Opslag en schaalbaarheid configureren voor Apache Kafka in HDInsight
Meer informatie over het configureren van het aantal beheerde schijven dat wordt gebruikt door Apache Kafka in HDInsight.
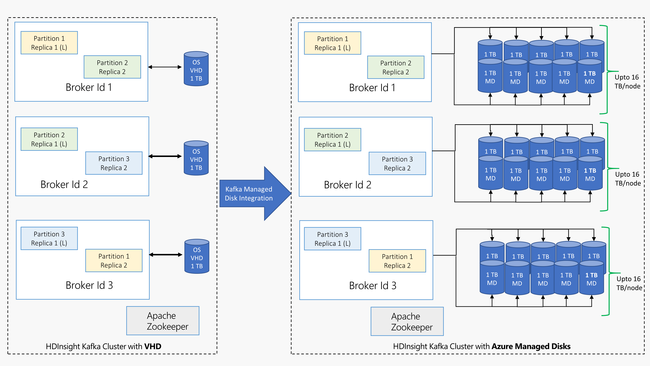
Kafka in HDInsight maakt gebruik van de lokale schijf van de virtuele machines in het HDInsight-cluster. Aangezien Kafka veel gebruikmaakt van invoer/uitvoer, wordt Azure Managed Disks gebruikt voor een hoge doorvoer en meer opslag per knooppunt. Als u de traditionele VHD (virtuele harde schijven) gebruikt voor Kafka, heeft elk knooppunt een limiet van 1 TB. Met beheerde schijven kunt u meerdere schijven gebruiken en zodat elk knooppunt in het cluster een limiet heeft van 16 TB.
In het volgende diagram ziet u een vergelijking tussen Kafka in HDInsight voordat beheerde schijven werden gebruikt, en Kafka in HDInsight met beheerde schijven:
Beheerde schijven configureren: Azure Portal
Volg de stappen in Een HDInsight-cluster maken voor de algemene stappen voor het maken van een cluster met behulp van de portal. Voltooi het proces voor het maken van de portal niet.
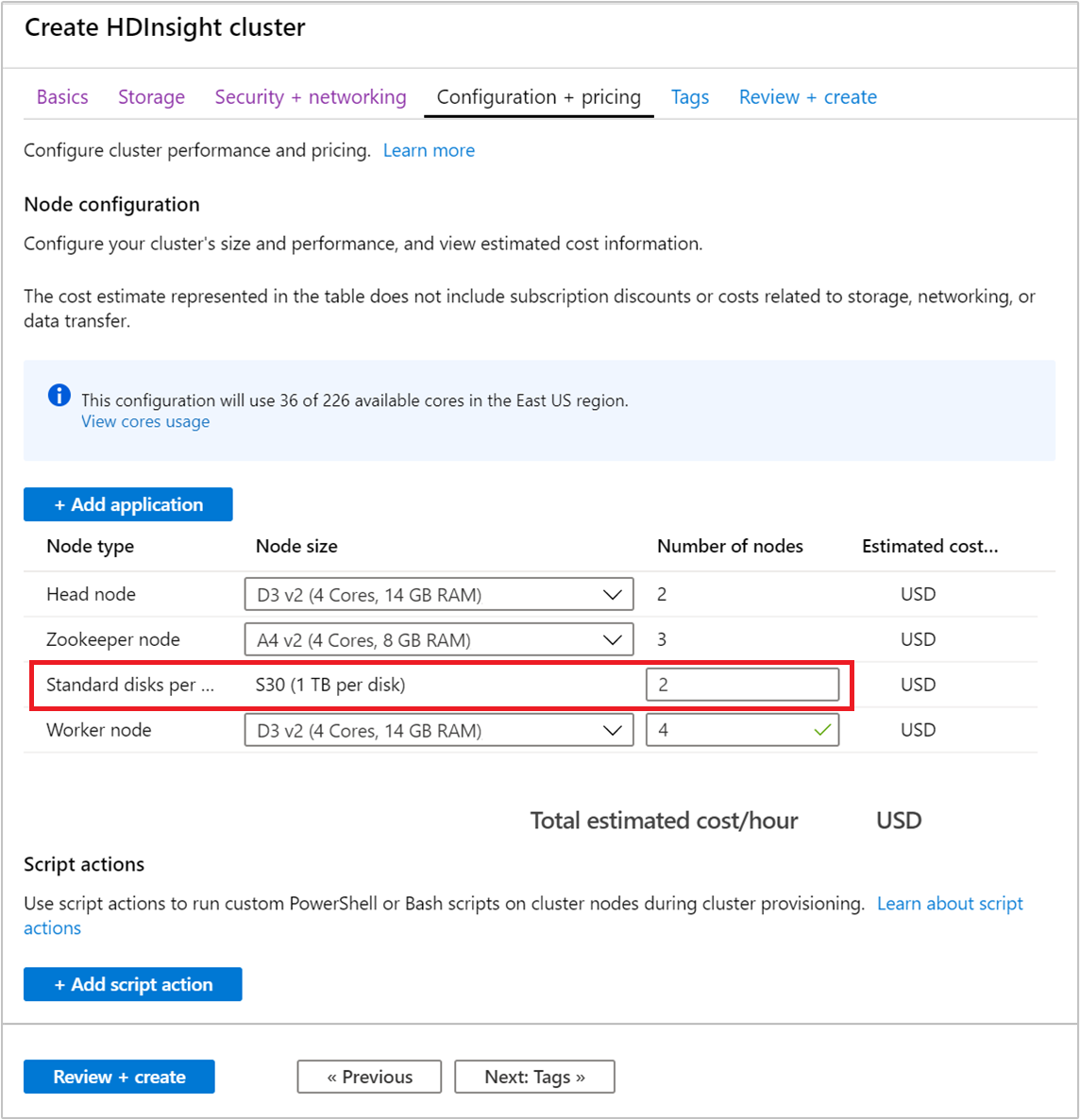
Gebruik in de sectie Configuratie en prijzen het veld Aantal knooppunten om het aantal schijven te configureren.
Notitie
Het type beheerde schijf is Standaard (HDD) of Premium (SSD). Premium-schijven worden gebruikt met virtuele machines uit de DS- en GS-reeks. Alle andere VM-typen gebruiken standaardschijven.
Beheerde schijven configureren: Resource Manager-sjabloon
Als u het aantal schijven wilt beheren dat wordt gebruikt in de werkknooppunten van een Kafka-cluster, gebruikt u de volgende sectie van de sjabloon:
"dataDisksGroups": [
{
"disksPerNode": "[variables('disksPerWorkerNode')]"
}
],
Volgende stappen
Zie de volgende documenten voor meer informatie over het werken met Apache Kafka in HDInsight:
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor