschakeling van zowel producenten als consumenten van een niet-beschikbare primaire naar de secundaire bron ervoor dat de oude primaire niet langer nieuwe gebeurtenissen ontvangt en daarom niet langer actueel is. Pure replicatie is daarom alleen geschikt voor failoverscenario's in één richting. Zodra de failover is uitgevoerd, wordt de oude primaire versie afgelaten en moeten er nieuwe secundaire Event Hubs worden gemaakt in een andere doelregio.
- Het samenvoegpatroon breidt het replicatiepatroon uit door een continue samenvoeging van de inhoud van twee of meer Event Hubs uit te voeren. Elke gebeurtenis die oorspronkelijk is geproduceerd in een van de Event Hubs die in het schema is opgenomen, wordt gerepliceerd naar de andere Event Hubs. Wanneer gebeurtenissen worden gerepliceerd, worden ze geannoteerd, zodat ze vervolgens worden genegeerd door het replicatieproces van het replicatiedoel. De resultaten van het gebruik van het samenvoegpatroon zijn twee of meer Event Hubs die dezelfde set gebeurtenissen op een uiteindelijk consistente manier bevatten.
In beide gevallen is de inhoud van de Event Hubs niet identiek. Gebeurtenissen van elke producent en gegroepeerd op dezelfde partitiesleutel worden weergegeven in dezelfde relatieve volgorde als oorspronkelijk verzonden, maar de absolute volgorde van gebeurtenissen kan verschillen. Dit geldt met name voor scenario's waarin het aantal partities van bron- en doelgebeurtenissen verschilt, wat wenselijk is voor verschillende uitgebreide patronen die hier worden beschreven. Een splitser of router kan een segment verkrijgen van een veel grotere Event Hubs met honderden partities en trechter in een kleinere Event Hubs met slechts een handvol partities, geschikter voor het verwerken van de subset met beperkte verwerkingsresources. Een samenvoeging kan daarentegen leiden tot trechtergegevens van verschillende kleinere Event Hubs in één, grotere Event Hubs met meer partities om te voldoen aan de geconsolideerde doorvoer- en verwerkingsbehoeften.
Het criterium voor het bijeenhouden van gebeurtenissen is de partitiesleutel en niet de oorspronkelijke partitie-id. Verdere overwegingen over relatieve volgorde en het uitvoeren van een failover van de ene Event Hubs naar de volgende zonder dat u afhankelijk bent van hetzelfde bereik van stroomverschuivingen, wordt besproken in de beschrijving van het replicatiepatroon .
Richtlijnen:
Optimalisatie van latentie
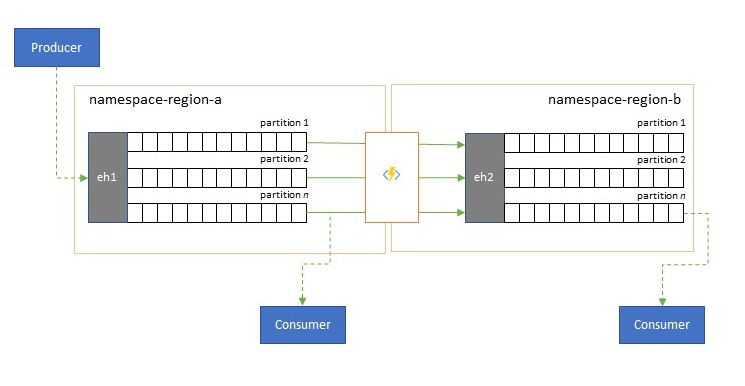
Gebeurtenisstromen worden eenmaal geschreven door producenten, maar kunnen een willekeurig aantal keren worden gelezen door gebeurtenisgebruikers. Voor scenario's waarbij een gebeurtenisstroom in een regio wordt gedeeld door meerdere consumenten en herhaaldelijk moet worden geopend tijdens analyseverwerking die zich in een andere regio bevindt, of met alle vereisten die gelijktijdige consumenten zouden veroorzaken, kan het nuttig zijn om een kopie van de gebeurtenisstroom in de buurt van de analyseprocessor te plaatsen om de retourlatentie te verminderen.
Goede voorbeelden voor wanneer replicatie de voorkeur moet krijgen boven het gebruik van gebeurtenissen op afstand vanuit verschillende regio's, zijn met name die waar de regio's zich uiterst ver van elkaar bevinden, bijvoorbeeld Europa en Australië bijna antipodes, geografisch en netwerklatenties kunnen gemakkelijk groter zijn dan 250 ms voor elke retour. U kunt de snelheid van het licht niet versnellen, maar u kunt het aantal retouren met hoge latentie verminderen om met gegevens te communiceren.
Richtlijnen:
Validatie, reductie en verrijking
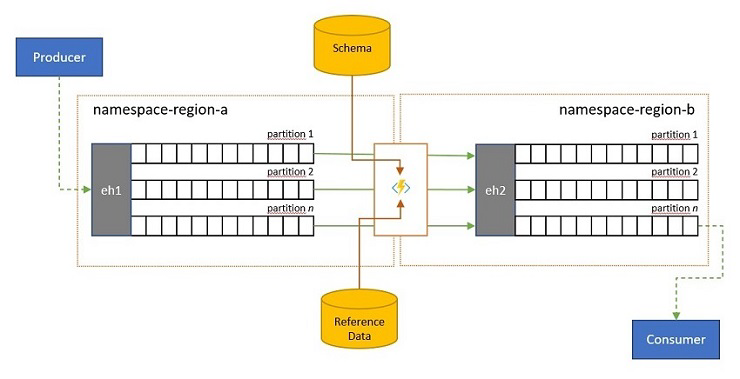
Gebeurtenisstromen kunnen worden verzonden naar een Event Hubs door clients buiten uw eigen oplossing. Dergelijke gebeurtenisstromen kunnen vereisen dat extern ingediende gebeurtenissen worden gecontroleerd op naleving van een bepaald schema en dat niet-compatibele gebeurtenissen worden verwijderd.
In scenario's waarin clients zeer bandbreedtebeperking hebben, omdat dit het geval is in veel scenario's met internet of dingen met bandbreedte met datalimiet, of wanneer gebeurtenissen oorspronkelijk worden verzonden via niet-IP-netwerken met beperkte pakketgrootten, moeten de gebeurtenissen mogelijk worden verrijkt met referentiegegevens om verdere context toe te voegen voor gebruik door downstream gebeurtenisprocessors.
In andere gevallen, met name wanneer streams worden geconsolideerd, moeten de gebeurtenisgegevens mogelijk in complexiteit of een enorme omvang worden verminderd door enige details weg te laten.
Een van deze bewerkingen kan optreden als onderdeel van replicatie, consolidatie of samenvoegingsstromen.
Richtlijnen:
Integratie met analyseservices
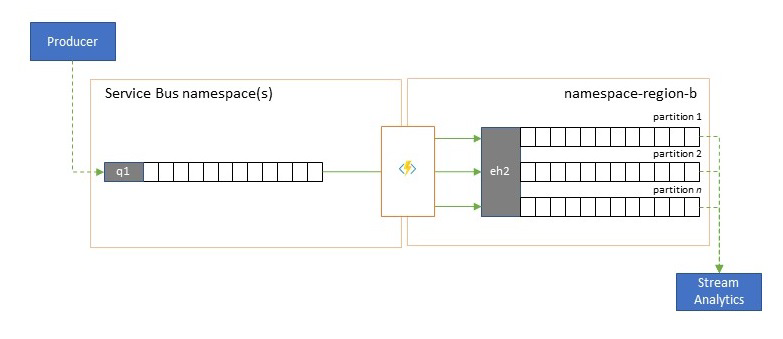
Verschillende cloudeigen analyseservices van Azure, zoals Azure Stream Analytics of Azure Synapse, werken het beste met gestreamde of vooraf gebatcheerde gegevens die afkomstig zijn van Azure Event Hubs, en Azure Event Hubs maakt integratie mogelijk met verschillende opensource-analysepakketten zoals Apache Samza, Apache Flink, Apache Spark en Apache Storm.
Als uw oplossing voornamelijk gebruikmaakt van Service Bus of Event Grid, kunt u deze gebeurtenissen eenvoudig toegankelijk maken voor dergelijke analysesystemen en ook voor archivering met Event Hubs Capture als u ze naar Event Hubs sluist. Event Grid kan dit systeemeigen doen met de Event Hubs-integratie, zodat Service Bus u de Service Bus-replicatierichtlijnen volgt.
Azure Stream Analytics kan rechtstreeks worden geïntegreerd met Event Hubs.
Richtlijnen:
Consolidatie en normalisatie van gebeurtenisstromen
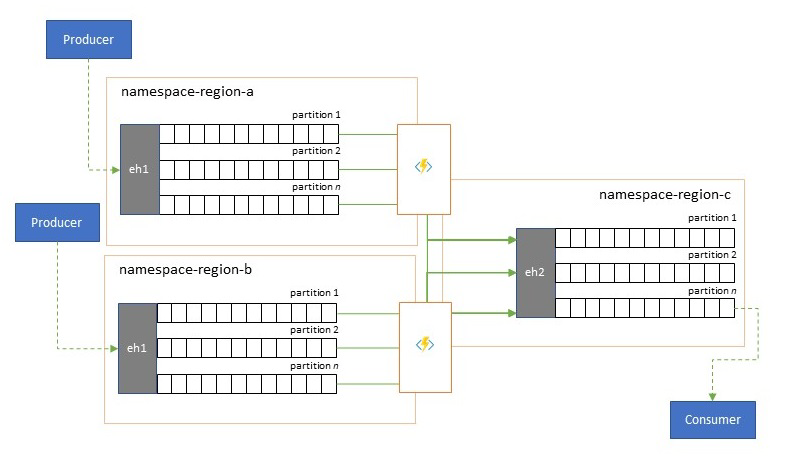
Wereldwijde oplossingen bestaan vaak uit regionale footprints die grotendeels onafhankelijk zijn, waaronder het hebben van hun eigen analysemogelijkheden, maar supra-regionale en wereldwijde analyseperspectief vereisen een geïntegreerd perspectief en daarom is een centrale samenvoeging van dezelfde gebeurtenisstromen die worden geëvalueerd in de respectieve regionale footprints voor het lokale perspectief.
Normalisatie is een variant van het consolidatiescenario, waarbij twee of meer binnenkomende gebeurtenisstromen hetzelfde soort gebeurtenissen bevatten, maar met verschillende structuren of verschillende coderingen, en de gebeurtenissen die het meest worden getranscodeerd of getransformeerd voordat ze kunnen worden gebruikt.
Normalisatie kan ook cryptografisch werk omvatten, zoals het ontsleutelen van end-to-end versleutelde nettoladingen en het opnieuw versleutelen met verschillende sleutels en algoritmen voor de downstream-consumenten doelgroep.
Richtlijnen:
Het splitsen en routeren van gebeurtenisstromen
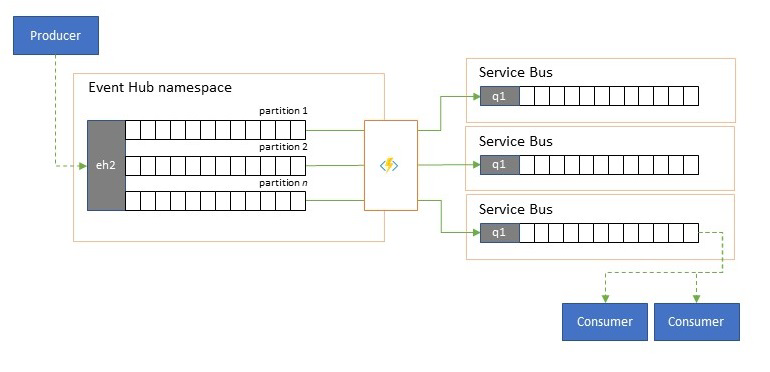
Azure Event Hubs wordt af en toe gebruikt in 'publish-subscribe'-stijlscenario's waarbij een binnenkomende torrent van opgenomen gebeurtenissen de capaciteit van Azure Service Bus of Azure Event Grid overschrijdt, die beide systeemeigen filter- en distributiemogelijkheden hebben en de voorkeur hebben voor dit patroon.
Hoewel een echte 'publish-subscribe'-mogelijkheid het aan abonnees overlaat om de gewenste gebeurtenissen te kiezen, heeft het splitsingspatroon de producer-toewijzingsgebeurtenissen aan partities door een vooraf bepaald distributiemodel en aangewezen consumenten vervolgens uitsluitend uit hun partitie gehaald. Als de Event Hubs het totale verkeer buffert, kan de inhoud van een bepaalde partitie, die een fractie van het oorspronkelijke doorvoervolume vertegenwoordigt, vervolgens worden gerepliceerd naar een wachtrij voor betrouwbaar, transactioneel, concurrerend verbruik van consumenten.
Veel scenario's waarbij Event Hubs voornamelijk wordt gebruikt voor het verplaatsen van gebeurtenissen binnen een toepassing binnen een regio, hebben enkele gevallen waarin bepaalde gebeurtenissen, misschien slechts uit één partitie, ook elders beschikbaar moeten worden gesteld. Dit scenario is vergelijkbaar met het splitsscenario, maar kan een schaalbare router gebruiken die alle berichten die binnenkomen in een Event Hubs en kersenkiezers, slechts een paar voor verdere routering gebruikt en die routeringsdoelen kan onderscheiden op basis van metagegevens of inhoud van gebeurtenissen.
Richtlijnen:
Logboekprojecties
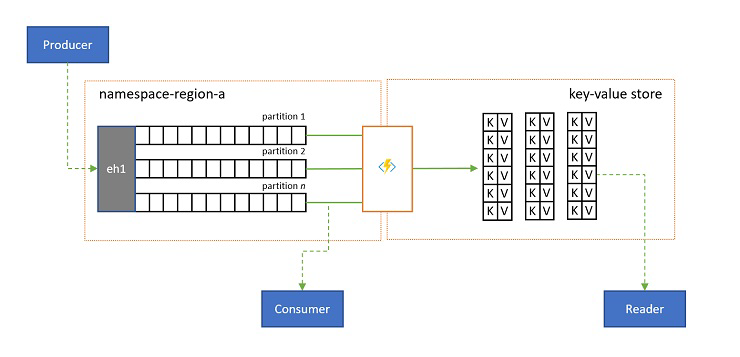
In sommige scenario's wilt u toegang hebben tot de meest recente waarde die is verzonden voor een substroom van een gebeurtenis en die vaak wordt onderscheiden door de partitiesleutel. In Apache Kafka wordt dit vaak bereikt door 'logboekcompressie' in te schakelen voor een onderwerp, dat alle behalve de meest recente gebeurtenis met een unieke sleutel negeert. De benadering voor het comprimeren van logboeken heeft drie samengestelde nadelen:
- Voor de compressie is een continue reorganisatie van het logboek vereist. Dit is een overmatig dure bewerking voor een broker die is geoptimaliseerd voor werkbelastingen met alleen toevoegbewerkingen.
- Compressie is destructief en biedt geen compact en niet-gecomprimeerd perspectief van dezelfde stroom.
- Een gecomprimeerde stroom heeft nog steeds een sequentieel toegangsmodel, wat betekent dat het vinden van de gewenste waarde in het logboek vereist dat het hele logboek in het slechtste geval wordt gelezen, wat meestal leidt tot optimalisaties die het exacte patroon implementeren dat hier wordt weergegeven: het projecteren van de logboekinhoud in een database of cache.
Uiteindelijk is een gecomprimeerd logboek een sleutel-waardearchief en als zodanig is het de slechtst mogelijke implementatieoptie voor een dergelijk archief. Het is veel efficiënter voor zoekacties en voor query's om een permanente projectie van het logboek te maken en te gebruiken in een correct sleutel-waardearchief of een andere database.
Omdat gebeurtenissen onveranderbaar zijn en de volgorde altijd behouden blijft in een logboek, is elke projectie van een logboek in een sleutel-waardearchief altijd identiek voor hetzelfde bereik van gebeurtenissen, wat betekent dat een projectie die u bijhoudt altijd een gezaghebbende weergave biedt en er nooit een goede reden is om het opnieuw te bouwen vanuit de logboekinhoud zodra deze is gebouwd.
Richtlijnen:
Technologieën voor replicatietoepassingen
Voor het implementeren van de bovenstaande patronen is een schaalbare en betrouwbare uitvoeringsomgeving vereist voor de replicatietaken die u wilt configureren en uitvoeren. In Azure zijn de runtime-omgevingen die het meest geschikt zijn voor dergelijke taken staatloze taken Azure Stream Analytics voor stateful stream-replicatietaken en Azure Functions voor staatloze replicatietaken.
Stateful replicatietoepassingen in Azure Stream Analytics
Voor stateful replicatietoepassingen die rekening moeten houden met relaties tussen gebeurtenissen, samengestelde gebeurtenissen maken, gebeurtenissen verrijken of verminderen, gegevensaggregaties maken en nettoladingen van gebeurtenissen transformeren, is Azure Stream Analytics de beste implementatieoptie.
In Azure Stream Analytics maakt u taken die invoer en uitvoer integreren en de gegevens uit de invoer integreren via query's die een resultaat opleveren dat vervolgens beschikbaar wordt gesteld in de uitvoer.
Query's zijn gebaseerd op de SQL-querytaal en kunnen gedurende een bepaalde periode eenvoudig streaminggegevens filteren, sorteren, aggregeren en samenvoegen. U kunt deze SQL-taal ook uitbreiden met door de gebruiker gedefinieerde javaScript- en C#-functies (UDF's). U kunt eenvoudig de opties voor gebeurtenisvolgorde en de duur van tijdvensters aanpassen bij het uitvoeren van combinatiebewerkingen, met behulp van eenvoudige taalconstructs en/of configuraties.
Elke taak heeft een of meer uitvoerwaarden voor de getransformeerde gegevens, en u kunt bepalen wat er gebeurt als reactie op de informatie die u hebt geanalyseerd. U kunt bijvoorbeeld:
- Stuur gegevens naar services zoals Azure Functions, Service Bus Topics of Queues om communicatie of downstream aangepaste werkstromen te activeren.
- Stuur gegevens naar een Power BI-dashboard voor realtime dashboards.
- Sla gegevens op in andere Azure-opslagservices (bijvoorbeeld Azure Data Lake, Azure Synapse Analytics, enzovoort) om batchanalyses uit te voeren of machine learning-modellen te trainen op basis van zeer grote, geïndexeerde pools met historische gegevens.
- Sla projecties (ook wel gerealiseerde weergaven genoemd) op in databases (SQL Database, Azure Cosmos DB).
Stateless replicatietoepassingen in Azure Functions
Voor staatloze replicatietaken waarbij u gebeurtenissen wilt doorsturen zonder rekening te houden met hun nettoladingen of processen, zonder rekening te hoeven houden met de relaties van gebeurtenissen (met uitzondering van hun relatieve volgorde), kunt u Azure Functions gebruiken, wat enorme flexibiliteit biedt.
Azure Functions heeft vooraf gebouwde, schaalbare triggers en uitvoerbindingen voor Azure Event Hubs, Azure IoT Hub, Azure Service Bus, Azure Event Grid en Azure Queue Storage, evenals aangepaste extensies voor RabbitMQ en Apache Kafka. De meeste triggers passen zich dynamisch aan de doorvoerbehoeften aan door het aantal gelijktijdige uitvoerexemplaren omhoog en omlaag te schalen op basis van gedocumenteerde metrische gegevens.
Voor het bouwen van logboekprojecties ondersteunt Azure Functions uitvoerbindingen voor Azure Cosmos DB en Azure Table Storage.
Azure Functions kan worden uitgevoerd onder een door Azure beheerde identiteit en daarmee kunnen de configuratiewaarden voor referenties worden bewaard in strikt toegangsbeheerde opslag in Azure Key Vault.
Met Azure Functions kunnen de replicatietaken bovendien rechtstreeks worden geïntegreerd met virtuele Azure-netwerken en service-eindpunten voor alle Azure Messaging-services en is deze direct geïntegreerd met Azure Monitor.
Met het Azure Functions-verbruiksplan kunnen de vooraf gemaakte triggers zelfs omlaag worden geschaald tot nul, terwijl er geen berichten beschikbaar zijn voor replicatie. Dit betekent dat er geen kosten in rekening worden gebracht om de configuratie gereed te houden om weer omhoog te schalen; het belangrijkste nadeel van het gebruik van het verbruiksplan is dat de latentie voor replicatietaken 'wakker worden' van deze status aanzienlijk hoger is dan bij de hostingplannen waar de infrastructuur wordt uitgevoerd.
In tegenstelling tot al deze, de meest voorkomende replicatie-engines voor berichten en gebeurtenissen, zoals De MirrorMaker van Apache Kafka, moet u zelf een hostingomgeving bieden en de replicatie-engine zelf schalen. Dit omvat het configureren en integreren van de beveiligings- en netwerkfuncties en het faciliteren van de stroom van bewakingsgegevens, en u hebt nog steeds geen mogelijkheid om aangepaste replicatietaken in de stroom te injecteren.
Kiezen tussen Azure Functions en Azure Stream Analytics
Azure Stream Analytics (ASA) is de beste optie wanneer u de nettolading van uw gebeurtenissen moet verwerken tijdens het repliceren ervan. ASA kan gebeurtenissen één voor één kopiëren of aggregaties maken die de informatie van gebeurtenisstromen verkorten voordat deze worden doorgestuurd. Het kan gemakkelijk zijn om referentiegegevens in Azure Blob Storage of Azure SQL Database aan te vullen zonder dergelijke gegevens in een stroom te hoeven importeren.
Met ASA kunt u eenvoudig permanente, gerealiseerde weergaven van streams in hyperschaaldatabases maken. Het is een veel superieure benadering van het onbelangrijke 'logboekcompressie'-model van Apache Kafka en de vluchtige tabelprojecties aan de clientzijde van Kafka Streams.
ASA kan gebeurtenissen met nettoladingen die zijn gecodeerd in de INDELINGen CSV, JSON en Apache Avro gemakkelijk verwerken en u kunt aangepaste deserialisaties voor elke andere indeling insluiten.
Voor alle replicatietaken waarin u gebeurtenisstromen 'as-is' wilt kopiëren en zonder de nettoladingen aan te raken, of als u een router moet implementeren, cryptografisch werk wilt uitvoeren, de codering van nettoladingen wilt wijzigen of als u op een andere manier volledige controle over de inhoud van de gegevensstroom nodig hebt, is Azure Functions de beste optie.
Volgende stappen
In dit artikel hebben we een reeks federatiepatronen verkend en de rol van Azure Functions uitgelegd als de gebeurtenis- en berichtenreplicatieruntime in Azure.
Vervolgens kunt u lezen hoe u een replicatortoepassing instelt met Azure Stream Analytics of Azure Functions en hoe u vervolgens gebeurtenisstromen tussen Event Hubs en verschillende andere gebeurtenis- en berichtensystemen repliceert: