Azure HDInsight-clusters automatisch schalen
De gratis functie voor automatisch schalen van Azure HDInsight kan het aantal werkknooppunten in uw cluster automatisch verhogen of verlagen op basis van de metrische gegevens van het cluster en het schaalbeleid dat door de klanten is aangenomen. De functie Voor automatisch schalen werkt door het aantal knooppunten binnen vooraf ingestelde limieten te schalen op basis van metrische prestatiegegevens of een gedefinieerd schema voor opschalen en omlaag schalen.
Hoe het werkt
De functie Automatisch schalen maakt gebruik van twee soorten voorwaarden om schaalgebeurtenissen te activeren: drempelwaarden voor verschillende metrische gegevens voor clusterprestaties (op basis van belasting) en tijdgebaseerde triggers (ook wel schaalaanpassing op basis van planning genoemd). Op belasting gebaseerde schaalaanpassing wijzigt het aantal knooppunten in uw cluster, binnen een bereik dat u instelt, om optimaal CPU-gebruik te garanderen en de lopende kosten te minimaliseren. Op schema's gebaseerde schaalaanpassing wijzigt het aantal knooppunten in uw cluster op basis van een schema van omhoog en omlaag schalen.
In de volgende video ziet u een overzicht van de uitdagingen die automatisch schalen oplost en hoe u hiermee kosten kunt beheren met HDInsight.
Schalen op basis van belasting of planning kiezen
Schaalaanpassing op basis van een planning kan worden gebruikt:
- Wanneer uw taken naar verwachting worden uitgevoerd volgens vaste planningen en voor een voorspelbare duur of wanneer u een laag gebruik verwacht tijdens specifieke tijdstippen van de dag. Test- en ontwikkelomgevingen bijvoorbeeld in werkuren na werktijden, end-of-day-taken.
Schaalaanpassing op basis van belasting kan worden gebruikt:
- Wanneer de belastingspatronen aanzienlijk en onvoorspelbaar gedurende de dag fluctueren. Ordergegevensverwerking met willekeurige schommelingen in belastingpatronen op basis van verschillende factoren.
Metrische clustergegevens
Automatisch schalen bewaakt continu het cluster en verzamelt de volgende metrische gegevens:
| Metrisch | Beschrijving |
|---|---|
| Totaal cpu in behandeling | Het totale aantal kernen dat nodig is om de uitvoering van alle in behandeling zijnde containers te starten. |
| Totaal geheugen in behandeling | Het totale geheugen (in MB) dat nodig is om de uitvoering van alle in behandeling zijnde containers te starten. |
| Totale gratis CPU | De som van alle ongebruikte kernen op de actieve werkknooppunten. |
| Totaal vrij geheugen | De som van ongebruikt geheugen (in MB) op de actieve werkknooppunten. |
| Gebruikt geheugen per knooppunt | De belasting op een werkknooppunt. Een werkknooppunt waarop 10 GB geheugen wordt gebruikt, wordt beschouwd als meer belasting dan een werkrol met 2 GB gebruikt geheugen. |
| Aantal toepassingsmodellen per knooppunt | Het aantal AM-containers (Application Master) dat wordt uitgevoerd op een werkknooppunt. Een werkrolknooppunt dat als host fungeert voor twee AM-containers, wordt als belangrijker beschouwd dan een werkknooppunt dat als host fungeert voor nul AM-containers. |
De bovenstaande metrische gegevens worden elke 60 seconden gecontroleerd. Automatische schaalaanpassing maakt beslissingen voor omhoog en omlaag schalen op basis van deze metrische gegevens.
Zie Ondersteunde metrische gegevens voor Microsoft.HDInsight/clusters voor een volledige lijst met metrische clustergegevens.
Schaalvoorwaarden op basis van belasting
Wanneer de volgende voorwaarden worden gedetecteerd, geeft automatisch schalen een schaalaanvraag uit:
| Omhoog schalen | Omlaag schalen |
|---|---|
| Het totale aantal cpu's dat in behandeling is, is langer dan 3-5 minuten groter dan de totale gratis CPU. | Het totale aantal cpu's dat in behandeling is, is gedurende meer dan 3-5 minuten minder dan de totale gratis CPU. |
| Het totale geheugen in behandeling is langer dan het totale vrije geheugen gedurende meer dan 3-5 minuten. | Het totale geheugen dat in behandeling is, is gedurende meer dan 3-5 minuten minder dan het totale vrije geheugen. |
Voor omhoog schalen geeft Automatisch schalen een aanvraag voor opschalen uit om het vereiste aantal knooppunten toe te voegen. Het omhoog schalen is gebaseerd op het aantal nieuwe werkknooppunten dat nodig is om te voldoen aan de huidige CPU- en geheugenvereisten.
Bij omlaag schalen wordt een aanvraag voor het verwijderen van sommige knooppunten automatisch geschaald. De schaal omlaag is gebaseerd op het aantal AM-containers (Application Master) per knooppunt. En de huidige CPU- en geheugenvereisten. De service detecteert ook welke knooppunten kandidaten zijn voor verwijdering op basis van de huidige taakuitvoering. Met de bewerking omlaag schalen worden eerst de knooppunten buiten gebruik gesteld en vervolgens uit het cluster verwijderd.
Overwegingen voor het aanpassen van de grootte van Ambari DB voor automatisch schalen
Het wordt aanbevolen dat Ambari DB de juiste grootte heeft om de voordelen van automatische schaalaanpassing te profiteren. Klanten moeten de juiste DB-laag gebruiken en de aangepaste Ambari-database gebruiken voor grote clusters. Lees de aanbevelingen voor database- en hoofdknooppuntgrootten.
Clustercompatibiliteit
Belangrijk
De functie voor automatisch schalen van Azure HDInsight is op 7 november 2019 algemeen beschikbaar gekomen voor Spark- en Hadoop-clusters en bevat verbeteringen die niet beschikbaar zijn in de preview-versie van de functie. Als u vóór 7 november 2019 een Spark-cluster hebt gemaakt en de functie Voor automatisch schalen in uw cluster wilt gebruiken, is het aanbevolen pad om een nieuw cluster te maken en enable Autoscale op het nieuwe cluster.
Automatische schaalaanpassing voor Interactive Query (LLAP) is uitgebracht voor algemene beschikbaarheid voor HDI 4.0 op 27 augustus 2020. Automatisch schalen is alleen beschikbaar in Spark, Hadoop en Interactive Query, clusters
In de volgende tabel worden de clustertypen en -versies beschreven die compatibel zijn met de functie Automatische schaalaanpassing.
| Versie | Spark | Hive | Interactive Query | HBase | Kafka |
|---|---|---|---|---|---|
| HDInsight 4.0 zonder ESP | Ja | Ja | Ja* | Nee | Nr. |
| HDInsight 4.0 met ESP | Ja | Ja | Ja* | Nee | Nr. |
| HDInsight 5.0 zonder ESP | Ja | Ja | Ja* | Nee | Nr. |
| HDInsight 5.0 met ESP | Ja | Ja | Ja* | Nee | Nr. |
* Interactieve queryclusters kunnen alleen worden geconfigureerd voor schaalaanpassing op basis van planning, niet op basis van belasting.
Aan de slag
Een cluster maken met automatisch schalen op basis van belasting
Voer de volgende stappen uit als u de functie Voor automatisch schalen wilt inschakelen met schaalaanpassing op basis van belasting, als onderdeel van het normale proces voor het maken van clusters:
Schakel op het tabblad Configuratie en prijzen het
Enable autoscaleselectievakje in.Selecteer Laden op basis van automatisch schalen.
Voer de beoogde waarden in voor de volgende eigenschappen:
- Eerste aantal knooppunten voor worker-knooppunten.
- Minimum aantal werkknooppunten.
- Maximum aantal werkknooppunten.
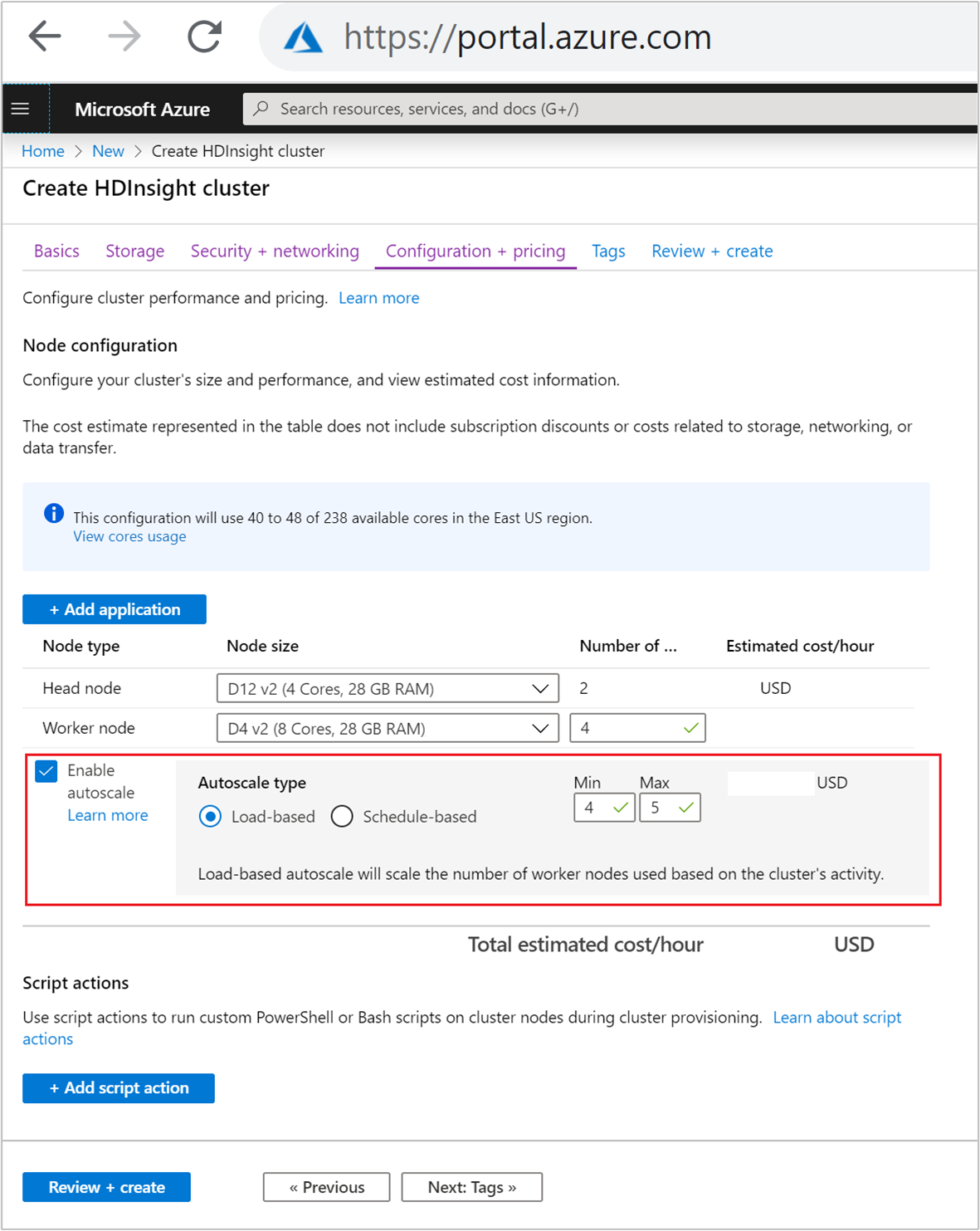
Het eerste aantal werkknooppunten moet tussen het minimum en maximum vallen, inclusief. Deze waarde definieert de initiële grootte van het cluster wanneer het wordt gemaakt. Het minimum aantal werkknooppunten moet worden ingesteld op drie of meer. Het schalen van uw cluster naar minder dan drie knooppunten kan ertoe leiden dat het vastloopt in de veilige modus vanwege onvoldoende bestandsreplicatie. Zie Vastlopen in de veilige modus voor meer informatie.
Een cluster maken met automatisch schalen op basis van een planning
Als u de functie Automatisch schalen met schaalaanpassing op basis van een planning wilt inschakelen, voert u de volgende stappen uit als onderdeel van het normale proces voor het maken van clusters:
Schakel op het tabblad Configuratie en prijzen het
Enable autoscaleselectievakje in.Voer het aantal knooppunten voor worker-knooppunten in, waarmee de limiet wordt ingesteld voor het omhoog schalen van het cluster.
Selecteer de optie Op basis van planning onder Type automatische schaalaanpassing.
Selecteer Configureren om het configuratievenster voor automatische schaalaanpassing te openen.
Selecteer uw tijdzone en klik vervolgens op + Voorwaarde toevoegen
Selecteer de dagen van de week waarop de nieuwe voorwaarde van toepassing moet zijn.
Bewerk de tijd waarop de voorwaarde van kracht moet worden en het aantal knooppunten waarnaar het cluster moet worden geschaald.
Voeg indien nodig meer voorwaarden toe.
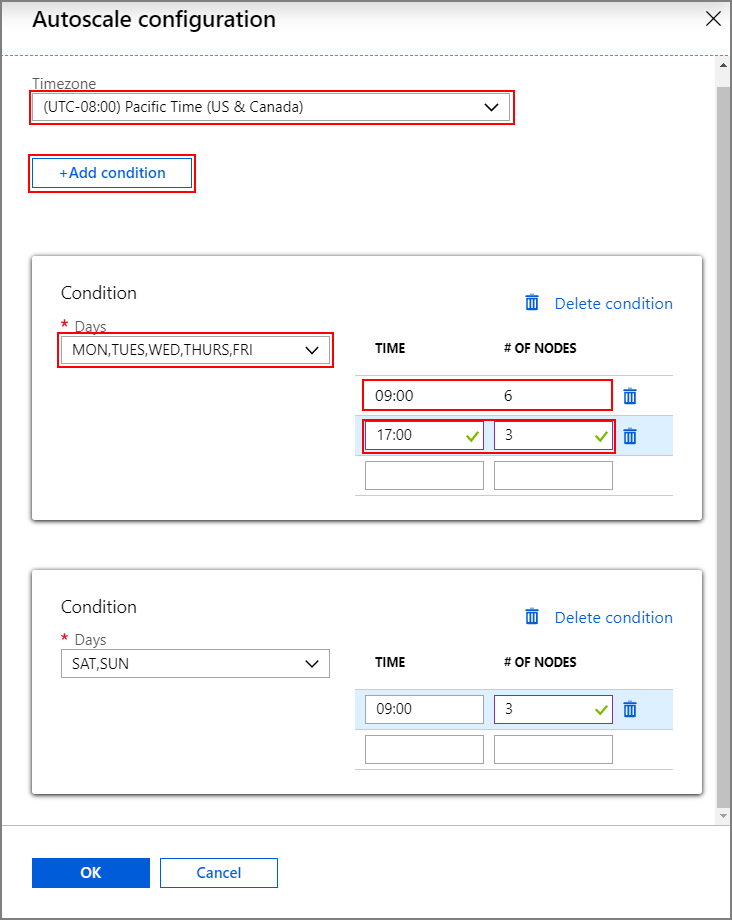
Het aantal knooppunten moet tussen 3 en het maximum aantal werkknooppunten zijn dat u hebt ingevoerd voordat u voorwaarden toevoegt.
Laatste stappen voor het maken
Selecteer het VM-type voor werkknooppunten door een VIRTUELE machine te selecteren in de vervolgkeuzelijst onder Knooppuntgrootte. Nadat u het VM-type voor elk knooppunttype hebt gekozen, kunt u het geschatte kostenbereik voor het hele cluster zien. Pas de VM-typen aan zodat deze passen bij uw budget.
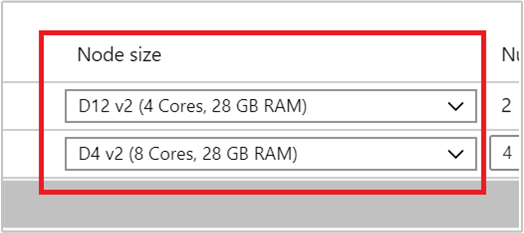
Uw abonnement heeft een capaciteitsquotum voor elke regio. Het totale aantal kernen van uw hoofdknooppunten en de maximale werkknooppunten kunnen het capaciteitsquotum niet overschrijden. Dit quotum is echter een zachte limiet; u kunt altijd een ondersteuningsticket maken om het eenvoudig te laten toenemen.
Notitie
Als u de totale quotumlimiet voor kernen overschrijdt, krijgt u een foutbericht met de mededeling dat het maximumknooppunt de beschikbare kernen in deze regio heeft overschreden. Kies een andere regio of neem contact op met de ondersteuning om het quotum te verhogen.'
Een cluster maken met een Resource Manager-sjabloon
Automatisch schalen op basis van belasting
U kunt een HDInsight-cluster maken met automatisch schalen op basis van belasting, door een autoscale knooppunt toe te voegen aan de computeProfileworkernode>sectie met de eigenschappen minInstanceCount en maxInstanceCount zoals weergegeven in het json-fragment. Zie quickstartsjabloon: Spark-cluster implementeren met automatisch schalen op basis van belasting ingeschakeld voor een volledige Resource Manager-sjabloon.
{
"name": "workernode",
"targetInstanceCount": 4,
"autoscale": {
"capacity": {
"minInstanceCount": 3,
"maxInstanceCount": 10
}
},
"hardwareProfile": {
"vmSize": "Standard_D13_V2"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
},
"virtualNetworkProfile": null,
"scriptActions": []
}
Automatisch schalen op basis van planning
U kunt een HDInsight-cluster maken met automatisch schalen op basis van een azure Resource Manager-sjabloon op basis van een planning door een autoscale knooppunt toe te voegen aan de computeProfile>workernode sectie. Het autoscale knooppunt bevat een recurrence timezone en schedule die beschrijft wanneer de wijziging plaatsvindt. Zie Spark-cluster implementeren met automatisch schalen op basis van planning ingeschakeld voor een volledige Resource Manager-sjabloon.
{
"autoscale": {
"recurrence": {
"timeZone": "Pacific Standard Time",
"schedule": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"timeAndCapacity": {
"time": "11:00",
"minInstanceCount": 10,
"maxInstanceCount": 10
}
}
]
}
},
"name": "workernode",
"targetInstanceCount": 4
}
Automatische schaalaanpassing voor een actief cluster in- en uitschakelen
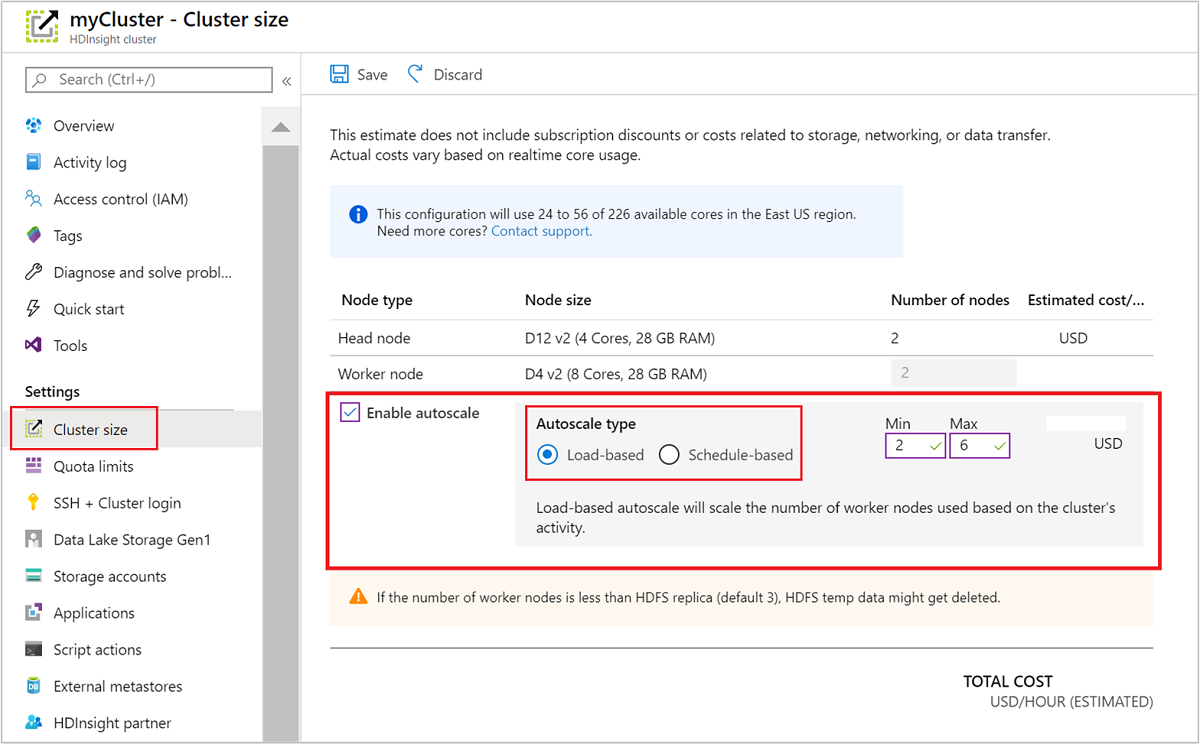
Met gebruik van Azure Portal
Als u automatische schaalaanpassing wilt inschakelen voor een actief cluster, selecteert u Clustergrootte onder Instellingen. Selecteer Enable autoscalevervolgens . Selecteer het gewenste type automatische schaalaanpassing en voer de opties in voor schaling op basis van belasting of planning. Selecteer ten slotte Opslaan.
De REST API gebruiken
Als u automatische schaalaanpassing wilt in- of uitschakelen voor een actief cluster met behulp van de REST API, moet u een POST-aanvraag indienen bij het eindpunt voor automatische schaalaanpassing:
https://management.azure.com/subscriptions/{subscription Id}/resourceGroups/{resourceGroup Name}/providers/Microsoft.HDInsight/clusters/{CLUSTERNAME}/roles/workernode/autoscale?api-version=2018-06-01-preview
Gebruik de juiste parameters in de nettolading van de aanvraag. De volgende json-nettolading kan worden gebruikt om enable Autoscale. Gebruik de nettolading {autoscale: null} om automatische schaalaanpassing uit te schakelen.
{ "autoscale": { "capacity": { "minInstanceCount": 3, "maxInstanceCount": 5 } } }
Zie de vorige sectie over het inschakelen van automatisch schalen op basis van belasting voor een volledige beschrijving van alle nettoladingparameters. Het wordt afgeraden om de service voor automatisch schalen af te schakelen op een actief cluster.
Activiteiten voor automatisch schalen bewaken
De clusterstatus
De clusterstatus die in Azure Portal wordt vermeld, kan u helpen bij het bewaken van activiteiten voor automatisch schalen.
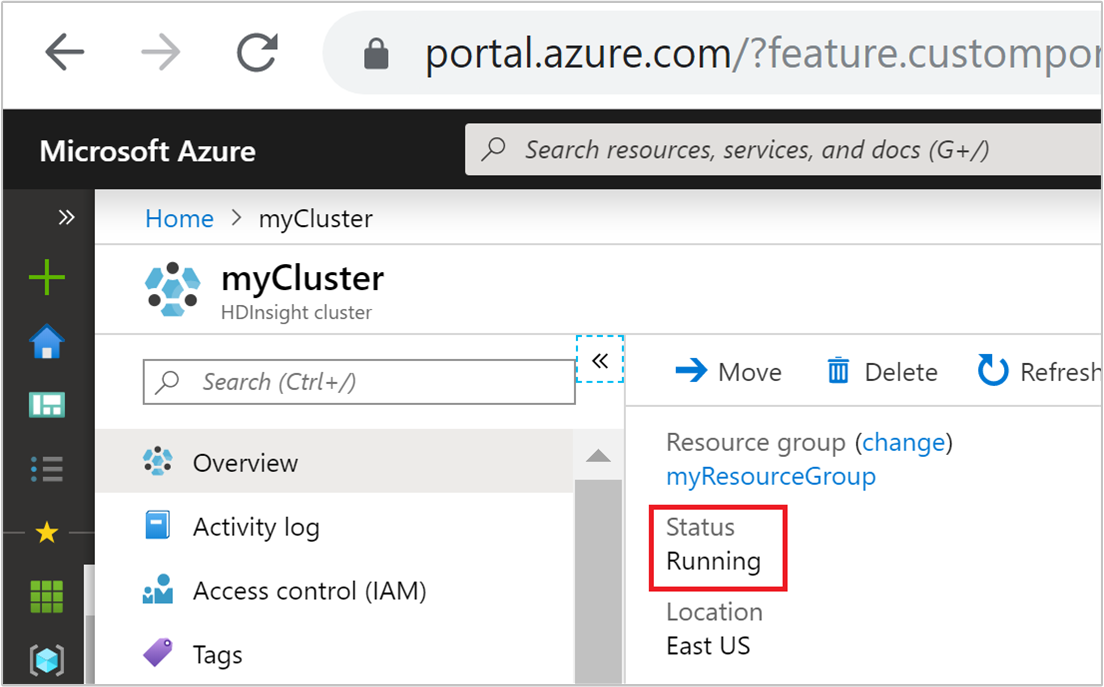
Alle clusterstatusberichten die u mogelijk ziet, worden in de volgende lijst uitgelegd.
| De clusterstatus | Beschrijving |
|---|---|
| Wordt uitgevoerd | Het cluster werkt normaal. Alle vorige activiteiten voor automatische schaalaanpassing zijn voltooid. |
| Bijwerken | De configuratie voor automatische schaalaanpassing van clusters wordt bijgewerkt. |
| HDInsight-configuratie | Er wordt een bewerking voor het omhoog of omlaag schalen van een cluster uitgevoerd. |
| Fout bijwerken | HDInsight heeft problemen gehad tijdens de configuratie-update voor automatische schaalaanpassing. Klanten kunnen ervoor kiezen om de update opnieuw uit te voeren of automatische schaalaanpassing uit te schakelen. |
| Error | Er is iets mis met het cluster en kan niet worden gebruikt. Verwijder dit cluster en maak een nieuw cluster. |
Als u het huidige aantal knooppunten in uw cluster wilt weergeven, gaat u naar de grafiek Clustergrootte op de pagina Overzicht voor uw cluster. Of selecteer Clustergrootte onder Instellingen.
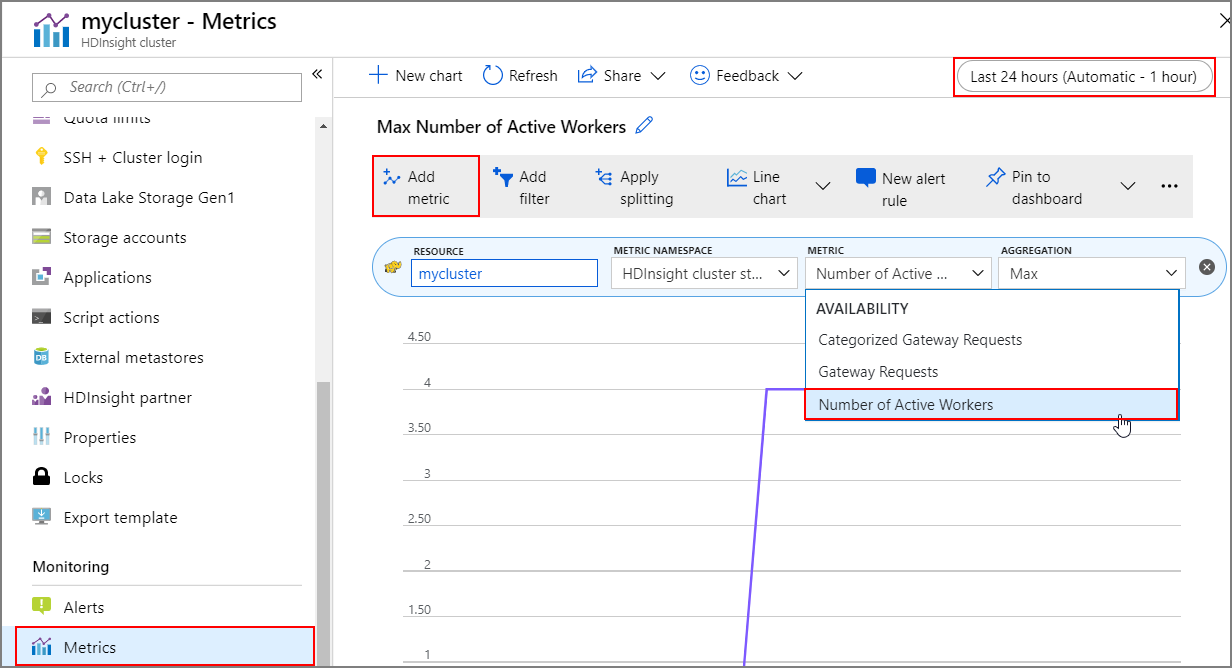
Bewerkingsgeschiedenis
U kunt de geschiedenis van het cluster omhoog en omlaag schalen bekijken als onderdeel van de metrische gegevens van het cluster. U kunt ook alle schaalacties weergeven gedurende de afgelopen dag, week of andere periode.
Selecteer Metrische gegevens onder Bewaking. Selecteer vervolgens Metrische gegevens en Aantal actieve werknemers toevoegen in de vervolgkeuzelijst Metrische gegevens. Selecteer de knop in de rechterbovenhoek om het tijdsbereik te wijzigen.
Aanbevolen procedures
Overweeg de latentie van omhoog en omlaag schalen van bewerkingen
Het kan 10 tot 20 minuten duren voordat de algehele schaalbewerking is voltooid. Plan deze vertraging bij het instellen van een aangepaste planning. Als u bijvoorbeeld wilt dat de clustergrootte 20 om 9:00 uur is, stelt u de schematrigger in op een eerder tijdstip, zoals 8:30 uur of eerder, zodat de schaalbewerking om 9:00 uur is voltooid.
Voorbereiden op omlaag schalen
Tijdens het omlaag schalen van het cluster worden de knooppunten buiten gebruik gesteld om te voldoen aan de doelgrootte. Bij automatisch schalen op basis van belasting wacht automatisch schalen als taken op deze knooppunten worden uitgevoerd totdat de taken zijn voltooid voor Spark- en Hadoop-clusters. Omdat elk werkknooppunt ook een rol in HDFS heeft, worden de tijdelijke gegevens verplaatst naar de resterende werkknooppunten. Zorg ervoor dat er voldoende ruimte is op de resterende knooppunten om alle tijdelijke gegevens te hosten.
Notitie
In het geval van schaalaanpassing op basis van automatische schaalaanpassing op basis van schema's, wordt een probleemloze buitengebruikstelling niet ondersteund. Dit kan leiden tot taakfouten tijdens een omlaag schalende bewerking en het wordt aanbevolen om planningen te plannen op basis van de verwachte taakplanningspatronen, zodat de lopende taken voldoende tijd hebben om te worden afgesloten. U kunt de planningen instellen die kijken naar de historische verspreiding van voltooiingstijden om taakfouten te voorkomen.
Op planning gebaseerde automatische schaalaanpassing configureren op basis van gebruikspatroon
U moet het patroon voor clustergebruik begrijpen wanneer u op schema gebaseerde automatische schaalaanpassing configureert. Grafana-dashboard kan u helpen inzicht te verkrijgen in de laad- en uitvoeringssites van uw query. U kunt de beschikbare uitvoerdersleuven en de totale uitvoerdersleuven ophalen vanuit het dashboard.
Hier volgt een manier om een schatting te maken van het aantal benodigde werkknooppunten. U wordt aangeraden nog een buffer van 10% te geven om de variatie van de workload af te handelen.
Aantal uitvoerdersites dat wordt gebruikt = Totale uitvoerdersleuven : totaal aantal beschikbare uitvoerdersleuven.
Aantal werkknooppunten vereist = Aantal uitvoerdersleuven dat daadwerkelijk wordt gebruikt / (hive.llap.daemon.num.executors + hive.llap.daemon.task.scheduler.wait.queue.size).
*hive.llap.daemon.num.executors kan worden geconfigureerd en de standaardwaarde is 4.
*hive.llap.daemon.task.scheduler.wait.queue.size is configureerbaar en de standaardwaarde is 10.
Aangepaste scriptacties
Aangepaste scriptacties worden meestal gebruikt voor het aanpassen van de knooppunten (HeadNode/ WorkerNodes) waarmee onze klanten bepaalde bibliotheken en hulpprogramma's kunnen configureren die door hen worden gebruikt. Een veelvoorkomende use-case is dat de taken die op het cluster worden uitgevoerd, mogelijk afhankelijk zijn van de bibliotheek van derden, die eigendom is van de klant en die beschikbaar moeten zijn op knooppunten om de taak te laten slagen. Voor automatische schaalaanpassing bieden we momenteel ondersteuning voor aangepaste scriptacties, die behouden blijven, dus telkens wanneer de nieuwe knooppunten worden toegevoegd aan het cluster als onderdeel van de opschaalbewerking, worden deze persistente scriptacties uitgevoerd en worden de containers of taken erop toegewezen. Hoewel aangepaste scriptacties helpen bij het opstarten van de nieuwe knooppunten, is het raadzaam om het minimaal te houden, omdat dit de algehele latentie van omhoog schalen zou kunnen optellen en invloed kan hebben op de geplande taken.
Houd rekening met de minimale clustergrootte
Schaal uw cluster niet omlaag naar minder dan drie knooppunten. Het schalen van uw cluster naar minder dan drie knooppunten kan ertoe leiden dat het vastloopt in de veilige modus vanwege onvoldoende bestandsreplicatie. Zie Vastlopen in de veilige modus voor meer informatie.
Microsoft Entra Domain Services & Scaling Operations
Als u een HDInsight-cluster gebruikt met Enterprise Security Package (ESP) dat is gekoppeld aan een door Microsoft Entra Domain Services beheerd domein, raden we u aan om de belasting van Microsoft Entra Domain Services te beperken. Bij complexe synchronisatie van mapstructuren wordt aanbevolen om gevolgen voor schaalbewerkingen te voorkomen.
De Hive-configuratie maximumaantal gelijktijdige query's instellen voor het piekgebruiksscenario
Gebeurtenissen voor automatisch schalen wijzigen de Hive-configuratie maximumaantal gelijktijdige query's in Ambari niet. Dit betekent dat de Interactieve Service van Hive Server 2 op elk moment alleen het opgegeven aantal gelijktijdige query's kan verwerken, zelfs als het aantal Interactive Query-daemons omhoog en omlaag wordt geschaald op basis van belasting en planning. De algemene aanbeveling is om deze configuratie in te stellen voor het piekgebruiksscenario om handmatige interventie te voorkomen.
Er kan echter een fout optreden bij het opnieuw opstarten van Hive Server 2 als er slechts een paar werkknooppunten zijn en de waarde voor het maximumaantal gelijktijdige query's te hoog is geconfigureerd. U hebt minimaal het minimale aantal werkknooppunten nodig dat geschikt is voor het opgegeven aantal Tez Ams (gelijk aan de configuratie maximumaantal gelijktijdige query's).
Beperkingen
Aantal interactieve query-daemons
Als interactieve queryclusters met automatische schaalaanpassing zijn ingeschakeld, wordt met een gebeurtenis voor automatisch omhoog/omlaag schalen ook het aantal Interactive Query-daemons omhoog/omlaag geschaald naar het aantal actieve werkknooppunten. De wijziging in het aantal daemons blijft niet behouden in de num_llap_nodes configuratie in Ambari. Als Hive-services handmatig opnieuw worden opgestart, wordt het aantal Interactive Query-daemons opnieuw ingesteld volgens de configuratie in Ambari.
Als de Interactive Query-service handmatig opnieuw wordt opgestart, moet u de num_llap_node configuratie (het aantal knooppunten) dat nodig is om de Hive Interactive Query-daemon uit te voeren, handmatig wijzigen onder Advanced hive-interactive-env , zodat deze overeenkomt met het huidige aantal actieve werkknooppunten. Interactive Query-cluster ondersteunt alleen automatisch schalen op basis van planning.
Volgende stappen
Lees meer over richtlijnen voor het handmatig schalen van clusters in de richtlijnen voor schalen.