Een pijplijn voor gegevensanalyse operationeel maken
Gegevenspijplijnen zijn te veel oplossingen voor gegevensanalyse. Zoals de naam al aangeeft, neemt een gegevenspijplijn onbewerkte gegevens op, schoont deze op en hervormt deze indien nodig, en voert vervolgens meestal berekeningen of aggregaties uit voordat de verwerkte gegevens worden opgeslagen. De verwerkte gegevens worden gebruikt door clients, rapporten of API's. Een gegevenspijplijn moet herhaalbare resultaten bieden, ongeacht of dit volgens een schema of wanneer deze wordt geactiveerd door nieuwe gegevens.
In dit artikel wordt beschreven hoe u uw gegevenspijplijnen operationeel kunt maken voor herhaalbaarheid met behulp van Oozie die wordt uitgevoerd op HDInsight Hadoop-clusters. Het voorbeeldscenario begeleidt u door een gegevenspijplijn waarmee vluchttijdreeksgegevens van luchtvaartmaatschappijen worden voorbereid en verwerkt.
In het volgende scenario zijn de invoergegevens een plat bestand met een batch vluchtgegevens voor één maand. Deze vluchtgegevens omvatten informatie zoals de luchthaven van herkomst en bestemming, de mijlen die zijn gevlogen, de vertrek- en aankomsttijden, enzovoort. Het doel van deze pijplijn is om de prestaties van dagelijkse luchtvaartmaatschappijen samen te vatten, waarbij elke luchtvaartmaatschappij één rij heeft voor elke dag met het gemiddelde vertrek- en aankomstvertraging in minuten en de totale mijlen die dag zijn gevlogen.
| YEAR | MONTH | DAY_OF_MONTH | VERVOERDER | AVG_DEP_DELAY | AVG_ARR_DELAY | TOTAL_DISTANCE |
|---|---|---|---|---|---|---|
| 2017 | 1 | 3 | AA | 10.142229 | 7.862926 | 2644539 |
| 2017 | 1 | 3 | AS | 9.435449 | 5.482143 | 572289 |
| 2017 | 1 | 3 | DL | 6.935409 | -2.1893024 | 1909696 |
De voorbeeldpijplijn wacht totdat de vluchtgegevens van een nieuwe periode binnenkomen en slaat die gedetailleerde vluchtinformatie vervolgens op in uw Apache Hive-datawarehouse voor langetermijnanalyses. De pijplijn maakt ook een veel kleinere gegevensset die alleen de dagelijkse vluchtgegevens samenvat. Deze dagelijkse vluchtoverzichtsgegevens worden verzonden naar een SQL Database om rapporten te verstrekken, zoals voor een website.
In het volgende diagram ziet u de voorbeeldpijplijn.
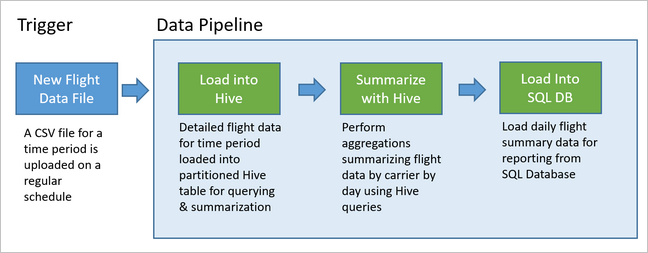
Overzicht van Apache Oozie-oplossing
Deze pijplijn maakt gebruik van Apache Oozie die wordt uitgevoerd op een HDInsight Hadoop-cluster.
Oozie beschrijft de pijplijnen in termen van acties, werkstromen en coördinatoren. Acties bepalen het werkelijke werk dat moet worden uitgevoerd, zoals het uitvoeren van een Hive-query. Werkstromen definiëren de volgorde van acties. Coördinatoren definiëren het schema voor wanneer de werkstroom wordt uitgevoerd. Coördinatoren kunnen ook wachten op de beschikbaarheid van nieuwe gegevens voordat ze een exemplaar van de werkstroom starten.
In het volgende diagram ziet u het ontwerp op hoog niveau van deze Oozie-pijplijn.
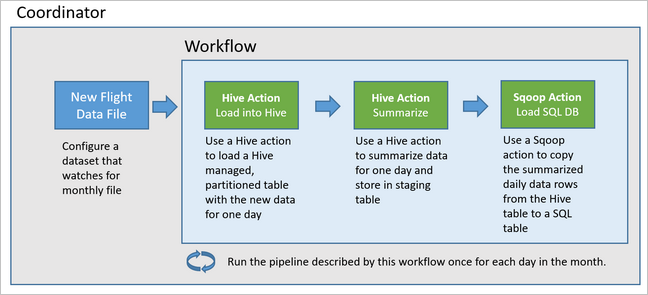
Azure-resources inrichten
Voor deze pijplijn zijn een Azure SQL Database en een HDInsight Hadoop-cluster op dezelfde locatie vereist. De Azure SQL Database slaat zowel de samenvattingsgegevens op die zijn geproduceerd door de pijplijn als het Oozie Metadata Store.
Azure SQL Database inrichten
Maak een Azure SQL Database. Zie Een Azure SQL Database maken in Azure Portal.
Als u ervoor wilt zorgen dat uw HDInsight-cluster toegang heeft tot de verbonden Azure SQL Database, configureert u firewallregels voor Azure SQL Database om Azure-services en -resources toegang te geven tot de server. U kunt deze optie inschakelen in Azure Portal door serverfirewall instellen te selecteren en aan te geven onder Toestaan dat Azure-services en -resources toegang hebben tot deze server voor Azure SQL Database. Raadpleeg IP-firewallregels maken en beheren voor meer informatie.
Gebruik de Query-editor om de volgende SQL-instructies uit te voeren om de
dailyflightstabel te maken waarmee de samengevatte gegevens van elke uitvoering van de pijplijn worden opgeslagen.CREATE TABLE dailyflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER CHAR(2), AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) GO CREATE CLUSTERED INDEX dailyflights_clustered_index on dailyflights(YEAR,MONTH,DAY_OF_MONTH,CARRIER) GO
Uw Azure SQL Database is nu gereed.
Een Apache Hadoop-cluster inrichten
Maak een Apache Hadoop-cluster met een aangepaste metastore. Zorg ervoor dat u tijdens het maken van het cluster vanuit de portal, op het tabblad Storage , uw SQL Database selecteert onder Metastore-instellingen. Zie Een aangepaste metastore selecteren tijdens het maken van een cluster voor meer informatie over het selecteren van een metastore. Zie Aan de slag met HDInsight in Linux voor meer informatie over het maken van clusters.
SSH-tunneling instellen
Als u de Oozie-webconsole wilt gebruiken om de status van uw coördinator- en werkstroomexemplaren weer te geven, stelt u een SSH-tunnel in op uw HDInsight-cluster. Zie SSH-tunnel voor meer informatie.
Notitie
U kunt Chrome ook gebruiken met de Foxy Proxy-extensie om door de webresources van uw cluster te bladeren in de SSH-tunnel. Configureer deze om alle aanvragen via de host via de poort localhost 9876 van de tunnel te proxyen. Deze methode is compatibel met de Windows-subsysteem voor Linux, ook wel bekend als Bash in Windows 10.
Voer de volgende opdracht uit om een SSH-tunnel naar uw cluster te openen, waarbij
CLUSTERNAMEde naam van uw cluster is:ssh -C2qTnNf -D 9876 sshuser@CLUSTERNAME-ssh.azurehdinsight.netControleer of de tunnel operationeel is door naar Ambari op uw hoofdknooppunt te navigeren door te bladeren naar:
http://headnodehost:8080Als u vanuit Ambari toegang wilt krijgen tot de Oozie-webconsole, gaat u naar Oozie>Quick Links> [Active server] >Oozie Web UI.
Hive configureren
Gegevens uploaden
Download een voorbeeld van een CSV-bestand dat vluchtgegevens voor één maand bevat. Download het ZIP-bestand
2017-01-FlightData.zipuit de HDInsight GitHub-opslagplaats en pak het uit in het CSV-bestand2017-01-FlightData.csv.Kopieer dit CSV-bestand naar het Azure Storage-account dat is gekoppeld aan uw HDInsight-cluster en plaats het in de
/example/data/flightsmap.Gebruik SCP om de bestanden van uw lokale computer te kopiëren naar de lokale opslag van het hoofdknooppunt van uw HDInsight-cluster.
scp ./2017-01-FlightData.csv sshuser@CLUSTERNAME-ssh.azurehdinsight.net:2017-01-FlightData.csvGebruik de ssh-opdracht om verbinding te maken met uw cluster. Bewerk de onderstaande opdracht door
CLUSTERNAMEte vervangen door de naam van uw cluster.Voer vervolgens deze opdracht in:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netGebruik vanuit uw SSH-sessie de HDFS-opdracht om het bestand te kopiëren van de lokale opslag van uw hoofdknooppunt naar Azure Storage.
hadoop fs -mkdir /example/data/flights hdfs dfs -put ./2017-01-FlightData.csv /example/data/flights/2017-01-FlightData.csv
Tabellen maken
De voorbeeldgegevens zijn nu beschikbaar. Voor de pijplijn zijn echter twee Hive-tabellen vereist voor verwerking, één voor de binnenkomende gegevens (rawFlights) en één voor de samengevatte gegevens (flights). Maak deze tabellen als volgt in Ambari.
Meld u aan bij Ambari door naar
http://headnodehost:8080.Selecteer Hive in de lijst met services.
Selecteer Naar beeld gaan naast het label Hive View 2.0.
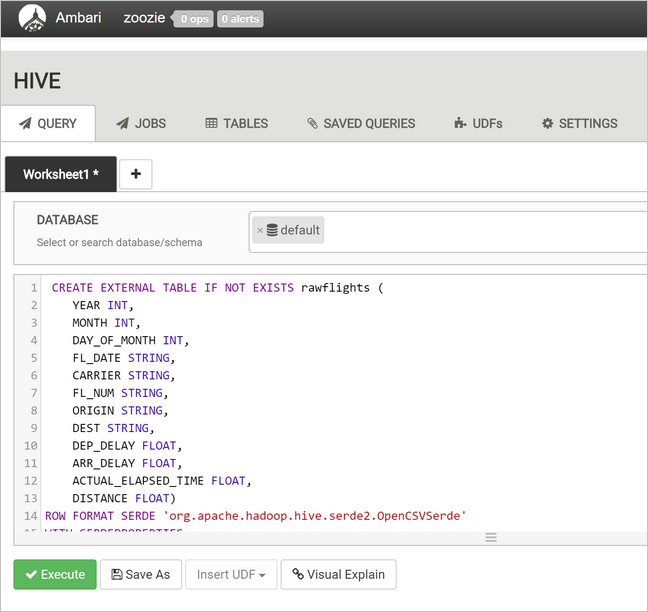
Plak in het tekstgebied van de query de volgende instructies om de
rawFlightstabel te maken. DerawFlightstabel bevat een schema-on-read voor de CSV-bestanden in de/example/data/flightsmap in Azure Storage.CREATE EXTERNAL TABLE IF NOT EXISTS rawflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" ) LOCATION '/example/data/flights'Selecteer Uitvoeren om de tabel te maken.
Als u de
flightstabel wilt maken, vervangt u de tekst in het querytekstgebied door de volgende instructies. Deflightstabel is een door Hive beheerde tabel waarmee gegevens die in de tabel zijn geladen per jaar, maand en dag van de maand worden gepartitioneerd. Deze tabel bevat alle historische vluchtgegevens, met de laagste granulariteit die aanwezig is in de brongegevens van één rij per vlucht.SET hive.exec.dynamic.partition.mode=nonstrict; CREATE TABLE flights ( FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT ) PARTITIONED BY (YEAR INT, MONTH INT, DAY_OF_MONTH INT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" );Selecteer Uitvoeren om de tabel te maken.
De Oozie-werkstroom maken
Pijplijnen verwerken doorgaans gegevens in batches met een bepaald tijdsinterval. In dit geval verwerkt de pijplijn de vluchtgegevens dagelijks. Met deze methode kunnen de invoer-CSV-bestanden dagelijks, wekelijks, maandelijks of jaarlijks binnenkomen.
De voorbeeldwerkstroom verwerkt de vluchtgegevens dagelijks, in drie belangrijke stappen:
- Voer een Hive-query uit om de gegevens voor het datumbereik van die dag te extraheren uit het CSV-bronbestand dat wordt vertegenwoordigd door de
rawFlightstabel en de gegevens in de tabel in teflightsvoegen. - Voer een Hive-query uit om dynamisch een faseringstabel te maken in Hive voor de dag, die een kopie bevat van de vluchtgegevens die zijn samengevat op dag en vervoerder.
- Gebruik Apache Sqoop om alle gegevens uit de dagelijkse faseringstabel in Hive te kopiëren naar de doeltabel
dailyflightsin Azure SQL Database. Sqoop leest de bronrijen van de gegevens achter de Hive-tabel die zich in Azure Storage bevinden en laadt deze in SQL Database met behulp van een JDBC-verbinding.
Deze drie stappen worden gecoördineerd door een Oozie-werkstroom.
Maak op uw lokale werkstation een bestand met de naam
job.properties. Gebruik de onderstaande tekst als de begininhoud voor het bestand. Werk vervolgens de waarden voor uw specifieke omgeving bij. In de tabel onder de tekst wordt elk van de eigenschappen samengevat en wordt aangegeven waar u de waarden voor uw eigen omgeving kunt vinden.nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net jobTracker=[ACTIVERESOURCEMANAGER]:8050 queueName=default oozie.use.system.libpath=true appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie oozie.wf.application.path=${appBase}/load_flights_by_day hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql hiveDailyTableName=dailyflights${year}${month}${day} hiveDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/${year}/${month}/${day} sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]" sqlDatabaseTableName=dailyflights year=2017 month=01 day=03Eigenschappen Waardebron nameNode Het volledige pad naar de Azure Storage-container die is gekoppeld aan uw HDInsight-cluster. jobTracker De interne hostnaam naar het YARN-hoofdknooppunt van uw actieve cluster. Selecteer YARN op de startpagina van Ambari in de lijst met services en kies Vervolgens Active Resource Manager. De hostnaam-URI wordt boven aan de pagina weergegeven. Voeg poort 8050 toe. queueName De naam van de YARN-wachtrij die wordt gebruikt bij het plannen van de Hive-acties. Als standaard ingesteld laten. oozie.use.system.libpath Laat staan als waar. appBase Het pad naar de submap in Azure Storage waar u de Oozie-werkstroom en ondersteunende bestanden implementeert. oozie.wf.application.path De locatie van de Oozie-werkstroom workflow.xmldie moet worden uitgevoerd.hiveScriptLoadPartition Het pad in Azure Storage naar het Hive-querybestand hive-load-flights-partition.hql.hiveScriptCreateDailyTable Het pad in Azure Storage naar het Hive-querybestand hive-create-daily-summary-table.hql.hiveDailyTableName De dynamisch gegenereerde naam die moet worden gebruikt voor de faseringstabel. hiveDataFolder Het pad in Azure Storage naar de gegevens in de faseringstabel. sqlDatabase Verbinding maken ionString De JDBC-syntaxis verbindingsreeks naar uw Azure SQL Database. sqlDatabaseTableName De naam van de tabel in Azure SQL Database waarin samenvattingsrijen worden ingevoegd. Laat staan als dailyflights.jaar Het jaargedeelte van de dag waarvoor vluchtoverzichten worden berekend. Laat deze staan. maand Het maandonderdeel van de dag waarvoor vluchtoverzichten worden berekend. Laat deze staan. dagen De dag van de maandcomponent van de dag waarvoor vluchtoverzichten worden berekend. Laat deze staan. Maak op uw lokale werkstation een bestand met de naam
hive-load-flights-partition.hql. Gebruik de onderstaande code als de inhoud voor het bestand.SET hive.exec.dynamic.partition.mode=nonstrict; INSERT OVERWRITE TABLE flights PARTITION (YEAR, MONTH, DAY_OF_MONTH) SELECT FL_DATE, CARRIER, FL_NUM, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, ACTUAL_ELAPSED_TIME, DISTANCE, YEAR, MONTH, DAY_OF_MONTH FROM rawflights WHERE year = ${year} AND month = ${month} AND day_of_month = ${day};Oozie-variabelen gebruiken de syntaxis
${variableName}. Deze variabelen worden ingesteld in hetjob.propertiesbestand. Oozie vervangt de werkelijke waarden tijdens runtime.Maak op uw lokale werkstation een bestand met de naam
hive-create-daily-summary-table.hql. Gebruik de onderstaande code als de inhoud voor het bestand.DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName} ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER STRING, AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT year, month, day_of_month, carrier, avg(dep_delay) avg_dep_delay, avg(arr_delay) avg_arr_delay, sum(distance) total_distance FROM flights GROUP BY year, month, day_of_month, carrier HAVING year = ${year} AND month = ${month} AND day_of_month = ${day};Met deze query maakt u een faseringstabel waarmee alleen de samengevatte gegevens voor één dag worden opgeslagen. Noteer de SELECT-instructie waarmee de gemiddelde vertragingen en het totale aantal afstanden per vervoerder per dag worden berekend. De gegevens die zijn ingevoegd in deze tabel die zijn opgeslagen op een bekende locatie (het pad dat wordt aangegeven door de variabele hiveDataFolder), zodat deze in de volgende stap als bron voor Sqoop kunnen worden gebruikt.
Maak op uw lokale werkstation een bestand met de naam
workflow.xml. Gebruik de onderstaande code als de inhoud voor het bestand. Deze stappen hierboven worden uitgedrukt als afzonderlijke acties in het Oozie-werkstroombestand.<workflow-app name="loadflightstable" xmlns="uri:oozie:workflow:0.5"> <start to = "RunHiveLoadFlightsScript"/> <action name="RunHiveLoadFlightsScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptLoadPartition}</script> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> </hive> <ok to="RunHiveCreateDailyFlightTableScript"/> <error to="fail"/> </action> <action name="RunHiveCreateDailyFlightTableScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptCreateDailyTable}</script> <param>hiveTableName=${hiveDailyTableName}</param> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> <param>hiveDataFolder=${hiveDataFolder}/${year}/${month}/${day}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}/${year}/${month}/${day}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>
De twee Hive-query's worden geopend via hun pad in Azure Storage en de resterende variabelewaarden worden geleverd door het job.properties bestand. Dit bestand configureert de werkstroom die moet worden uitgevoerd voor de datum 3 januari 2017.
De Oozie-werkstroom implementeren en uitvoeren
Gebruik SCP vanuit uw bash-sessie om uw Oozie-werkstroom (workflow.xml), de Hive-query's (hive-load-flights-partition.hql en) en hive-create-daily-summary-table.hqlde taakconfiguratie (job.properties) te implementeren. In Oozie kan alleen het job.properties bestand bestaan op de lokale opslag van het hoofdknooppunt. Alle andere bestanden moeten worden opgeslagen in HDFS, in dit geval Azure Storage. De Sqoop-actie die door de werkstroom wordt gebruikt, is afhankelijk van een JDBC-stuurprogramma voor de communicatie met uw SQL Database, die moet worden gekopieerd van het hoofdknooppunt naar HDFS.
Maak de
load_flights_by_daysubmap onder het pad van de gebruiker in de lokale opslag van het hoofdknooppunt. Voer vanuit uw geopende ssh-sessie de volgende opdracht uit:mkdir load_flights_by_dayKopieer alle bestanden in de huidige map (de
workflow.xmlenjob.propertiesbestanden) tot aan deload_flights_by_daysubmap. Voer vanaf uw lokale werkstation de volgende opdracht uit:scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:load_flights_by_dayWerkstroombestanden kopiëren naar HDFS. Voer vanuit uw geopende SSH-sessie de volgende opdrachten uit:
cd load_flights_by_day hadoop fs -mkdir -p /oozie/load_flights_by_day hdfs dfs -put ./* /oozie/load_flights_by_dayKopieer
mssql-jdbc-7.0.0.jre8.jarvanuit het lokale hoofdknooppunt naar de werkstroommap in HDFS. Wijzig de opdracht indien nodig als uw cluster een ander JAR-bestand bevat. Pasworkflow.xmlindien nodig aan om een ander JAR-bestand weer te geven. Voer vanuit uw geopende ssh-sessie de volgende opdracht uit:hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /oozie/load_flights_by_dayDe werkstroom uitvoeren. Voer vanuit uw geopende ssh-sessie de volgende opdracht uit:
oozie job -config job.properties -runBekijk de status met behulp van de Oozie Web Console. Vanuit Ambari selecteert u Oozie, Snelle koppelingen en vervolgens Oozie Web Console. Selecteer Alle taken op het tabblad Werkstroomtaken.
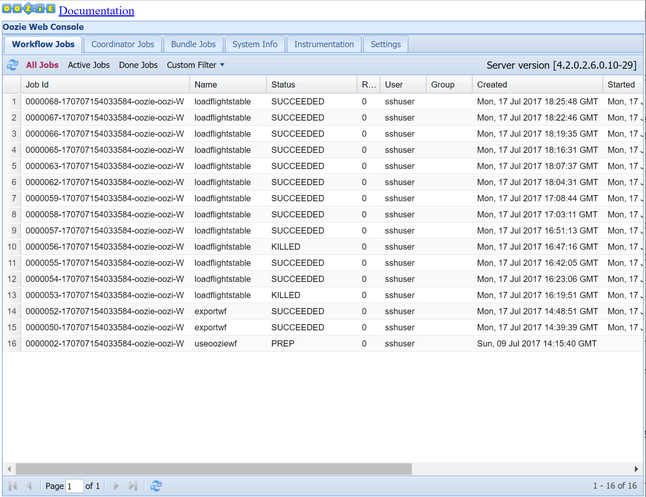
Wanneer de status SUCCEEDED is, voert u een query uit op de SQL Database-tabel om de ingevoegde rijen weer te geven. Ga in Azure Portal naar het deelvenster voor uw SQL Database, selecteer Extra en open de Power Query-editor.
SELECT * FROM dailyflights
Nu de werkstroom voor één testdag wordt uitgevoerd, kunt u deze werkstroom verpakken met een coördinator die de werkstroom plant, zodat deze dagelijks wordt uitgevoerd.
De werkstroom uitvoeren met een coördinator
Als u deze werkstroom zo wilt plannen dat deze dagelijks (of alle dagen in een datumbereik) wordt uitgevoerd, kunt u een coördinator gebruiken. Een coördinator wordt gedefinieerd door een XML-bestand, bijvoorbeeld coordinator.xml:
<coordinator-app name="daily_export" start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" timezone="UTC" xmlns="uri:oozie:coordinator:0.4">
<datasets>
<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC">
<uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template>
<done-flag></done-flag>
</dataset>
</datasets>
<input-events>
<data-in name="event_input1" dataset="ds_input1">
<instance>${coord:current(0)}</instance>
</data-in>
</input-events>
<action>
<workflow>
<app-path>${appBase}/load_flights_by_day</app-path>
<configuration>
<property>
<name>year</name>
<value>${coord:formatTime(coord:nominalTime(), 'yyyy')}</value>
</property>
<property>
<name>month</name>
<value>${coord:formatTime(coord:nominalTime(), 'MM')}</value>
</property>
<property>
<name>day</name>
<value>${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveScriptLoadPartition</name>
<value>${hiveScriptLoadPartition}</value>
</property>
<property>
<name>hiveScriptCreateDailyTable</name>
<value>${hiveScriptCreateDailyTable}</value>
</property>
<property>
<name>hiveDailyTableNamePrefix</name>
<value>${hiveDailyTableNamePrefix}</value>
</property>
<property>
<name>hiveDailyTableName</name>
<value>${hiveDailyTableNamePrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}${coord:formatTime(coord:nominalTime(), 'MM')}${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveDataFolderPrefix</name>
<value>${hiveDataFolderPrefix}</value>
</property>
<property>
<name>hiveDataFolder</name>
<value>${hiveDataFolderPrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}/${coord:formatTime(coord:nominalTime(), 'MM')}/${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>sqlDatabaseConnectionString</name>
<value>${sqlDatabaseConnectionString}</value>
</property>
<property>
<name>sqlDatabaseTableName</name>
<value>${sqlDatabaseTableName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
Zoals u ziet, geeft het merendeel van de coördinator alleen configuratiegegevens door aan het werkstroomexemplaren. Er zijn echter enkele belangrijke items die moeten worden aangeroepen.
Punt 1: De
startenendkenmerken van hetcoordinator-appelement zelf bepalen het tijdsinterval waarop de coördinator wordt uitgevoerd.<coordinator-app ... start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" ...>Een coördinator is verantwoordelijk voor het plannen van acties binnen het
startenenddatumbereik, volgens het interval dat is opgegeven door hetfrequencykenmerk. Elke geplande actie voert de werkstroom op zijn beurt uit zoals geconfigureerd. In de bovenstaande definitie van de coördinator is de coördinator geconfigureerd voor het uitvoeren van acties van 1 januari 2017 tot 5 januari 2017. De frequentie wordt ingesteld op één dag door de Oozie Expression Language frequency expression.${coord:days(1)}Dit resulteert in het plannen van een actie (en dus de werkstroom) eenmaal per dag door de coördinator. Voor datumbereiken die zich in het verleden bevinden, zoals in dit voorbeeld, wordt de actie gepland om zonder vertraging uit te voeren. Het begin van de datum van waaruit een actie moet worden uitgevoerd, wordt de nominale tijd genoemd. Als u bijvoorbeeld de gegevens voor 1 januari 2017 wilt verwerken, plant de coördinator actie met een nominale tijd van 2017-01-01T00:00:00 GMT.Punt 2: Binnen het datumbereik van de werkstroom geeft het
datasetelement aan waar in HDFS moet worden gezocht naar de gegevens voor een bepaald datumbereik en wordt geconfigureerd hoe Oozie bepaalt of de gegevens nog beschikbaar zijn voor verwerking.<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC"> <uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template> <done-flag></done-flag> </dataset>Het pad naar de gegevens in HDFS wordt dynamisch gebouwd op basis van de expressie in het
uri-templateelement. In deze coördinator wordt ook een frequentie van één dag gebruikt met de gegevensset. Terwijl de begin- en einddatums van het coördinatorelement bepalen wanneer de acties worden gepland (en hun nominale tijden definiëren), bepalen deinitial-instanceenfrequencyop de gegevensset de berekening van de datum die wordt gebruikt bij het samenstellen van deuri-template. In dit geval stelt u het eerste exemplaar in op één dag vóór het begin van de coördinator om ervoor te zorgen dat de eerste dag (1 januari 2017) gegevens ophaalt. De datumberekening van de gegevensset wordt doorgestuurd vanaf de waarde vaninitial-instance(12-31-2016) die gaat in stappen van de frequentie van de gegevensset (één dag) totdat de meest recente datum wordt gevonden die niet de nominale tijd doorgeeft die is ingesteld door de coördinator (2017-01-01T00:00:00 GMT voor de eerste actie).Het lege
done-flagelement geeft aan dat wanneer Oozie controleert op de aanwezigheid van invoergegevens op het aangewezen tijdstip, Oozie gegevens bepaalt of deze beschikbaar zijn door aanwezigheid van een map of bestand. In dit geval is het de aanwezigheid van een CSV-bestand. Als er een CSV-bestand aanwezig is, gaat Oozie ervan uit dat de gegevens gereed zijn en wordt een werkstroomexemplaren gestart om het bestand te verwerken. Als er geen CSV-bestand aanwezig is, gaat Oozie ervan uit dat de gegevens nog niet gereed zijn en dat de uitvoering van de werkstroom een wachtstatus krijgt.Punt 3: Het
data-inelement geeft het specifieke tijdstempel op dat moet worden gebruikt als de nominale tijd bij het vervangen van de waarden inuri-templatevoor de bijbehorende gegevensset.<data-in name="event_input1" dataset="ds_input1"> <instance>${coord:current(0)}</instance> </data-in>Stel in dit geval het exemplaar in op de expressie
${coord:current(0)}, die resulteert in het gebruik van de nominale tijd van de actie zoals oorspronkelijk gepland door de coördinator. Met andere woorden, wanneer de coördinator plant dat de actie wordt uitgevoerd met een nominale tijd van 01/01/2017, dan wordt 01/01/2017 gebruikt om de variabelen YEAR (2017) en MONTH (01) in de URI-sjabloon te vervangen. Zodra de URI-sjabloon voor dit exemplaar is berekend, controleert Oozie of de verwachte map of het verwachte bestand beschikbaar is en plant de volgende uitvoering van de werkstroom dienovereenkomstig.
De drie voorgaande punten zijn gecombineerd om een situatie op te leveren waarbij de coördinator de verwerking van de brongegevens op een dagelijkse manier plant.
Punt 1: De coördinator begint met een nominale datum van 2017-01-01.
Punt 2: Oozie zoekt naar gegevens die beschikbaar zijn in
sourceDataFolder/2017-01-FlightData.csv.Punt 3: Wanneer Oozie dat bestand vindt, wordt een exemplaar van de werkstroom gepland waarmee de gegevens voor 1 januari 2017 worden verwerkt. Oozie blijft dan verwerken voor 2017-01-02. Deze evaluatie herhaalt maximaal maar niet inclusief 2017-01-05.
Net als bij werkstromen wordt de configuratie van een coördinator gedefinieerd in een job.properties bestand, dat een superset heeft van de instellingen die door de werkstroom worden gebruikt.
nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net
jobTracker=[ACTIVERESOURCEMANAGER]:8050
queueName=default
oozie.use.system.libpath=true
appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie
oozie.coord.application.path=${appBase}
sourceDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/
hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql
hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql
hiveDailyTableNamePrefix=dailyflights
hiveDataFolderPrefix=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/
sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]"
sqlDatabaseTableName=dailyflights
De enige nieuwe eigenschappen die in dit job.properties bestand zijn geïntroduceerd, zijn:
| Eigenschappen | Waardebron |
|---|---|
| oozie.coord.application.path | Geeft de locatie aan van het coordinator.xml bestand met de Oozie-coördinator die moet worden uitgevoerd. |
| hiveDailyTableNamePrefix | Het voorvoegsel dat wordt gebruikt bij het dynamisch maken van de tabelnaam van de faseringstabel. |
| hiveDataFolderPrefix | Het voorvoegsel van het pad waar alle faseringstabellen worden opgeslagen. |
De Oozie-coördinator implementeren en uitvoeren
Als u de pijplijn wilt uitvoeren met een coördinator, gaat u op dezelfde manier als voor de werkstroom, behalve dat u werkt vanuit een map op één niveau boven de map die uw werkstroom bevat. Deze mapconventie scheidt de coördinatoren van de werkstromen op schijf, zodat u één coördinator kunt koppelen aan verschillende onderliggende werkstromen.
Gebruik SCP vanaf uw lokale computer om de coördinatorbestanden te kopiëren naar de lokale opslag van het hoofdknooppunt van uw cluster.
scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:~SSH in uw hoofdknooppunt.
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netKopieer de coördinatorbestanden naar HDFS.
hdfs dfs -put ./* /oozie/Voer de coördinator uit.
oozie job -config job.properties -runControleer de status met behulp van de Oozie-webconsole, selecteer deze keer het tabblad Coördinatortaken en vervolgens Alle taken.
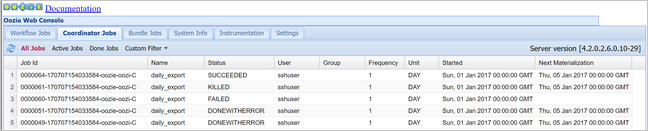
Selecteer een coördinatorexemplaren om de lijst met geplande acties weer te geven. In dit geval ziet u vier acties met nominale tijden in het bereik van 1 januari 2017 tot 4 januari 2017.
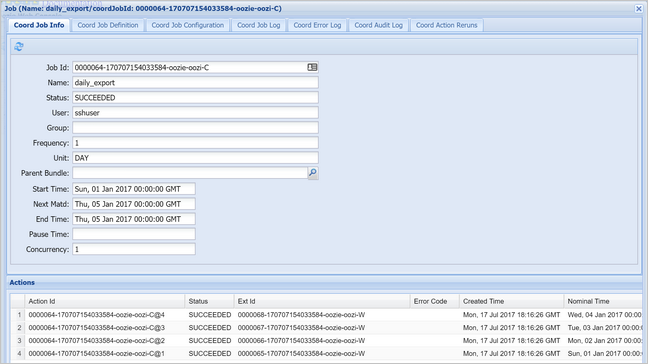
Elke actie in deze lijst komt overeen met een instantie van de werkstroom die de gegevens van één dag verwerkt, waarbij het begin van die dag wordt aangegeven door de nominale tijd.
Volgende stappen
Documentatie voor Apache Oozie (Engelstalig)
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor