Problemen met Apache Hive HDFS oplossen met behulp van Azure HDInsight
Meer informatie over de belangrijkste problemen en oplossingen bij het werken met Hadoop Distributed File System (HDFS). Zie de HANDLEIDING voor HDFS-opdrachten en de Handleiding voor bestandssysteemshell voor een volledige lijst met opdrachten.
Hoe kan ik toegang tot de lokale HDFS vanuit een cluster?
Probleem
Open de lokale HDFS vanaf de opdrachtregel en toepassingscode in plaats van azure Blob Storage of Azure Data Lake Storage vanuit het HDInsight-cluster.
Stappen voor het oplossen
Gebruik
hdfs dfs -D "fs.default.name=hdfs://mycluster/" ...bij de opdrachtprompt letterlijk, zoals in de volgende opdracht:hdfs dfs -D "fs.default.name=hdfs://mycluster/" -ls / Found 3 items drwxr-xr-x - hdiuser hdfs 0 2017-03-24 14:12 /EventCheckpoint-30-8-24-11102016-01 drwx-wx-wx - hive hdfs 0 2016-11-10 18:42 /tmp drwx------ - hdiuser hdfs 0 2016-11-10 22:22 /userGebruik vanuit broncode de URI
hdfs://mycluster/letterlijk, zoals in de volgende voorbeeldtoepassing:import java.io.IOException; import java.net.URI; import org.apache.commons.io.IOUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; public class JavaUnitTests { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String hdfsUri = "hdfs://mycluster/"; conf.set("fs.defaultFS", hdfsUri); FileSystem fileSystem = FileSystem.get(URI.create(hdfsUri), conf); RemoteIterator<LocatedFileStatus> fileStatusIterator = fileSystem.listFiles(new Path("/tmp"), true); while(fileStatusIterator.hasNext()) { System.out.println(fileStatusIterator.next().getPath().toString()); } } }Voer het gecompileerde .jar-bestand (bijvoorbeeld een bestand met de naam
java-unit-tests-1.0.jar) uit op het HDInsight-cluster met de volgende opdracht:hadoop jar java-unit-tests-1.0.jar JavaUnitTests hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.info hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.lck hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.info hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.lck
Opslagonderzondering voor schrijven op blob
Probleem
Wanneer u de hadoop of hdfs dfs opdrachten gebruikt om bestanden te schrijven die ongeveer 12 GB of groter zijn op een HBase-cluster, kunt u de volgende fout tegenkomen:
ERROR azure.NativeAzureFileSystem: Encountered Storage Exception for write on Blob : example/test_large_file.bin._COPYING_ Exception details: null Error Code : RequestBodyTooLarge
copyFromLocal: java.io.IOException
at com.microsoft.azure.storage.core.Utility.initIOException(Utility.java:661)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:366)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:350)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: com.microsoft.azure.storage.StorageException: The request body is too large and exceeds the maximum permissible limit.
at com.microsoft.azure.storage.StorageException.translateException(StorageException.java:89)
at com.microsoft.azure.storage.core.StorageRequest.materializeException(StorageRequest.java:307)
at com.microsoft.azure.storage.core.ExecutionEngine.executeWithRetry(ExecutionEngine.java:182)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlockInternal(CloudBlockBlob.java:816)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlock(CloudBlockBlob.java:788)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:354)
... 7 more
Oorzaak
HBase op HDInsight-clusters is standaard ingesteld op een blokgrootte van 256 kB bij het schrijven naar Azure Storage. Hoewel het werkt voor HBase-API's of REST-API's, resulteert dit in een fout bij het gebruik van de hadoop of hdfs dfs opdrachtregelprogramma's.
Oplossing
Hiermee fs.azure.write.request.size geeft u een grotere blokgrootte op. U kunt deze wijziging per gebruik uitvoeren met behulp van de -D parameter. De volgende opdracht is een voorbeeld van het gebruik van deze parameter met de hadoop opdracht:
hadoop -fs -D fs.azure.write.request.size=4194304 -copyFromLocal test_large_file.bin /example/data
U kunt ook de waarde van globaal verhogen met behulp van fs.azure.write.request.size Apache Ambari. De volgende stappen kunnen worden gebruikt om de waarde in de Ambari-webgebruikersinterface te wijzigen:
Ga in uw browser naar de Ambari-webgebruikersinterface voor uw cluster. De URL is
https://CLUSTERNAME.azurehdinsight.net, waarCLUSTERNAMEis de naam van uw cluster. Wanneer u hierom wordt gevraagd, voert u de beheerdersnaam en het wachtwoord voor het cluster in.Selecteer HDFS aan de linkerkant van het scherm en selecteer vervolgens het tabblad Configuraties.
Voer in het veld Filter... de tekst in
fs.azure.write.request.size.Wijzig de waarde van 262144 (256 kB) in de nieuwe waarde. Bijvoorbeeld 4194304 (4 MB).
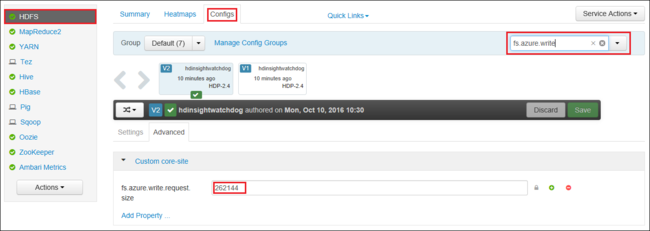
Zie HDInsight-clusters beheren met behulp van de Apache Ambari-webinterface voor meer informatie over het gebruik van Ambari.
Du
Met -du de opdracht worden de grootten van bestanden en mappen weergegeven die zijn opgenomen in de opgegeven map of de lengte van een bestand voor het geval het alleen een bestand is.
De -s optie produceert een geaggregeerde samenvatting van de weergegeven bestandslengten.
Met -h de optie worden de bestandsgrootten opgemaakt.
Voorbeeld:
hdfs dfs -du -s -h hdfs://mycluster/
hdfs dfs -du -s -h hdfs://mycluster/tmp
micrometer
Met de opdracht -rm worden bestanden verwijderd die zijn opgegeven als argumenten.
Voorbeeld:
hdfs dfs -rm hdfs://mycluster/tmp/testfile
Volgende stappen
Als u uw probleem niet hebt gezien of uw probleem niet kunt oplossen, gaat u naar een van de volgende kanalen voor meer ondersteuning:
Krijg antwoorden van Azure-experts via de ondersteuning van De Azure-community.
Maak verbinding met @AzureSupport : het officiële Microsoft Azure-account voor het verbeteren van de klantervaring. De Azure-community verbinden met de juiste resources: antwoorden, ondersteuning en experts.
Als u meer hulp nodig hebt, kunt u een ondersteuningsaanvraag indienen via Azure Portal. Selecteer Ondersteuning in de menubalk of open de Help + ondersteuningshub . Raadpleeg hoe u een ondersteuning voor Azure aanvraag maakt voor meer informatie. Toegang tot abonnementsbeheer en factuurbeheer is in uw Microsoft Azure-abonnement inbegrepen, en technische ondersteuning wordt verstrekt via een van de Azure-ondersteuningsplannen.