MirrorMaker gebruiken om Apache Kafka-onderwerpen te repliceren met Kafka in HDInsight
Meer informatie over het gebruik van de functie voor spiegeling van Apache Kafka om onderwerpen te repliceren naar een secundair cluster. U kunt spiegeling uitvoeren als een continu proces, of af en toe, om gegevens van het ene cluster naar het andere te migreren.
In dit artikel gebruikt u spiegeling om onderwerpen te repliceren tussen twee HDInsight-clusters. Deze clusters bevinden zich in verschillende virtuele netwerken in verschillende datacenters.
Waarschuwing
Gebruik spiegeling niet als een middel om fouttolerantie te bereiken. De verschuiving naar items in een onderwerp verschilt tussen de primaire en secundaire clusters, zodat clients de twee niet door elkaar kunnen gebruiken. Als u zich zorgen maakt over fouttolerantie, moet u replicatie instellen voor de onderwerpen in uw cluster. Zie Aan de slag met Apache Kafka in HDInsight voor meer informatie.
Hoe Apache Kafka-spiegeling werkt
Spiegeling werkt met behulp van het hulpprogramma MirrorMaker , dat deel uitmaakt van Apache Kafka. MirrorMaker verbruikt records uit onderwerpen op het primaire cluster en maakt vervolgens een lokale kopie op het secundaire cluster. MirrorMaker maakt gebruik van een (of meer) consumenten die lezen uit het primaire cluster en een producent die schrijft naar het lokale (secundaire) cluster.
De nuttigste instelling voor spiegeling voor herstel na noodgevallen maakt gebruik van Kafka-clusters in verschillende Azure-regio's. Om dit te bereiken, worden de virtuele netwerken waarin de clusters zich bevinden, gekoppeld aan elkaar.
In het volgende diagram ziet u het spiegelingsproces en hoe de communicatie tussen clusters verloopt:
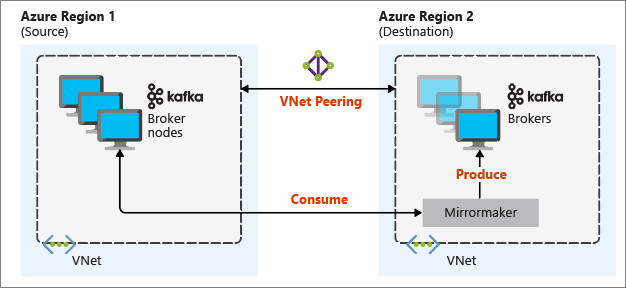
De primaire en secundaire clusters kunnen verschillen in het aantal knooppunten en partities, en verschuivingen binnen de onderwerpen zijn ook verschillend. Spiegeling behoudt de sleutelwaarde die wordt gebruikt voor partitionering, zodat de recordvolgorde per sleutel wordt behouden.
Spiegeling over netwerkgrenzen heen
Als u moet spiegelen tussen Kafka-clusters in verschillende netwerken, zijn er de volgende aanvullende overwegingen:
Gateways: de netwerken moeten kunnen communiceren op TCP/IP-niveau.
Serveradressering: u kunt ervoor kiezen om uw clusterknooppunten te adresseren met behulp van hun IP-adressen of volledig gekwalificeerde domeinnamen.
IP-adressen: als u uw Kafka-clusters configureert voor het gebruik van IP-adresadvertenties, kunt u doorgaan met het instellen van spiegeling met behulp van de IP-adressen van de brokerknooppunten en ZooKeeper-knooppunten.
Domeinnamen: als u uw Kafka-clusters niet configureert voor IP-adresadvertenties, moeten de clusters verbinding met elkaar kunnen maken met behulp van FQDN's (Fully Qualified Domain Names). Hiervoor is een DNS-server (Domain Name System) vereist in elk netwerk dat is geconfigureerd voor het doorsturen van aanvragen naar de andere netwerken. Wanneer u een virtueel Azure-netwerk maakt, moet u in plaats van de automatische DNS die bij het netwerk wordt geleverd, een aangepaste DNS-server en het IP-adres voor de server opgeven. Nadat u het virtuele netwerk hebt gemaakt, moet u een virtuele Azure-machine maken die gebruikmaakt van dat IP-adres. Vervolgens installeert en configureert u DNS-software erop.
Belangrijk
Maak en configureer de aangepaste DNS-server voordat u HDInsight in het virtuele netwerk installeert. Er is geen aanvullende configuratie vereist voor HDInsight om de DNS-server te gebruiken die is geconfigureerd voor het virtuele netwerk.
Zie Een verbinding configureren voor meer informatie over het verbinden van twee virtuele Azure-netwerken.
Architectuur voor spiegeling
Deze architectuur bevat twee clusters in verschillende resourcegroepen en virtuele netwerken: een primaire en een secundaire.
Stappen voor het maken
Maak twee nieuwe resourcegroepen:
Resourcegroep Locatie kafka-primary-rg Central US kafka-secondary-rg VS - noord-centraal Maak een nieuw virtueel netwerk kafka-primary-vnet in kafka-primary-rg. Laat de standaardinstellingen staan.
Maak een nieuw virtueel netwerk kafka-secondary-vnet in kafka-secondary-rg, ook met standaardinstellingen.
Maak twee nieuwe Kafka-clusters:
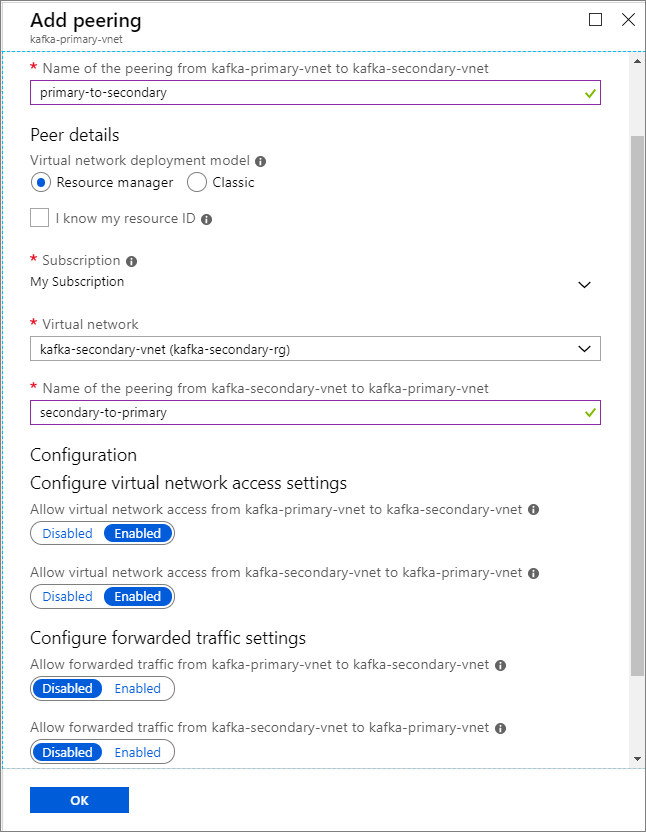
Clusternaam Resourcegroep Virtueel netwerk Storage-account kafka-primary-cluster kafka-primary-rg kafka-primary-vnet kafkaprimarystorage kafka-secondary-cluster kafka-secondary-rg kafka-secondary-vnet kafkasecondarystorage Peerings voor virtuele netwerken maken. In deze stap worden twee peerings gemaakt: een van kafka-primary-vnet naar kafka-secondary-vnet en een terug van kafka-secondary-vnet naar kafka-primary-vnet.
Selecteer het virtuele netwerk kafka-primary-vnet .
Selecteer onder Instellingen de optie Peerings.
Selecteer Toevoegen.
Voer in het scherm Peering toevoegen de details in, zoals wordt weergegeven in de volgende schermafbeelding.
IP-reclame configureren
Configureer IP-advertenties zodat een client verbinding kan maken met behulp van IP-adressen van de broker in plaats van domeinnamen.
Ga naar het Ambari-dashboard voor het primaire cluster:
https://PRIMARYCLUSTERNAME.azurehdinsight.net.Selecteer Services>Kafka. Selecteer het tabblad Configuraties .
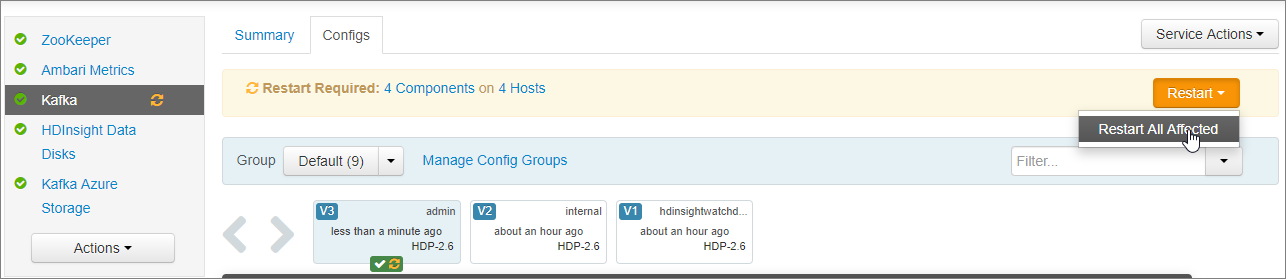
Voeg de volgende configuratieregels toe aan de onderste kafka-env-sjabloonsectie . Selecteer Opslaan.
# Configure Kafka to advertise IP addresses instead of FQDN IP_ADDRESS=$(hostname -i) echo advertised.listeners=$IP_ADDRESS sed -i.bak -e '/advertised/{/advertised@/!d;}' /usr/hdp/current/kafka-broker/conf/server.properties echo "advertised.listeners=PLAINTEXT://$IP_ADDRESS:9092" >> /usr/hdp/current/kafka-broker/conf/server.propertiesVoer een opmerking in op het scherm Configuratie opslaan en selecteer Opslaan.
Als u een configuratiewaarschuwing krijgt, selecteert u Toch doorgaan.
Selecteer ok bij Configuratiewijzigingen opslaan.
Selecteer in de melding Opnieuw opstarten vereistde optie Opnieuw opstarten>Alle betrokken opnieuw opstarten. Selecteer vervolgens Alles opnieuw opstarten bevestigen.
Kafka configureren om te luisteren op alle netwerkinterfaces
- Blijf op het tabblad Configuraties onder Services>Kafka. Stel in de sectie Kafka Broker de eigenschap listeners in op
PLAINTEXT://0.0.0.0:9092. - Selecteer Opslaan.
- Selecteer Opnieuw opstarten>Bevestigen Alles opnieuw opstarten.
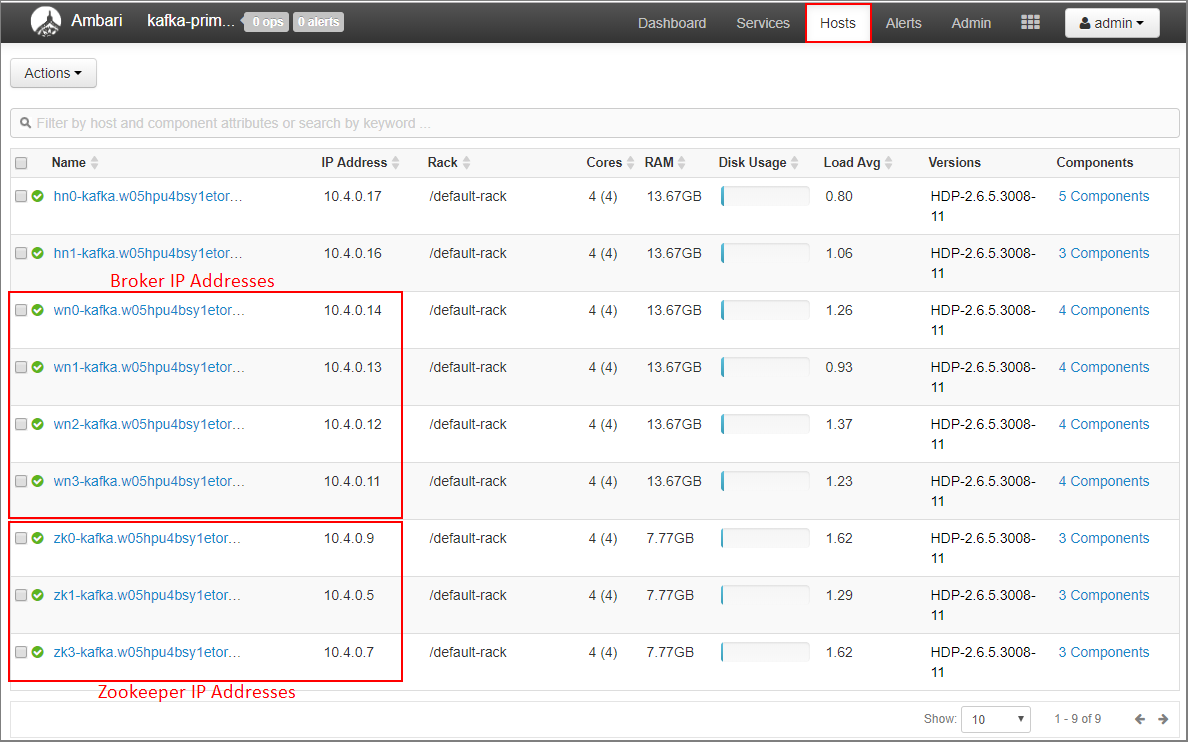
IP-adressen van brokers en ZooKeeper-adressen vastleggen voor het primaire cluster
Selecteer Hosts op het Ambari-dashboard.
Noteer de IP-adressen voor de brokers en ZooKeepers. De brokerknooppunten hebben wn als de eerste twee letters van de hostnaam en de ZooKeeper-knooppunten hebben zk als de eerste twee letters van de hostnaam.
Herhaal de vorige drie stappen voor het tweede cluster, kafka-secondary-cluster: IP-advertenties configureren, listeners instellen en een notitie maken van de broker- en ZooKeeper-IP-adressen.
Onderwerpen maken
Verbinding maken met het primaire cluster met behulp van SSH:
ssh sshuser@PRIMARYCLUSTER-ssh.azurehdinsight.netVervang door
sshuserde SSH-gebruikersnaam die u hebt gebruikt bij het maken van het cluster. Vervang doorPRIMARYCLUSTERde basisnaam die u hebt gebruikt bij het maken van het cluster.Zie SSH gebruiken met HDInsight voor meer informatie.
Gebruik de volgende opdracht om twee omgevingsvariabelen te maken met de Apache ZooKeeper-hosts en brokerhosts voor het primaire cluster. Vervang tekenreeksen zoals
ZOOKEEPER_IP_ADDRESS1door de werkelijke IP-adressen die eerder zijn vastgelegd, zoals10.23.0.11en10.23.0.7. Hetzelfde geldt voorBROKER_IP_ADDRESS1. Als u FQDN-omzetting gebruikt met een aangepaste DNS-server, volgt u deze stappen om broker- en ZooKeeper-namen op te halen.# get the ZooKeeper hosts for the primary cluster export PRIMARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181, ZOOKEEPER_IP_ADDRESS2:2181, ZOOKEEPER_IP_ADDRESS3:2181' # get the broker hosts for the primary cluster export PRIMARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'Gebruik de volgende opdracht om een onderwerp met de naam
testtopicte maken:/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $PRIMARY_ZKHOSTSGebruik de volgende opdracht om te controleren of het onderwerp is gemaakt:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --zookeeper $PRIMARY_ZKHOSTSHet antwoord bevat
testtopic.Gebruik het volgende om de brokerhostgegevens voor dit (het primaire) cluster weer te geven:
echo $PRIMARY_BROKERHOSTSDit retourneert informatie die vergelijkbaar is met de volgende tekst:
10.23.0.11:9092,10.23.0.7:9092,10.23.0.9:9092Sla deze gegevens op. Deze wordt gebruikt in de volgende sectie.
Spiegeling configureren
Maak verbinding met het secundaire cluster met behulp van een andere SSH-sessie:
ssh sshuser@SECONDARYCLUSTER-ssh.azurehdinsight.netVervang door
sshuserde SSH-gebruikersnaam die u hebt gebruikt bij het maken van het cluster. Vervang doorSECONDARYCLUSTERde naam die u hebt gebruikt bij het maken van het cluster.Zie SSH gebruiken met HDInsight voor meer informatie.
Gebruik een
consumer.propertiesbestand om communicatie met het primaire cluster te configureren. Gebruik de volgende opdracht om het bestand te maken:nano consumer.propertiesGebruik de volgende tekst als de inhoud van het
consumer.propertiesbestand:bootstrap.servers=PRIMARY_BROKERHOSTS group.id=mirrorgroupVervang door
PRIMARY_BROKERHOSTSde IP-adressen van de brokerhost van het primaire cluster.In dit bestand worden de consumentengegevens beschreven die moeten worden gebruikt bij het lezen van het primaire Kafka-cluster. Zie Consumer Configs op
kafka.apache.orgvoor meer informatie.Als u het bestand wilt opslaan, drukt u op Ctrl+X, op Y en vervolgens op Enter.
Voordat u de producent configureert die communiceert met het secundaire cluster, moet u een variabele instellen voor de broker-IP-adressen van het secundaire cluster. Gebruik de volgende opdrachten om deze variabele te maken:
export SECONDARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'De opdracht
echo $SECONDARY_BROKERHOSTSmoet informatie retourneren die vergelijkbaar is met de volgende tekst:10.23.0.14:9092,10.23.0.4:9092,10.23.0.12:9092Gebruik een
producer.propertiesbestand om het secundaire cluster te communiceren. Gebruik de volgende opdracht om het bestand te maken:nano producer.propertiesGebruik de volgende tekst als de inhoud van het
producer.propertiesbestand:bootstrap.servers=SECONDARY_BROKERHOSTS compression.type=noneVervang door
SECONDARY_BROKERHOSTSde IP-adressen van de broker die in de vorige stap zijn gebruikt.Zie Producer Configs op
kafka.apache.orgvoor meer informatie.Gebruik de volgende opdrachten om een omgevingsvariabele te maken met de IP-adressen van de ZooKeeper-hosts voor het secundaire cluster:
# get the ZooKeeper hosts for the secondary cluster export SECONDARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181,ZOOKEEPER_IP_ADDRESS2:2181,ZOOKEEPER_IP_ADDRESS3:2181'De standaardconfiguratie voor Kafka in HDInsight staat het automatisch maken van onderwerpen niet toe. U moet een van de volgende opties gebruiken voordat u het spiegelingsproces start:
De onderwerpen op het secundaire cluster maken: met deze optie kunt u ook het aantal partities en de replicatiefactor instellen.
U kunt van tevoren onderwerpen maken met behulp van de volgende opdracht:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $SECONDARY_ZKHOSTSVervang door
testtopicde naam van het onderwerp dat u wilt maken.Het cluster configureren voor het automatisch maken van onderwerpen: met deze optie kan MirrorMaker automatisch onderwerpen maken. Houd er rekening mee dat deze mogelijk worden gemaakt met een ander aantal partities of een andere replicatiefactor dan het primaire onderwerp.
Voer de volgende stappen uit om het secundaire cluster te configureren voor het automatisch maken van onderwerpen:
- Ga naar het Ambari-dashboard voor het secundaire cluster:
https://SECONDARYCLUSTERNAME.azurehdinsight.net. - Selecteer Services>Kafka. Selecteer vervolgens het tabblad Configuraties .
- Voer in het veld Filter de waarde in van
auto.create. Hiermee filtert u de lijst met eigenschappen en wordt deauto.create.topics.enableinstelling weergegeven. - Wijzig de waarde van
auto.create.topics.enableintrueen selecteer opslaan. Voeg een notitie toe en selecteer vervolgens opnieuw Opslaan . - Selecteer de Kafka-service , selecteer Opnieuw opstarten en selecteer vervolgens Alle betrokken opnieuw opstarten. Wanneer u hierom wordt gevraagd, selecteert u Alles opnieuw opstarten bevestigen.
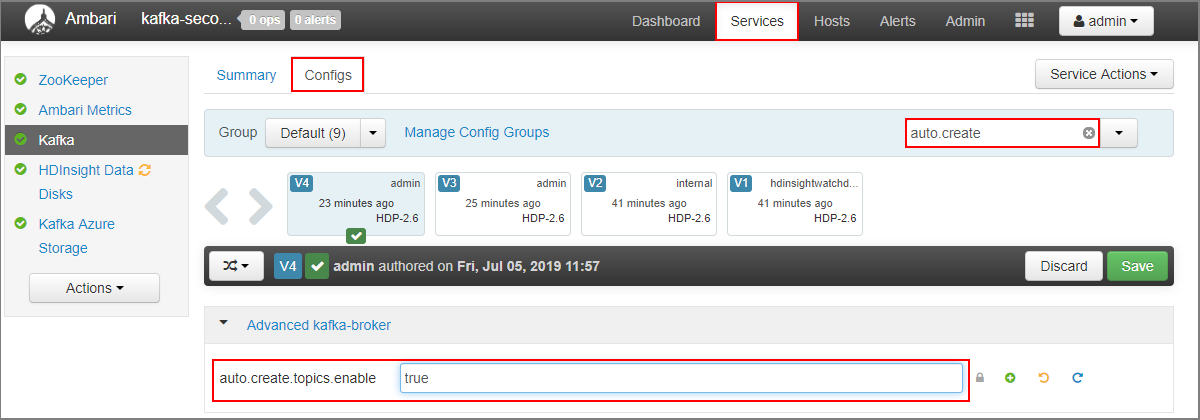
- Ga naar het Ambari-dashboard voor het secundaire cluster:
MirrorMaker starten
Notitie
Dit artikel bevat verwijzingen naar een term die microsoft niet meer gebruikt. Zodra de term uit de software wordt verwijderd, verwijderen we deze uit dit artikel.
Gebruik vanuit de SSH-verbinding met het secundaire cluster de volgende opdracht om het MirrorMaker-proces te starten:
/usr/hdp/current/kafka-broker/bin/kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config consumer.properties --producer.config producer.properties --whitelist testtopic --num.streams 4De parameters die in dit voorbeeld worden gebruikt, zijn:
Parameter Beschrijving --consumer.configHiermee geeft u het bestand dat consumenteneigenschappen bevat. U gebruikt deze eigenschappen om een consument te maken die leest uit het primaire Kafka-cluster. --producer.configHiermee geeft u het bestand op dat producenteigenschappen bevat. U gebruikt deze eigenschappen om een producer te maken die schrijft naar het secundaire Kafka-cluster. --whitelistEen lijst met onderwerpen die MirrorMaker repliceert van het primaire cluster naar het secundaire cluster. --num.streamsHet aantal consumententhreads dat moet worden gemaakt. De consument op het secundaire knooppunt wacht nu op het ontvangen van berichten.
Gebruik vanuit de SSH-verbinding met het primaire cluster de volgende opdracht om een producer te starten en berichten naar het onderwerp te verzenden:
/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $PRIMARY_BROKERHOSTS --topic testtopicWanneer u bij een lege regel met een cursor komt, typt u een paar sms-berichten. De berichten worden verzonden naar het onderwerp in het primaire cluster. Wanneer u klaar bent, drukt u op Ctrl+C om het producerproces te beëindigen.
Druk vanuit de SSH-verbinding naar het secundaire cluster op Ctrl+C om het MirrorMaker-proces te beëindigen. Het kan enkele seconden duren voordat het proces is beëindigd. Als u wilt controleren of de berichten zijn gerepliceerd naar de secundaire, gebruikt u de volgende opdracht:
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $SECONDARY_BROKERHOSTS --topic testtopic --from-beginningDe lijst met onderwerpen bevat
testtopicnu , die wordt gemaakt wanneer MirrorMaster het onderwerp van het primaire cluster naar het secundaire cluster spiegelt. De berichten die uit het onderwerp worden opgehaald, zijn dezelfde als de berichten die u hebt ingevoerd in het primaire cluster.
Het cluster verwijderen
Waarschuwing
HDInsight-clusters worden pro rato per minuut gefactureerd, ongeacht of u er wel of niet gebruik van maakt. Verwijder uw cluster daarom als u er klaar mee bent. Zie how to delete an HDInsight cluster (een HDInsight-cluster verwijderen).
Met de stappen in dit artikel zijn clusters in verschillende Azure-resourcegroepen gemaakt. Als u alle gemaakte resources wilt verwijderen, kunt u de twee gemaakte resourcegroepen verwijderen: kafka-primary-rg en kafka-secondary-rg. Als u de resourcegroepen verwijdert, worden alle resources verwijderd die zijn gemaakt door dit artikel te volgen, inclusief clusters, virtuele netwerken en opslagaccounts.
Volgende stappen
In dit artikel hebt u geleerd hoe u MirrorMaker gebruikt om een replica van een Apache Kafka-cluster te maken. Gebruik de volgende koppelingen om andere manieren te ontdekken om met Kafka te werken:
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor