Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
HDInsight biedt elasticiteit met opties om het aantal werkknooppunten in uw clusters omhoog en omlaag te schalen. Met deze elasticiteit kunt u een cluster na uren of in het weekend verkleinen. En breid het uit tijdens piekactiviteiten.
Schaal uw cluster omhoog vóór periodieke batchverwerking, zodat het cluster voldoende resources heeft. Nadat de verwerking is voltooid en het gebruik omlaag gaat, schaalt u het HDInsight-cluster omlaag naar minder werkknooppunten.
U kunt een cluster handmatig schalen met een van de volgende methoden. U kunt ook opties voor automatisch schalen gebruiken om automatisch omhoog en omlaag te schalen als reactie op bepaalde metrische gegevens.
Opmerking
Alleen clusters met HDInsight versie 3.1.3 of hoger worden ondersteund. Als u niet zeker weet wat de versie van uw cluster is, kunt u de pagina Eigenschappen controleren.
Hulpprogramma's voor het schalen van clusters
Microsoft biedt de volgende hulpprogramma's voor het schalen van clusters:
| Nutsvoorzieningen | Beschrijving |
|---|---|
| PowerShell Az |
Set-AzHDInsightClusterSize
-ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE
|
| Azure CLI |
az hdinsight resize
--resource-group RESOURCEGROUP --name CLUSTERNAME --workernode-count NEWSIZE
|
| Klassieke Azure CLI | azure hdinsight cluster resize CLUSTERNAME NEWSIZE |
| Azure-portal | Open het deelvenster HDInsight-cluster, selecteer Clustergrootte in het linkermenu, typ in het deelvenster Clustergrootte het aantal werkknooppunten en selecteer Opslaan. |
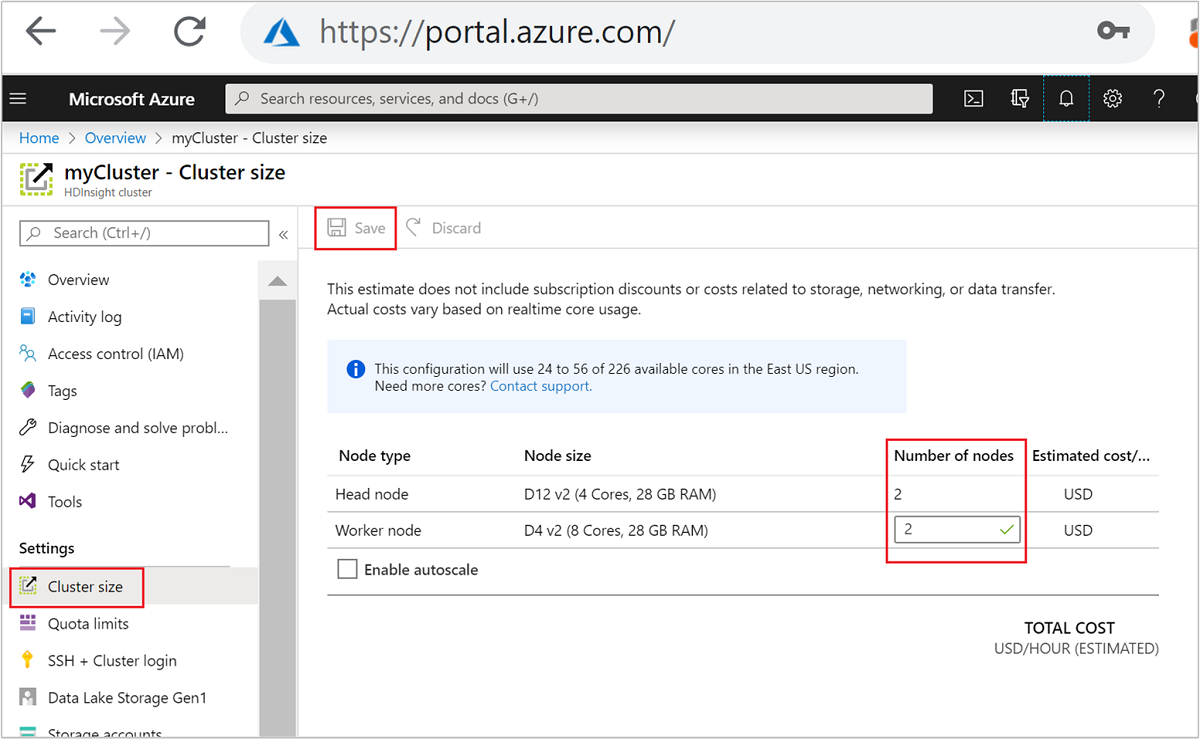
Met behulp van een van deze methoden kunt u uw HDInsight-cluster binnen enkele minuten omhoog of omlaag schalen.
Belangrijk
Impact van schaaloperaties
Wanneer u knooppunten toevoegt aan uw actieve HDInsight-cluster (omhoog schalen), blijven taken ongewijzigd. Nieuwe banen kunnen veilig worden ingediend terwijl het schaalproces wordt uitgevoerd. Als de schaalbewerking mislukt, blijft uw cluster functioneel.
Als u knooppunten verwijdert (omlaag schalen), mislukken wachtende of actieve taken wanneer de schaalbewerking is voltooid. Deze fout is het gevolg van een aantal services die opnieuw worden opgestart tijdens het schaalproces. Uw cluster kan vastlopen in de veilige modus tijdens een handmatige schaalbewerking.
De impact van het wijzigen van het aantal gegevensknooppunten varieert voor elk type cluster dat wordt ondersteund door HDInsight:
Apache Hadoop
U kunt het aantal werkknooppunten in een actieve Hadoop-cluster naadloos verhogen zonder dat dit van invloed is op taken. Er kunnen ook nieuwe taken worden ingediend terwijl de bewerking wordt uitgevoerd. Fouten in een schaalbewerking worden probleemloos verwerkt. Het cluster blijft altijd functioneel.
Wanneer een Hadoop-cluster omlaag wordt geschaald met minder gegevensknooppunten, worden sommige services opnieuw opgestart. Dit gedrag zorgt ervoor dat alle lopende en wachtende taken mislukken na voltooiing van de schaaloperatie. U kunt de taken echter opnieuw indienen zodra de bewerking is voltooid.
Apache HBase
U kunt naadloos knooppunten toevoegen aan of verwijderen uit uw HBase-cluster terwijl het wordt uitgevoerd. Regionale servers worden binnen een paar minuten na het voltooien van de schaaloperatie automatisch gebalanceerd. U kunt de regionale servers echter handmatig verdelen. Meld u aan bij het hoofdknooppunt van het cluster en voer de volgende opdrachten uit:
pushd %HBASE_HOME%\bin hbase shell balancerZie Aan de slag met een Apache HBase-voorbeeld in HDInsight voor meer informatie over het gebruik van de HBase-shell.
Opmerking
Niet geschikt voor Kafka-clusters.
Apache Hive LLAP
Na het schalen naar
Nwerkknooppunten stelt HDInsight automatisch de volgende configuraties in en start Hive opnieuw op.- Maximum totaal aantal gelijktijdige query's:
hive.server2.tez.sessions.per.default.queue = min(N, 32) - Aantal knooppunten dat wordt gebruikt door LLAP van Hive:
num_llap_nodes = N - Aantal knooppunten voor het uitvoeren van Hive LLAP-daemon:
num_llap_nodes_for_llap_daemons = N
- Maximum totaal aantal gelijktijdige query's:
Een cluster veilig omlaag schalen
Een cluster omlaag schalen met lopende taken
Om te voorkomen dat uw lopende taken mislukken tijdens een schaalvermindering, kunt u drie dingen proberen:
- Wacht totdat de taken zijn voltooid voordat u het cluster omlaag schaalt.
- Beëindig de taken handmatig.
- Start de taken opnieuw nadat de schaaloperatie is afgerond.
Als u een lijst wilt zien met taken die in behandeling zijn en worden uitgevoerd, kunt u de GEBRUIKERSinterface van YARN Resource Manager gebruiken door de volgende stappen uit te voeren:
Selecteer uw cluster via de Azure-portal. Het cluster wordt geopend op een nieuwe portalpagina.
Navigeer vanuit de hoofdweergave naar deambari-startpaginaclusterdashboards>. Voer uw clusterreferenties in.
Selecteer YARN in de Ambari-gebruikersinterface in de lijst met services in het menu aan de linkerkant.
Selecteer op de YARN-pagina Snelle koppelingen en beweeg de muisaanwijzer over het actieve hoofdknooppunt en selecteer vervolgens de Gebruikersinterface van Resource Manager.
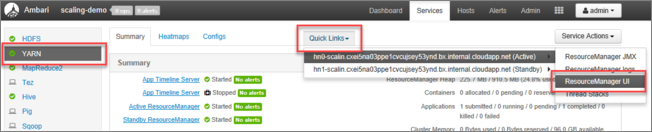
U kunt rechtstreeks toegang krijgen tot de Gebruikersinterface van Resource Manager met https://<HDInsightClusterName>.azurehdinsight.net/yarnui/hn/cluster.
U ziet een lijst met taken, samen met de huidige status. In de schermopname wordt er één taak uitgevoerd:
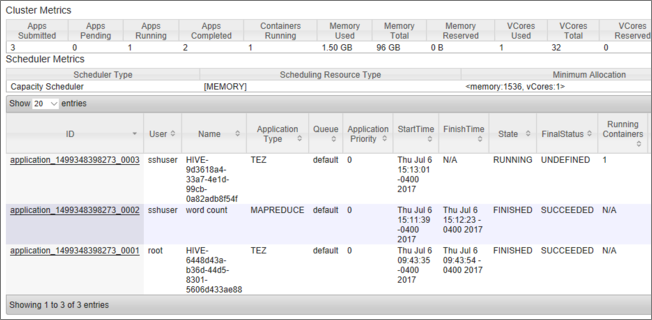
Als u die actieve toepassing handmatig wilt beëindigen, voert u de volgende opdracht uit vanuit de SSH-shell:
yarn application -kill <application_id>
Voorbeeld:
yarn application -kill "application_1499348398273_0003"
Vastzitten in veilige modus
Wanneer u een cluster omlaag schaalt, gebruikt HDInsight Apache Ambari-beheerinterfaces om eerst de extra werkknooppunten buiten gebruik te stellen. De knooppunten repliceren hun HDFS-blokken naar andere onlinewerkknooppunten. Daarna schaalt HDInsight het cluster veilig omlaag. HDFS gaat in de veilige modus tijdens de schaalbewerking. HDFS moet uitkomen zodra de schaalvergroting is voltooid. In sommige gevallen blijft HDFS echter vastzitten in de veilige modus tijdens een schaalbewerking vanwege onder-replicatie van bestandsblokken.
HDFS is standaard geconfigureerd met een dfs.replication instelling van 1, waarmee wordt bepaald hoeveel exemplaren van elk bestandsblok beschikbaar zijn. Elke kopie van een bestandsblok wordt opgeslagen op een ander knooppunt van het cluster.
Wanneer het verwachte aantal blokkopieën niet beschikbaar is, wordt HDFS geactiveerd in de veilige modus en worden er waarschuwingen gegenereerd in Ambari. HDFS kan de veilige modus inschakelen voor een schaalbewerking. Het cluster kan vastlopen in de veilige modus als het vereiste aantal knooppunten niet wordt gedetecteerd voor replicatie.
Voorbeeldfouten wanneer de veilige modus is ingeschakeld
org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /tmp/hive/hive/819c215c-6d87-4311-97c8-4f0b9d2adcf0. Name node is in safe mode.
org.apache.http.conn.HttpHostConnectException: Connect to active-headnode-name.servername.internal.cloudapp.net:10001 [active-headnode-name.servername. internal.cloudapp.net/1.1.1.1] failed: Connection refused
U kunt de logboeken van het naamknooppunt bekijken in de /var/log/hadoop/hdfs/ map, in de buurt van het tijdstip waarop het cluster is geschaald, om te zien wanneer het in de veilige modus is gegaan. De logboekbestanden hebben de naam Hadoop-hdfs-namenode-<active-headnode-name>.*.
De hoofdoorzaak was dat Hive afhankelijk is van tijdelijke bestanden in HDFS tijdens het uitvoeren van query's. Wanneer HDFS in de veilige modus komt, kan Hive geen query's uitvoeren omdat deze niet naar HDFS kan schrijven. Tijdelijke bestanden in HDFS bevinden zich op het lokale station dat is gekoppeld aan de vm's van het afzonderlijke werkknooppunt. De bestanden worden gerepliceerd tussen andere werkknooppunten in minimaal drie replica's.
Voorkomen dat HDInsight vastloopt in de veilige modus
Er zijn verschillende manieren om te voorkomen dat HDInsight in de veilige modus wordt achtergelaten:
- Stop alle Hive-taken voordat u HDInsight omlaag schaalt. Als alternatief kunt u het afschalingsproces plannen om conflicten met lopende Hive-taken te voorkomen.
- Schoon de scratchmapbestanden
tmpvan Hive handmatig op in HDFS voordat u omlaag schaalt. - Schaal HDInsight alleen omlaag naar drie werkknooppunten, minimaal. Vermijd zo laag als één werkknooppunt.
- Voer de opdracht uit om de veilige modus te verlaten, indien nodig.
In de volgende secties worden deze opties beschreven.
Alle Hive-taken stoppen
Stop alle Hive-taken voordat u omlaag schaalt naar één werkknooppunt. Als uw werkbelasting is gepland, voert u de schaal omlaag uit nadat Hive-werk is voltooid.
Stop de Hive-taken voordat u schaalt, om het aantal scratchbestanden in de tmp-map (indien aanwezig) te minimaliseren.
De scratchbestanden van Hive handmatig opschonen
Als Hive tijdelijke bestanden heeft achtergelaten, kunt u deze bestanden handmatig opschonen voordat u omlaag schaalt om veilige modus te voorkomen.
Controleer welke locatie wordt gebruikt voor tijdelijke Hive-bestanden door de
hive.exec.scratchdirconfiguratie-eigenschap te bekijken. Deze parameter wordt ingesteld in/etc/hive/conf/hive-site.xml:<property> <name>hive.exec.scratchdir</name> <value>hdfs://mycluster/tmp/hive</value> </property>Stop Hive-services en zorg ervoor dat alle query's en taken zijn voltooid.
Vermeld de inhoud van de hierboven gevonden
hdfs://mycluster/tmp/hive/scratchmap om te zien of deze bestanden bevat:hadoop fs -ls -R hdfs://mycluster/tmp/hive/hiveHier volgt een voorbeelduitvoer wanneer er bestanden bestaan:
sshuser@scalin:~$ hadoop fs -ls -R hdfs://mycluster/tmp/hive/hive drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/_tmp_space.db -rw-r--r-- 3 hive hdfs 27 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.info -rw-r--r-- 3 hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.lck drwx------ - hive hdfs 0 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699 -rw-r--r-- 3 hive hdfs 26 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699/inuse.infoAls u weet dat Hive klaar is met deze bestanden, kunt u ze verwijderen. Zorg ervoor dat Hive geen query's heeft die worden uitgevoerd door te kijken op de gebruikersinterfacepagina van Yarn Resource Manager.
Voorbeeld van opdrachtregel voor het verwijderen van bestanden uit HDFS:
hadoop fs -rm -r -skipTrash hdfs://mycluster/tmp/hive/
HDInsight schalen naar drie of meer werkknooppunten
Als uw clusters regelmatig vastlopen in de veilige modus wanneer u omlaag schaalt naar minder dan drie werkknooppunten, moet u ten minste drie werkknooppunten behouden.
Het hebben van drie werkknooppunten is duurder dan omlaag schalen naar slechts één werkknooppunt. Met deze actie voorkomt u echter dat uw cluster vastloopt in de veilige modus.
HDInsight omlaag schalen naar één werkknooppunt
Zelfs wanneer het cluster omlaag wordt geschaald naar één knooppunt, blijft werkknooppunt 0 bestaan. Werkrolknooppunt 0 kan nooit buiten gebruik worden gesteld.
Voer de opdracht uit om de veilige modus te verlaten
De laatste optie is om de opdracht veilige modus verlaten uit te voeren. Als HDFS in de veilige modus is gegaan vanwege onder-replicatie van hive-bestanden, voert u de volgende opdracht uit om de veilige modus te verlaten:
hdfs dfsadmin -D 'fs.default.name=hdfs://mycluster/' -safemode leave
Een Apache HBase-cluster omlaag schalen
Regioservers worden binnen een paar minuten na het voltooien van een schaalbewerkingsproces automatisch in balans gebracht. Voer de volgende stappen uit om regioservers handmatig te verdelen:
Maak verbinding met het HDInsight-cluster met behulp van SSH. Zie SSH gebruiken met HDInsight voor meer informatie.
Start de HBase-shell:
hbase shellGebruik de volgende opdracht om de regioservers handmatig te verdelen:
balancer
Volgende stappen
Zie voor specifieke informatie over het schalen van uw HDInsight-cluster: